Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article s’adresse aux modélisateurs de données qui développent des modèles composites Power BI Desktop. Il décrit les cas d’utilisation des modèles composites et donne des conseils de conception. Plus précisément, il vous permet de déterminer si un modèle composite est adapté à votre solution. Si c’est le cas, cet article vous aidera également à concevoir des modèles et des rapports composites optimaux.
Notes
L’introduction aux modèles composites n’est pas abordée dans cet article. Si vous ne connaissez pas les modèles composites, nous vous recommandons de lire d’abord l’article Utiliser des modèles composites dans Power BI Desktop.
Étant donné que les modèles composites se composent d’au moins une source DirectQuery, il est également important de bien comprendre les relations entre les modèles, les modèles DirectQuery et l’aide à la conception de modèles DirectQuery.
Cas d’utilisation des modèles composites
Par définition, un modèle composite combine plusieurs groupes de sources. Un groupe source peut représenter des données importées ou une connexion à une source DirectQuery. Une source DirectQuery peut être une base de données relationnelle ou un autre modèle tabulaire, qui peut être un modèle sémantique Power BI ou un modèle tabulaire Analysis Services. Lorsqu’un modèle tabulaire se connecte à un autre modèle tabulaire, on parle de chaînage. Pour plus d’informations, consultez Utilisation de DirectQuery pour les modèles sémantiques Power BI et Analysis Services.
Remarque
Lorsqu’un modèle se connecte à un modèle tabulaire mais ne l’étend pas avec des données supplémentaires, il ne s’agit pas d’un modèle composite. Dans ce cas, il s’agit d’un modèle DirectQuery qui se connecte à un modèle distant - il ne comprend donc qu’un groupe source. Vous pouvez créer ce type de modèle pour modifier les propriétés des objets du modèle source, comme le nom d’une table, l’ordre de tri des colonnes ou une chaîne de format.
La connexion à des modèles tabulaires est particulièrement pertinente lors de l’extension d’un modèle sémantique d’entreprise (qu’il s’agisse d’un modèle sémantique Power BI ou d’un modèle Analysis Services). Un modèle sémantique d’entreprise est fondamental pour le développement et le fonctionnement d’un entrepôt de données. Il fournit une couche d’abstraction sur les données de l’entrepôt de données afin de présenter les définitions et la terminologie métier. Il est couramment utilisé en tant que lien entre les modèles de données physiques et les outils de reporting, comme Power BI. Dans la plupart des organisations, il est géré par une équipe centrale, et c’est pourquoi il est décrit comme entreprise. Pour plus d’informations, consultez le scénario d’utilisation BI d’entreprise.
Vous pouvez développer un modèle composite dans les situations suivantes.
- Votre modèle pourrait être un modèle DirectQuery et vous souhaitez améliorer les performances. Dans un modèle composite, vous pouvez améliorer les performances en configurant un stockage approprié pour chaque table. Vous pouvez également ajouter des agrégations définies par l’utilisateur. Ces deux optimisations sont décrites plus loin dans cet article.
- Vous souhaitez combiner un modèle DirectQuery avec des données supplémentaires, qui doivent être importées dans le modèle. Vous pouvez charger des données importées à partir d’une autre source de données ou à partir de tables calculées.
- Vous souhaitez combiner plusieurs sources de données DirectQuery dans un modèle unique. Ces sources peuvent être des bases de données relationnelles ou d’autres modèles tabulaires.
Notes
Les modèles composites ne peuvent pas inclure de connexions à certaines bases de données analytiques externes. Ces bases de données incluent SAP Business Warehouse, et SAP HANA lorsque l’on traite SAP HANA en tant que source multidimensionnelle.
Évaluer d’autres options de conception de modèle
Bien que pouvant résoudre des problèmes de conception particuliers, les modèles composites Power BI contribuent parfois à ralentir les performances. En outre, dans certaines situations, des résultats de calcul inattendus peuvent se produire (voir plus loin dans cet article). Pour ces raisons, évaluez les autres options de conception du modèle lorsqu’elles existent.
Dans la mesure du possible, il est préférable de développer un modèle en mode d’importation. Ce mode offre une plus grande flexibilité de conception et des performances optimales.
Toutefois, les modèles d’importation ne peuvent pas toujours résoudre les problèmes liés aux gros volumes de données ou aux rapports basés sur des données en quasi temps réel. Dans ces deux cas, vous pouvez envisager un modèle DirectQuery, à condition que vos données soient stockées dans une source de données unique prise en charge par le mode DirectQuery. Pour plus d’informations, consultez Modèles DirectQuery dans Power BI Desktop.
Conseil
Si votre objectif est uniquement d’étendre un modèle tabulaire existant avec davantage de données, ajoutez, dans la mesure du possible, ces données à la source de données existante.
Mode Stockage Table
Dans un modèle composite, vous pouvez définir le mode de stockage pour chaque table (à l’exception des tables calculées).
- DirectQuery : nous vous recommandons de définir ce mode pour les tables qui représentent de gros volumes de données ou qui doivent fournir des résultats en quasi temps réel. Les données ne seront jamais importées dans ces tables. En règle générale, ces tables sont des tables de type fait, qui sont des tables résumées.
- Importation : nous vous recommandons de définir ce mode pour les tables qui ne sont pas utilisées pour le filtrage et le regroupement des tables de faits en mode DirectQuery ou Hybrid. Il s’agit également de la seule option pour les tables basées sur des sources non prises en charge par le mode DirectQuery. Les tables calculées sont toujours des tables d’importation.
- Double : nous vous recommandons de définir ce mode pour les tables de type dimension si elles sont potentiellement interrogées avec des tables de type fait DirectQuery à partir de la même source.
- Hybride : nous vous recommandons de définir ce mode en ajoutant des partitions d’importation, et une partition DirectQuery à une table de faits lorsque vous souhaitez inclure les dernières modifications de données en temps réel, ou lorsque vous souhaitez fournir un accès rapide aux données les plus fréquemment utilisées par le biais des partitions d’importation tout en laissant l’essentiel de données plus rarement utilisées dans l’entrepôt de données.
Plusieurs scénarios sont possibles lorsque Power BI interroge un modèle composite.
- Les requêtes ne concernent que les tables importées ou doubles : Power BI récupère toutes les données du cache du modèle. Ce scénario offre les performances les plus rapides possibles. Il est courant pour les tables de type dimension interrogées par des filtres ou des visuels de segment.
- Interroge une ou plusieurs tables doubles ou tables DirectQuery à partir de la même source : Power BI récupère toutes les données en envoyant une ou plusieurs requêtes natives à la source DirectQuery. Ce scénario offre de bonnes performances, en particulier lorsque les tables sources comportent des index appropriés. Il est courant pour les requêtes qui associent des tables de type dimension et des tables de type fait DirectQuery. Ces requêtes étant de type groupe intrasource, toutes les relations un-à-un ou un-à-plusieurs sont évaluées comme étant des relations régulières.
- Interroge une ou plusieurs tables doubles ou hybrides de la même source : ce scénario est une combinaison des deux scénarios précédents. Power BI récupère les données du cache du modèle lorsqu’elles sont disponibles dans les partitions d’importation, sinon il envoie une ou plusieurs requêtes natives à la source DirectQuery. Il offre des performances plus rapides, car seule une partie des données est interrogée dans l’entrepôt de données, en particulier lorsque des index appropriés existent sur les tables sources. Comme pour les tables doubles de type dimension et les tables de type faits DirectQuery, ces requêtes sont des groupes intra-sources. Par conséquent, toutes les relations un-à-un ou un-à-plusieurs sont évaluées comme des relations régulières.
- Toutes les autres requêtes : ces requêtes impliquent des relations de groupe intersource, Soit parce qu’une table d’importation est associée à une table DirectQuery, soit parce qu’une table double est associée à une table DirectQuery à partir d’une autre source, auquel cas elle se comporte comme une table d’importation. Toutes les relations sont évaluées comme des relations limitées. Cela signifie également que les regroupements appliqués aux tables non DirectQuery doivent être envoyés à la source DirectQuery en tant que sous-requêtes matérialisées (tables virtuelles). Dans ce cas, la requête native peut être inefficace, en particulier pour les jeux de regroupement volumineux.
Suivez par conséquent les recommandations suivantes :
- Demandez-vous bien si un modèle composite est la bonne solution : s’il permet l’intégration au niveau du modèle de différentes sources de données, il présente également des complexités de conception avec des conséquences possibles (décrites ultérieurement dans cet article).
- Définissez le mode de stockage sur DirectQuery lorsque la table est une table de type fait qui stocke de gros volumes de données, ou qu’elle doit fournir des résultats en quasi-temps réel.
- Envisagez d’utiliser le mode hybride en définissant une stratégie d’actualisation incrémentielle et des données en temps réel ou en partitionnant la table de faits à l’aide de TOM, TMSL ou d’un outil tiers. Pour plus d’informations, consultez Actualisation incrémentielle et données en temps réel pour les modèles sémantiques et Scénario d’utilisation de la gestion avancée des modèles de données.
- Définissez le mode de stockage sur Double lorsque la table est une table de type dimension et qu’elle sera interrogée avec des tables de type fait DirectQuery ou hybride basées sur le même groupe source.
- Définissez des fréquences d’actualisation permettant de maintenir la synchronisation du cache de modèle des tables doubles et hybrides (et de toutes les tables calculées dépendantes) avec la ou les bases de données sources.
- Efforcez-vous de garantir l’intégrité des données entre les groupes sources (y compris le cache de modèle), car les relations limitées éliminent les lignes dans les résultats des requêtes lorsque les valeurs des colonnes liées ne correspondent pas.
- Dans la mesure du possible, optimisez les sources de données DirectQuery avec les index appropriés pour obtenir des jointures, filtres et le regroupements efficaces.
Agrégations définies par l’utilisateur
Vous pouvez ajouter des agrégations définies par l’utilisateur aux tables DirectQuery. Leur fonction est d’améliorer les performances des requêtes à grain élevé.
Lorsque les agrégations sont mises en cache dans le modèle, elles se comportent comme des tables d’importation (bien qu’elles ne soient pas utilisables comme une table de modèle). L’ajout d’agrégations d’importation à un modèle DirectQuery donne lieu à un modèle composite.
Notes
Les tables hybrides ne prennent pas en charge les agrégations, car certaines des partitions fonctionnent en mode d’importation. Il n’est pas possible d’ajouter des agrégations au niveau d’une partition DirectQuery individuelle.
Nous vous recommandons de suivre une règle de base pour l’agrégation : son nombre de lignes doit être au moins 10 fois plus petit que la table sous-jacente. Par exemple, si la table sous-jacente stocke un milliard de lignes, la table d’agrégation ne doit pas dépasser 100 millions de lignes. Cette règle garantit un gain de performances adapté au coût de création et de maintenance de l’agrégation.
Relations de groupe intersource
Lorsqu’une relation de modèle s’étend sur des groupes sources, elle est appelée relation de groupes de sources croisées. Les relations entre groupes de sources croisées sont également des relations limitées car il n’y a pas de côté « unique » garanti. Pour plus d’informations, consultez Évaluation des relations.
Notes
Dans certains cas, vous pouvez éviter de créer une relation de groupes de sources croisées. Consultez la rubrique Utiliser les segments de synchronisation plus loin dans cet article.
Lorsque vous définissez des relations entre les groupes de sources croisées, tenez compte des recommandations suivantes.
