Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les dataflows sont un outil cloud qui vous permet de préparer et de transformer des données sans écrire de code. Ils fournissent une interface à faible code pour l’ingestion de données à partir de centaines de sources de données, la transformation de vos données à l’aide de transformations de données 300+ et le chargement des données résultantes dans plusieurs destinations. Considérez-les comme votre assistant de données personnelles qui peut se connecter à des centaines de sources de données différentes, nettoyer les données désordonnée et le fournir exactement là où vous en avez besoin. Que vous soyez un développeur citoyen ou professionnel, les dataflows vous permettent d'utiliser une expérience d'intégration de données moderne pour ingérer, préparer et transformer des données à partir d'un ensemble complet de sources de données, notamment des bases de données, des data warehouse, lakehouse, des données en temps réel, etc.
Dataflow Gen2 est la version plus récente et plus puissante qui fonctionne en même temps que le dataflow d’origine Power BI (maintenant appelé Gen1). Conçu à l'aide de l'expérience familière Power Query disponible sur plusieurs produits et services de Microsoft tels que Excel, Power BI, Power Platform et Dynamics 365, Dataflow Gen2 offre des fonctionnalités améliorées, de meilleures performances et des fonctionnalités de copie rapide pour ingérer rapidement et rapidement transformer des données. Si vous démarrez une nouvelle version, nous vous recommandons Dataflow Gen2 pour ses fonctionnalités améliorées et de meilleures performances.
Important
À compter d’avril 2026, l’option permettant de créer de nouveaux éléments Dataflow Gen2 sans prise en charge de l’intégration CI/CD et Git (précédemment appelée Dataflow Gen2 Classic) n’est plus disponible. Tous les nouveaux éléments Dataflow Gen2 sont désormais créés avec la prise en charge de l’intégration CI/CD et Git par défaut. Les éléments Dataflow Gen2 existants sans prise en charge CI/CD continuent de fonctionner comme prévu. Pour convertir un dataflow classique existant, utilisez la fonctionnalité Enregistrer sous.
Que pouvez-vous faire avec les dataflows ?
Avec les dataflows, vous pouvez :
- Connectez-vous à vos données : extrayez des informations à partir de bases de données, de fichiers, de services web, etc. Vous pouvez également vous reconnecter aux sources récemment utilisées.
- Transformer vos données : nettoyer, filtrer, combiner et remodeler vos données à l’aide d’une interface visuelle.
- Charger des données n’importe où : envoyez vos données transformées aux bases de données, aux entrepôts de données ou aux storage cloud.
- Automatisez le processus : configurez des planifications afin que vos données restent fraîches et up-to-date.
Fonctionnalités de dataflow
Voici les fonctionnalités disponibles entre Dataflow Gen2 et Gen1 :
| Caractéristique | Dataflow Gen2 | Dataflow Gen1 |
|---|---|---|
| Créer des dataflows avec Power Query | ✓ | ✓ |
| Processus de création plus simple | ✓ | |
| Enregistrement automatique et publication en arrière-plan | ✓ | |
| Destinations de sortie multiples | ✓ | |
| Meilleure surveillance et suivi des actualisations | ✓ | |
| Fonctionne avec pipelines | ✓ | |
| Calcul haute performance | ✓ | |
| Se connecter via le connecteur de flux de données | ✓ | ✓ |
| Requête directe via le connecteur de flux de données | ✓ | |
| Actualiser uniquement les données modifiées | ✓ | ✓ |
| Insights basés sur l’intelligence artificielle | ✓ | ✓ |
| Raccourcis de données récents vers des sources précédemment utilisées | ✓ |
Mises à niveau vers Dataflow Gen2
Dans les sections suivantes, voici quelques-unes des principales améliorations apportées à Dataflow Gen2 par rapport à Gen1 pour faciliter et améliorer l’efficacité de vos tâches de préparation des données.
Gen2 est plus facile à créer et à utiliser
Dataflow Gen2 est familier si vous avez déjà utilisé Power Query. Nous avons rationalisé le processus pour vous aider à être opérationnel plus rapidement. Vous serez guidé pas à pas lors de l’obtention de données dans votre dataflow, et nous avons réduit le nombre d’étapes nécessaires pour créer vos dataflows.

L’enregistrement automatique protège votre travail
Dataflow Gen2 enregistre automatiquement vos modifications au fur et à mesure que vous travaillez. Vous pouvez vous éloigner de votre ordinateur, fermer votre navigateur ou perdre la connexion Internet sans vous soucier de perdre votre progression. Quand tu reviens, tout est juste là où tu l’as laissé.
Une fois que vous avez terminé de créer votre flux de données, vous pouvez publier vos modifications. La publication enregistre votre travail et exécute des validations en arrière-plan. Vous n’avez donc pas besoin d’attendre que tout soit vérifié avant de passer à votre prochaine tâche.
Pour en savoir plus sur le processus de sauvegarde, consultez Enregistrer un projet de votre flux de données.
Envoyer des données partout où vous en avez besoin
Bien que Dataflow Gen1 stocke des données transformées dans son propre storage interne (que vous pouvez access via le connecteur Dataflow), Dataflow Gen2 vous offre la possibilité d’utiliser ce storage ou d’envoyer vos données à différentes destinations.
Cette flexibilité ouvre de nouvelles possibilités. Par exemple, vous pouvez :
- Utiliser un flux de données pour charger des données dans un entrepôt de données, puis les analyser avec un notebook.
- Charger des données dans une base de données Azure SQL, puis utiliser un pipeline pour le déplacer vers un entrepôt de données
Dataflow Gen2 prend actuellement en charge ces destinations :
- bases de données Azure SQL
- Azure Data Explorer (Kusto)
- Azure Datalake Gen2
- Tables Fabric Lakehouse
- Les fichiers de Fabric Lakehouse
- entrepôt de tissus
- base de données Fabric KQL
- base de données SQL Fabric
- fichiers SharePoint
- Base de données Snowflake
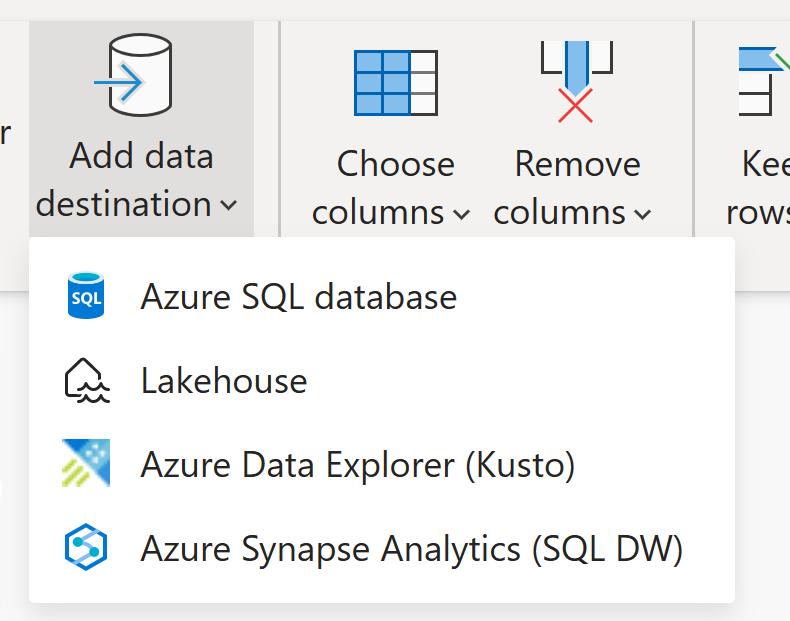
Pour plus d’informations sur les destinations de données disponibles, consultez les destinations de données Dataflow Gen2 et les paramètres managés.
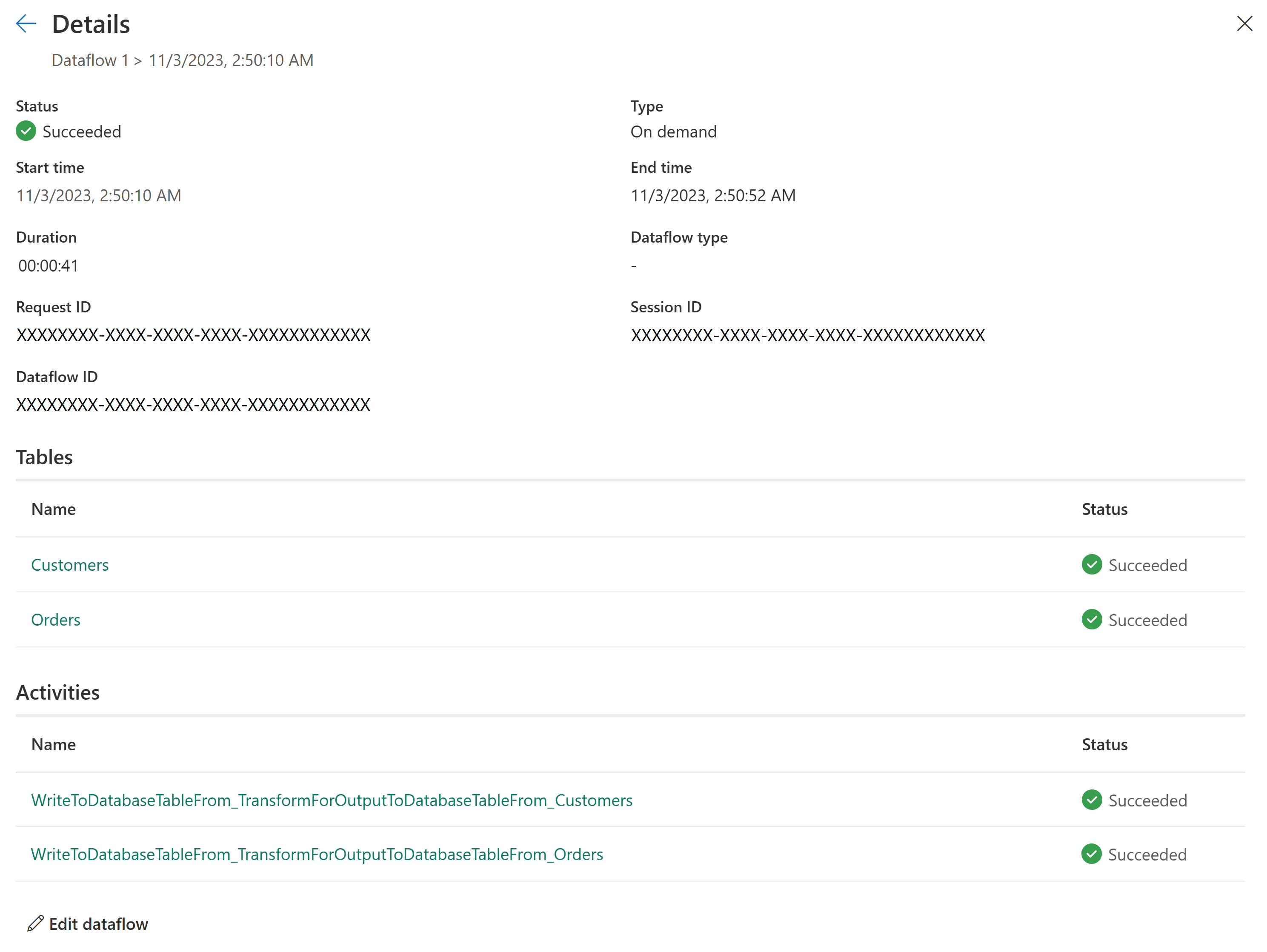
Meilleure surveillance et suivi des actualisations
Dataflow Gen2 vous donne une image plus claire de ce qui se passe avec vos actualisations de données. Nous avons intégré monitoring Hub et amélioré l’expérience d’historique des actualisations , ce qui vous permet de suivre l’état et les performances de vos dataflows.
Fonctionne de manière fluide avec les pipelines
Pipelines vous permet de regrouper les activités pour effectuer des tâches plus volumineuses. Considérez-les comme des flux de travail qui peuvent copier des données, exécuter des requêtes SQL, exécuter des procédures stockées ou exécuter des notebooks Python.
Vous pouvez connecter plusieurs activités dans un pipeline et la définir pour qu’elles s’exécutent selon une planification. Par exemple, tous les lundis, vous pouvez utiliser un pipeline pour extraire les données d’un objet blob Azure et les nettoyer, puis déclencher un Dataflow Gen2 pour analyser les données du journal. Ou à la fin du mois, vous pouvez copier des données d’un objet blob Azure vers une base de données Azure SQL, puis exécuter une procédure stockée sur cette base de données.
Pour en savoir plus sur la connexion des pipelines avec des dataflows, consultez les activités des dataflows.
Calcul haute performance
Dataflow Gen2 utilise des moteurs de calcul SQL avancés Fabric pour gérer efficacement de grandes quantités de données. Pour que cela fonctionne, Dataflow Gen2 crée des éléments Lakehouse et Warehouse dans votre espace de travail et les utilise pour stocker et accéder aux données, ce qui améliore les performances de tous vos flux de données.
Rechercher et réutiliser des sources de données récentes
Dataflow Gen2 inclut un module de données récent qui enregistre les éléments que vous avez utilisés précédemment, tels que les tables, les fichiers, les dossiers, les bases de données et les feuilles, et vous permet de les charger directement dans le canevas d’édition Dataflow Gen2. Vous pouvez accéder aux données récentes à partir du ruban Power Query ou de l’expérience Modern Get Data. Vous pouvez donc rapidement revenir aux données dont vous avez besoin sans reconfigurer vos connexions.
À partir de n’importe quelle entrée de données récente, vous pouvez également sélectionner Parcourir l’emplacement pour explorer et sélectionner des éléments connexes supplémentaires dans le même dossier ou la même base de données, ce qui facilite l’utilisation de plusieurs ressources dans le même emplacement.
Copilot pour Dataflow Gen2
Dataflow Gen2 s’intègre à Microsoft Copilot dans Fabric pour fournir une assistance basée sur l’IA pour créer des solutions d’intégration de données à l’aide d’invites en langage naturel. Copilot vous aide à simplifier votre processus de développement de flux de données en vous permettant d’utiliser le langage conversationnel pour effectuer des transformations et des opérations de données.
- Obtenir des données à partir de sources : utilisez l’invite de démarrage « Obtenir des données à partir de » pour vous connecter à différentes sources de données telles que OData, bases de données et fichiers
-
Transformer des données en langage naturel : appliquez des transformations à l’aide d’invites conversationnelles telles que :
- « Conserver uniquement les clients européens »
- « Compter le nombre total d’employés par ville »
- « Conservez uniquement les commandes dont les quantités sont supérieures à la valeur médiane »
- Créer des exemples de données : utilisez Azure OpenAI pour générer des exemples de données pour les tests et le développement
- Opérations d’annulation : tapez ou sélectionnez « Annuler » pour supprimer la dernière étape appliquée
- Validate et révision : chaque action de Copilot apparaît sous forme de carte de réponse avec les étapes correspondantes dans la liste des étapes appliquées
Pour plus d’informations, consultez Copilot pour Dataflow Gen2.
De quoi avez-vous besoin pour utiliser des flux de données ?
Dataflow Gen2 nécessite une capacité de Fabric, une capacité d’essai Fabric ou une capacité Power BI Premium. Pour comprendre le fonctionnement des licences pour les flux de données, consultez les concepts et les licences Microsoft Fabric.
Passage de Dataflow Gen1 à Gen2
Si vous avez déjà créé des dataflows avec Gen1, ne vous inquiétez pas , vous pouvez facilement les migrer vers Gen2. Nous avons plusieurs options pour vous aider à faire le changement :
- Exporter et importer vos requêtes
- Copy et coller dans Power Query
- Utiliser la fonctionnalité Enregistrer sous
Exporter et importer vos requêtes
Vous pouvez exporter vos requêtes Dataflow Gen1 et les enregistrer dans un fichier PQT, puis les importer dans Dataflow Gen2. Pour obtenir des instructions pas à pas, consultez Utiliser la fonctionnalité de modèle d’exportation.
Copier et coller dans Power Query
Si vous avez un flux de données dans Power BI ou Power Apps, vous pouvez copier vos requêtes et les coller dans l’éditeur Dataflow Gen2. Cette approche vous permet de migrer sans avoir à reconstruire vos requêtes à partir de zéro. En savoir plus : Copier et coller des requêtes Dataflow Gen1 existantes.
Utiliser la fonctionnalité Enregistrer sous
Si vous avez déjà un type de dataflow (Gen1 ou Gen2), Data Factory inclut la fonctionnalité Enregistrer sous. Cela vous permet d’enregistrer tout flux de données existant sous la forme d’un nouvel élément Dataflow Gen2 avec la prise en charge de l’intégration CI/CD et Git dans une seule action. Plus d’informations : Migrer vers Dataflow Gen2 à l’aide de 'Enregistrer sous'.
Mise en scène des éléments dans votre espace de travail
Dans certaines expériences, vous pouvez voir des éléments générés par le système comme DataflowsStagingLakehouse ou DataflowsStagingWarehouse dans votre espace de travail. Il s’agit d’éléments intermédiaires internes utilisés par Dataflow Gen2 et ne sont pas destinés à une interaction directe. Vous pouvez les ignorer en toute sécurité.
Contenu connexe
Prêt à en savoir plus ? Consultez ces ressources utiles :
- Surveiller vos dataflows - Suivre l’historique d’actualisation et les performances
- Enregistrer des brouillons au fur et à mesure que vous travaillez - En savoir plus sur la fonctionnalité d’enregistrement automatique
- Migrer de Gen1 vers Gen2 - Guide de migration pas à pas