Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article fournit des informations sur les problèmes et les erreurs que vous pourriez rencontrer lors de l’utilisation des solutions de données de santé dans Microsoft Fabric, et comment les résoudre. L’article comprend également des conseils sur la surveillance des applications.
Si votre problème persiste après avoir suivi les instructions de cet article, créez un ticket d’incident pour l’équipe de support.
Résoudre les problèmes de déploiement
Parfois, vous pouvez rencontrer des problèmes intermittents lorsque vous déployez les solutions de données de santé dans l’espace de travail Fabric. Voici quelques problèmes couramment observés et des solutions pour les résoudre :
La création de la solution échoue ou prend trop de temps.
Erreur : La création de la solution de santé est en cours depuis plus de 5 minutes et/ou échoue.
Cause : Cette erreur se produit s’il existe une autre solution de soins de santé qui partage le même nom ou qui a été récemment supprimée.
Résolution : si vous avez récemment supprimé une solution, attendez 30 à 60 minutes avant de tenter un autre déploiement.
Échec du déploiement de la capacité.
Erreur : Les fonctionnalités des solutions de données de santé ne parviennent pas à se déployer.
Résolution : Vérifiez si la fonctionnalité est répertoriée dans la section Gérer les capacités déployées .
- Si la fonctionnalité n’est pas répertoriée dans le tableau, essayez de la déployer à nouveau. Sélectionnez la vignette de la fonctionnalité, puis sélectionnez Déployer dans l’espace de travail.
- Si la fonctionnalité est répertoriée dans le tableau avec la valeur d’état Échec du déploiement, redéployez la fonctionnalité. Vous pouvez également créer un environnement de solutions de données de santé et y redéployer la capacité.
Dépanner les tables non identifiées
Lorsque les tables Delta sont créées dans la lakehouse pour la première fois, elles peuvent temporairement s’afficher comme non identifiées ou vides dans la vue Explorateur de lakehouse. Cependant, elles devraient apparaître correctement sous le dossier tables après quelques minutes.

Réexécuter le pipeline de données
Pour réexécuter les exemples de données de bout en bout, suivez ces étapes :
Exécutez une instruction SQL Spark à partir d’un notebook pour supprimer toutes les tables d’une lakehouse. Prenons un exemple :
lakehouse_name = "<lakehouse_name>" tables = spark.sql(f"SHOW TABLES IN {lakehouse_name}") for row in tables.collect(): spark.sql(f"DROP TABLE {lakehouse_name}.{row[1]}")Utiliser Explorateur de fichiers OneLake pour vous connecter à OneLake dans votre explorateur de fichiers Windows.
Accédez au dossier de votre espace de travail dans l’Explorateur de fichiers Windows. Sous
<solution_name>.HealthDataManager\DMHCheckpoint, supprimez tous les dossiers correspondants dans<lakehouse_id>/<table_name>. Alternativement, vous pouvez également utiliser Utilitaires Microsoft Spark (MSSparkUtils) pour Fabric pour supprimer le dossier.Réexécutez tous les pipelines de données, en commençant par l’ingestion de données cliniques dans la lakehouse bronze.
Moniteur Apache Spark applications avec Azure Log Analytics
Les journaux de l’application Apache Spark sont envoyés à une instance de l’espace de travail Azure Log Analytics que vous pouvez interroger. Utilisez cet exemple de requête Kusto pour filtrer les journaux spécifiques aux solutions de données de santé :
AppTraces
| where Properties['LoggerName'] contains "Healthcaredatasolutions"
or Properties['LoggerName'] contains "DMF"
or Properties['LoggerName'] contains "RMT"
| limit 1000
Les journaux de la console du notebook enregistrent également le RunId pour chaque exécution. Vous pouvez utiliser cette valeur pour récupérer les journaux pour une exécution spécifique, comme indiqué dans l’exemple de requête suivant :
AppTraces
| where Properties['RunId'] == "<RunId>"
Pour obtenir des informations générales sur la surveillance, consultez Utiliser le hub de surveillance Fabric.
Utiliser l’explorateur de fichiers OneLake
L’application Explorateur de fichiers OneLake intègre de manière transparente OneLake à l’explorateur de fichiers Windows. Vous pouvez utiliser l’explorateur de fichiers OneLake pour afficher n’importe quel dossier ou fichier déployé dans votre espace de travail Fabric. Vous pouvez également voir les exemples de données, les fichiers et dossiers OneLake et les fichiers du point de contrôle.
Utiliser l’Explorateur de stockage Azure
Vous pouvez également utiliser l’Explorateur de stockage Azure pour :
- Accéder aux fichiers OneLake dans vos lakehouses Fabric
- Vous connecter au chemin de votre fichier d’URL OneLake
Réinitialiser la version d’exécution Spark dans l’espace de travail Fabric
Par défaut, tous les nouveaux espaces de travail Fabric utilisent la dernière version du runtime Fabric, qui est actuellement Runtime 1.3. Cependant, les solutions de données de santé ne prennent en charge que Runtime 1.2.
Ainsi, après avoir déployé des solutions de données de santé sur votre espace de travail, assurez-vous que la version d’exécution par défaut de Fabric est définie sur Runtime 1.2 (Apache Spark 3.4 et Delta Lake 2.4). Sinon, les exécutions de votre pipeline de données et ou notebook peuvent échouer. Pour plus d’informations, consultez Prise en charge de plusieurs environnements d’exécution dans Fabric.
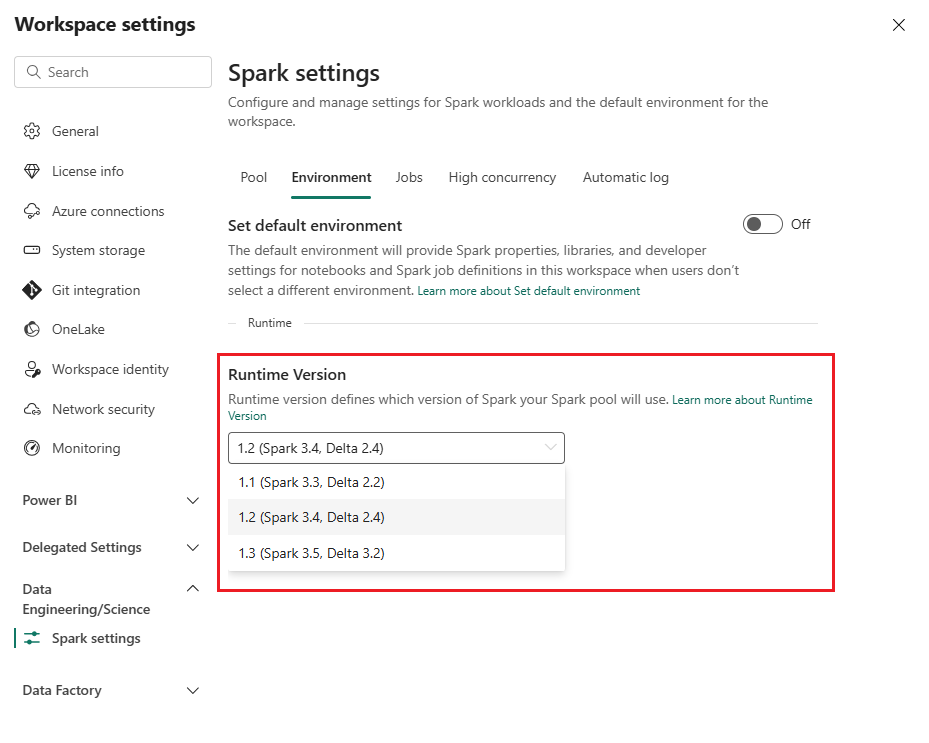
Suivez ces étapes pour examiner/mettre à jour la version du runtime Fabric :
Accédez à votre espace de travail Solutions de données de santé et sélectionnez Paramètres de l’espace de travail.
Sur la page des paramètres de l’espace de travail, développez la zone déroulante Engineering données/Science et sélectionnez Paramètres Spark.
Dans l’onglet Environnement , mettez à jour la valeur de la version d’exécution sur 1.2 (Spark 3.4, Delta 2.4) et enregistrez les modifications.

Actualiser l’interface utilisateur Fabric et l’explorateur de fichiers OneLake
Parfois, vous remarquerez que l’interface utilisateur Fabric ou explorateur de fichiers OneLake n’actualise pas toujours le contenu après chaque exécution du notebook. Si vous ne voyez pas le résultat attendu dans l’interface utilisateur après avoir exécuté une étape d’exécution, (par exemple, créer un dossier ou une lakehouse ou ingérer de nouvelles données dans une table), essayez d’actualiser l’artefact (table, lakehouse, dossier). Cette actualisation peut souvent résoudre les écarts avant d’explorer d’autres options ou d’approfondir les recherches.