Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Découvrez comment entraîner un modèle d’apprentissage profond personnalisé à l’aide de l’apprentissage de transfert, d’un modèle TensorFlow préentraîné et de l’API de classification d’images ML.NET pour classifier les images de surfaces concrètes comme craquelées ou non brouillées.
Dans ce tutoriel, vous allez apprendre à :
- Comprendre le problème
- En savoir plus sur l’API de classification d’images ML.NET
- Comprendre le modèle préentraîné
- Utiliser l’apprentissage de transfert pour entraîner un modèle de classification d’images TensorFlow personnalisé
- Classifier des images avec le modèle personnalisé
Prerequisites
Comprendre le problème
La classification d’images est un problème de vision par ordinateur. La classification d’images prend une image comme entrée et la catégorise dans une classe prescrite. Les modèles de classification d’images sont couramment formés à l’aide d’apprentissage profond et de réseaux neuronaux. Pour plus d’informations, consultez Deep Learning et Machine Learning.
Voici quelques scénarios où la classification d’images est utile :
- Reconnaissance faciale
- Détection d’émotions
- Diagnostic médical
- Détection de points de repère
Ce tutoriel entraîne un modèle de classification d’images personnalisé pour effectuer une inspection visuelle automatisée des ponts de pont afin d’identifier les structures endommagées par des fissures.
API de classification d’images ML.NET
ML.NET offre différentes façons d’effectuer la classification d’images. Ce tutoriel applique l'apprentissage par transfert à l'aide de l'API de classification d'images. L’API Classification d’images utilise TensorFlow.NET, une bibliothèque de bas niveau qui fournit des liaisons C# pour l’API C++ TensorFlow.
Qu’est-ce que l’apprentissage de transfert ?
Le transfert d’apprentissage applique les connaissances acquises à partir de la résolution d’un problème à un autre problème lié.
L’apprentissage d’un modèle d’apprentissage profond à partir de zéro nécessite la définition de plusieurs paramètres, une grande quantité de données d’apprentissage étiquetées et une grande quantité de ressources de calcul (centaines d’heures GPU). L’utilisation d’un modèle préentraîné avec l’apprentissage de transfert vous permet de raccourcir le processus d’entraînement.
Processus de formation
L’API Classification d’images démarre le processus d’apprentissage en chargeant un modèle TensorFlow préentraîné. Le processus d’entraînement se compose de deux étapes :
- Phase de goulot d’étranglement.
- Phase d’entraînement.
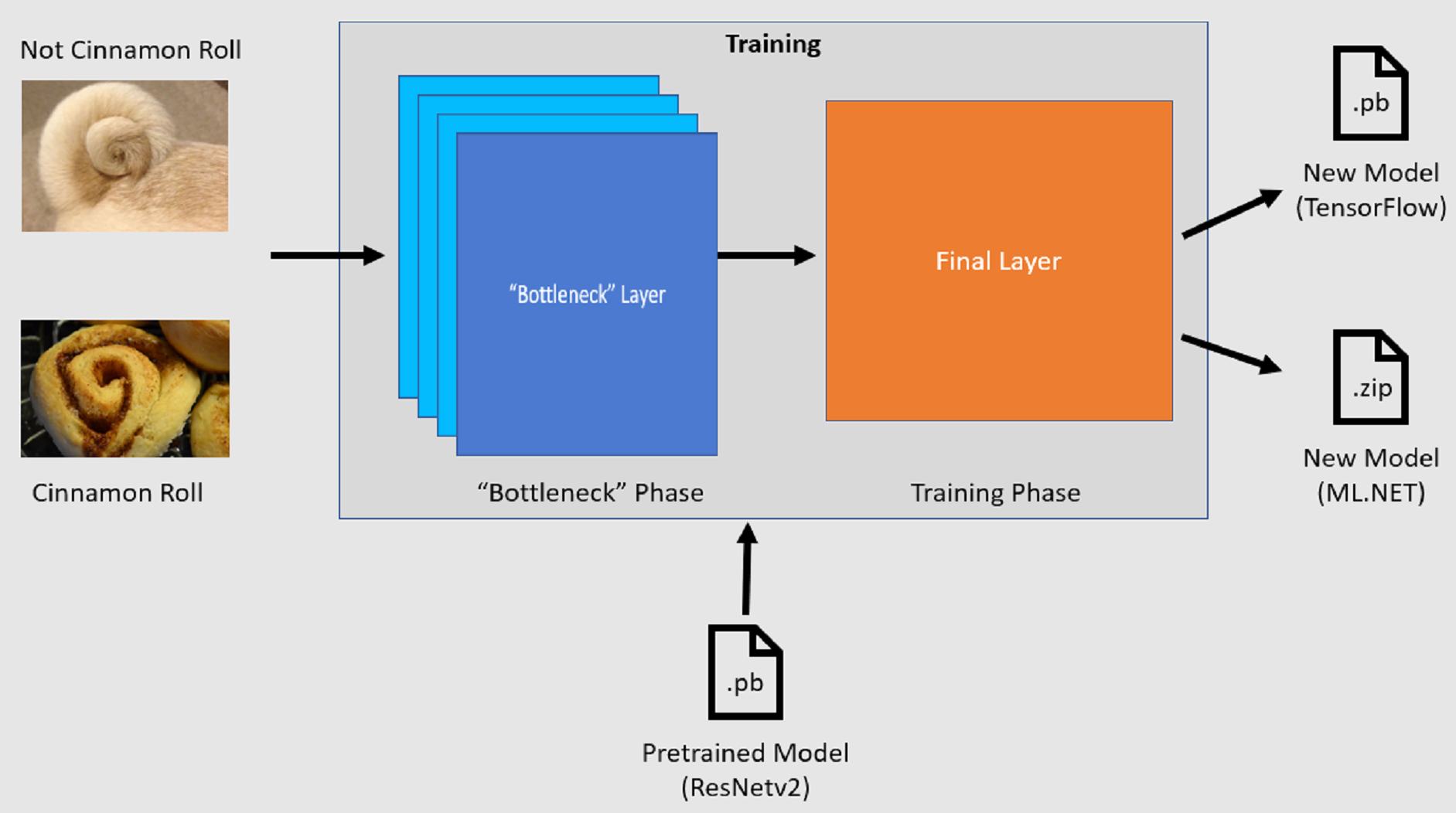
Phase de goulot d’étranglement
Pendant la phase de goulet d'étranglement, l'ensemble d'images d'entraînement est chargé et les valeurs de pixels sont utilisées comme entrée, ou "features" (caractéristiques), pour les couches figées du modèle préentraîné. Les couches figées incluent toutes les couches du réseau neuronal jusqu’à la dernière couche, connue de manière informelle sous le nom de couche de goulot d’étranglement. Ces couches sont appelées figées, car aucune formation ne se produit sur ces couches et les opérations sont directes. C’est à ces couches figées où les modèles de niveau inférieur qui aident un modèle à différencier les différentes classes sont calculés. Plus le nombre de couches est élevé, plus cette étape est gourmande en calcul. Heureusement, étant donné qu’il s’agit d’un calcul unique, les résultats peuvent être mis en cache et utilisés dans les exécutions ultérieures lors de l’expérience avec différents paramètres.
