Utiliser les sources des données de santé dans les solutions de données de santé (version préliminaire)
[Cet article fait partie de la documentation en version préliminaire et peut faire l’objet de modifications.]
La fonctionnalité de Sources des données de santé améliore le traitement des données Fast Healthcare Interoperability Resources (FHIR) dans l’environnement du lac de données et structure efficacement les données pour l’analyse et la modélisation IA/Machine Learning. Ces pipelines de données aplatissent ou transforment les données FHIR JSON ingérées en une structure tabulaire. Accessible via les outils SQL traditionnels, il permet une analyse exploratoire sur divers aspects des données de santé, y compris les modules de données cliniques, financières (réclamations et prestations étendues) et administratives.
La base des solutions de données de santé (version préliminaire) repose sur l’architecture médaillon Lakehouse. Dans l’architecture médaillon, les données sont organisées et traitées logiquement à l’aide d’une approche multicouche. L’objectif est d’améliorer progressivement la structure et la qualité des données à mesure qu’elles circulent à travers chaque couche de l’architecture. La première couche est bronze qui maintient l’état brut du source de données. La deuxième couche est argent qui représente une version validée et enrichie des données. La troisième et dernière couche est l’ or qui est hautement raffiné et agrégé. Après l’aplatissement des données, les outils SQL traditionnels peuvent utiliser les données cliniques pour effectuer une analyse exploratoire. Les fondations de données de santé prennent également en charge les fonctionnalités suivantes :
- En utilisant Microsoft Fabric des blocs-notes qui prennent en charge une interaction transparente avec les données de Lakehouse à l’aide des bibliothèques populaires PySpark et Python pour l’exploration et le traitement des données.
- Utilisation de points de terminaison SQL avec T-SQL pour interroger les données tabulaires et effectuer une analyse ad hoc ou exploratoire.
- En utilisant Power BI pour visualiser les données stockées dans OneLake. Vous pouvez créer des tableaux de bord, des rapports, des diagrammes et des graphiques pour explorer et présenter les données de manière significative.
Pour en savoir plus sur cette fonctionnalité et comprendre comment la déployer et la configurer, accédez à :
- Présentation des fondations de données de santé
- Déployer et configurer les Sources des données de santé
La capacité inclut aussi le notebook de configuration globale healthcare#_msft_config_notebook qui permet de configurer et de gérer la configuration nécessaire à toutes les transformations de données dans les solutions de données de santé (version préliminaire).
Important
Évitez d’exécuter ce notebook, car il est exécuté dans d’autres notebooks lors de l’installation.
La fonctionnalité Sources des données de santé est requise pour exécuter d’autres fonctionnalités des solutions de données de santé (version préliminaire). Par conséquent, assurez-vous de déployer avec succès cette fonctionnalité avant de tenter d’en déployer d’autres. Toutefois, pour exécuter les pipelines des fondations de données de santé, vous devez d’abord configurer et exécuter le pipeline d’ingestion de données FHIR pour ingérer les données FHIR ou les exemples de données. Pour plus d’informations, accédez à :
Conditions préalables
Avant d’exécuter le bloc-notes du service d’exportation FHIR, assurez-vous d’avoir effectué les étapes suivantes :
- Si vous n’utilisez pas de serveur FHIR, les exemples de données fournis sont configurés et connectés à l’espace de travail Fabric comme expliqué dans Déployer des exemples de données.
- Les étapes de déploiement et de configuration sont terminées comme expliqué dans Déployer et configurer les Sources des données de santé.
- Le déploiement, la configuration et l’exécution sont terminés pour la fonctionnalité d’ingestion de données FHIR.
- Le healthcare#_msft_config_notebook est configuré comme expliqué dans Configurer le notebook de configuration globale.
- Une configuration supplémentaire est configurée pour les autres ordinateurs portables, en fonction de vos besoins, comme expliqué dans Configuration du portable.
Ingestion de bronze
Cette section explique comment utiliser le healthcare#_msft_raw_bronze_ingestion notebook déployé dans le cadre de la fonctionnalité Sources des données de santé. Le notebook invoque le module BronzeIngestionService dans la bibliothèque de solutions de données de santé (version préliminaire) pour ingérer les données FHIR des fichiers sources NDJSON dans la table correspondante dans le lakehouse bronze. Pour plus d’informations sur ce bloc-notes, voir healthcare#_msft_raw_bronze_ingestion.
Le bloc-notes peut être exécuté à la demande ou selon un calendrier préféré dans le cadre d’un pipeline de données dans Microsoft Fabric. Pour plus d’informations, consultez Le pipeline de données s’exécute dans Fabric.
Après l’exécution du notebook, vous pouvez vérifier si les enregistrements sont correctement ingérés dans la table bronze Lakehouse correspondante. Vous pouvez exécuter une requête SELECT sur la table bronze Lakehouse, comme indiqué dans l’exemple suivant avec la table Patient :

Note
Par défaut, le notebook est configuré pour utiliser les exemples de données fournis avec les solutions de données de santé (version préliminaire). Si vous souhaitez utiliser vos propres données et non les exemples de données, mettez à jour la source_path_pattern variable dans le bloc-notes pour qu’elle pointe vers l’emplacement de vos données.
Aplatissement de l’argent
Cette section explique comment utiliser le healthcare#_msft_bronze_silver_flatten notebook déployé dans le cadre de la fonctionnalité Sources des données de santé. Le notebook appelle le module SilverIngestionService de la bibliothèque de solutions de données de santé (version préliminaire) pour aplatir les ressources FHIR des tables lakehouse bronze et d’ingérer les données résultantes dans les tables lakehouse argent correspondantes. Par défaut, vous n’êtes pas censé apporter de modifications à ce bloc-notes. Si vous préférez pointer vers des Lakehouses sources et cibles différentes, vous pouvez modifier les valeurs dans le healthcare#_msft_config_notebook.
Nous vous recommandons de planifier l’exécution de cette tâche de bloc-notes toutes les 4 heures. L’exécution initiale peut ne pas contenir de données à consommer en raison de tâches simultanées et dépendantes, ce qui entraîne une latence. L’ajustement de la fréquence des tâches des couches supérieures peut réduire cette latence.
Après l’exécution du notebook, vous pouvez vérifier si les enregistrements sont correctement ingérés dans la table argent Lakehouse correspondante. Vous pouvez exécuter une requête SELECT sur la table argent Lakehouse, comme indiqué dans l’exemple suivant avec la table Patient :

Lignes directrices pour l’aplatissement de l’argent
L’aplatissement de chaque ressource de domaine FHIR est traité selon les règles suivantes :
Les éléments FHIR primitifs, tels que chaîne, entier et booléen, sont aplatis et codés en types SQL natifs (au format de stockage delta ou parquet). Peu d’exemples de tels éléments FHIR sont
genderetbirthDatedans la ressource Patient .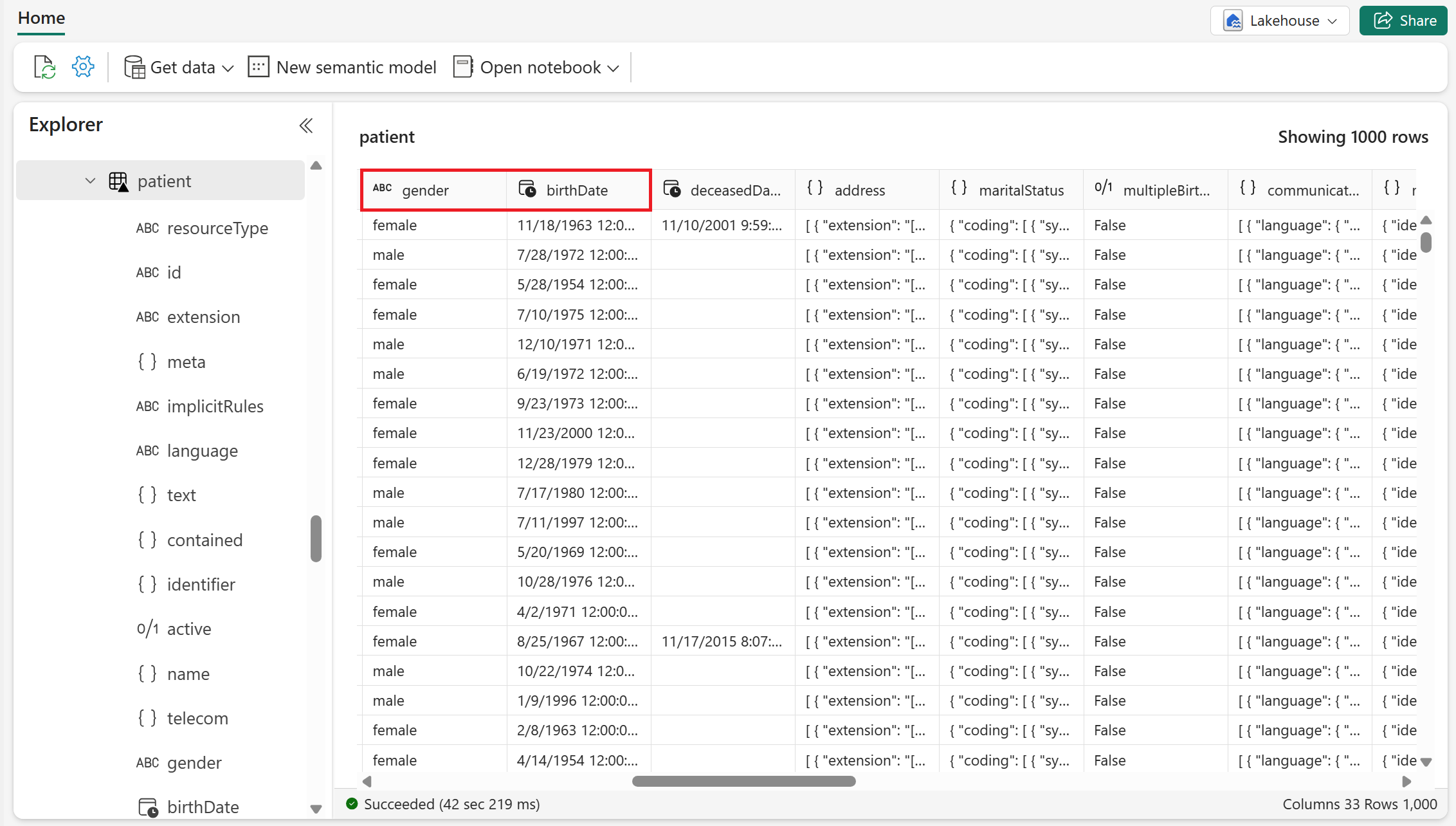
Les éléments FHIR complexes et à valeurs multiples sont conservés sous forme de structures et de tableaux (au format parquet). Peu d’exemples de tels éléments FHIR sont
identifier,nameettelecomdans la ressource Patient .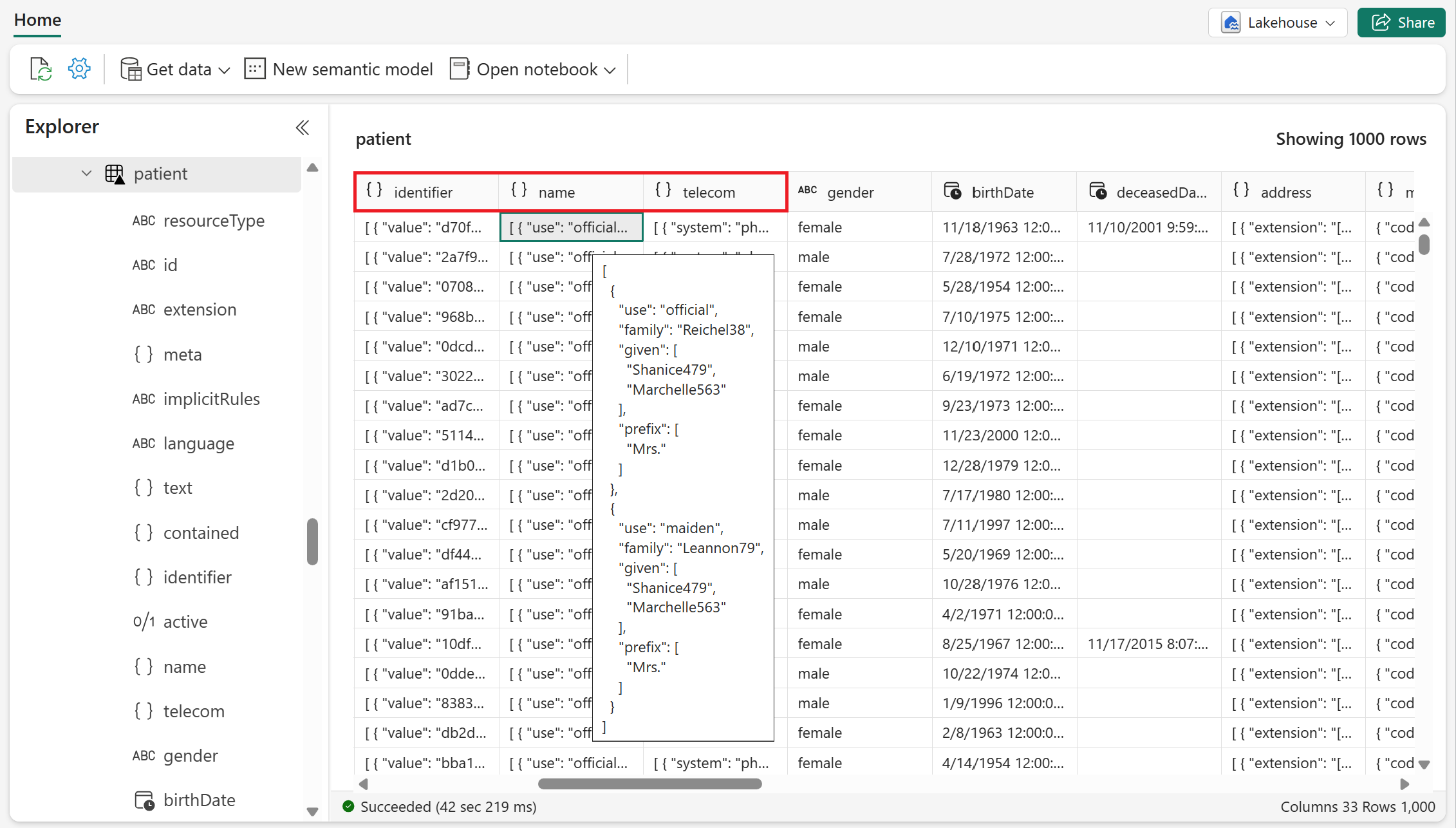
Actuellement, analytique SQL point de terminaison ne fait pas apparaître les types complexes (tels que les structures et les tableaux). Chaque colonne complexe est convertie en une représentation sous forme de chaîne du complexe jeu de données et étiquetée avec un suffixe
_string. Vous pouvez ensuite l’interroger à partir de l’analyse SQL point de terminaison. Peu d’exemples de tels éléments FHIR sontname_string,telecom_stringetidentifier_stringdans la ressource Patient .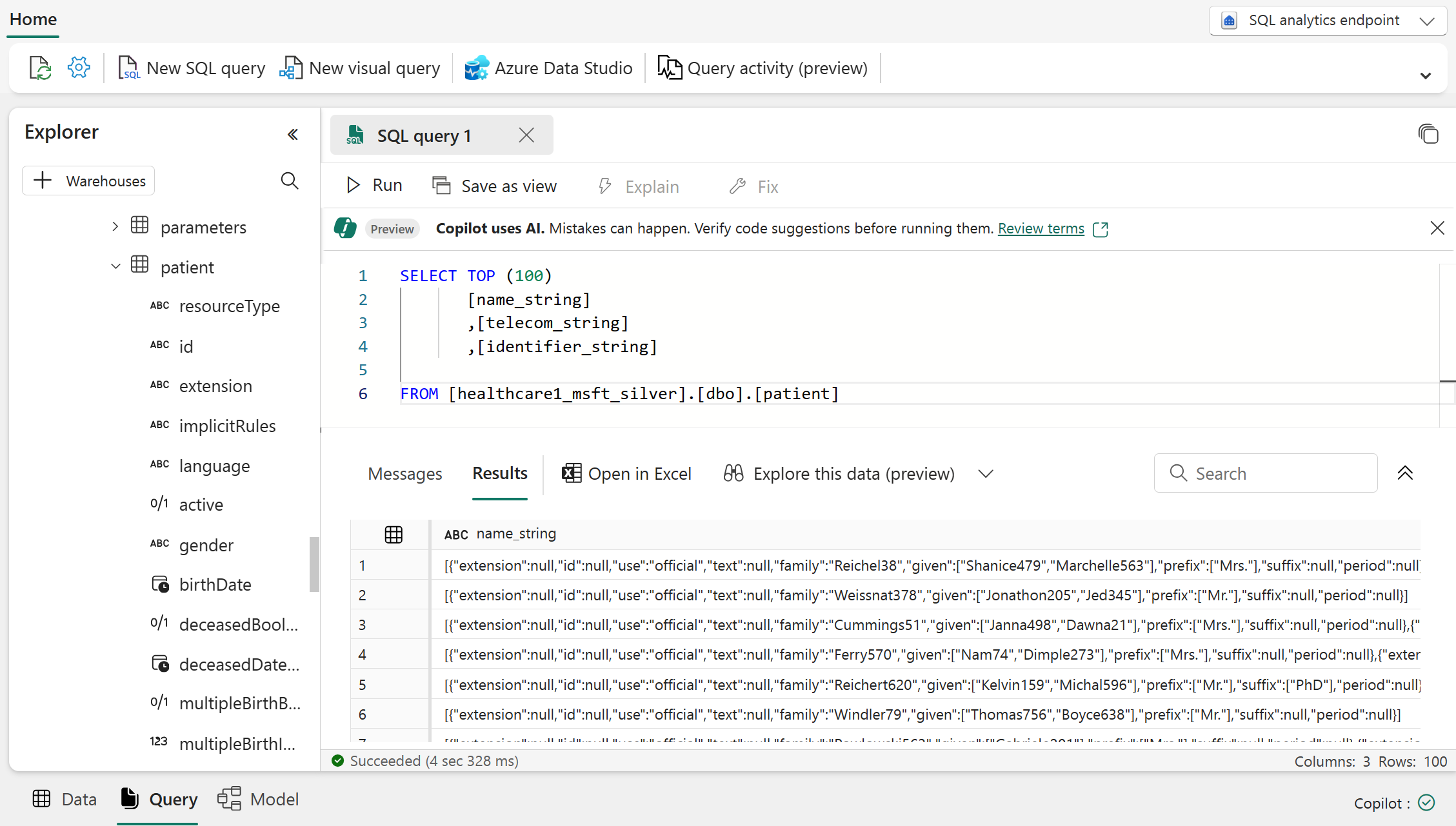



Normalisation
La normalisation est un processus permettant de réduire la redondance des données dans une table et d’améliorer l’intégrité des données. Le système l’effectue comme une étape supplémentaire après l’aplatissement des données et lors de la transformation des données de la couche bronze à la couche argent. Les types de données courants tels que les champs DateHeure et les champs de référence sont normalisés sur la base des HL7 SQL sur FHIR directives :
Une référence unique et un ID de ressource sont normalisés à l’aide des règles suivantes :
Tous les ID de ressources sont normalisés en appliquant la fonction de hachage SHA-256 au format spécifique suivant :
sourceSystemURL/resourceType/resourceId. Ce processus garantit que chaque ressource dispose d’un identifiant cohérent et unique dans tout le système.L’ID d’origine est ensuite conservé sous la forme
id_orig.
Cette approche de normalisation d’un seul objet ressource est utilisée de manière récursive pour normaliser un tableau d’objets de référence et de références imbriquées.
Les éléments FHIR
datesont convertis en UTC et leur valeur d’origine est conservée dans une_origcolonne.