Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
L’API Prompt est une API web expérimentale qui vous permet d’inviter un petit modèle de langage (SLM) intégré à Microsoft Edge, à partir du code JavaScript de votre site web ou de l’extension de navigateur. Utilisez l’API Prompt pour générer et analyser du texte ou créer une logique d’application basée sur l’entrée utilisateur, et découvrez des façons innovantes d’intégrer des fonctionnalités d’ingénierie d’invite dans votre application web.
Contenu détaillé :
- Disponibilité de l’API Prompt
- Alternatives et avantages de l’API Prompt
- Petits modèles de langage intégrés à Microsoft Edge
- Le modèle Phi-4-mini
- Modèle Aion-1.0-Instruct
- Activer l’API d’invite
- Voir un exemple de travail
- Utiliser l’API d’invite
- Envoyer des commentaires
- Voir aussi
Disponibilité de l’API Prompt
L’API Prompt est disponible en préversion pour les développeurs dans les canaux Microsoft Edge Canary et Edge Dev, à compter de la version 138.0.3309.2.
L’API Prompt est destinée à vous aider à découvrir les cas d’usage et à comprendre les défis liés aux SVM intégrées. Cette API devrait être réussie par d’autres API expérimentales pour des tâches spécifiques basées sur l’IA, telles que l’aide à l’écriture et la traduction de texte. Pour en savoir plus sur ces autres API, consultez :
- Résumer, écrire et réécrire du texte avec les API d’aide à l’écriture
- Traduire du texte avec l’API Translator
- Détecter les langues avec l’API Détecteur de langues
Alternatives et avantages de l’API Prompt
Pour tirer parti des fonctionnalités d’IA dans les sites web et les extensions de navigateur, vous pouvez également utiliser les méthodes suivantes :
Envoyez des demandes réseau à des services IA basés sur le cloud, tels que des solutions d’ia Azure.
Exécutez des modèles IA locaux à l’aide de l’API Web Neural Network (WebNN) ou du runtime ONNX pour le web.
L’API Prompt utilise un SLM qui s’exécute sur le même appareil que celui où les entrées et sorties du modèle sont utilisées (c’est-à-dire, localement). Cela présente les avantages suivants par rapport aux solutions basées sur le cloud :
Coût réduit : Il n’y a aucun coût associé à l’utilisation d’un service IA cloud.
Indépendance du réseau : Au-delà du téléchargement initial du modèle, il n’y a aucune latence réseau lors de l’invite du modèle et peut également être utilisé lorsque l’appareil est hors connexion.
Confidentialité améliorée : Les données entrées dans le modèle ne quittent jamais l’appareil et ne sont pas collectées pour entraîner des modèles IA.
L’API Prompt utilise un modèle fourni par Microsoft Edge et intégré au navigateur, qui offre des avantages supplémentaires par rapport aux solutions locales personnalisées telles que celles basées sur WebGPU, WebNN ou WebAssembly :
Coût unique partagé : Le modèle fourni par le navigateur est téléchargé la première fois que l’API est appelée et partagée sur tous les sites web qui s’exécutent dans le navigateur, ce qui réduit les coûts réseau pour l’utilisateur et le développeur.
Utilisation simplifiée pour les développeurs web : Le modèle intégré peut être exécuté à l’aide d’API web simples et ne nécessite pas d’expertise en IA/ML ou en utilisant des infrastructures tierces.
Petits modèles de langage intégrés à Microsoft Edge
Dans les canaux Microsoft Edge Canary et Dev, à compter de la version 138.0.3309.2, l’API Prompt utilise le modèle Phi-4-mini, qui est intégré à Microsoft Edge.
À compter de la version 150.0.4070, l’API Prompt peut également être utilisée avec le modèle Aion-1.0-Instruct préversion, qui est également intégré à Microsoft Edge. Aion-1.0-Instruct est un modèle plus petit, plus rapide et plus efficace que Phi-4-mini, et est pris en charge sur les appareils avec des GPU moins performants ou sans GPU, via l’inférence du processeur. Si la classe de performances de votre appareil n’est pas suffisamment élevée pour prendre en charge Phi-4-mini, vous pouvez tester le modèle Aion-1.0-Instruct préversion.
Pour en savoir plus sur les deux modèles et sur l’activation d’Aion-1.0-Instruct, lisez les sections ci-dessous.
Le modèle Phi-4-mini
L’API Prompt vous permet d’inviter Phi-4-mini, qui est intégré à Microsoft Edge. Phi-4-mini est un modèle de petit langage puissant qui excelle dans les tâches textuelles. Pour en savoir plus sur Phi-4-mini et ses fonctionnalités, consultez le modèle carte sur microsoft/Phi-4-mini-instruct.
Clause d’exclusion de responsabilité
Comme d’autres modèles de langage, la famille de modèles Phi peut potentiellement se comporter de manière injuste, non fiable ou offensante. Pour en savoir plus sur les considérations relatives à l’IA du modèle, consultez Considérations relatives à l’IA responsable.
Configuration matérielle requise
La préversion du développeur de l’API Prompt est destinée à fonctionner sur les appareils dotés de fonctionnalités matérielles qui produisent des sorties SLM avec une qualité et une latence prévisibles. L’API Prompt est actuellement limitée à :
Système d’exploitation : Windows 10 ou 11 et macOS 13.3 ou version ultérieure.
Stockage: Au moins 20 Go disponibles sur le volume qui contient votre profil Edge. Si le stockage disponible tombe en dessous de 10 Go, le modèle est supprimé pour s’assurer que les autres fonctionnalités du navigateur disposent de suffisamment d’espace pour fonctionner.
GPU : 5,5 Go de VRAM ou plus.
Réseau: Forfait de données illimité ou connexion non limitée. Le modèle n’est pas téléchargé si vous utilisez une connexion limitée.
Pour case activée si votre appareil prend en charge la préversion de l’API Prompt, consultez Activer l’API Prompt ci-dessous et case activée la classe de performances de votre appareil.
En raison de la nature expérimentale de l’API Prompt, vous pouvez observer des problèmes sur des configurations matérielles spécifiques. Si vous rencontrez des problèmes sur des configurations matérielles spécifiques, envoyez vos commentaires en ouvrant un nouveau problème dans le référentiel MSEdgeExplainers.
Disponibilité du modèle Phi-4-mini
Un téléchargement initial du modèle Phi-4-mini est nécessaire la première fois qu’un site web appelle une API qui nécessite un modèle sur l’appareil. Vous pouvez surveiller le téléchargement du modèle Phi-4-mini à l’aide de l’option monitor lors de la création d’une session d’API d’invite. Pour en savoir plus, consultez Surveiller la progression du téléchargement du modèle ci-dessous.
Modèle Aion-1.0-Instruct
Dans Microsoft Edge Canary ou Edge Dev, à compter de la version 150.0.4070, l’API Prompt peut également être utilisée avec le modèle Aion-1.0-Instruct préversion, qui est intégré à Microsoft Edge.
Ce modèle Aion-1.0-Instruct est beaucoup plus petit, plus rapide et plus efficace que Phi-4-mini, et est pris en charge sur les appareils avec des GPU moins performants ou sans GPU, via l’inférence du processeur.
Aion-1.0-Instruct devrait être mis à disposition en tant que modèle open source en juillet 2026.
Activer Aion-1.0-Instruct pour l’API Prompt
Par défaut, l’API Prompt utilise le modèle Phi-4-mini. Pour utiliser Aion-1.0-Instruct dans Microsoft Edge Canary ou Edge Dev, activez l’indicateur Activer la préversion du modèle de langage sur l’appareil , comme décrit dans les étapes ci-dessous. Lorsque cet indicateur est activé, Aion-1.0-Instruct remplace Phi-4-mini comme modèle par défaut pour l’API Prompt.
Vérifiez que vous utilisez la dernière version de Edge Canary ou Edge Dev (version 150.0.4070 ou ultérieure). Consultez Devenir un Insider Microsoft Edge.
Dans Edge Canary ou Edge Dev, ouvrez un nouvel onglet ou une nouvelle fenêtre, puis accédez à
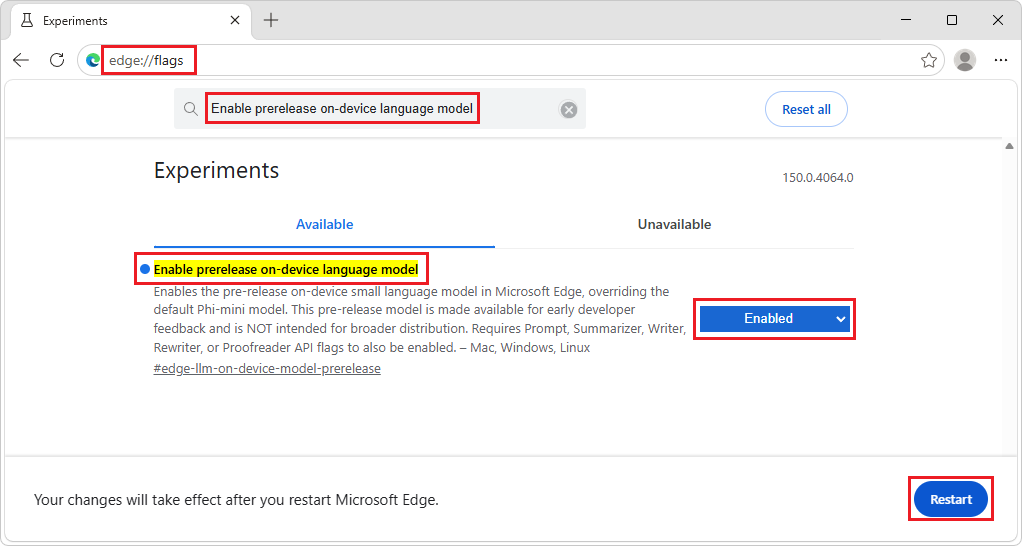
edge://flags.Dans la zone de recherche en haut de la page, entrez Activer le modèle de langue de préversion sur l’appareil.
Dans la liste déroulante Activer la préversion du modèle de langage sur l’appareil , sélectionnez Activé, puis cliquez sur le bouton Redémarrer :
Pour case activée que Aion-1.0-Instruct est utilisé comme modèle de langage sur l’appareil, accédez à
edge://on-device-internals, cliquez sur État du modèle et case activée que Nom du modèle est défini sur Aion-1.0-Instruct.
Clause d’exclusion de responsabilité
Le modèle Aion-1.0-Instruct est disponible dans Microsoft Edge 150.0.4070 pour les premiers tests et commentaires des développeurs. Outre les considérations relatives à l’IA responsable répertoriées ci-dessus, notez que, compte tenu de son état de préversion, les comportements et les fonctionnalités du modèle sont susceptibles d’être modifiés.
Disponibilité du modèle Aion-1.0-Instruct
Un téléchargement initial du modèle Aion-1.0-Instruct est nécessaire la première fois qu’un site web appelle une API qui nécessite un modèle sur l’appareil. Vous pouvez surveiller le téléchargement du modèle Aion-1.0-Instruct à l’aide de l’option monitor lors de la création d’une session d’API Prompt. Pour en savoir plus, consultez Surveiller la progression du téléchargement du modèle ci-dessous.
Activer l’API d’invite
Pour utiliser l’API Prompt dans Microsoft Edge :
Vérifiez que vous utilisez la dernière version de Microsoft Edge Canary ou Edge Dev (version 138.0.3309.2 ou ultérieure). Consultez Devenir un Insider Microsoft Edge.
Dans Edge Canary ou Edge Dev, ouvrez un nouvel onglet ou une nouvelle fenêtre, puis accédez à
edge://flags/.Dans la zone de recherche, en haut de la page, entrez API d’invite pour le modèle de langue sur l’appareil.
La page est filtrée pour afficher l’indicateur correspondant.
Sous API d’invite pour le modèle de langage sur l’appareil, sélectionnez Activé :

Si vous le souhaitez, pour journaliser localement des informations qui peuvent être utiles pour le débogage des problèmes, activez également l’indicateur Activer sur le modèle IA de débogage de l’appareil .
Redémarrez Edge Canary ou Edge Dev.
Pour case activée si votre appareil répond à la configuration matérielle requise pour la préversion de l’API Demander aux développeurs, ouvrez un nouvel onglet, accédez à
edge://on-device-internalset case activée la valeur de la classe de performances de l’appareil.Si la classe de performances de votre appareil est Élevée ou supérieure, l’API Prompt doit être prise en charge sur votre appareil.
Si la classe de performances de votre appareil est Moyenne ou Faible, l’API Prompt est uniquement prise en charge par le biais du modèle Aion-1.0-Instruct préversion, disponible à partir de la version 150.0.4070 de Edge. Pour tester le modèle Aion-1.0-Instruct, consultez Activer Aion-1.0-Instruct pour l’API Prompt, ci-dessus.
Si vous remarquez des problèmes avec ces modèles, créez un problème dans le dépôt MSEdgeExplainers.
Voir un exemple de travail
Pour voir l’API Prompt en action et passer en revue le code existant qui utilise l’API :
Activez l’API Prompt, comme décrit ci-dessus.
Dans Edge Canary ou Edge Dev, ouvrez un onglet ou une fenêtre et accédez au terrain de jeu de l’API d’invite.
Dans le volet de navigation Jeux d’IA intégrés sur la gauche, l’option Demander est sélectionnée.
Dans la bannière d’informations en haut, case activée le status : il lit initialement Téléchargement de modèle, veuillez patienter :

Une fois le modèle téléchargé, la bannière d’informations indique l’API et le modèle prêts, indiquant que l’API et le modèle peuvent être utilisés :

Si le téléchargement du modèle ne démarre pas, redémarrez Microsoft Edge et réessayez.
L’API Prompt est prise en charge uniquement sur les appareils qui répondent à certaines exigences matérielles. Pour plus d’informations, consultez Configuration matérielle requise ci-dessus.
Si vous le souhaitez, modifiez les valeurs des paramètres d’invite, par exemple :
- Prompt de l’utilisateur
- Invite système
- Schéma de contrainte de réponse
- Autres paramètres>Instructions de l’invite N-shot
Cliquez sur le bouton Demander , en bas de la page.
La réponse est générée dans la section réponse de la page :
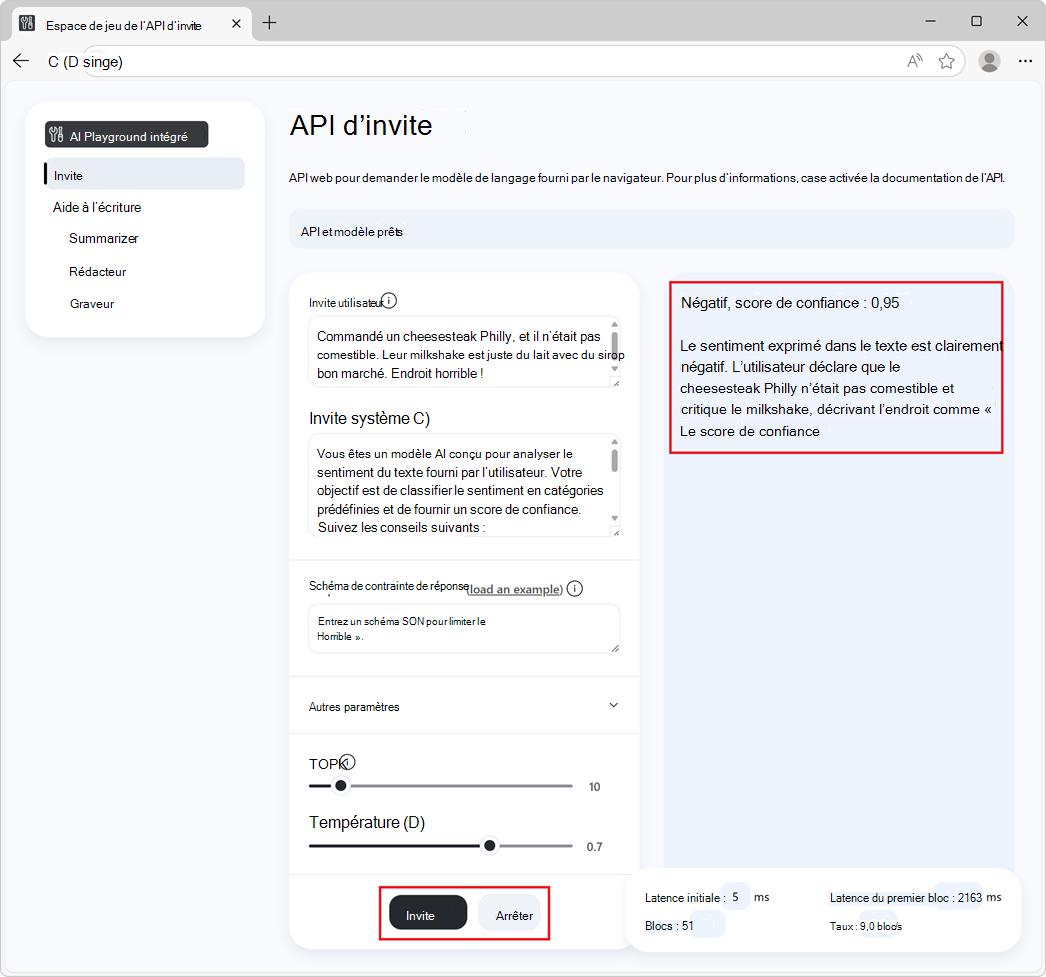
Pour arrêter la génération de la réponse, cliquez à tout moment sur le bouton Arrêter .