Phase d’entraînement
Une fois les valeurs de sortie de la phase de goulot d’étranglement calculées, elles sont utilisées comme entrée pour réentraîner la couche finale du modèle. Ce processus est itératif et s’exécute pour le nombre de fois spécifié par les paramètres de modèle. Pendant chaque exécution, la perte et la précision sont évaluées. Ensuite, les ajustements appropriés sont effectués pour améliorer le modèle avec l’objectif de minimiser la perte et d’optimiser la précision. Une fois l’entraînement terminé, deux formats de modèle sont en sortie. L’une d’elles est la .pb version du modèle, et l’autre est la .zip version sérialisée ML.NET du modèle. Lorsque vous travaillez dans des environnements pris en charge par ML.NET, il est recommandé d’utiliser la .zip version du modèle. Toutefois, dans les environnements où ML.NET n’est pas pris en charge, vous avez la possibilité d’utiliser la .pb version.
Comprendre le modèle préentraîné
Le modèle préentraîné utilisé dans ce tutoriel est la variante de 101 couches du modèle Réseau résiduel (ResNet) v2. Le modèle d’origine est entraîné pour classifier des images en mille catégories. Le modèle prend comme entrée une image de taille 224 x 224 et génère les probabilités de classe pour chacune des classes sur laquelle il est entraîné. Une partie de ce modèle est utilisée pour entraîner un nouveau modèle à l’aide d’images personnalisées pour effectuer des prédictions entre deux classes.
Créer une application console
Maintenant que vous avez une compréhension générale de l’apprentissage du transfert et de l’API Classification d’images, il est temps de créer l’application.
Créez une application console C# appelée « DeepLearning_ImageClassification_Binary ». Cliquez sur le bouton Suivant .
Choisissez .NET 8 comme framework à utiliser, puis sélectionnez Créer.
Installez le package NuGet Microsoft.ML :
Note
Cet exemple utilise la dernière version stable des packages NuGet mentionnés, sauf indication contraire.
- Dans l’Explorateur de solutions, cliquez avec le bouton droit sur votre projet, puis sélectionnez Gérer les packages NuGet.
- Choisissez « nuget.org » comme source du package.
- Sélectionnez l’onglet Parcourir.
- Cochez la case Inclure la préversion .
- Recherchez Microsoft.ML.
- Sélectionnez le bouton Installer.
- Sélectionnez le bouton Accepter dans la boîte de dialogue Acceptation de licence si vous acceptez les termes du contrat de licence pour les packages répertoriés.
- Répétez ces étapes pour les packages NuGet Microsoft.ML.Vision, SciSharp.TensorFlow.Redist (version 2.3.1) et Microsoft.ML.ImageAnalytics .
Préparer et comprendre les données
Note
Les jeux de données de ce didacticiel proviennent de Maguire, Marc ; Dorafshan, Sattar ; et Thomas, Robert J., « SDNET2018 : Un jeu de données d’image de fissure concrète pour les applications machine learning » (2018). Parcourez tous les jeux de données. Papier 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 est un jeu de données d’image qui contient des annotations pour les structures en béton craquelées et non fissurées (ponts, murs et trottoirs).

Les données sont organisées en trois sous-répertoires :
- D contient des images de pont de pont
- P contient des images de pavage
- W contient des images de mur
Chacune de ces sous-répertoires contient deux sous-répertoires préfixés supplémentaires :
- C est le préfixe utilisé pour les surfaces fissurées
- U est le préfixe utilisé pour les surfaces non brouillées
Dans ce tutoriel, seules les images de tablier de pont sont utilisées.
- Téléchargez le jeu de données et décompressez-le.
- Créez un répertoire nommé « Assets » dans votre projet pour enregistrer vos fichiers de jeu de données.
- Copiez les sous-répertoires CD et UD du répertoire récemment décompressé vers le répertoire Assets .
Créer des classes d’entrée et de sortie
Ouvrez le fichier Program.cs et remplacez le contenu existant par les directives suivantes
using:using Microsoft.ML; using Microsoft.ML.Vision; using static Microsoft.ML.DataOperationsCatalog;Créez une classe appelée
ImageData. Cette classe est utilisée pour représenter les données initialement chargées.class ImageData { public string? ImagePath { get; set; } public string? Label { get; set; } }ImageDatacontient les propriétés suivantes :-
ImagePathest le chemin complet où l’image est stockée. -
Labelest la catégorie à laquelle appartient l’image. Il s’agit de la valeur à prédire.
-
Créez des classes pour vos données d’entrée et de sortie.
Sous la
ImageDataclasse, définissez le schéma de vos données d’entrée dans une nouvelle classe appeléeModelInput.class ModelInput { public byte[]? Image { get; set; } public uint LabelAsKey { get; set; } public string? ImagePath { get; set; } public string? Label { get; set; } }ModelInputcontient les propriétés suivantes :-
Imageest labyte[]représentation de l’image. Le modèle s’attend à ce que les données d’image soient de ce type pour l’entraînement. -
LabelAsKeyest la représentation numérique duLabel. -
ImagePathest le chemin complet où l’image est stockée. -
Labelest la catégorie à laquelle appartient l’image. Il s’agit de la valeur à prédire.
Seuls
ImageetLabelAsKeysont utilisés pour entraîner le modèle et effectuer des prédictions. Les propriétésImagePathetLabelsont conservées pour faciliter l'accès au nom et à la catégorie du fichier image d’origine.-
Ensuite, sous la
ModelInputclasse, définissez le schéma de vos données de sortie dans une nouvelle classe appeléeModelOutput.class ModelOutput { public string? ImagePath { get; set; } public string? Label { get; set; } public string? PredictedLabel { get; set; } }ModelOutputcontient les propriétés suivantes :-
ImagePathest le chemin complet où l’image est stockée. -
Labelest la catégorie d’origine à laquelle appartient l’image. Il s’agit de la valeur à prédire. -
PredictedLabelest la valeur prédite par le modèle.
Similaire à
ModelInput, seule laPredictedLabelprédiction est nécessaire pour effectuer des prédictions, car elle contient la prédiction effectuée par le modèle. Les propriétésImagePathetLabelsont conservées pour un accès pratique au nom et à la catégorie du fichier image d’origine.-
Définir des chemins d’accès et initialiser des variables
Sous les
usingdirectives, ajoutez le code suivant à :Définissez l’emplacement des ressources.
Initialisez la
mlContextvariable avec une nouvelle instance de MLContext.La classe MLContext est un point de départ pour toutes les opérations ML.NET, et l’initialisation de mlContext crée un environnement ML.NET qui peut être partagé entre les objets de flux de travail de création de modèle. Il est similaire, conceptuellement, à
DbContextentity Framework.
var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var assetsRelativePath = Path.Combine(projectDirectory, "Assets"); MLContext mlContext = new();
Chargement des données
Créer une méthode utilitaire de chargement de données
Les images sont stockées dans deux sous-répertoires. Avant de charger les données, elles doivent être mises en forme dans une liste d’objets ImageData . Pour ce faire, créez la LoadImagesFromDirectory méthode :
static IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
var files = Directory.GetFiles(folder, "*",
searchOption: SearchOption.AllDirectories);
foreach (var file in files)
{
if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png"))
continue;
var label = Path.GetFileName(file);
if (useFolderNameAsLabel)
label = Directory.GetParent(file)?.Name;
else
{
for (int index = 0; index < label.Length; index++)
{
if (!char.IsLetter(label[index]))
{
label = label[..index];
break;
}
}
}
yield return new ImageData()
{
ImagePath = file,
Label = label
};
}
}
La méthode LoadImagesFromDirectory :
- Obtient tous les chemins de fichiers des sous-répertoires.
- Parcourt chaque fichier à l'aide d'une
foreachdéclaration et vérifie que les extensions de fichier sont prises en charge. L’API Classification d’images prend en charge les formats JPEG et PNG. - Obtient l’étiquette du fichier. Si le
useFolderNameAsLabelparamètre est définitruesur , le répertoire parent où le fichier est enregistré est utilisé comme étiquette. Sinon, elle s’attend à ce que l’étiquette soit un préfixe du nom de fichier ou du nom de fichier lui-même. - Crée une instance de
ModelInput.
Préparer les données
Ajoutez le code suivant après la ligne où vous créez la nouvelle instance de MLContext.
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);
IDataView imageData = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey(
inputColumnName: "Label",
outputColumnName: "LabelAsKey")
.Append(mlContext.Transforms.LoadRawImageBytes(
outputColumnName: "Image",
imageFolder: assetsRelativePath,
inputColumnName: "ImagePath"));
IDataView preProcessedData = preprocessingPipeline
.Fit(shuffledData)
.Transform(shuffledData);
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3);
TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);
IDataView trainSet = trainSplit.TrainSet;
IDataView validationSet = validationTestSplit.TrainSet;
IDataView testSet = validationTestSplit.TestSet;
Le code précédent :
Appelle la
LoadImagesFromDirectoryméthode utilitaire pour obtenir la liste des images utilisées pour l’entraînement après l’initialisation de lamlContextvariable.Charge les images dans un
IDataViewen utilisant la méthodeLoadFromEnumerable.Déchique les données à l’aide de la
ShuffleRowsméthode. Les données sont chargées dans l’ordre dans lequel elles ont été lues à partir des répertoires. Le shuffle est effectué pour l’équilibrer.Effectue un prétraitement sur les données avant l’entraînement. Pour ce faire, les modèles Machine Learning s’attendent à ce que les entrées soient au format numérique. Le code de prétraitement crée une
EstimatorChainforme composée desMapValueToKeytransformations etLoadRawImageBytesdes transformations. LaMapValueToKeytransformation prend la valeur catégorielle dans laLabelcolonne, la convertit en valeur numériqueKeyTypeet la stocke dans une nouvelle colonne appeléeLabelAsKey. LeLoadImagesutilise les valeurs de la colonneImagePathainsi que le paramètreimageFolderpour charger des images destinées à l'entraînement.Utilise la
Fitméthode pour appliquer les données à lapreprocessingPipelineEstimatorChainTransformméthode suivie, qui retourne uneIDataViewvaleur contenant les données prétraitées.Fractionne les données en jeux d’apprentissage, de validation et de test.
Pour entraîner un modèle, il est important d’avoir un jeu de données d’entraînement ainsi qu’un jeu de données de validation. Le modèle est entraîné sur le jeu d’entraînement. La façon dont elle effectue des prédictions sur des données invisibles est mesurée par les performances par rapport au jeu de validation. En fonction des résultats de ces performances, le modèle apporte des ajustements à ce qu’il a appris dans un effort d’amélioration. Le jeu de validation peut provenir du fractionnement de votre jeu de données d’origine ou d’une autre source qui a déjà été mis de côté à cet effet.
L’exemple de code effectue deux fractionnements. Tout d’abord, les données prétraite sont fractionnées et 70% sont utilisées pour l’entraînement, tandis que les 30% restants sont utilisés pour la validation. Ensuite, le jeu de validation 30% est divisé en jeux de validation et de test où 90% sont utilisés pour la validation et 10% sont utilisés pour les tests.
Une façon de réfléchir à l’objectif de ces partitions de données consiste à passer un examen. Lorsque vous étudiez pour un examen, vous passez en revue vos notes, livres ou autres ressources pour vous familiariser avec les concepts qui se trouvent à l’examen. C’est à cela que sert le train miniature. Ensuite, vous pouvez passer un examen fictif pour valider vos connaissances. C’est là que le jeu de validation s’avère utile. Vous souhaitez vérifier si vous avez une bonne compréhension des concepts avant de passer l’examen réel. En fonction de ces résultats, vous prenez note de ce sur quoi vous vous êtes trompé ou ce que vous n’avez pas bien compris et intégrez vos modifications à mesure que vous révisez pour l’examen réel. Enfin, vous prenez l’examen. Le jeu de tests est utilisé pour cela. Vous n'avez jamais vu les questions de l'examen et vous utilisez maintenant ce que vous avez appris lors de la formation et de la validation pour appliquer vos connaissances à la tâche en cours.
Affecte les partitions à leurs valeurs respectives pour les données d’apprentissage, de validation et de test.
Définir le pipeline d’entraînement
L’entraînement du modèle se compose de deux étapes. Tout d’abord, l’API Classification d’images est utilisée pour entraîner le modèle. Ensuite, les étiquettes encodées dans la PredictedLabel colonne sont converties en valeur catégorielle d’origine à l’aide de la MapKeyToValue transformation.
var classifierOptions = new ImageClassificationTrainer.Options()
{
FeatureColumnName = "Image",
LabelColumnName = "LabelAsKey",
ValidationSet = validationSet,
Arch = ImageClassificationTrainer.Architecture.ResnetV2101,
MetricsCallback = (metrics) => Console.WriteLine(metrics),
TestOnTrainSet = false,
ReuseTrainSetBottleneckCachedValues = true,
ReuseValidationSetBottleneckCachedValues = true
};
var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions)
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
ITransformer trainedModel = trainingPipeline.Fit(trainSet);
Le code précédent :
Crée une variable pour stocker un ensemble de paramètres obligatoires et facultatifs pour un ImageClassificationTrainer. Un ImageClassificationTrainer prend plusieurs paramètres facultatifs :
-
FeatureColumnNameest la colonne utilisée comme entrée pour le modèle. -
LabelColumnNameest la colonne de la valeur à prédire. -
ValidationSetIDataViewcontient les données de validation. -
Archdéfinit les architectures de modèle préentraînées à utiliser. Ce tutoriel utilise la variante de couche 101 du modèle ResNetv2. -
MetricsCallbacklie une fonction pour suivre la progression pendant l’entraînement. -
TestOnTrainSetindique au modèle de mesurer les performances par rapport au jeu d’entraînement lorsqu’aucun jeu de validation n’est présent. -
ReuseTrainSetBottleneckCachedValuesindique au modèle s’il faut utiliser les valeurs mises en cache de la phase de goulot d’étranglement dans les exécutions suivantes. La phase de goulot d’étranglement est un calcul pass-through unique qui est gourmand en calcul la première fois qu’elle est effectuée. Si les données d’apprentissage ne changent pas et que vous souhaitez expérimenter à l’aide d’un nombre différent d’époques ou de tailles de lot, l’utilisation des valeurs mises en cache réduit considérablement la durée nécessaire à l’apprentissage d’un modèle. -
ReuseValidationSetBottleneckCachedValuesest similaire uniquement àReuseTrainSetBottleneckCachedValuescela dans ce cas, il s’agit du jeu de données de validation.
-
Définit le pipeline d’entraînement qui se compose à la
EstimatorChainfois dumapLabelEstimatoret du ImageClassificationTrainer.Utilise la
Fitméthode pour entraîner le modèle.
Utiliser le modèle
Maintenant que vous avez entraîné le modèle, il est temps de l’utiliser pour classifier des images.
Créez une méthode utilitaire appelée OutputPrediction pour afficher les informations de prédiction dans la console.
static void OutputPrediction(ModelOutput prediction)
{
string? imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Classifier une seule image
Créez une méthode appelée
ClassifySingleImagepour effectuer et générer une prédiction d’image unique.static void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel); ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data, reuseRowObject: true).First(); ModelOutput prediction = predictionEngine.Predict(image); Console.WriteLine("Classifying single image"); OutputPrediction(prediction); }La méthode
ClassifySingleImage:- Crée un
PredictionEngineélément à l’intérieur de laClassifySingleImageméthode. IlPredictionEngines’agit d’une API pratique qui vous permet de transmettre, puis d’effectuer une prédiction sur une seule instance de données. - Pour accéder à une instance unique
ModelInput, convertit ladataIDataViewvaleur en une méthode à l’aide deIEnumerablelaCreateEnumerableméthode, puis obtient la première observation. - Utilise la
Predictméthode pour classifier l’image. - Génère la prédiction dans la console avec la
OutputPredictionméthode.
- Crée un
Appelez après avoir appelé
ClassifySingleImagelaFitméthode à l’aide du jeu de tests d’images.ClassifySingleImage(mlContext, testSet, trainedModel);
Classifier plusieurs images
Créez une méthode appelée
ClassifyImagespour effectuer et générer plusieurs prédictions d’image.static void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { IDataView predictionData = trainedModel.Transform(data); IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10); Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); } }La méthode
ClassifyImages:- Crée un
IDataViewconteneur des prédictions à l’aide de laTransformméthode. - Pour itérer sur les prédictions, convertit le
predictionDataIDataViewen unIEnumerableen utilisant la méthodeCreateEnumerable, puis obtient les 10 premières observations. - Itère et génère les étiquettes d’origine et prédites pour les prédictions.
- Crée un
Appelez
ClassifyImagesaprès avoir appelé la méthodeClassifySingleImage()à l’aide du jeu de tests d’images.ClassifyImages(mlContext, testSet, trainedModel);
Exécuter l’application
Exécutez votre application console. La sortie doit être similaire à la sortie suivante.
Note
Vous pouvez voir des avertissements ou des messages de traitement. Ces messages ont été supprimés des résultats suivants pour plus de clarté. Par souci de concision, la sortie a été condensée.
Phase de goulot d’étranglement
Aucune valeur n’est imprimée pour le nom de l’image, car les images sont chargées en tant qu’il byte[] n’existe donc aucun nom d’image à afficher.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Phase d’entraînement
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Classifier la sortie des images
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
Lors de l’inspection de l’image 7001-220.jpg , vous pouvez vérifier qu’elle n’est pas fissurée, comme le modèle prédit.

Félicitations! Vous avez maintenant créé un modèle d’apprentissage profond pour classifier des images.
Améliorer le modèle
Si vous n’êtes pas satisfait des résultats du modèle, vous pouvez essayer d’améliorer ses performances en essayant certaines des approches suivantes :
- Plus de données sont les suivantes : plus un modèle apprend, mieux il effectue. Téléchargez le jeu de données SDNET2018 complet et utilisez-le pour effectuer l’apprentissage.
- Augmentez les données : une technique courante pour ajouter de la variété aux données consiste à augmenter les données en prenant une image et en appliquant différentes transformations (rotation, retourne, shift, rognage). Cela ajoute des exemples plus variés pour le modèle à partir duquel apprendre.
- Entraîner pendant plus longtemps : plus vous effectuez l’apprentissage, plus le modèle sera ajusté. L’augmentation du nombre d’époques peut améliorer les performances de votre modèle.
- Expérimentez les hyper-paramètres : en plus des paramètres utilisés dans ce didacticiel, d’autres paramètres peuvent être paramétrés pour améliorer potentiellement les performances. La modification du taux d’apprentissage, qui détermine l’ampleur des mises à jour apportées au modèle après chaque époque, peut améliorer les performances.
- Utilisez une architecture de modèle différente : selon l’apparence de vos données, le modèle qui peut mieux apprendre ses fonctionnalités peut différer. Si vous n’êtes pas satisfait des performances de votre modèle, essayez de modifier l’architecture.
Étapes suivantes
Dans ce tutoriel, vous avez appris à créer un modèle d’apprentissage profond personnalisé à l’aide de l’apprentissage de transfert, d’un modèle TensorFlow de classification d’images préentraîné et de l’API ML.NET Classification d’images pour classifier les images de surfaces concrètes comme craquelées ou non brouillées.
Passez au tutoriel suivant pour en savoir plus.
Voir aussi
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.