Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article traite de l’actualisation incrémentielle des données dans Dataflow Gen2 pour Data Factory de Microsoft Fabric. Lorsque vous utilisez des dataflows pour l’ingestion et la transformation des données, vous devez parfois actualiser uniquement les données nouvelles ou mises à jour, en particulier lorsque vos données augmentent.
L’actualisation incrémentielle vous aide à :
- Réduire les temps d’actualisation
- Rendre les opérations plus fiables en évitant les processus de longue durée
- Utiliser moins de ressources
Prerequisites
Pour utiliser l’actualisation incrémentielle dans Dataflow Gen2, vous avez besoin des éléments suivants :
- Capacité du réseau de tissu
- Source de données qui prend en charge le pliage (recommandé) et contient une colonne Date/DateTime pour le filtrage des données
- Destination de données prenant en charge l’actualisation incrémentielle (voir Prise en charge de la destination)
- Passez en revue les limitations avant de commencer
Prise en charge de destination
Ces destinations de données prennent en charge l’actualisation incrémentielle :
- Fabric Lakehouse
- Fabric Warehouse
- Azure SQL Database
Vous pouvez également utiliser d’autres destinations avec l’actualisation incrémentielle. Créez une deuxième requête qui référence les données intermédiaires pour mettre à jour votre destination. Cette approche vous permet toujours d’utiliser l’actualisation incrémentielle pour réduire les données qui nécessitent le traitement à partir du système source. Toutefois, vous devez effectuer une actualisation complète des données intermédiaires vers votre destination finale.
En outre, la configuration de destination par défaut n’est pas prise en charge pour l’actualisation incrémentielle. Vous devez définir explicitement la destination dans vos paramètres de requête.
Comment utiliser l’actualisation incrémentielle
Créez un dataflow Gen2 ou ouvrez-en un existant.
Dans l’éditeur de flux de données, créez une requête qui obtient les données que vous souhaitez actualiser de manière incrémentielle.
Vérifiez l’aperçu des données pour vous assurer que votre requête retourne des données avec une colonne DateTime, Date ou DateTimeZone pour le filtrage.
Assurez-vous que votre requête est entièrement pliée, ce qui signifie que la requête est envoyée au système source. S’il n’est pas entièrement plié, modifiez votre requête de façon à ce qu’elle le fasse. Vous pouvez vérifier si votre requête se plie entièrement en examinant les étapes de requête dans l’éditeur de requête.
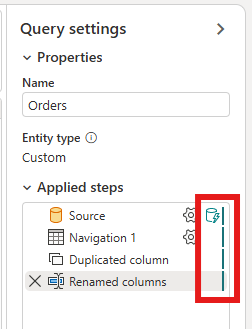
Cliquez avec le bouton droit sur la requête et sélectionnez Actualisation incrémentielle.
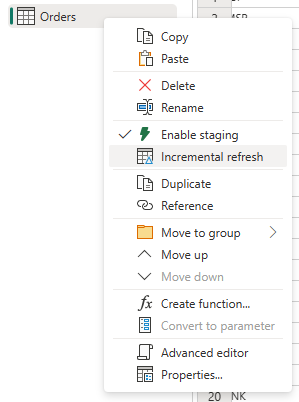
Configurez les paramètres requis pour l’actualisation incrémentielle.
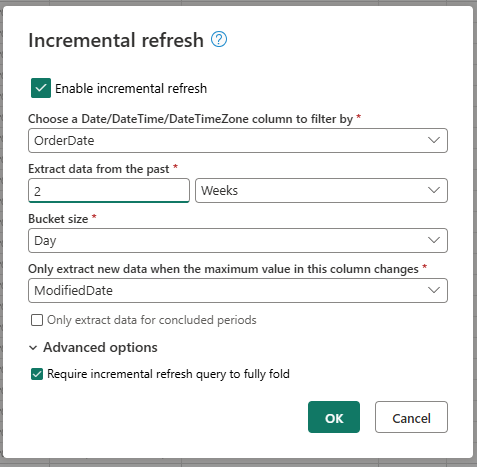
- Choisir une colonne DateTime avec laquelle filtrer.
- Extraire des données du passé.
- Taille du compartiment.
- Extraire uniquement les nouvelles données quand la valeur maximale de cette colonne est modifiée.
Configurez les paramètres avancés, le cas échéant.
- Exiger une requête d’actualisation incrémentielle pour un repli complet.
Sélectionnez OK pour enregistrer vos paramètres.
Si vous le souhaitez, configurez une destination de données pour la requête. Effectuez cette étape avant la première actualisation incrémentielle, sinon votre destination ne contiendra que les données modifiées de façon incrémentielle depuis la dernière actualisation.
Publiez Dataflow Gen2.
Après avoir configuré l’actualisation incrémentielle, le flux de données actualise automatiquement les données de manière incrémentielle en fonction de vos paramètres. Le flux de données obtient uniquement les données qui ont changé depuis la dernière actualisation, de sorte qu’elles s’exécutent plus rapidement et utilisent moins de ressources.
Comment fonctionne l’actualisation incrémentielle en arrière-plan
L’actualisation incrémentielle divise vos données en compartiments en fonction de la colonne DateTime. Chaque compartiment contient des données qui ont changé depuis la dernière actualisation. Le flux de données sait ce qui a changé en vérifiant la valeur maximale dans la colonne que vous avez spécifiée.
Si la valeur maximale a changé pour ce compartiment, le flux de données obtient l’ensemble du compartiment et remplace les données dans la destination. Si la valeur maximale n’a pas changé, le dataflow n’obtient aucune donnée. Voici comment il fonctionne pas à pas.
Première étape : évaluer les modifications
Lorsque votre dataflow s’exécute, il vérifie d’abord ce qui a changé dans votre source de données. Elle examine la valeur maximale dans votre colonne DateTime et la compare à la valeur maximale de la dernière actualisation.
Si la valeur maximale a changé (ou s’il s’agit de votre première actualisation), le flux de données marque ce compartiment comme étant « modifié » et le traitera. Si la valeur maximale est la même, le flux de données ignore entièrement ce compartiment.
Deuxième étape : Obtenir les données
À présent, le flux de données obtient les données de chaque compartiment modifié. Il traite plusieurs compartiments en même temps pour accélérer les choses.
Le flux de données charge ces données dans une zone de préparation. Elle obtient uniquement les données qui se trouvent dans l’intervalle de temps du compartiment, ce qui signifie uniquement les données qui ont réellement changé depuis votre dernière actualisation.
Dernière étape : remplacer les données dans la destination
Le flux de données met à jour votre destination avec les nouvelles données. Il utilise une approche de « remplacement » : tout d’abord, il supprime les anciennes données pour ce compartiment spécifique, puis insère les nouvelles données.
Ce processus affecte uniquement les données dans l’intervalle de temps du bucket. Les données qui se trouvent en dehors de cette plage (comme les données historiques plus anciennes) restent inchangées.
Explication des paramètres d'actualisation incrémentielle
Pour configurer l’actualisation incrémentielle, vous devez spécifier ces paramètres.
Paramètres généraux :
Ces paramètres sont requis et spécifient la configuration de base pour l’actualisation incrémentielle.
Choisir une colonne DateTime avec laquelle filtrer
Ce paramètre obligatoire spécifie la colonne que les flux de données utilisent pour filtrer les données. Cette colonne doit être une colonne DateTime, Date ou DateTimeZone. Le flux de données utilise cette colonne pour filtrer les données et obtient uniquement les données modifiées depuis la dernière actualisation.
Extraire des données du passé
Ce paramètre requis spécifie la distance à laquelle le flux de données doit extraire des données. Ce paramètre obtient le chargement initial des données. Le flux de données obtient toutes les données du système source dans l’intervalle de temps spécifié. Les valeurs possibles sont les suivantes :
- x jours
- x semaines
- x mois
- x trimestres
- x ans
Par exemple, si vous spécifiez 1 mois, le flux de données obtient toutes les nouvelles données du système source au cours du dernier mois.
Taille du seau
Ce paramètre requis spécifie la taille des compartiments que le flux de données utilise pour filtrer les données. Le flux de données divise les données en compartiments en fonction de la colonne DateTime. Chaque compartiment contient des données qui ont changé depuis la dernière actualisation. La taille du compartiment détermine la quantité de données traitées dans chaque itération :
- Une taille de compartiment plus petite signifie que le flux de données traite moins de données dans chaque itération, mais nécessite davantage d’itérations pour traiter toutes les données.
- Une taille de compartiment plus grande signifie que le flux de données traite plus de données dans chaque itération, mais nécessite moins d’itérations pour traiter toutes les données.
Extraire uniquement les nouvelles données quand la valeur maximale de cette colonne a été modifiée
Ce paramètre requis spécifie la colonne utilisée par le flux de données pour déterminer si les données ont changé. Le flux de données compare la valeur maximale de cette colonne à la valeur maximale de l’actualisation précédente. Si la valeur maximale a changé, le flux de données obtient les données modifiées depuis la dernière actualisation. Si la valeur maximale n’a pas changé, le dataflow n’obtient aucune donnée.
Extraire uniquement les données des périodes terminées
Ce paramètre facultatif spécifie si le flux de données doit uniquement extraire des données pour des périodes terminées. Si vous activez ce paramètre, le flux de données extrait uniquement les données pour les périodes qui se sont terminées. Le flux de données extrait uniquement les données pour les périodes qui sont terminées et ne contiennent aucune donnée future. Si vous désactivez ce paramètre, le flux de données extrait des données pour toutes les périodes, y compris les périodes qui ne sont pas terminées et contiennent des données futures.
Par exemple, si vous avez une colonne DateTime qui contient la date de la transaction et que vous souhaitez uniquement actualiser les mois complets, vous pouvez activer ce paramètre avec la taille du compartiment de month. Le flux de données extrait uniquement les données des mois complets et n’extrait pas les données pendant des mois incomplets.
Paramètres avancés
Certains paramètres sont considérés comme avancés et ne sont pas nécessaires dans la plupart des scénarios.
Exiger une requête d’actualisation incrémentielle pour un repli complet
Ce paramètre contrôle si votre requête d’actualisation incrémentielle doit « entièrement plier ». Lorsqu’une requête est entièrement pliée, elle est entièrement envoyée à votre système source pour traitement.
Si vous activez ce paramètre, votre requête doit être entièrement pliable. Si vous la désactivez, la requête peut être partiellement traitée par le flux de données au lieu de votre système source.
Nous vous recommandons vivement de conserver ce paramètre activé. Cela garantit que, après avoir enregistré le flux de données, nous vérifions si le pliage de la requête vers la source est réalisable. Si cette validation échoue, votre dataflow peut souffrir d’une réduction des performances et peut finir par récupérer des données inutiles et non filtrées.
Dans certains cas, vous pouvez voir un indicateur de repli vert lors de la création. Toutefois, lorsque nous validons la définition finale du flux de données, le pliage peut ne plus être possible ; Par exemple, si une étape telle que Table.SelectRows interrompt le pliage. Cela peut entraîner une erreur de validation.
Limitations
La prise en charge de Lakehouse est fournie avec certaines mises en garde supplémentaires
Lorsque vous utilisez lakehouse comme destination de données, tenez compte de ces limitations :
Le nombre maximal d’évaluations simultanées est de 10. Cela signifie que le flux de données ne peut évaluer que 10 compartiments en même temps. Si vous avez plus de 10 compartiments, vous devez limiter le nombre de compartiments ou limiter le nombre d’évaluations simultanées.
Lorsque vous écrivez dans un lakehouse, le flux de données suit les fichiers qu’il écrit. Cela suit les pratiques standard d'un "lakehouse".
Mais voici le problème : si d'autres outils (comme Spark) ou processus écrivent également dans la même table, ils peuvent interférer avec la mise à jour incrémentielle. Nous vous recommandons d’éviter d’autres auteurs lors de l’utilisation de l’actualisation incrémentielle.
Si vous devez utiliser d'autres rédacteurs, assurez-vous qu'ils ne sont pas en conflit avec le processus de rafraîchissement incrémentiel. En outre, la maintenance de table comme les opérations OPTIMIZE ou REORG TABLE n'est pas prise en charge pour les tables qui utilisent l’actualisation incrémentielle.
Si vous tirez parti d’une passerelle de données pour vous connecter à vos sources de données, vérifiez que la passerelle est mise à jour vers au moins la version 2025 (3000.270) ou ultérieure. Cela est essentiel pour maintenir la compatibilité et garantir que les fonctions d’actualisation incrémentielle fonctionnent correctement avec les destinations lakehouse.
Le passage de l’actualisation non incrémentielle à l’actualisation incrémentielle avec des données qui se chevauchent déjà dans la destination n’est pas pris en charge. Si la destination lakehouse contient déjà des données pour les compartiments qui chevauchent les compartiments incrémentiels définis dans les paramètres, le système ne peut pas se convertir en actualisation incrémentielle sans réécrire l’intégralité de la table Delta. Nous vous recommandons de filtrer l’ingestion initiale pour inclure uniquement les données avant le compartiment incrémentiel le plus ancien afin d’éviter le chevauchement et de garantir un comportement d’actualisation correct.
La destination de données doit être définie sur un schéma fixe
La destination des données doit être définie sur un schéma fixe, ce qui signifie que le schéma de la table dans la destination de données doit être fixe et ne peut pas changer. Si le schéma de la table dans la destination de données est défini sur un schéma dynamique, vous devez le modifier en un schéma fixe avant de configurer l’actualisation incrémentielle.
La seule méthode de mise à jour prise en charge dans la destination de données est replace
La seule méthode de mise à jour prise en charge dans la destination de données est replace, ce qui signifie que le flux de données remplace les données pour chaque compartiment de la destination de données par les nouvelles données. Toutefois, les données en dehors de la plage d'intervalle ne sont pas affectées. Si vous avez des données dans la destination des données antérieures au premier compartiment, l’actualisation incrémentielle n’affecte pas ces données.
Le nombre maximal de compartiments est de 50 pour une requête unique et de 150 pour l’ensemble du flux de données
Chaque requête peut gérer jusqu’à 50 compartiments. Si vous avez plus de 50 buckets, vous devrez agrandir la taille de vos buckets ou réduire l’intervalle de temps pour en diminuer le nombre.
Pour l’ensemble de votre dataflow, la limite est de 150 compartiments au total. Si vous atteignez cette limite, vous pouvez réduire le nombre de requêtes à l’aide de l’actualisation incrémentielle ou augmenter la taille du compartiment dans vos requêtes.
Différences entre l’actualisation incrémentielle dans Dataflow Gen1 et dans Dataflow Gen2
Il existe des différences dans le fonctionnement de l’actualisation incrémentielle entre Dataflow Gen1 et Dataflow Gen2. Voici les principales différences :
Fonctionnalité de première classe : l’actualisation incrémentielle est désormais une fonctionnalité de première classe dans Dataflow Gen2. Dans Dataflow Gen1, vous avez configuré l’actualisation incrémentielle après avoir publié le dataflow. Dans Dataflow Gen2, vous pouvez le configurer directement dans l’éditeur de flux de données. Cela facilite la configuration et la réduction du risque d’erreurs.
Aucune plage de données historique : dans Dataflow Gen1, vous avez spécifié la plage de données historique lorsque vous avez configuré l’actualisation incrémentielle. Dans Dataflow Gen2, vous ne spécifiez pas cette plage. Le flux de données ne supprime aucune donnée de la destination qui se trouve en dehors de la plage du compartiment. Si vous avez des données dans la destination qui sont antérieures au premier "bucket", l’actualisation incrémentielle ne les affecte pas.
Paramètres automatiques : dans Dataflow Gen1, vous avez spécifié les paramètres d’actualisation incrémentielle lorsque vous l’avez configuré. Dans Dataflow Gen2, vous ne spécifiez pas ces paramètres. Le flux de données ajoute automatiquement les filtres et les paramètres à la dernière étape de la requête.
FAQ
J’ai reçu un avertissement indiquant que j’ai utilisé la même colonne pour détecter les modifications et le filtrage. Qu’est-ce que cela signifie ?
Si vous recevez cet avertissement, cela signifie que la colonne que vous avez spécifiée pour détecter les modifications est également utilisée pour filtrer les données. Nous ne recommandons pas cela, car cela peut entraîner des résultats inattendus.
Utilisez plutôt une autre colonne pour détecter les modifications et filtrer les données. Si les données passent d’un compartiment à l’autre, le flux de données risque de ne pas détecter correctement les modifications et de créer des données dupliquées dans votre destination.
Vous pouvez résoudre cet avertissement en utilisant différentes colonnes pour détecter les modifications et pour filtrer les données. Ou vous pouvez ignorer l’avertissement si vous êtes sûr que les données n’ont pas été modifiées entre les actualisations de la colonne que vous avez spécifiée.
Je souhaite utiliser l’actualisation incrémentielle avec une destination de données qui n’est pas prise en charge. Que puis-je faire ?
Si vous souhaitez utiliser l’actualisation incrémentielle avec une destination de données qui ne la prend pas en charge, voici ce que vous pouvez faire :
Activez l’actualisation incrémentielle sur votre requête et créez une deuxième requête qui référence les données intermédiaires. Utilisez ensuite cette deuxième requête pour mettre à jour votre destination finale. Cette approche réduit toujours le traitement des données de votre système source, mais vous devez effectuer une actualisation complète des données intermédiaires vers votre destination finale.
Veillez à configurer correctement la fenêtre et la taille du compartiment. Nous ne garantissons pas que les données intermédiaires restent disponibles en dehors de la plage de compartiments.
Une autre option consiste à utiliser le modèle amass incrémentiel. Consultez notre guide : Collecte incrémentielle de données avec Dataflow Gen2.
Comment savoir si l’actualisation incrémentielle est activée sur ma requête ?
Vous pouvez voir si l’actualisation incrémentielle est activée sur votre requête en vérifiant l’icône à côté de la requête dans l’éditeur de flux de données. Si l’icône contient un triangle bleu, l’actualisation incrémentielle est activée. Si l’icône ne contient pas de triangle bleu, l’actualisation incrémentielle n’est pas activée.
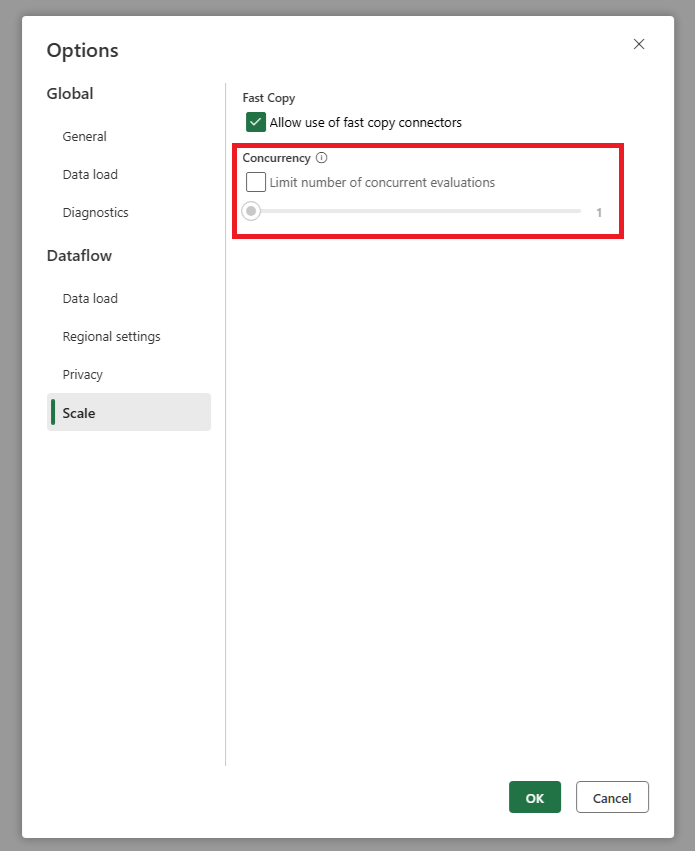
Ma source obtient trop de requêtes quand j'utilise l'actualisation incrémentielle. Que puis-je faire ?
Vous pouvez contrôler le nombre de demandes envoyées par votre flux de données au système source. Voici comment procéder :
Accédez aux paramètres globaux de votre dataflow et recherchez le paramètre d’évaluation des requêtes parallèles. Définissez cette valeur sur un nombre inférieur pour réduire les demandes envoyées à votre système source. Cela permet de réduire la charge sur votre source et d’améliorer ses performances.
Pour trouver ce paramètre : accédez à l’onglet >Échelle des paramètres > globaux pour définir le nombre maximal d’évaluations de requêtes parallèles.
Nous vous recommandons d’utiliser cette limite uniquement si votre système source ne peut pas gérer le nombre par défaut de requêtes simultanées.
Je souhaite utiliser l’actualisation incrémentielle, mais je vois qu’après l’activation, le flux de données prend plus de temps à actualiser. Que puis-je faire ?
L’actualisation incrémentielle doit accélérer le flux de données en traitant moins de données. Mais parfois le contraire se produit. Cela signifie généralement que la surcharge liée à la gestion des compartiments et la vérification des modifications prennent plus de temps que vous n'en gagnez en traitant moins de données.
Voici ce que vous pouvez essayer :
Ajustez vos paramètres : augmentez la taille de votre compartiment pour réduire le nombre de compartiments. Moins de compartiments signifient moins de surcharge liée à leur gestion.
Essayez une actualisation complète : si l’ajustement des paramètres n’est pas utile, envisagez de désactiver l’actualisation incrémentielle. Une actualisation complète peut réellement être plus efficace pour votre scénario spécifique.