Utiliser Tidyverse
Tidyverse est une collection de packages R que les scientifiques des données utilisent couramment dans les analyses de données quotidiennes. Il inclut des packages pour l’importation de données (readr), la visualisation des données (ggplot2), la manipulation des données (dplyr, tidyr), la programmation fonctionnelle (purrr) et la création de modèles (tidymodels), etc. Les packages dans tidyverse sont conçus pour fonctionner ensemble en toute transparence et suivre un ensemble cohérent de principes de conception.
Microsoft Fabric distribue la dernière version stable de tidyverse avec chaque version du runtime. Importez et commencez à utiliser vos packages R familiers.
Prérequis
Obtenir un abonnement Microsoft Fabric. Ou, inscrivez-vous pour un essai gratuit de Microsoft Fabric.
Connectez-vous à Microsoft Fabric.
Utilisez le sélecteur d'expérience sur le côté gauche de votre page d'accueil pour passer à l'expérience science des données Synapse.

Ouvrez ou créez un notebook. Pour en savoir plus, consultez Comment utiliser les blocs-notes Microsoft Fabric.
Réglez l'option de langue sur SparkR (R) pour modifier la langue principale.
Attachez votre cahier à une cabane au bord du lac. Sur le côté gauche, sélectionnez Ajouter pour ajouter un lakehouse existant ou pour créer un lakehouse.
Charger tidyverse
# load tidyverse
library(tidyverse)
Importation de données
readr est un package R qui fournit des outils pour lire des fichiers de données rectangulaires tels que des fichiers CSV, TSV et de largeur fixe. readr offre un moyen rapide et convivial de lire des fichiers de données rectangulaires tels que la fourniture de fonctions read_csv() et read_tsv() la lecture des fichiers CSV et TSV respectivement.
Nous allons d’abord créer un data.frame R, l’écrire dans lakehouse à l’aide de readr::write_csv() et le relire avec readr::read_csv().
Remarque
Pour accéder aux fichiers Lakehouse à l’aide de readr, vous devez utiliser le chemin d’accès de l’API de fichier. Dans l’explorateur Lakehouse, cliquez avec le bouton droit sur le fichier ou le dossier auquel vous souhaitez accéder, puis copiez son chemin d’accès à l’API Fichier à partir du menu contextuel.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Ensuite, écrivons les données dans lakehouse à l’aide du chemin d’accès de l’API de fichier.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Lisez les données de lakehouse.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Rangement des données
tidyr est un package R qui fournit des outils pour travailler avec des données désordonnées. Les fonctions principales dans tidyr sont conçues pour vous aider à remodeler les données dans un format ordonné. Les données rangées ont une structure spécifique où chaque variable est une colonne et chaque observation est une ligne, ce qui facilite l’utilisation des données dans R et d’autres outils.
Par exemple, la fonction gather() dans tidyr peut être utilisée pour convertir des données larges en données longues. Voici un exemple :
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Programmation fonctionnelle
purrr est un package R qui améliore le kit de ressources de programmation fonctionnelle de R en fournissant un ensemble complet et cohérent d’outils permettant d’utiliser des fonctions et des vecteurs. Le meilleur point de départ avec purrr est la famille de fonctions map() qui vous permettent de remplacer de nombreuses boucles par du code à la fois plus succinct et plus facile à lire. Voici un exemple d’utilisation map() pour appliquer une fonction à chaque élément d’une liste :
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Manipulation des données
dplyr est un package R qui fournit un ensemble cohérent de verbes qui vous aident à résoudre les problèmes de manipulation de données les plus courants, tels que la sélection de variables en fonction des noms, le choix de cas en fonction des valeurs, la réduction de plusieurs valeurs à un seul résumé et la modification de l’ordre des lignes, etc. Voici quelques exemples :
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Visualisation des données
ggplot2 est un package R pour la création déclarative de graphiques, basé sur La grammaire des graphiques. Vous fournissez les données, expliquez à ggplot2 comment mapper les variables à l’esthétique, quelles primitives graphiques utiliser et il prend soin des détails. Voici quelques exemples :
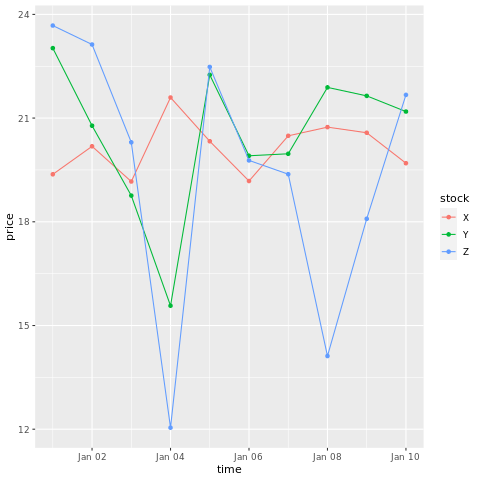
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
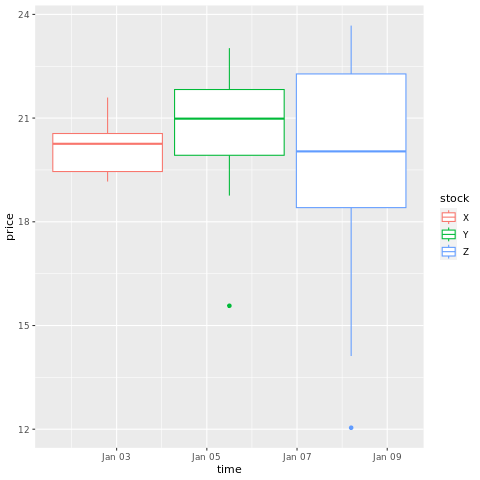
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Génération de modèles
L’infrastructure tidymodels est une collection de packages pour la modélisation et le Machine Learning à l’aide de principes tidyverse. Il couvre une liste de packages principaux pour une grande variété de tâches de génération de modèles, telles que rsample pour le fractionnement d’échantillons de jeux de données d’apprentissage/test, parsnip pour la spécification du modèle, recipes pour le prétraitement des données, workflows pour les workflows de modélisation, tune pour le réglage des hyperparamètres, yardstick pour l’évaluation des modèles, broom pour la gestion des sorties de modèle et dials pour la gestion des paramètres de paramétrage. Vous pouvez en savoir plus sur les packages en visitant le site web tidymodels. Voici un exemple de construction d’un modèle de régression linéaire pour prédire les miles par gallon (mpg) d’une voiture en fonction de son poids (wt) :
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
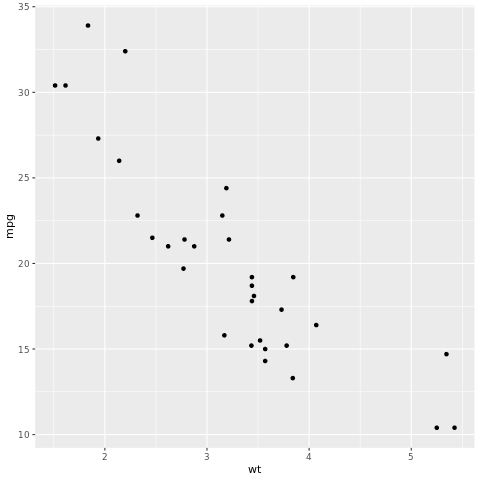
À partir du tracé de points, la relation est approximativement linéaire et la variance est constante. Essayons de modéliser cela à l’aide de la régression linéaire.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Appliquez le modèle de régression linéaire pour prédire sur le jeu de données de test.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
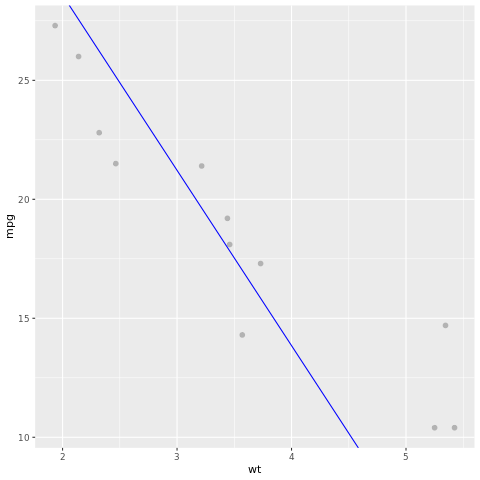
Examinons le résultat du modèle. Nous pouvons dessiner le modèle sous forme de graphique en courbes et les données de vérité du terrain de test sous forme de points sur le même graphique. Le modèle est bon.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")
Contenu connexe
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour