Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'applique à :✅ Fabric Data Engineering and Data Science
L'API Fabric Livy vous permet d'envoyer des travaux batch et de session Spark directement vers les ressources de calcul Spark de Fabric à partir d'un client distant, sans utiliser le portail Fabric. Dans cet article, vous allez créer un Lakehouse, vous authentifier avec un jeton Microsoft Entra, découvrir le point de terminaison de l’API Livy et envoyer et surveiller un travail de session Spark.
Prérequis
Capacité Premium ou en essai de Fabric avec un Lakehouse
Activer le paramètre d’administrateur de locataire pour l’API Livy
Un client distant tel que Visual Studio Code avec le support des notebooks Jupyter, PySpark et Microsoft Authentication Library (MSAL) pour Python
Soit un jeton d'application Microsoft Entra. Registrer une application avec le Microsoft identity platform
Ou un jeton SPN (principal de service) Microsoft Entra. Ajoutez et gérez les identifiants de l’application dans Microsoft Entra ID
Choisir un client d’API REST
Vous pouvez interagir avec l’API Livy à partir de n’importe quel client qui prend en charge les requêtes HTTP, y compris des outils tels que curl ou n’importe quel langage avec une bibliothèque HTTP. Les exemples de cet article utilisent Visual Studio Code avec Jupyter Notebooks, PySpark et le Microsoft Authentication Library (MSAL) pour Python.
Comment autoriser les demandes d’API Livy
Pour utiliser l’API Livy, vous devez authentifier vos demandes à l’aide de Microsoft Entra ID. Il existe deux méthodes d’autorisation disponibles :
Entra SPN Token (Principal de service) : l’application s’authentifie en son propre nom à l’aide d’informations d’identification telles qu’un secret client ou un certificat. Cette méthode convient aux processus automatisés et aux services en arrière-plan où aucune interaction utilisateur n’est requise.
Jeton d’application Entra (délégué) : l’application agit pour le compte d’un utilisateur connecté. Cette méthode convient lorsque vous souhaitez que l’application accède aux ressources avec les autorisations de l’utilisateur authentifié.
Choisissez la méthode d’autorisation qui correspond le mieux à votre scénario et suivez la section correspondante ci-dessous.
Comment autoriser les demandes d’API Livy avec un jeton SPN Microsoft Entra
Pour utiliser Fabric API, notamment l’API Livy, vous devez d’abord créer une application Microsoft Entra et créer un secret et utiliser ce secret dans votre code. Votre application doit être inscrite et configurée correctement pour effectuer des appels d’API sur Fabric. Pour plus d’informations, consultez Ajouter et gérer les informations d’identification de l’application dans Microsoft Entra ID
Après avoir créé l’enregistrement de l’application, créez un secret client.
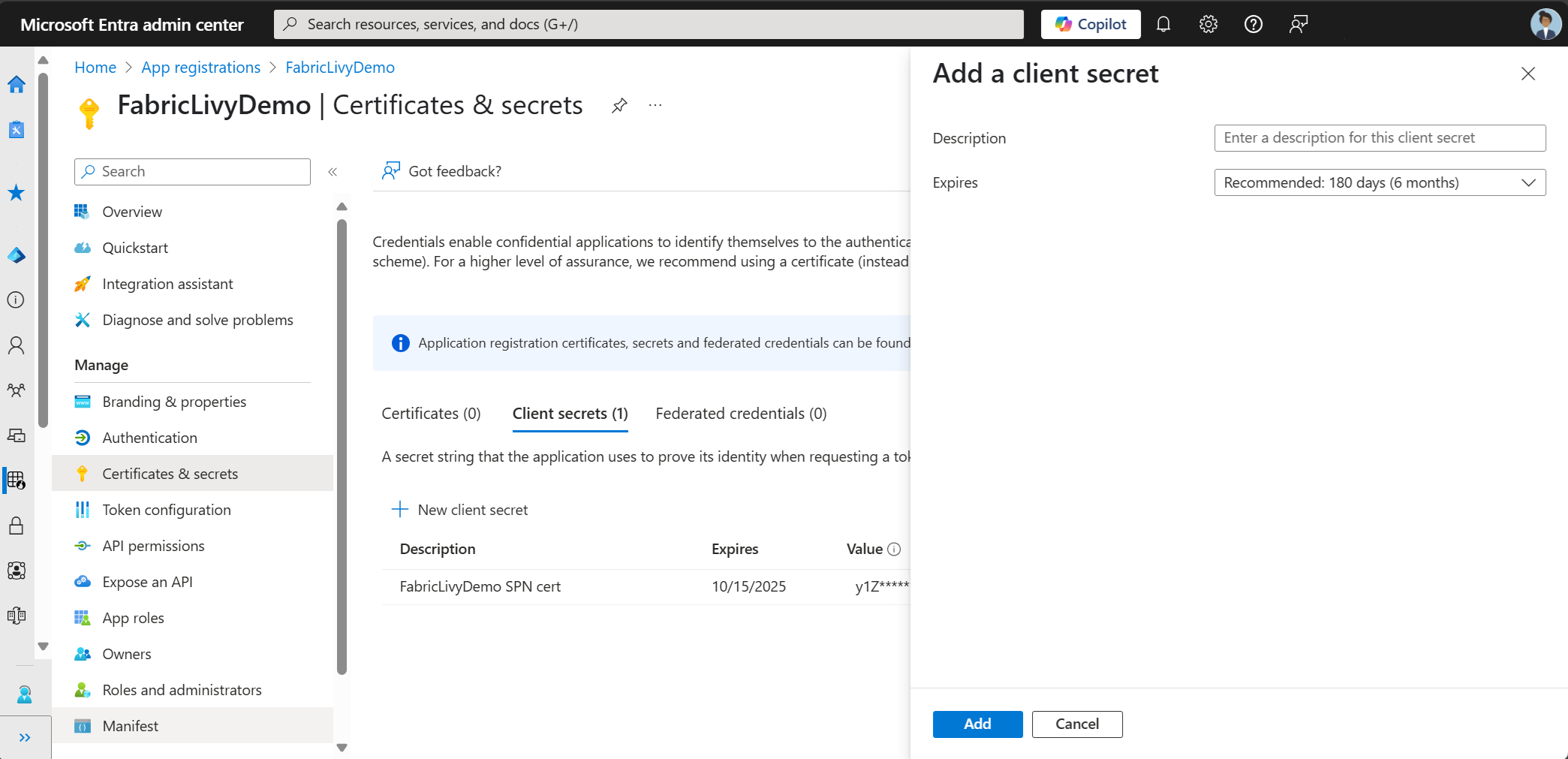
Lorsque vous créez le secret client, veillez à copier la valeur. Vous en avez besoin plus tard dans le code, et le secret ne peut pas être vu à nouveau. Vous avez également besoin de l’ID d’application (client) et de l’annuaire (ID de locataire) en plus du secret dans votre code.
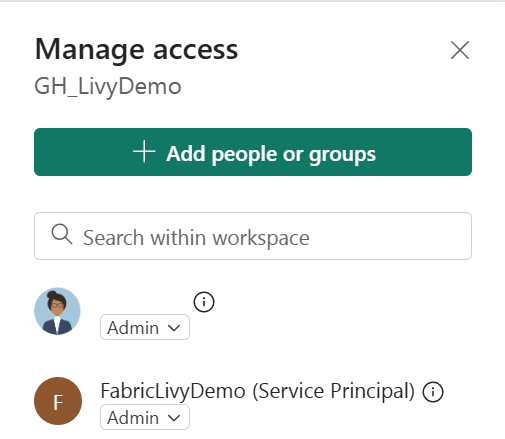
Ensuite, ajoutez le principal de service à votre espace de travail.
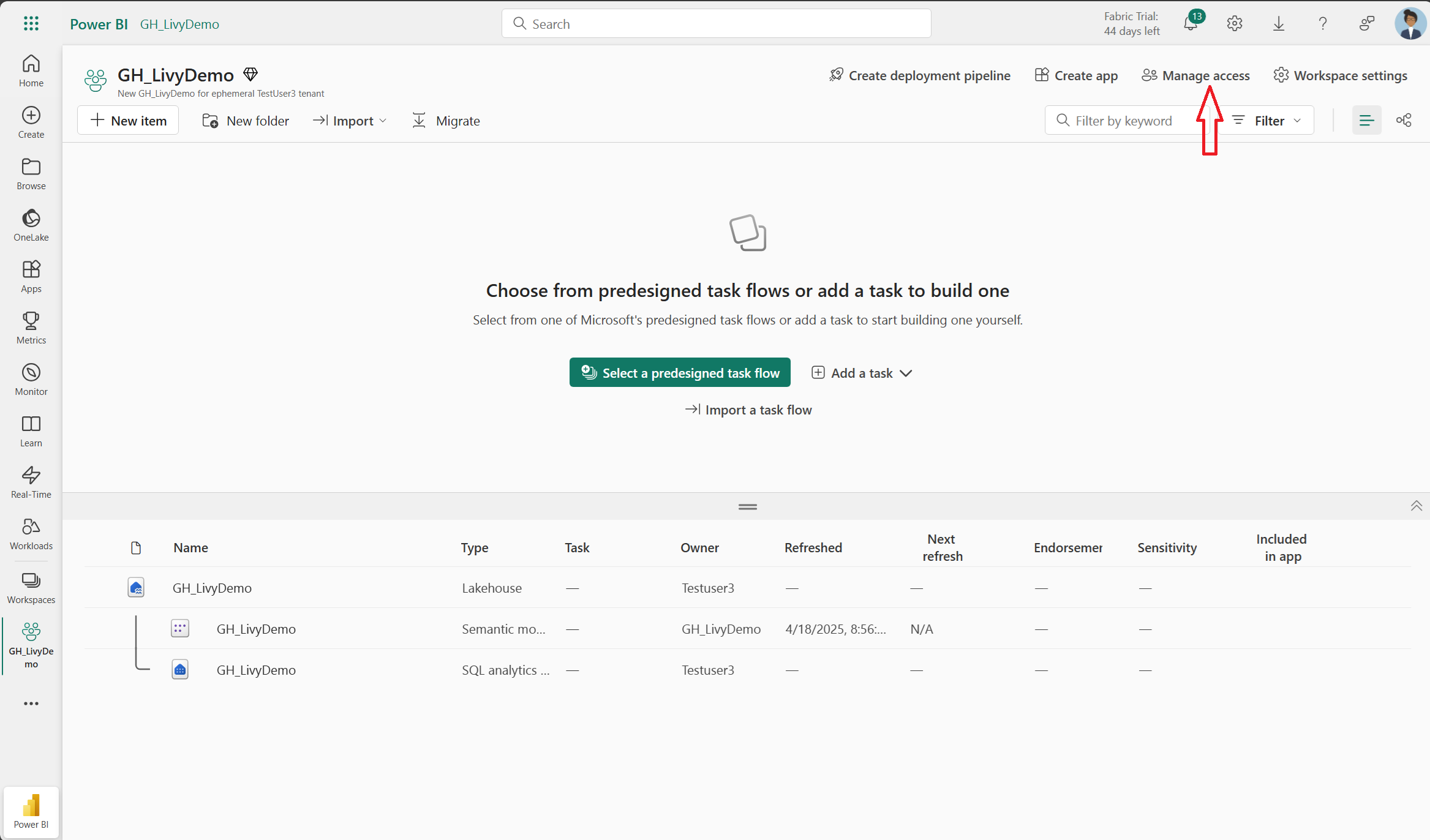
Recherchez l’application Microsoft Entra à l’aide de l’ID ou du nom de l’application (client), ajoutez-la à l’espace de travail et vérifiez que le principal de service dispose des autorisations Contributeur.



Comment autoriser les demandes d’API Livy avec un jeton d’application Entra
Pour utiliser Fabric API, y compris l’API Livy, vous devez d’abord créer une application Microsoft Entra et obtenir un jeton. Votre application doit être inscrite et configurée correctement pour effectuer des appels d’API sur Fabric. Pour plus d’informations, consultez Registrer une application avec le Microsoft identity platform.
Les autorisations d’étendue Microsoft Entra suivantes sont requises pour exécuter des travaux d’API Livy :

Étendues requises
| Étendue | Description |
|---|---|
Lakehouse.Execute.All |
Exécutez des opérations dans Fabric lakehouses. |
Lakehouse.Read.All |
Lire les métadonnées lakehouse. |
Code.AccessFabric.All |
Permet d’obtenir des jetons d’accès à Microsoft Fabric. Obligatoire pour toutes les opérations d’API Livy. |
Code.AccessStorage.All |
Permet d’obtenir des jetons d’accès à OneLake et au stockage Azure. Requis pour la lecture et l’écriture de données dans les lakehouses. |
Domaines de code optionnels.*
Ajoutez ces étendues uniquement si vos travaux Spark doivent accéder aux services de Azure correspondants au moment de l’exécution.
| Étendue | Description | Quand utiliser |
|---|---|---|
Code.AccessAzureKeyvault.All |
Permet d’obtenir des jetons d’accès à Azure Key Vault. | Votre code Spark récupère des secrets, des clés ou des certificats à partir de Azure Key Vault. |
Code.AccessAzureDataLake.All |
Permet d’obtenir des jetons d’accès à Azure Data Lake Storage Gen1. | Votre code Spark lit à partir de ou écrit dans des comptes Azure Data Lake Storage Gen1. |
Code.AccessAzureDataExplorer.All |
Permet d’obtenir des jetons d’accès à Azure Data Explorer (Kusto). | Votre code Spark effectue des requêtes ou ingère des données vers et depuis des clusters Azure Data Explorer. |
Code.AccessSQL.All |
Permet d’obtenir des jetons d’accès à Azure SQL. | Votre code Spark doit se connecter aux bases de données Azure SQL. |
Lorsque vous inscrivez votre application, vous avez besoin de l’ID d’application (client) et de l’ID d’annuaire (locataire).

L’utilisateur authentifié appelant l’API Livy doit être membre de l’espace de travail où se trouvent à la fois l’API et les éléments de source de données avec un rôle Collaborateur. Pour plus d’informations, consultez Donner aux utilisateurs l’accès aux espaces de travail.
Compréhension des périmètres Code.* pour l’API Livy
Lorsque vos travaux Spark s’exécutent via l’API Livy, les Code.* étendues contrôlent les services externes auxquels le runtime Spark peut accéder pour le compte de l’utilisateur authentifié. Deux sont nécessaires ; le reste est facultatif en fonction de votre charge de travail.
Étendues des codes requis.*
| Étendue | Description |
|---|---|
Code.AccessFabric.All |
Permet d’obtenir des jetons d’accès à Microsoft Fabric. Obligatoire pour toutes les opérations d’API Livy. |
Code.AccessStorage.All |
Permet d’obtenir des jetons d’accès à OneLake et au stockage Azure. Requis pour la lecture et l’écriture de données dans les lakehouses. |
Domaines de code optionnels.*
Ajoutez ces étendues uniquement si vos travaux Spark doivent accéder aux services de Azure correspondants au moment de l’exécution.
| Étendue | Description | Quand utiliser |
|---|---|---|
Code.AccessAzureKeyvault.All |
Permet d’obtenir des jetons d’accès à Azure Key Vault. | Votre code Spark récupère des secrets, des clés ou des certificats à partir de Azure Key Vault. |
Code.AccessAzureDataLake.All |
Permet d’obtenir des jetons d’accès à Azure Data Lake Storage Gen1. | Votre code Spark lit à partir de ou écrit dans des comptes Azure Data Lake Storage Gen1. |
Code.AccessAzureDataExplorer.All |
Permet d’obtenir des jetons d’accès à Azure Data Explorer (Kusto). | Votre code Spark effectue des requêtes ou ingère des données vers et depuis des clusters Azure Data Explorer. |
Code.AccessSQL.All |
Permet d’obtenir des jetons d’accès à Azure SQL. | Votre code Spark doit se connecter aux bases de données Azure SQL. |
Remarque
Les étendues Lakehouse.Execute.All et Lakehouse.Read.All sont également requises, mais ne font pas partie de la famille Code.*. Ils accordent l’autorisation d’exécuter des opérations dans et de lire des métadonnées à partir de Fabric lakehouses respectivement.