- Utilisez des colonnes de relation à faible cardinalité : pour de meilleures performances, nous recommandons que les colonnes de relation soient à faible cardinalité, ce qui signifie qu’elles doivent stocker moins de 50 000 valeurs uniques. Cette recommandation est particulièrement vraie lors de la combinaison de modèles tabulaires et pour les colonnes non textuelles.
- Évitez d’utiliser de grandes colonnes de texte dans les relations : si vous devez utiliser des colonnes de texte dans une relation, calculez la longueur de texte attendue pour le filtre en multipliant la cardinalité par la longueur moyenne de la colonne de texte. La longueur de texte possible ne doit pas dépasser 1 000 000 caractères.
- Augmentez la granularité des relations : si possible, créez des relations à un niveau de granularité plus élevé. Par exemple, au lieu de relier une table de dates sur sa clé de date, utilisez plutôt sa clé de mois. Cette approche de conception exige que la table liée comprenne une colonne clé de mois, et les rapports ne pourront pas afficher les faits quotidiens.
- Efforcez-vous d’obtenir une conception de relation simple : créez une relation de groupes de sources croisées uniquement lorsque cela est nécessaire et essayez de limiter le nombre de tables dans le chemin de la relation. Cette approche de conception permettra d’améliorer les performances et d’éviter les chemins de relation ambigus.
Avertissement
Comme Power BI Desktop ne valide pas entièrement les relations de groupes de sources croisées, il est possible de créer des relations ambiguës.
Scénario 1 de relation de groupes de sources croisées
Envisagez un scénario de conception de relation complexe et la façon dont elle pourrait produire des résultats différents, mais valides.
Dans ce scénario, la table Region du groupe source A possède une relation avec la table Date et la table Sales du groupe source B. La relation entre la table Region et la table Date est active, tandis que la relation entre la table Region et la table Sales est inactive. Il existe également une relation active entre la table Region et la table Sales, qui font toutes deux partie du groupe source B. La table Sales comprend une mesure appelée TotalSales, et la table Region comprend deux mesures appelées RegionalSales et RegionalSalesDirect.
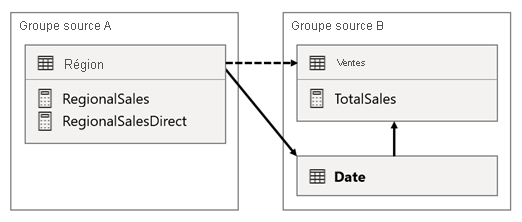
Voici les définitions des mesures.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Notez comment la mesure RegionalSales fait référence à la mesure TotalSales, à la différence de la mesure RegionalSalesDirect. Au lieu de cela, la mesure RegionalSalesDirect utilise l’expression SUM(Sales[Sales]), qui est l’expression de la mesure TotalSales.
La différence est subtile dans le résultat. Lorsque Power BI évalue la mesure RegionalSales, il applique le filtre du tableau Region aux tables Sales et Date. Par conséquent, le filtre se propage également de la table Date à la table Sales. En revanche, en évaluant la mesure RegionalSalesDirect, Power BI ne propage le filtre que de la table Region à la table Sales. Les résultats renvoyés par la mesure RegionalSales et la mesure RegionalSalesDirect peuvent différer même si les expressions sont sémantiquement équivalentes.
Important
Chaque fois que vous utilisez la fonction CALCULATE avec une expression qui est une mesure dans un groupe source distant, testez minutieusement les résultats du calcul.
Scénario 2 de relation de groupes de sources croisées
Envisagez un scénario dans lequel une relation de groupe de sources croisées a des colonnes de relation à cardinalité élevée.
Dans ce scénario, la table Date est liée à la table Sales sur les colonnes DateKey. Le type de données des colonnes DateKey est un nombre entier, stockant des nombres entiers qui utilisent le format aaaammjj. Les tables appartiennent à des groupes de sources différents. En outre, il s’agit d’une relation à cardinalité élevée car la première date de la table Date est le 1er janvier 1900 et la dernière date le 31 décembre 2100. La table contient donc un total de 73 414 lignes (une ligne pour chaque date de la période 1900-2100).
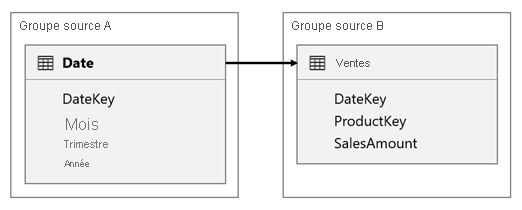
Deux cas nous intéressent.
Tout d’abord, lorsque vous utilisez les colonnes de la table Date comme filtres, la propagation des filtres filtre la colonne DateKey de la table Sales pour évaluer les mesures. Lors d’un filtrage d’une seule année, par exemple 2022, la requête DAX inclut une expression de filtre telle que Sales[DateKey] IN { 20220101, 20220102, …20221231 }. La taille du texte de la requête peut devenir extrêmement importante lorsque le nombre de valeurs dans l’expression du filtre est élevé, ou lorsque les valeurs du filtre sont de longues chaînes de caractères. Il est coûteux pour Power BI de générer la longue requête et pour la source de données d’exécuter la requête.
Deuxièmement, lorsque vous utilisez des colonnes de table Date, comme Année, Trimestre ou Mois, en tant que colonnes de regroupement, il en résulte des filtres qui incluent toutes les combinaisons uniques d’année, de trimestre ou de mois et les valeurs de la colonne DateKey . La taille de la chaîne de la requête, qui contient des filtres sur les colonnes de regroupement et la colonne de relation, peut devenir extrêmement importante. Cela est particulièrement vrai lorsque le nombre de colonnes de regroupement et/ou la cardinalité de la colonne de jointure (colonne DateKey) est élevé.
Pour résoudre tout problème de performance, vous pouvez :
- Ajoutez la table Date à la source de données, ce qui donne un modèle de groupe à source unique (c’est-à-dire qu’il ne s’agit plus d’un modèle composite).
- Augmentez la granularité de la relation. Par exemple, vous pouvez ajouter une colonne MonthKey aux deux tables et créer la relation sur ces colonnes. Cependant, en augmentant la granularité de la relation, vous ne pouvez plus établir de rapports sur l’activité de vente quotidienne (à moins que vous n’utilisiez la colonne DateKey de la table Sales).
Scénario 3 de relation de groupes de sources croisées
Envisagez un scénario dans lequel il n’y a pas de valeurs correspondantes entre les tables dans une relation de groupe de sources croisées.
Dans ce scénario, la table Date du groupe source B a une relation avec la table Ventes de ce groupe source, ainsi qu’avec la table Cible du groupe source A. Toutes les relations sont de type un-à-plusieurs à partir de la table Date qui relie les colonnes Année. La table Sales comprend une colonne SalesAmount qui enregistre les montants des ventes, tandis que la table Target comprend une colonne TargetAmount qui enregistre les montants cibles.
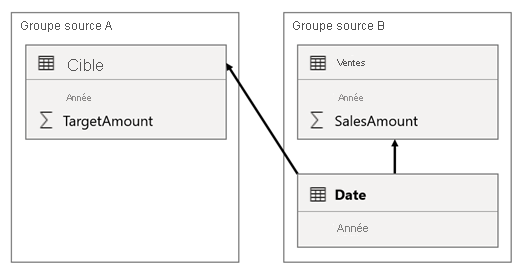
La table Date stocke les années 2021 et 2022. La table Ventes stocke les montants des ventes pour les années 2021 (100) et 2022 (200), tandis que la table Cible stocke les montants cibles pour 2021 (100), 2022 (200) et 2023 (300), une année dans le futur.
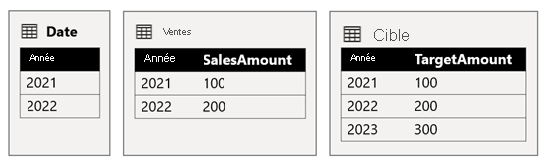
Lorsqu’un visuel de table Power BI interroge le modèle composite en regroupant sur la colonne Year de la table Date et en additionnant les colonnes SalesAmount et TargetAmount, il n’affiche pas de quantité cible pour 2023. Cela est dû au fait que la relation de groupes de sources croisées est une relation limitée et qu’elle utilise donc la sémantique INNER JOIN, qui élimine les lignes sans valeur correspondante des deux côtés. Cela produira toutefois un montant total cible correct (600), car le filtre de la table Date ne s’applique pas à son évaluation.

Si la relation entre la table Date et la table Cible est une relation intragroupe source (en supposant que la table Cible appartient au groupe source B), le visuel comprendra une année vide (Blank) pour indiquer le montant cible de 2023 (et de toute autre année non appariée).
Important
Pour éviter les erreurs de rapport, assurez-vous que les colonnes de relation comportent des valeurs correspondantes lorsque les tables de dimensions et de faits résident dans des groupes sources différents.
Pour plus d’informations sur les relations limitées, voir Évaluation des relations.
Calculs
Vous devez tenir compte des limitations spécifiques lorsque vous ajoutez des colonnes calculées et des groupes de calcul à un modèle composite.
Colonnes calculées
Les colonnes calculées ajoutées à une table DirectQuery avec leurs données provenant d’une base de données relationnelle, comme Microsoft SQL Server, sont limitées aux expressions qui opèrent sur une seule ligne à la fois. Ces expressions ne peuvent pas utiliser les fonctions d’itérateur DAX, comme SUMX, ou les fonctions de modification du contexte de filtrage, comme CALCULATE.
Notes
Il n’est pas possible d’ajouter des colonnes calculées ou des tableaux calculés qui dépendent de modèles tabulaires chaînés.
Une expression de colonne calculée sur une table DirectQuery distante est limitée à l’évaluation intra-ligne uniquement. Bien que vous puissiez créer une telle expression, celle-ci entraîne une erreur lorsqu’elle est utilisée dans un visuel. Par exemple, si vous ajoutez une colonne calculée à une table DirectQuery distante nommée DimProduct en utilisant l’expression [Product Sales] / SUM (DimProduct[ProductSales]), vous pourrez enregistrer l’expression dans le modèle. Cependant, elle entraînera une erreur lorsqu’elle sera utilisée dans un visuel car elle viole la restriction d’évaluation intra-rangée.
En revanche, les colonnes calculées ajoutées à une table DirectQuery distante qui est un modèle tabulaire, qui est soit un modèle sémantique Power BI, soit un modèle Analysis Services, sont plus flexibles. Dans ce cas, toutes les fonctions DAX sont autorisées car l’expression sera évaluée dans le modèle tabulaire source.
De nombreuses expressions nécessitent Power BI pour matérialiser la colonne calculée avant de l’utiliser en tant que groupe ou filtre, ou de l’agréger. Lorsqu’une colonne calculée est matérialisée sur une grande table, elle peut être coûteuse en termes de processeur et de mémoire, en fonction de la cardinalité des colonnes dont dépend la colonne calculée. Dans ce cas, nous vous recommandons d’ajouter ces colonnes calculées au modèle source.
Notes
Lorsque vous ajoutez des colonnes calculées à un modèle composite, veillez à tester tous les calculs du modèle. Les calculs en amont peuvent ne pas fonctionner correctement parce qu’ils n’ont pas pris en compte leur influence sur le contexte du filtre.
Groupes de calcul
Si des groupes de calcul existent dans un groupe source qui se connecte à un modèle sémantique Power BI ou à un modèle Analysis Services, Power BI peut renvoyer des résultats inattendus. Pour plus d’informations, consultez Groupes de calcul, évaluation des requêtes et des mesures.
Conception de modèle
Pour optimiser un modèle Power BI, vous devez adopter une conception de schéma en étoile.
Conseil
Pour plus d’informations, consultez Comprendre le schéma en étoile et son importance pour Power BI.
Veillez à créer des tables de dimensions distinctes des tables de faits afin que Power BI puisse interpréter correctement les jointures et produire des plans de requête efficaces. Bien que s’appliquant à tous les modèles Power BI, ces conseils sont essentiels pour les modèles qui deviendront le groupe source d’un modèle composite. Celui-ci permettra une intégration plus simple et plus efficace d’autres tables dans les modèles en aval.
Dans la mesure du possible, évitez d’avoir des tables de dimension dans un groupe source qui se rapportent à une table de faits dans un groupe source différent. En effet, il est préférable d’avoir des relations intra groupe source que de groupes de sources croisées, en particulier pour les colonnes de relations à forte cardinalité. Comme décrit précédemment, les relations de groupes de sources croisées dépendent de l’existence de valeurs correspondantes dans les colonnes de relation, sinon des résultats inattendus peuvent apparaître dans les visuels du rapport.
Sécurité au niveau des lignes
Si votre modèle comprend des agrégations définies par l’utilisateur, des colonnes calculées sur des tables d’importation ou des tables calculées, assurez-vous que toute sécurité au niveau des lignes (RLS) est configurée correctement et testée.
Si le modèle composite se connecte à d’autres modèles tabulaires, les règles RLS ne sont appliquées que sur le groupe source (modèle local) où elles sont définies. Elles ne seront pas appliquées à d’autres groupes sources (modèles distants). En outre, vous ne pouvez pas définir les règles de sécurité au niveau des lignes sur une table à partir d’un autre groupe source, ni les définir sur une table locale qui a une relation avec un autre groupe source.
Conception de rapports
Dans certaines situations, vous pouvez améliorer les performances d’un modèle composite en concevant une mise en page de rapport optimisée.
Visuels de groupe source unique
Dans la mesure du possible, créez des visuels qui utilisent des champs provenant d’un seul groupe source. En effet, les requêtes générées par des visuels seront plus performantes lorsque le résultat est extrait d’un seul groupe source. Envisagez de créer deux visuels placés côte à côte qui récupèrent les données de deux groupes sources différents.
Utiliser des segments de synchronisation
Dans certaines situations, vous pouvez configurer des segments de synchronisation pour éviter de créer une relation de groupes de sources croisées dans votre modèle. Cela peut vous permettre de combiner visuellement les groupes de sources qui peuvent être plus performants.
Considérons un scénario dans lequel votre modèle comporte deux groupes sources. Chaque groupe de sources dispose d’une table de dimension de produit utilisée pour filtrer les ventes des revendeurs et d’Internet.
Dans ce scénario, le groupe source A contient la table Product qui est liée à la table ResellerSales. Le groupe source B contient la table Product2 qui est liée à la table InternetSales. Il n’y a pas de relations entre les groupes de sources croisées.
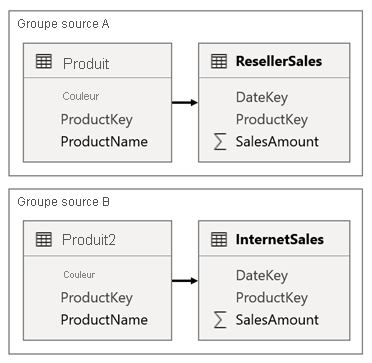
Dans le rapport, vous ajoutez un segment qui filtre la page en utilisant la colonne Color de la table Product. Par défaut, le segment filtre la table ResellerSales, mais pas la table InternetSales. Vous ajoutez ensuite un segment masqué à l’aide de la colonne Color de la table Product2. En définissant un nom de groupe identique (trouvé dans les Options avancées des segments de synchronisation), les filtres appliqués au segment visible se propagent automatiquement au segment masqué.
Notes
Si l’utilisation de segments de synchronisation permet d’éviter la création d’une relation de groupe de sources croisées, elle accroît la complexité de la conception du modèle. Veillez à expliquer aux autres utilisateurs pourquoi vous avez conçu le modèle avec des tableaux de dimensions en double. Évitez toute confusion en masquant les tables de dimension que vous ne voulez pas que les autres utilisateurs utilisent. Vous pouvez également ajouter un texte de description aux tableaux cachés pour documenter leur objectif.
Pour plus d’informations, consultez Synchroniser des segments distincts.
Autres conseils
Voici d’autres conseils pour vous aider à concevoir et à maintenir des modèles composites.
- Performances et évolutivité : Si vos rapports étaient auparavant connectés en direct à un modèle sémantique Power BI ou à un modèle Analysis Services, le service Power BI pourrait réutiliser les caches visuels dans les rapports. Après que vous aurez converti la connexion active pour créer un modèle DirectQuery local, les rapports ne bénéficieront plus de ces caches. Par conséquent, vous pouvez rencontrer un ralentissement des performances, voire des échecs d’actualisation. En outre, la charge de travail du service Power BI augmente, ce qui peut vous obliger à augmenter votre capacité ou à la répartir entre les autres capacités. Pour plus d’informations sur l’actualisation et la mise en cache des données, consultez Actualisation des données dans Power BI.
- Renommer : Nous vous déconseillons de renommer les modèles sémantiques utilisés par les modèles composites, ni de renommer leurs espaces de travail. En effet, les modèles composites se connectent aux modèles sémantiques Power BI en utilisant les noms de l’espace de travail et du modèle sémantique (et non leurs identifiants uniques internes). Renommer un modèle sémantique ou un espace de travail pourrait rompre les connexions utilisées par votre modèle composite.
- Gouvernance : il est déconseillé que votre version unique du modèle de vérité soit un modèle composite. Cela est dû au fait qu’il dépend d’autres sources de données ou modèles, ce qui, s’il est mis à jour, peut entraîner la rupture du modèle composite. Nous vous recommandons plutôt de publier un modèle sémantique d’entreprise comme version unique de la vérité. Considérez ce modèle comme une base fiable. D’autres modélisateurs de données peuvent ensuite créer des modèles composites qui étendent le modèle de base pour créer des modèles spécialisés.
- Lignage des données : utilisez les fonctionnalités de lignage des données et d'analyse d'impact du modèle sémantique avant de publier les modifications du modèle composite. Ces fonctionnalités sont disponibles dans le service Power BI et peuvent vous aider à comprendre comment les modèles sémantiques sont liés et utilisés. Il est important de comprendre que vous ne pouvez pas effectuer d’analyse d’impact sur des modèles sémantiques externes affichés dans la vue lignage mais qui sont en fait situés dans un autre espace de travail. Pour effectuer une analyse d'impact sur un modèle sémantique externe, vous devez accéder à l'espace de travail source.
- Mises à jour de schéma : vous devez actualiser votre modèle composite dans Power BI Desktop lorsque des modifications de schéma sont apportées aux sources de données en amont. Vous devez ensuite republier le modèle dans le service Power BI. Veillez à tester minutieusement les calculs et les rapports dépendants.
Contenu connexe
Pour plus d’informations en rapport avec cet article, consultez les ressources suivantes.
- Utiliser des modèles composites dans Power BI Desktop
- Relations de modèle dans Power BI Desktop
- Modèles DirectQuery dans Power BI Desktop
- Utiliser DirectQuery dans Power BI Desktop
- Utilisation de DirectQuery pour les modèles sémantiques Power BI et Analysis Services
- Mode de stockage dans Power BI Desktop
- Agrégations définies par l’utilisateur
- Vous avez des questions ? Essayez d’interroger la communauté Power BI
- Vous avez des suggestions ? Envoyez-nous vos idées pour améliorer Power BI