Migrer une définition de tâche Spark d’Azure Synapse vers Fabric
Pour migrer des définitions de tâche Spark d’Azure Synapse vers Fabric, vous avez deux options différentes :
- Option 1 : Créez une définition de tâche Spark manuellement dans Fabric.
- Option 2 : Vous pouvez utiliser un script pour exporter des définitions de tâche Spark à partir d’Azure Synapse et les importer dans Fabric à l’aide de l’API.
Pour plus d’informations sur les définitions de tâche Spark, consultez les différences entre Azure Synapse Spark et Fabric.
Prérequis
Si vous n’en avez pas encore, créez un espace de travail Fabric dans votre locataire.
Option 1 : Créer une définition de tâche Spark manuellement
Pour exporter une définition de tâche Spark depuis Azure Synapse :
- Ouvrez Synapse Studio : connectez-vous à Azure. Accédez à votre espace de travail Azure Synapse et ouvrez Synapse Studio.
- Localisez la tâche Spark Python/Scala/R : recherchez et identifiez la définition de tâche Spark Python/Scala/R que vous voulez migrer.
- Exportez la configuration de la définition de tâche :
- Dans Synapse Studio, ouvrez la définition de tâche Spark.
- Exportez ou notez les paramètres de configuration, notamment l’emplacement du fichier de script, les dépendances, les paramètres et tous les autres détails pertinents.
Pour créer une définition de tâche Spark (SJD) basée sur les informations SJD exportées dans Fabric :
- Accédez à l’espace de travail Fabric : connectez-vous à Fabric et accédez à votre espace de travail.
- Créez une définition de tâche Spark dans Fabric :
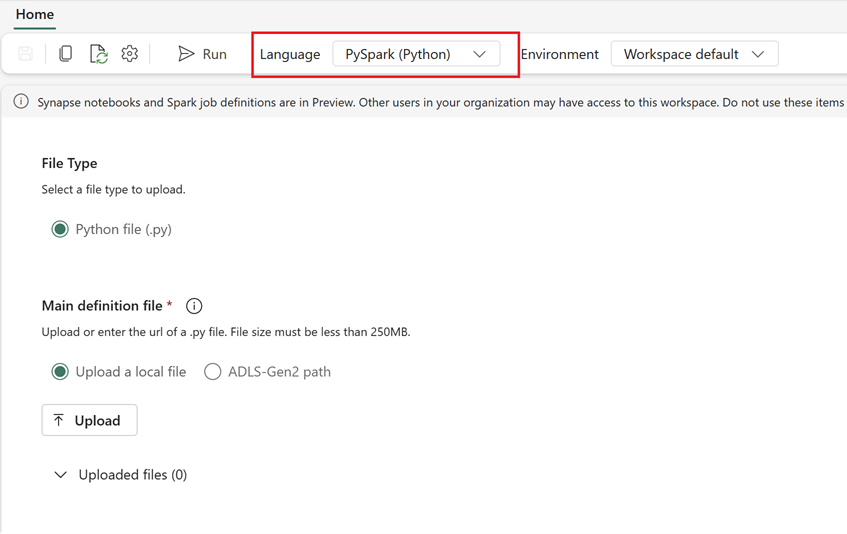
- Dans Fabric, accédez à la page d’accueil Engineering données.
- Sélectionnez Définition de tâche Spark.
- Configurez la tâche avec les informations que vous avez exportées de Synapse, notamment l’emplacement du script, les dépendances, les paramètres et les paramètres de cluster.
- Adaptez et testez : Si nécessaire, adaptez le script ou la configuration à l’environnement Fabric. Testez la tâche dans Fabric pour vous assurer qu’elle s’exécute correctement.
Une fois la définition de tâche Spark créée, validez les dépendances :
- Veillez à utiliser la même version Spark.
- Validez l’existence du fichier de définition principal.
- Validez l’existence des fichiers, dépendances et ressources référencés.
- Services liés, connexions de source de données et points de montage.
Découvrez plus en détail comment créer une définition de tâche Apache Spark dans Fabric.
Option 2 : Utiliser l’API Fabric
Suivez ces étapes clés pour la migration :
- Conditions préalables.
- Étape 1 : Exportez la définition de tâche Spark d’Azure Synapse vers OneLake (.json).
- Étape 2 : Importez automatiquement la définition de tâche Spark dans Fabric à l’aide de l’API Fabric.
Prérequis
Les prérequis incluent les actions à prendre en compte avant de commencer la migration de la définition de tâche Spark vers Fabric.
- Un espace de travail Fabric.
- Si vous n’en avez pas encore, créez un lakehouse Fabric dans votre espace de travail.
Étape 1 : Exporter la définition de tâche Spark de l’espace de travail Azure Synapse
L’étape 1 consiste à exporter la définition de tâche Spark de l’espace de travail Azure Synapse vers OneLake au format json. Ce processus est le suivant :
- 1.1) Importez un notebook de migration de définition de tâche Spark vers l’espace de travail Fabric. Ce notebook exporte toutes les définitions de tâche Spark d’un espace de travail Azure Synapse donné vers un répertoire intermédiaire dans OneLake. L’API Synapse est utilisée pour exporter les définitions de tâche Spark.
- 1.2) Configurez les paramètres dans la première commande pour exporter la définition de tâche Spark vers un stockage intermédiaire (OneLake). Cette opération exporte uniquement le fichier de métadonnées json. L’extrait de code suivant est utilisé pour configurer les paramètres source et de destination. Veillez à les remplacer par vos propres valeurs.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
- 1.3) Exécutez les deux premières cellules du notebook d’exportation/importation pour exporter les métadonnées de définition de tâche Spark vers OneLake. Une fois les cellules terminées, cette structure de dossiers sous le répertoire de sortie intermédiaire est créée.

Étape 2 : Importer la définition de tâche Spark dans Fabric
L’étape 2 consiste à importer les définitions de tâche Spark d’un stockage intermédiaire vers l’espace de travail Fabric. Ce processus est le suivant :
- 2.1) Validez les configurations de l’étape 1.2 pour vous assurer que le préfixe et l’espace de travail appropriés sont indiqués pour importer les définitions de tâche Spark.
- 2.2) Exécutez la troisième cellule du notebook d’exportation/importation pour importer toutes les définitions de tâche Spark à partir de l’emplacement intermédiaire.
Remarque
L’option d’exportation génère un fichier de métadonnées json. Vérifiez que les fichiers exécutables, les fichiers de référence et les arguments de définition de tâche Spark sont accessibles dans Fabric.
Contenu connexe
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour