Copie rapide dans Dataflows Gen2
Cet article décrit la fonctionnalité de copie rapide dans Dataflows Gen2 pour Data Factory dans Microsoft Fabric. Les flux de données aident à ingérer et à transformer les données. Avec l’introduction du scale-out du flux de données avec le calcul SQL DW, vous pouvez transformer vos données à grande échelle. Toutefois, vos données doivent d’abord être ingérées. Avec l’introduction de la copie rapide, vous pouvez ingérer des téraoctets de données avec l'expérience simple des flux de données, mais avec le back end évolutif de l’activité Copy du pipeline.
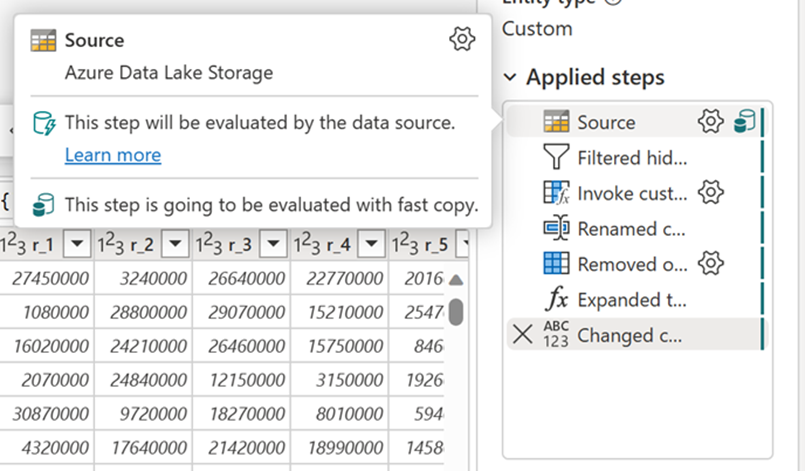
Après avoir activé cette fonctionnalité, les flux de données basculent automatiquement le back end lorsque la taille des données dépasse un seuil particulier, sans avoir à modifier quoi que ce soit lors de la création des flux de données. Après l’actualisation d’un flux de données, vous pouvez vérifier dans l’historique d’actualisation pour voir si une copie rapide a été utilisée pendant l’exécution en examinant le type Moteur qui s’y affiche.
Avec l’option Exiger une copie rapide activée, l’actualisation du flux de données est annulée si la copie rapide n’est pas utilisée. Cela vous permet d’éviter d’attendre un délai d’expiration d’actualisation pour continuer. Ce comportement peut également être utile dans une session de débogage pour tester le comportement du flux de données avec vos données tout en réduisant le temps d’attente. À l’aide des indicateurs de copie rapide dans le volet étapes de requête, vous pouvez facilement vérifier si votre requête peut s’exécuter avec une copie rapide.
Prérequis
- Vous devez disposer d’une capacité Fabric.
- Pour les données de fichier, les fichiers sont au format .csv ou parquet d’au moins 100 Mo et stockés dans un Azure Data Lake Storage (ADLS) Gen2 ou un compte de stockage blob.
- Pour les bases de données, y compris Azure SQL DB et PostgreSQL, 5 millions de lignes ou plus de données dans la source de données.
Remarque
Vous pouvez contourner le seuil pour forcer la copie rapide en sélectionnant le paramètre « Exiger une copie rapide ».
Prise en charge du connecteur
La copie rapide est actuellement prise en charge pour les connecteurs Dataflow Gen2 suivants :
- ADLS Gen2
- Stockage Blob
- Azure SQL DB
- Lakehouse
- PostgreSQL
- SQL Server localement
L’activité de copie prend uniquement en charge quelques transformations lors de la connexion à une source de fichier :
- Combiner des fichiers
- Sélectionner des colonnes
- Changer les types de données
- Renommer une colonne
- Supprimer une colonne
Vous pouvez toujours appliquer d’autres transformations en fractionnant les étapes d’ingestion et de transformation en requêtes distinctes. La première requête récupère les données et la deuxième requête fait référence à ses résultats afin que le calcul DW puisse être utilisé. Pour les sources SQL, toute transformation qui fait partie de la requête native est prise en charge.
Lorsque vous chargez directement la requête vers une destination de sortie, seules les destinations Lakehouse sont prises en charge actuellement. Si vous souhaitez utiliser une autre destination de sortie, vous pouvez d’abord indexer la requête et la référencer ultérieurement.
Comment utiliser la copie rapide
Accédez au point de terminaison Fabric approprié.
Accédez à un espace de travail Premium et créez un flux de données Gen2.
Sous l’onglet Accueil du nouveau flux de données, sélectionnez Options :
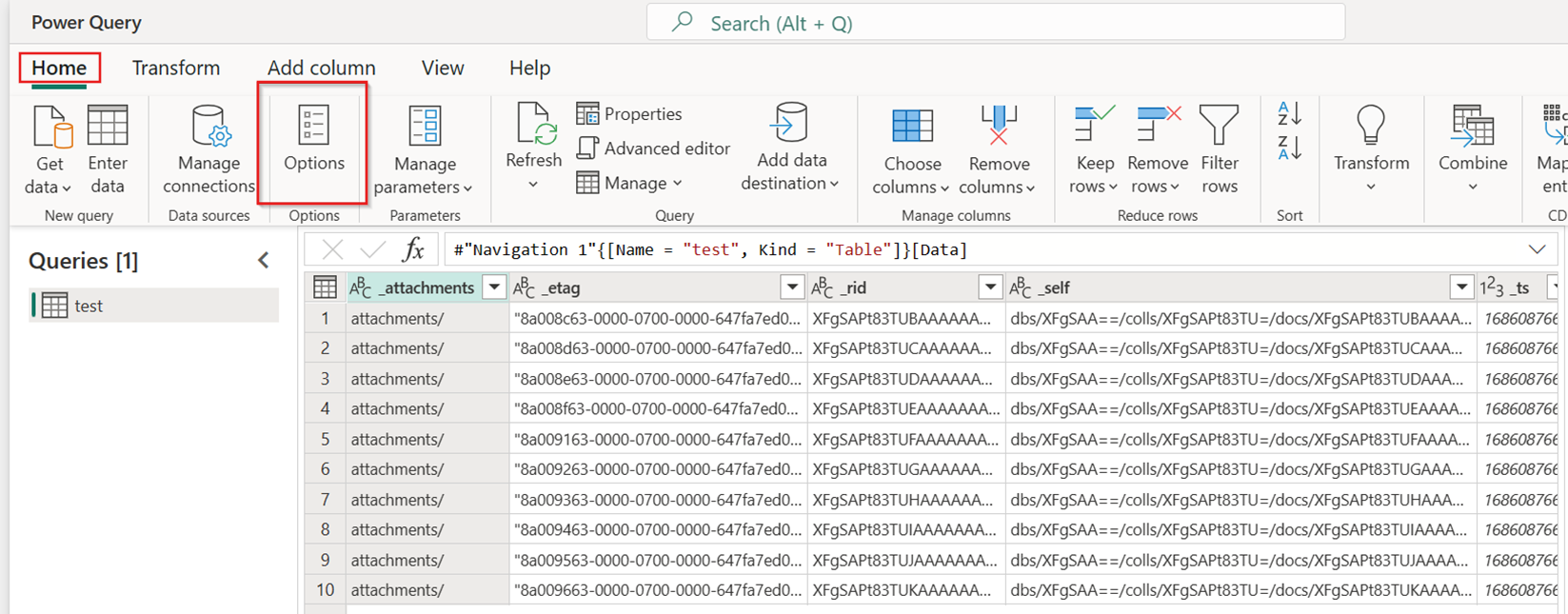
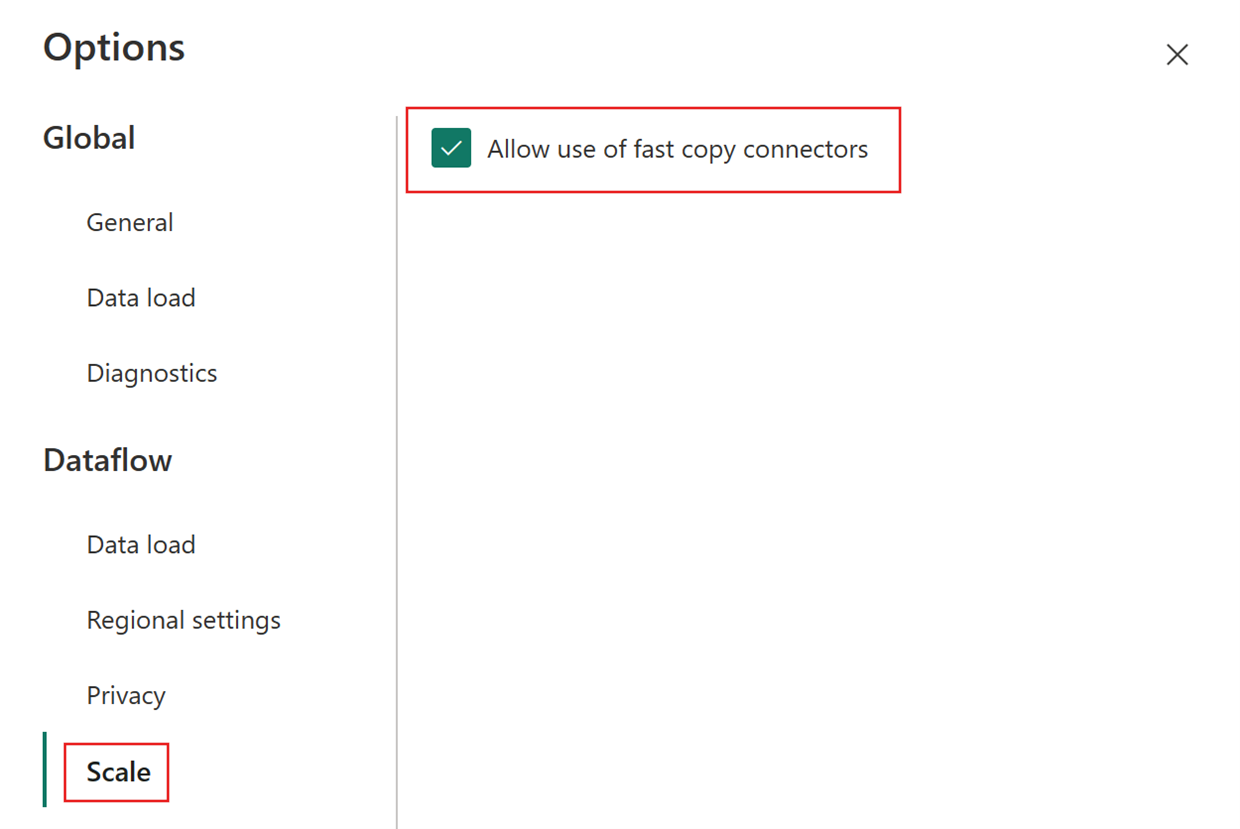
Choisissez ensuite l’onglet Mise à l’échelle dans la boîte de dialogue Options et sélectionnez la case à cocher Autoriser l’utilisation des connecteurs de copie rapide pour activer la copie rapide. Fermez ensuite la boîte de dialogue Options.
Sélectionnez Obtenir des données, puis choisissez la source ADLS Gen2, puis renseignez les détails de votre conteneur.
Utilisez la fonctionnalité Combiner un fichier.

Pour garantir une copie rapide, appliquez uniquement les transformations répertoriées dans la section Prise en charge du connecteur de cet article. Si vous avez besoin d’appliquer plus de transformations, indexer d’abord les données et référencez la requête ultérieurement. Effectuez d’autres transformations sur la requête référencée.
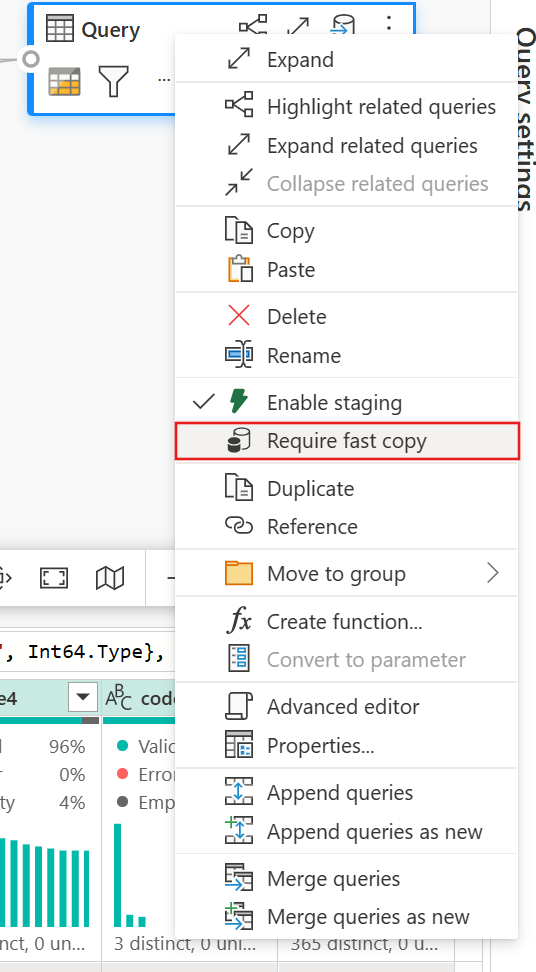
(Facultatif) Vous pouvez définir l’option Exiger une copie rapide pour la requête en cliquant dessus avec le bouton droit pour sélectionner et activer cette option.
(Facultatif) Actuellement, vous ne pouvez configurer qu’un Lakehouse comme destination de sortie. Pour toute autre destination, indexez la requête et référencez-la ultérieurement dans une autre requête où vous pouvez générer une sortie vers n’importe quelle source.
Vérifiez les indicateurs de copie rapide pour voir si votre requête peut s’exécuter avec une copie rapide. Si c’est le cas, le type Moteur affiche CopyActivity.

Publiez le flux de données.
Vérifiez une fois l’actualisation terminée pour confirmer que la copie rapide a été utilisée.

Contenu connexe
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour