Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Ce module prend environ 25 minutes. Vous créez un dataflow, appliquez des transformations et déplacez les données brutes de la table de couche de données bronze dans une table de couche de données gold .
Avec les données brutes chargées dans votre table bronze Lakehouse à partir du dernier module, vous pouvez maintenant les enrichir. Vous allez la combiner avec une autre table qui contient des remises pour chaque fournisseur et les voyages de chaque fournisseur pendant un jour spécifique. Ensuite, cette table finale Lakehouse en or est chargée et prête à être consommée.
Les étapes générales du flux de données sont les suivantes :
- Obtenez des données brutes à partir de la table Lakehouse créée par le travail de copie dans le module 1 : Ingérer des données avec un travail de copie.
- Transformez les données importées à partir de la table Lakehouse.
- Connectez-vous à un fichier CSV contenant des données de remises.
- Transformez les données de remises.
- Combinez les voyages et les données de remises.
- Chargez la requête de sortie dans la table Gold Lakehouse.
Conditions préalables
Module 1 de cette série de didacticiels : Importer des données avec une tâche de copie
Obtenir des données à partir d’une table Lakehouse
Dans la barre latérale, sélectionnez votre espace de travail, sélectionnez Nouvel élément, puis Dataflow Gen2 pour créer un dataflow Gen2.
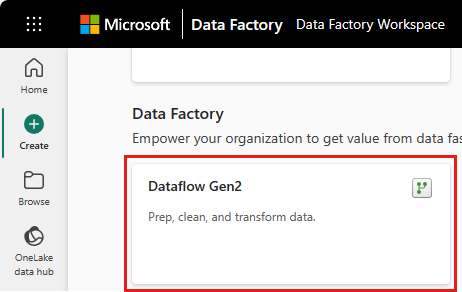
Dans le nouveau menu dataflow, sélectionnez Obtenir des données, puis Plus....
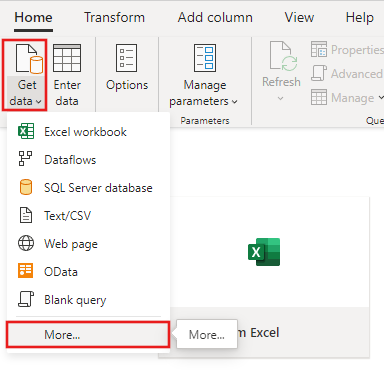
Recherchez et sélectionnez le connecteur Lakehouse .
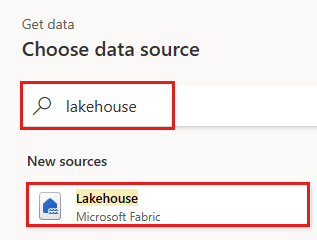
La boîte de dialogue Se connecter à la source de données s’affiche et une nouvelle connexion est créée automatiquement pour vous en fonction de l’utilisateur actuellement connecté. Cliquez sur Suivant.
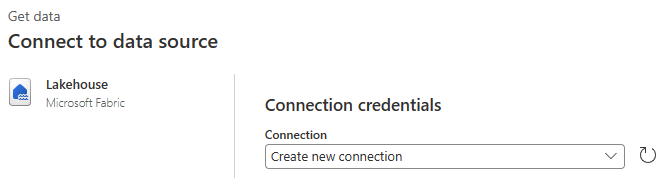
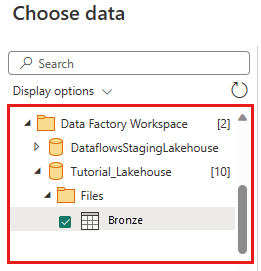
La boîte de dialogue Choisir des données s’affiche. Utilisez le volet de navigation pour rechercher le Lakehouse que vous avez créé pour la destination dans le module précédent. Il se trouve peut-être sous le dossier Mon espace de travail . Sélectionnez la table de données Bronze . Sélectionnez ensuite Créer.