Guide pratique pour découvrir le point de terminaison de l’API Livy Fabric
Un artefact Lakehouse est requis pour accéder au point de terminaison Livy. Une fois le Lakehouse créé, le point de terminaison de l’API Livy peut se trouver dans le panneau des paramètres.

Le point de terminaison de l’API Livy suit ce modèle :
https://api.fabric.microsoft.com/v1/workspaces/><ws_id>/lakehouses/<lakehouse_id>/livyapi/versions/2023-12-01/
L’URL est ajoutée avec des <sessions> ou des <lots> en fonction de ce que vous choisissez.
Télécharger les fichiers Swagger de l’API Livy
Les fichiers swagger complets de l’API Livy sont disponibles ici.
Sessions de concurrence élevée
La prise en charge de la concurrence élevée (HC) permet l’exécution simultanée de Spark en permettant aux clients d’acquérir plusieurs contextes d’exécution indépendants, appelés sessions de concurrence élevée.
Chaque session HC représente un contexte d’exécution logique qui correspond à un REPL Spark (Boucle de Lecture-Évaluation-Impression). Les instructions Spark soumises sous différentes sessions HC peuvent s’exécuter simultanément.
Cela permet :
- Exécution parallèle entre les sessions HC
- Utilisation prévisible des ressources
- Isolation entre les requêtes simultanées
- Réduction de la surcharge par rapport à la création d’une nouvelle session par requête
L’utilisation d’une session unique pour toutes les requêtes entraîne l’exécution séquentielle des instructions. La création d’une nouvelle session pour chaque requête introduit une surcharge inutile et une sous-utilisation des ressources.
Remarque
L’acquisition de session HC n’est pas idempotente. Plusieurs demandes d’acquisition avec le même sessionTag retournent différents ID de session HC, même lorsqu'elles sont soutenues par la même session Livy sous-jacente.
Pour obtenir une procédure pas à pas avec un exemple de code, consultez Commencez avec l’API Livy pour les sessions de haute concurrence de Fabric. Pour obtenir une vue d’ensemble conceptuelle, consultez Support de la concurrence dans l'API Fabric Livy.
Soumettre des travaux de l’API Livy
Maintenant que la configuration de l’API Livy est terminée, vous pouvez choisir d’envoyer des tâches de traitement par lots ou de session.
- Soumettre des travaux par session en utilisant l’API Livy
- Soumettre des travaux par lot en utilisant l’API Livy
Intégration avec des environnements Fabric
Par défaut, cette session d’API Livy s’exécute sur le pool de démarrage par défaut de l’espace de travail. Vous pouvez également utiliser Fabric environnements Create, configurer et utiliser un environnement dans Microsoft Fabric pour personnaliser le pool Spark utilisé par la session API Livy pour ces travaux Spark.
Pour utiliser un environnement Fabric dans une session Livy Spark, mettez à jour le json pour inclure cette charge utile.
create_livy_session = requests.post(livy_base_url, headers = headers, json={
"conf" : {
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID""}"}
}
)
Pour utiliser un environnement Fabric dans une session batch Livy Spark, mettez à jour la charge utile json comme indiqué ici :
payload_data = {
"name":"livybatchdemo_with"+ newlakehouseName,
"file":"abfss://YourABFSPathToYourPayload.py",
"conf": {
"spark.targetLakehouse": "Fabric_LakehouseID",
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID"\"}" # Replace "EnvironmentID" with your environment ID, or remove this line to use starter pools instead of an environment
}
}
Comment surveiller l’historique des requêtes
Vous pouvez utiliser le hub de surveillance pour afficher vos soumissions précédentes de l’API Livy et déboguer les erreurs de soumission.

Contenu connexe
- Documentation de l’API REST Apache Livy
- Commencez avec les paramètres d’administration de votre capacité de Fabric
- paramètres d’administration de l’espace de travail Apache Spark dans Microsoft Fabric
- Registrer une application avec le Microsoft identity platform
- Microsoft Entra vue d’ensemble de l’autorisation et du consentement
- Périmètres de l’API REST de Fabric
- Vue d’ensemble de la supervision d'Apache Spark
- Détails sur les applications Apache Spark