Voir aussi :
- /built-in-ai/ : code source et fichier Lisez-moi pour les terrains de jeu d’IA intégrés, y compris le terrain de jeu de l’API Prompt.
Utiliser l’API d’invite
Vérifier si l’API est activée
Avant d’utiliser l’API dans le code de votre site web ou extension, case activée que l’API est activée en testant la présence de l’objet LanguageModel :
if (!LanguageModel) {
// The Prompt API is not available.
} else {
// The Prompt API is available.
}
Vérifier si le modèle peut être utilisé
L’API d’invite ne peut être utilisée que si l’appareil prend en charge l’exécution du modèle et une fois que le modèle de langage et le runtime du modèle ont été téléchargés par Microsoft Edge.
Pour case activée si l’API peut être utilisée, utilisez la LanguageModel.availability() méthode :
const availability = await LanguageModel.availability();
if (availability == "unavailable") {
// The model is not available.
}
if (availability == "downloadable" || availability == "downloading") {
// The model can be used, but it needs to be downloaded first.
}
if (availability == "available") {
// The model is available and can be used.
}
Créer une session
La création d’une session indique au navigateur de charger le modèle de langage en mémoire, afin qu’il puisse être utilisé. Avant de pouvoir inviter le modèle de langage, créez une session à l’aide de la create() méthode :
// Create a LanguageModel session.
const session = await LanguageModel.create();
Pour personnaliser la session de modèle, vous pouvez passer des options à la create() méthode :
// Create a LanguageModel session with options.
const session = await LanguageModel.create(options);
Les options disponibles sont les suivantes :
monitor, pour suivre la progression du téléchargement du modèle.initialPrompts, pour donner au modèle un contexte sur les invites qui seront envoyées au modèle et pour établir un modèle d’interactions utilisateur/assistant que le modèle doit suivre pour les invites ultérieures.
Ces options sont documentées ci-dessous.
Surveiller la progression du téléchargement du modèle
Vous pouvez suivre la progression du téléchargement du modèle à l’aide de l’option monitor . Cela est utile lorsque le modèle n’a pas encore été entièrement téléchargé sur l’appareil où il sera utilisé, pour informer les utilisateurs de votre site web qu’ils doivent attendre.
// Create a LanguageModel session with the monitor option to monitor the model
// download.
const session = await LanguageModel.create({
monitor: m => {
// Use the monitor object argument to add an listener for the
// downloadprogress event.
m.addEventListener("downloadprogress", event => {
// The event is an object with the loaded and total properties.
if (event.loaded == event.total) {
// The model is fully downloaded.
} else {
// The model is still downloading.
const percentageComplete = (event.loaded / event.total) * 100;
}
});
}
});
Fournir au modèle une invite système
Pour définir une invite système, qui est un moyen de donner au modèle des instructions à utiliser lors de la génération de texte en réponse à une invite, utilisez l’option initialPrompts .
L’invite système que vous fournissez lors de la création d’une session est conservée pendant toute l’existence de la session, même si la fenêtre de contexte déborde en raison d’un trop grand nombre d’invites.
// Create a LanguageModel session with a system prompt.
const session = await LanguageModel.create({
initialPrompts: [{
role: "system",
content: "You are a helpful assistant."
}]
});
Le fait de placer l’invite { role: "system", content: "You are a helpful assistant." } n’importe où à la 0e position dans initialPrompts rejette avec un TypeError.
Invite N-shot avec initialPrompts
L’option initialPrompts vous permet également de fournir des exemples d’interactions utilisateur/assistant que vous souhaitez que le modèle continue à utiliser lorsque vous y êtes invité.
Cette technique est également appelée invite en N-shot et est utile pour rendre les réponses générées par le modèle plus déterministes.
// Create a LanguageModel session with multiple initial prompts, for N-shot
// prompting.
const session = await LanguageModel.create({
initialPrompts: [
{ role: "system", content: "Classify the following product reviews as either OK or Not OK." },
{ role: "user", content: "Great shoes! I was surprised at how comfortable these boots are for the price. They fit well and are very lightweight." },
{ role: "assistant", content: "OK" },
{ role: "user", content: "Terrible product. The manufacturer must be completely incompetent." },
{ role: "assistant", content: "Not OK" },
{ role: "user", content: "Could be better. Nice quality overall, but for the price I was expecting something more waterproof" },
{ role: "assistant", content: "OK" }
]
});
Cloner une session pour recommencer la conversation avec les mêmes options
Clonez une session existante pour inviter le modèle à l’insu des interactions précédentes, mais avec les mêmes options de session.
Le clonage d’une session est utile lorsque vous souhaitez utiliser les options d’une session précédente, mais sans influencer le modèle avec les réponses précédentes.
// Create a first LanguageModel session.
const firstSession = await LanguageModel.create({
initialPrompts: [
role: "system",
content: "You are a helpful assistant."
]
});
// Later, create a new session by cloning the first session to start a new
// conversation with the model, but preserve the first session's settings.
const secondSession = await firstSession.clone();
Demander au modèle
Pour inviter le modèle, une fois que vous avez créé une session de modèle, utilisez les session.prompt() méthodes ou session.promptStreaming() .
Attendez la réponse finale
La prompt méthode retourne une promesse qui se résout une fois que le modèle a fini de générer du texte en réponse à votre invite :
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model and wait for the response to be generated.
const result = await session.prompt(promptString);
// Use the generated text.
console.log(result);
Afficher les jetons au fur et à mesure qu’ils sont générés
La promptStreaming méthode retourne immédiatement un objet stream. Utilisez le flux pour afficher les jetons de réponse au fur et à mesure qu’ils sont générés :
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model.
const stream = session.promptStreaming(myPromptString);
// Use the stream object to display tokens that are generated by the model, as
// they are being generated.
for await (const chunk of stream) {
console.log(chunk);
}
Vous pouvez appeler les prompt méthodes et promptStreaming plusieurs fois dans le même objet de session pour continuer à générer du texte basé sur les interactions précédentes avec le modèle au sein de cette session.
Limiter la sortie du modèle à l’aide d’un schéma JSON ou d’une expression régulière
Pour rendre le format des réponses du modèle plus déterministe et plus facile à utiliser par programmation, utilisez l’option responseConstraint lorsque vous invitez le modèle.
L’option responseConstraint accepte un schéma JSON ou une expression régulière :
Pour que le modèle réponde avec un objet JSON stringifié qui suit un schéma donné, définissez
responseConstraintsur le schéma JSON que vous souhaitez utiliser.Pour que le modèle réponde avec une chaîne qui correspond à une expression régulière, définissez
responseConstraintsur cette expression régulière.
L’exemple suivant montre comment faire en sorte que le modèle réponde à une invite avec un objet JSON qui suit un schéma donné :
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Define a JSON schema for the Prompt API to constrain the generated response.
const schema = {
"type": "object",
"required": ["sentiment", "confidence"],
"additionalProperties": false,
"properties": {
"sentiment": {
"type": "string",
"enum": ["positive", "negative", "neutral"],
"description": "The sentiment classification of the input text."
},
"confidence": {
"type": "number",
"minimum": 0,
"maximum": 1,
"description": "A confidence score indicating certainty of the sentiment classification."
}
}
}
;
// Prompt the model, by providing a system prompt and the JSON schema in the
// responseConstraints option.
const response = await session.prompt(
"Ordered a Philly cheesesteak, and it was not edible. Their milkshake is just milk with cheap syrup. Horrible place!",
{
initialPrompts: [
{
role: "system",
content: "You are an AI model designed to analyze the sentiment of user-provided text. Your goal is to classify the sentiment into predefined categories and provide a confidence score. Follow these guidelines:\n\n- Identify whether the sentiment is positive, negative, or neutral.\n- Provide a confidence score (0-1) reflecting the certainty of the classification.\n- Ensure the sentiment classification is contextually accurate.\n- If the sentiment is unclear or highly ambiguous, default to neutral.\n\nYour responses should be structured and concise, adhering to the defined output schema."
},
],
responseConstraint: schema
}
);
L’exécution du code ci-dessus retourne une réponse qui contient un objet JSON stringifié tel que :
{"sentiment": "negative", "confidence": 0.95}
Vous pouvez ensuite utiliser la réponse dans votre logique de code en l’analysant à l’aide de la JSON.parse() fonction :
// Parse the JSON string generated by the model and extract the sentiment and
// confidence values.
const { sentiment, confidence } = JSON.parse(response);
// Use the values.
console.log(`Sentiment: ${sentiment}`);
console.log(`Confidence: ${confidence}`);
Envoyer plusieurs messages par invite
En plus des chaînes, les prompt méthodes et promptStreaming acceptent également un tableau d’objets qui est utilisé pour envoyer plusieurs messages avec des rôles personnalisés. Les objets que vous envoyez doivent être au format { role, content }, où role est user ou assistant, et content est le message.
Par exemple, pour fournir plusieurs messages utilisateur et un message assistant dans la même invite :
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model by sending multiple messages at once.
const result = await session.prompt([
{ role: "user", content: "First user message" },
{ role: "user", content: "Second user message" },
{ role: "assistant", content: "The assistant message" }
]);
Arrêter la génération de texte
Pour abandonner une invite avant la résolution de la promesse retournée par session.prompt() ou avant la fin du flux retourné par session.promptStreaming() , utilisez un AbortController signal :
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Create an AbortController object.
const abortController = new AbortController();
// Prompt the model by passing the AbortController object by using the signal
// option.
const stream = session.promptStreaming(myPromptString , {
signal: abortController.signal
});
// Later, perhaps when the user presses a "Stop" button, call the abort()
// method on the AbortController object to stop generating text.
abortController.abort();
Détruire une session
Détruisez la session pour informer le navigateur que vous n’avez plus besoin du modèle de langage, afin que le modèle puisse être déchargé de la mémoire.
Vous pouvez détruire une session de deux manières différentes :
- À l’aide de la
destroy()méthode . - À l’aide d’un
AbortController.
Détruire une session à l’aide de la méthode destroy()
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Later, destroy the session by using the destroy method.
session.destroy();
Détruire une session à l’aide d’un AbortController
// Create an AbortController object.
const controller = new AbortController();
// Create a LanguageModel session and pass the AbortController object by using
// the signal option.
const session = await LanguageModel.create({ signal: controller.signal });
// Later, perhaps when the user interacts with the UI, destroy the session by
// calling the abort() function of the AbortController object.
controller.abort();
Envoyer des commentaires
La préversion du développeur de l’API Prompt est destinée à vous aider à découvrir les cas d’utilisation pour les modèles de langage fournis par le navigateur.
Nous aimerions en savoir plus sur les points suivants :
- La gamme de scénarios pour lesquels vous envisagez d’utiliser l’API Invite.
- Tout problème avec l’API Prompt.
- Tout problème avec les modèles de langage.
- Indique si de nouvelles API spécifiques à une tâche sont utiles.
Pour envoyer des commentaires sur vos scénarios et les tâches que vous souhaitez accomplir, ajoutez un commentaire au problème Demander des commentaires sur l’API.
Si vous remarquez des problèmes lors de l’utilisation de l’API à la place, signalez-le sur le dépôt.
Vous pouvez également contribuer à la discussion sur la conception de l’API Prompt dans le référentiel W3C Web Machine Learning Working Group.
Voir aussi
- Demander un brouillon de spécification d’API
- dépôt GitHub webmachinelearning/prompt-api
- Écrire, réécrire et résumer du texte avec les API d’aide à l’écriture
- Corriger les erreurs de grammaire, d’orthographe et de ponctuation dans le texte avec l’API Proofreader
- Traduire du texte avec l’API Translator
- /built-in-ai/ : code source et fichier Lisez-moi pour les terrains de jeu d’IA intégrés, y compris le terrain de jeu de l’API Prompt.