(Facultatif) Une fois que votre canevas est rempli avec les données, vous pouvez définir des informations de profil de colonne , car cela est utile pour le profilage des données. Vous pouvez appliquer la transformation appropriée et cibler les valeurs de données appropriées en fonction de celle-ci.
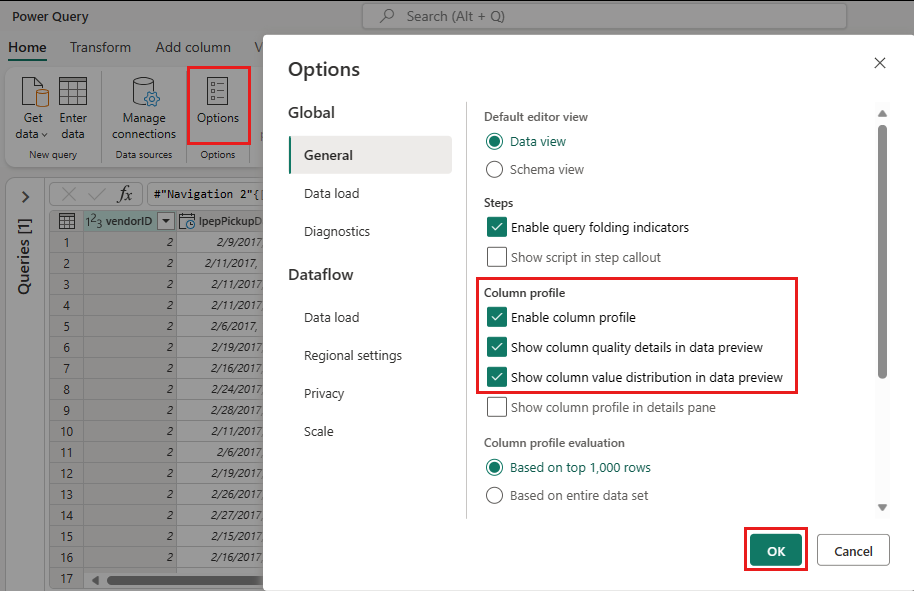
Pour ce faire, sélectionnez Options dans le volet du ruban, puis sélectionnez les trois premières options sous Profil de colonne, puis sélectionnez OK.



Transformer les données importées à partir de Lakehouse
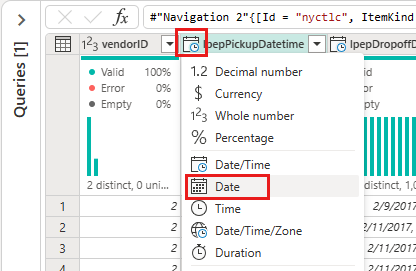
Sélectionnez l’icône de type de données dans l’en-tête de colonne de la deuxième colonne, IpepPickupDatetime, pour afficher un menu de liste déroulante et sélectionner le type de données dans le menu pour convertir la colonne du type Date/Heure en Date .
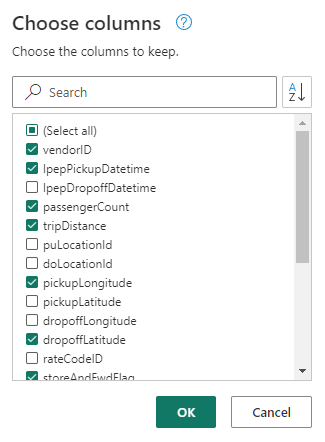
(Facultatif) Sous l’onglet Accueil du ruban, sélectionnez l’option Choisir des colonnes dans le groupe Gérer les colonnes .

(Facultatif) Dans la boîte de dialogue Choisir des colonnes , désélectionnez certaines colonnes répertoriées ici, puis sélectionnez OK.
- identifiant du fournisseur
- lpepPickupDatetime
- nombreDePassagers
- tripDistance
- picukupLongitude
- dropoffLatitude
- storeAndFwdFlag
- totalAmount
Sélectionnez le filtre et le menu de liste déroulante de tri de la colonne storeAndFwdFlag . (Si vous voyez une liste d’avertissements peut être incomplète, sélectionnez Charger plus pour afficher toutes les données.)
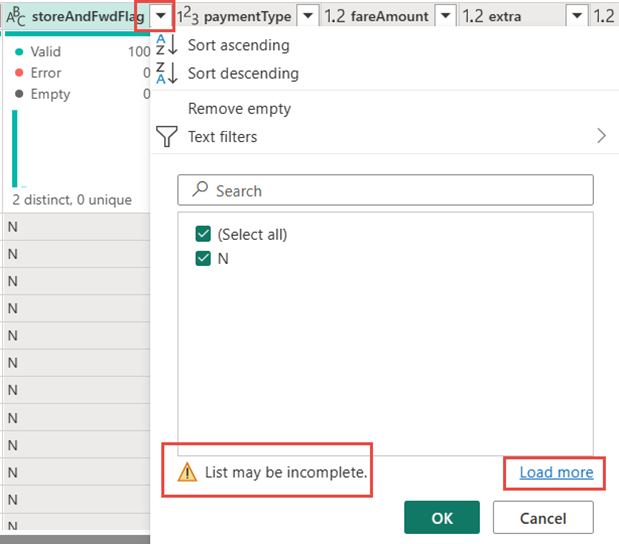
Sélectionnez « Y » pour afficher uniquement les lignes où une remise a été appliquée, puis sélectionnez OK.
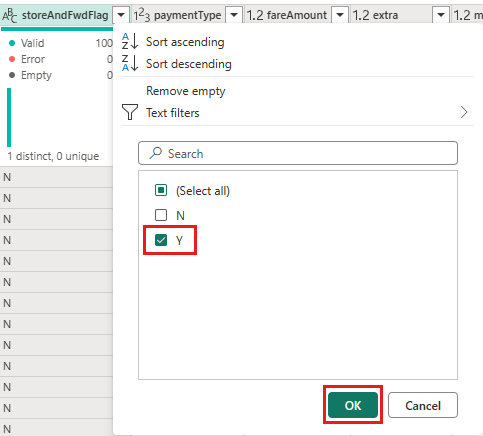
Attendez que les données sont filtrées.
Sélectionnez le menu de tri et de filtre de la colonne IpepPickupDatetime, puis sélectionnez Filtres Date, et choisissez le filtre Entre... fourni pour les types Date et Date/Heure.
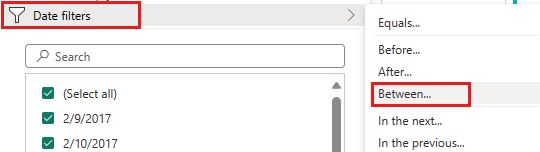
Dans la boîte de dialogue Filtrer les lignes , sélectionnez les dates entre le 1er janvier 2015 et le 31 janvier 2015, puis sélectionnez OK.
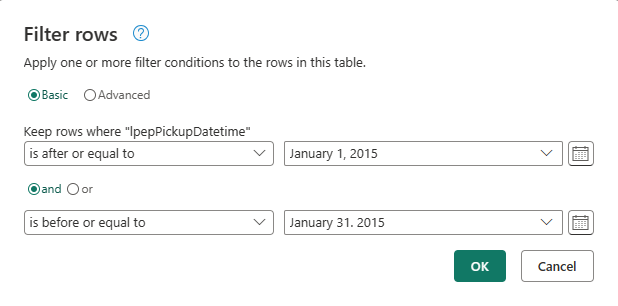
Attendez que les données sont filtrées.

Se connecter à un fichier CSV contenant des données de remise
Avec les données des voyages en place, nous voulons charger les données qui contiennent les remises respectives pour chaque jour et VendorID, et préparer les données avant de les combiner avec les données des voyages.
Dans l’onglet Accueil du menu de l’éditeur de flux de données, sélectionnez l’option Obtenir les données , puis choisissez Texte/CSV.
Dans la boîte de dialogue Se connecter à la source de données , fournissez les détails suivants :
-
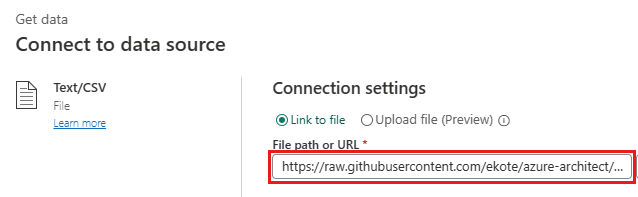
Chemin d’accès ou URL du fichier -
https://raw.githubusercontent.com/ekote/azure-architect/master/Generated-NYC-Taxi-Green-Discounts.csv - Type d’authentification - Anonyme
Ensuite, sélectionnez Suivant.
-
Chemin d’accès ou URL du fichier -
Dans la boîte de dialogue Aperçu des données de fichier , sélectionnez Créer.



Transformer les données de remise
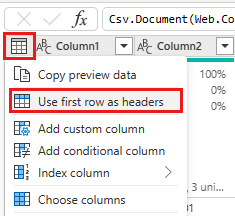
En examinant les données, nous voyons que les en-têtes apparaissent dans la première ligne. Définissez-les comme en-têtes en sélectionnant le menu contextuel du tableau dans la zone en haut à gauche de la grille d’aperçu et choisissez Utiliser la première ligne comme en-têtes.
Remarque
Après avoir promu les en-têtes, vous pouvez voir une nouvelle étape ajoutée au volet Étapes appliquées en haut de l’éditeur de flux de données aux types de données de vos colonnes.
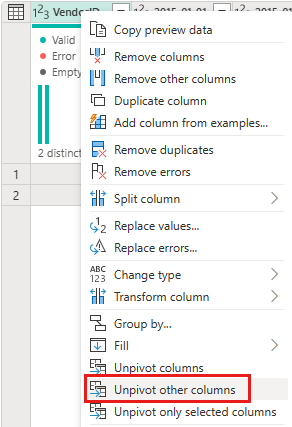
Cliquez avec le bouton droit de la souris sur la colonne VendorID, puis dans le menu contextuel affiché, sélectionnez l'option Dé-pivoter les autres colonnes. Cela vous permet de transformer des colonnes en paires attribut-valeur, où les colonnes deviennent des lignes.
Avec la table non pivotée, renommez les colonnes Attribut et Valeur en double-cliquant dessus et en remplaçant l’attribut par Date et Valeur par Remise.
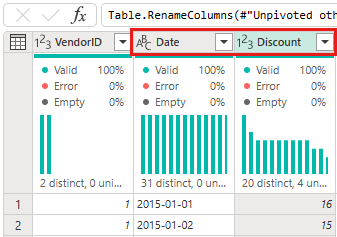
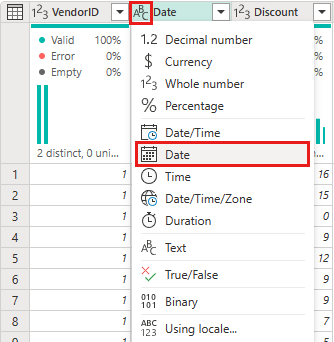
Modifiez le type de données de la colonne Date en sélectionnant le menu type de données à gauche du nom de la colonne et en choisissant Date.
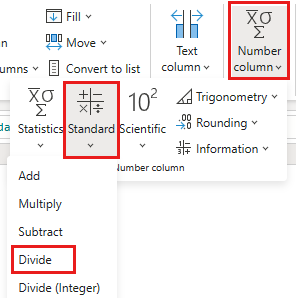
Sélectionnez la colonne Remise , puis sélectionnez l’onglet Transformer dans le menu. Sous la section Colonne Nombre , sélectionnez Transformations numériques standard dans le sous-menu, puis choisissez Diviser.
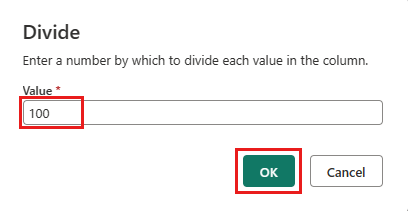
Dans la boîte de dialogue Diviser , entrez la valeur 100.

Combiner les données des voyages et des remises
L’étape suivante consiste à combiner les deux tables en une seule table qui a la remise qui doit être appliquée au voyage et le total ajusté.
Tout d’abord, activez le bouton Afficher le diagramme en bas à droite de la fenêtre, ce qui vous permet de voir les deux requêtes.
Sélectionnez votre requête de données d’origine (dans notre exemple, son nom bronze) et, sous l’onglet Accueil , dans le menu Combiner , choisissez Fusionner les requêtes, puis fusionnez les requêtes en tant que nouvelles.
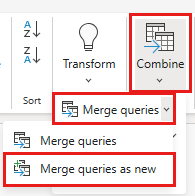
Dans la boîte de dialogue Fusionner, sélectionnez une fusion externe gauche, puis sélectionnez Generated-NYC-Taxi-Green-Discounts dans la liste déroulante Table de droite pour la fusion, puis sélectionnez l’icône « ampoule » en haut à droite de la boîte de dialogue pour afficher le mappage suggéré des colonnes entre les deux tables.
Choisissez le mappage suggéré pour mapper les colonnes VendorID et date des deux tables. Lorsque les deux mappages sont ajoutés, les en-têtes de colonne correspondants sont mis en surbrillance dans chaque table.
Un message s’affiche pour vous demander d’autoriser la combinaison de données provenant de plusieurs sources de données pour afficher les résultats. Sélectionnez OK dans la boîte de dialogue Fusionner .

Dans la zone de table, vous verrez initialement un avertissement indiquant que « Les informations sont requises pour la confidentialité des données ». Sélectionnez Continuer à traiter l’avertissement.
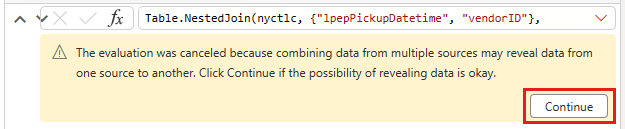
Pour ce tutoriel, sélectionnez Ignorer les niveaux de confidentialité pour ce document, car il s’agit d’exemples de données qui n’ont aucune information sensible. Pour vos propres sources de données, définissez les niveaux de confidentialité appropriés pour protéger vos données sensibles.
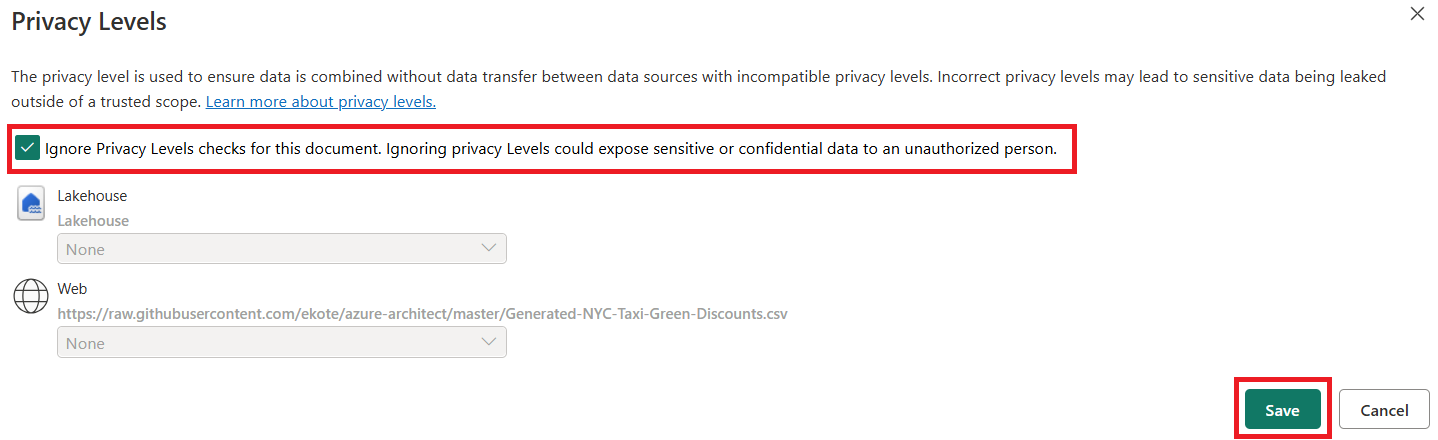
Cliquez sur Enregistrer.
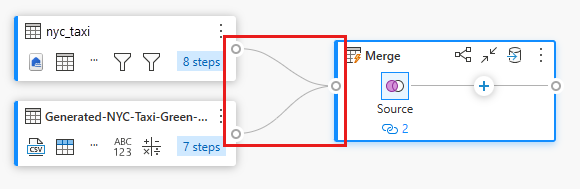
Notez comment une nouvelle requête a été créée en mode Diagramme montrant la relation de la nouvelle requête de fusion avec les deux requêtes que vous avez créées précédemment. En examinant le volet de table de l'éditeur, faites défiler vers la droite la liste des colonnes de la requête de fusion pour voir qu'une nouvelle colonne avec des valeurs de table est présente. Il s’agit de la colonne « Generated NYC Taxi-Green-Discounts », et son type est [Table]. Dans l’en-tête de colonne, il existe une icône avec deux flèches allant dans les directions opposées, ce qui vous permet de sélectionner des colonnes dans le tableau. Désélectionnez toutes les colonnes, à l'exception de la colonne Remise, puis sélectionnez OK.
Avec la valeur de remise maintenant au niveau de la ligne, nous pouvons créer une colonne pour calculer le montant total après remise. Pour ce faire, sélectionnez l’onglet Ajouter une colonne en haut de l’éditeur, puis choisissez Colonne personnalisée dans le groupe Général .
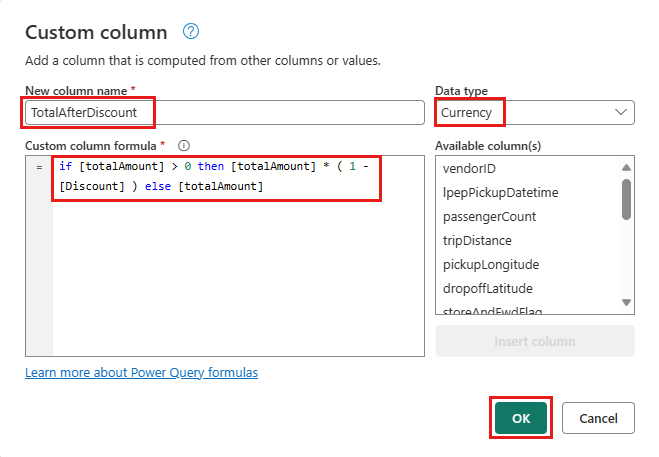
Dans la boîte de dialogue Custom column, vous pouvez utiliser le langage de formule Power Query (également appelé M) pour définir la façon dont votre nouvelle colonne doit être calculée. Entrez TotalAfterDiscount pour le nouveau nom de colonne, sélectionnez Devise pour le type de données et fournissez l’expression M suivante pour la formule de colonne personnalisée :
si [totalAmount] > 0 alors [totalAmount] * ( 1 -[Discount] ) sinon [totalAmount]
Ensuite, sélectionnez OK.
Sélectionnez la colonne TotalAfterDiscount nouvellement créée, puis sélectionnez l’onglet Transformer en haut de la fenêtre de l’éditeur. Dans le groupe Colonne Nombre, sélectionnez la liste déroulante Arrondir, puis choisissez Arrondir....
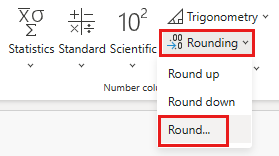
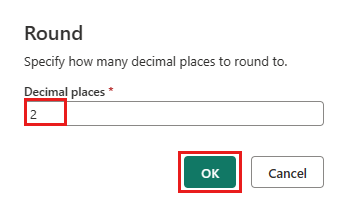
Dans la boîte de dialogue Arrondi, entrez 2 pour le nombre de décimales, puis sélectionnez OK.
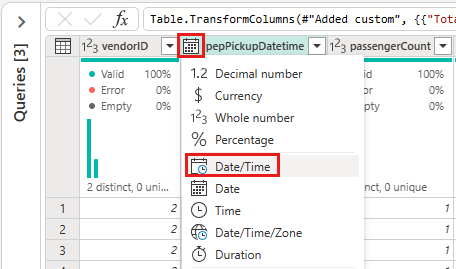
Modifiez le type de données de l’IpepPickupDatetime de Date à Date/Heure.
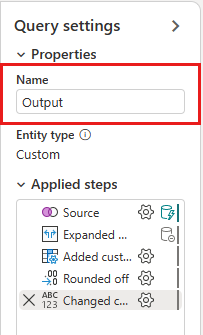
Enfin, développez le volet Paramètres de requête à partir du côté droit de l’éditeur s’il n’est pas déjà développé et renommez la requête de Merge to Output.






Charger la requête de sortie dans une table dans Lakehouse
Avec la requête de sortie maintenant entièrement préparée et avec les données prêtes à la sortie, nous pouvons définir la destination de sortie de la requête.
Sélectionnez la requête de fusion de sortie créée précédemment. Sélectionnez ensuite l’onglet Accueil dans l’éditeur, puis ajoutez la destination des données à partir du regroupement de requêtes pour sélectionner une destination Lakehouse .
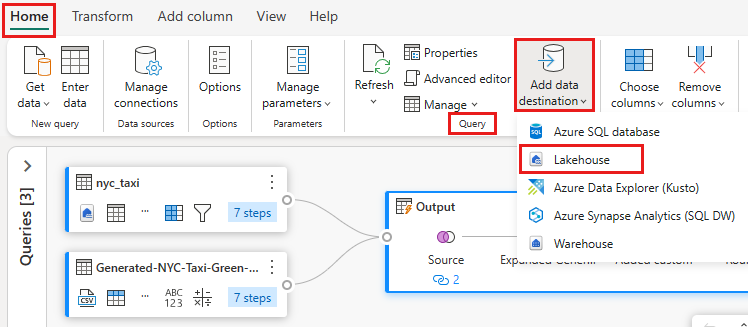
Dans la boîte de dialogue Se connecter à la destination des données , votre connexion doit déjà être sélectionnée. Sélectionnez Suivant pour continuer.
Dans la boîte de dialogue Choisir la cible de destination , accédez à Lakehouse où vous souhaitez charger les données et nommer la nouvelle table nyc_taxi_with_discounts, puis sélectionnez Suivant à nouveau.
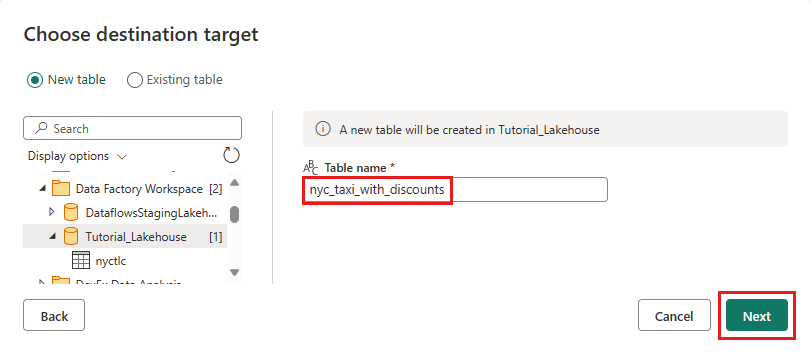
Dans la boîte de dialogue Choisir les paramètres de destination , vous pouvez utiliser les paramètres automatiques ou désélectionner les paramètres automatiques et laisser la méthode de mise à jour replace par défaut, vérifier que vos colonnes sont mappées correctement, puis sélectionner Enregistrer les paramètres.
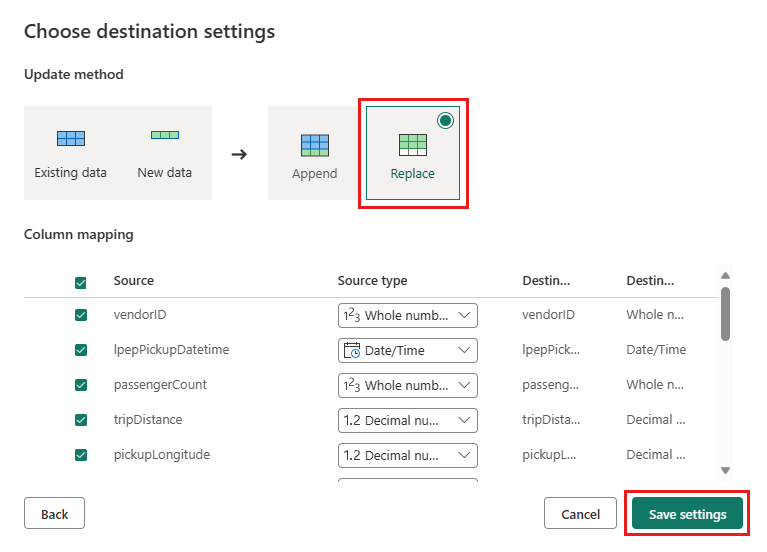
Dans la fenêtre de l’éditeur principal, vérifiez que vous voyez votre destination de sortie dans le volet Paramètres de requête de la table Sortie sous Destination des données, puis sélectionnez Enregistrer et exécuter.
Important
Lorsque le premier Dataflow Gen2 est créé dans un espace de travail, les éléments de type "lakehouse" et entrepôt sont mis en place, ainsi que le point de terminaison pour l’analyse SQL et les modèles sémantiques associés. Ces éléments sont partagés par tous les flux de données de l’espace de travail et sont requis pour que Dataflow Gen2 fonctionne. Ils ne doivent pas être supprimés et ne doivent pas être utilisés directement par les utilisateurs. Les éléments sont un détail d’implémentation de Dataflow Gen2. Les éléments ne sont pas visibles dans l’espace de travail, mais peuvent être accessibles dans d’autres expériences telles que les expériences Notebook, point de terminaison SQL, Lakehouse et Warehouse. Vous pouvez reconnaître les éléments par leur préfixe dans le nom. Le préfixe des éléments est « DataflowsStaging ».
(Facultatif) Dans la page de l’espace de travail, vous pouvez renommer votre dataflow en sélectionnant les points de suspension à droite du nom du flux de données qui s’affiche après avoir sélectionné la ligne, puis en choisissant Paramètres. Dans cet exemple, nous le renommons en nyc_taxi_with_discounts.
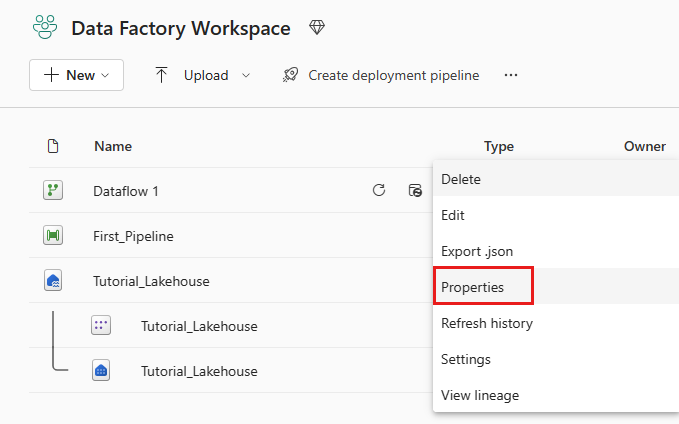
Sélectionnez l’icône d’actualisation du flux de données sous les points de suspension Autres options , puis, une fois terminé, vous devez voir votre nouvelle table Lakehouse créée comme configurée dans les paramètres de destination des données .
Vérifiez votre Lakehouse pour afficher la nouvelle table chargée là-bas.
