Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Power BI Dataflow Gen1 est désormais dans un état hérité et ne recevra pas de nouveaux investissements de fonctionnalités. Pour les clients Premium disposant d’un accès Fabric, Dataflow Gen2 est le chemin recommandé, offrant des améliorations des performances, de la mise à l’échelle, de la fiabilité, des fonctionnalités et de l’IA intégrée. Les clients Pro/PPU peuvent continuer à utiliser Gen1, car les orientations pour Gen2 concernant ces scénarios sont en cours d'élaboration. Pour obtenir des conseils sur la mise à niveau, consultez La mise à niveau de Dataflow Gen1 vers Dataflow Gen2 .
Les flux de données Power BI constituent une solution de préparation des données pour les entreprises, qui permet de disposer d’un écosystème de données prêtes à être consommées, réutilisées et intégrées. Cet article présente des scénarios courants, avec des liens vers d’autres articles et informations pour vous aider à comprendre et utiliser les flux de données de manière optimale.
Accès aux caractéristiques Premium des flux de données
Les flux de données Power BI dans des capacités Premium offrent de nombreuses caractéristiques clés qui permettent d’améliorer la mise à l’échelle et les performances pour vos flux de données, comme :
- Calcul avancé, qui accélère les performances ETL et fournit des fonctionnalités DirectQuery.
- Actualisation incrémentielle, qui vous permet de charger des données qui ont été modifiées à partir d’une source.
- Entités liées, que vous pouvez utiliser pour référencer d’autres flux.
- Entités calculées, que vous pouvez utiliser pour générer des blocs de construction composables de flux de données contenant davantage de logique métier.
Pour ces raisons, nous vous recommandons d’utiliser les flux de données dans une capacité Premium dans la mesure du possible. Les flux de données utilisés dans une licence Power BI Pro peuvent être utilisés pour des cas d’usage simples et à petite échelle.
Solution
L’accès à ces caractéristiques Premium des flux de données est possible de deux manières :
- Désignez une capacité Premium pour un espace de travail donné et apportez votre propre licence Pro pour y créer des flux de données.
- Apportez votre propre licence Premium par utilisateur (PPU) , qui exige que les autres membres de l’espace de travail possèdent également une licence PPU.
Vous ne pouvez pas consommer des flux de données PPU (ni aucun autre contenu) en dehors de l’environnement PPU, comme c'est le cas pour Premium, d'autres SKU ou licences.
Pour les capacités Premium, vos consommateurs de flux de données dans Power BI Desktop n’ont pas besoin de licences explicites pour consommer et publier des contenus sur Power BI. Mais pour publier dans un espace de travail ou partager un modèle sémantique résultant, vous avez besoin d’au moins une licence Pro.
Pour PPU, tout utilisateur qui crée ou consomme des contenus PPU doit disposer d’une licence PPU. Cette exigence varie par rapport au reste de Power BI en ce que vous devez explicitement accorder une licence Premium par utilisateur (PPU) à chacun. Vous ne pouvez pas mélanger des capacités Gratuite, Pro, voire Premium avec du contenu PPU, à moins de migrer l’espace de travail vers une capacité Premium.
Le choix du modèle dépend généralement de la taille et des objectifs de votre organisation, mais les instructions suivantes s’appliquent.
| Type d’équipe | Premium par capacité | Premium par utilisateur |
|---|---|---|
| >5 000 utilisateurs | ✔ | |
| <5 000 utilisateurs | ✔ |
Pour les petites équipes, PPU peut combler les lacunes entre les licences gratuites, Pro et Premium par capacité. Si vos besoins sont plus importants, utiliser une capacité Premium avec les utilisateurs disposant de licences Pro constitue la meilleure approche.
Créer des flux de données d’utilisateur avec sécurité appliquée
Imaginons que vous devez créer des flux de données pour la consommation, mais que vous avez des exigences de sécurité :
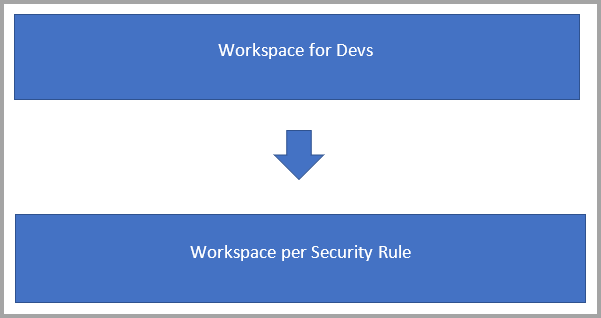
Dans ce scénario, vous disposez probablement de deux types d’espaces de travail :
Espaces de travail principaux dans lesquels vous développez des flux de données et générez la logique métier.
Espaces de travail d’utilisateur final dans lesquels vous souhaitez exposer des flux de données ou des tables à un groupe d’utilisateurs spécifique à des fins de consommation :
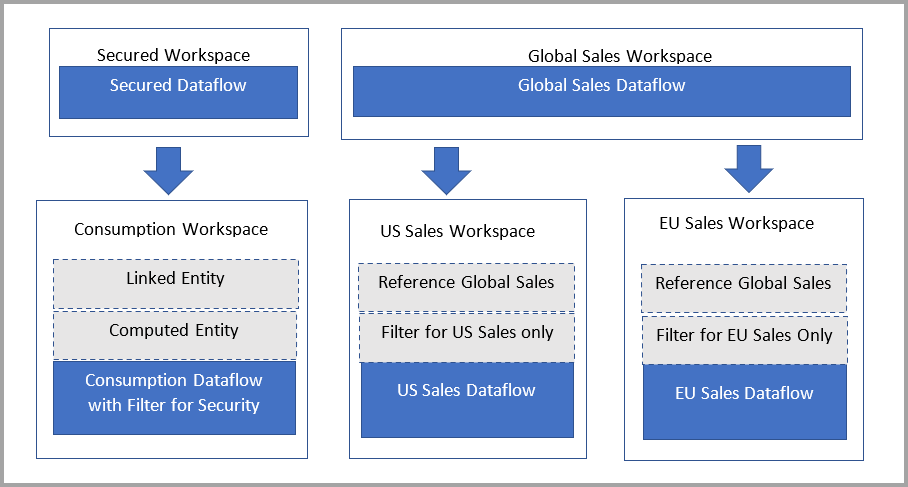
- L’espace de travail d’utilisateur contient des tables liées qui pointent vers les flux de données dans l’espace de travail principal.
- Les utilisateurs peuvent accéder à l’espace de travail de consommateur et ne peuvent pas accéder à l’espace de travail principal.
- Quand un utilisateur utilise Power BI Desktop pour accéder à un flux de données dans l’espace de travail utilisateur, il peut voir le flux de données. Toutefois, étant donné que le flux de données apparaît vide dans le navigateur, les tables liées ne s’affichent pas.
Comprendre les tables liées
Les tables liées sont un simple pointeur vers les tables de flux de données d’origine et elles héritent de l’autorisation de la source. Si Power BI a autorisé la table liée à utiliser l’autorisation de destination, n’importe quel utilisateur peut contourner l’autorisation source en créant une table liée dans la destination qui pointe vers la source.
Solution : utiliser des tables calculées
Si vous avez accès à Power BI Premium, vous pouvez créer une table calculée dans la destination qui fait référence à la table liée, qui contient une copie des données de la table liée. Vous pouvez supprimer des colonnes par le biais de projections et supprimer des lignes à l’aide de filtres. L’utilisateur disposant de l’autorisation sur l’espace de travail de destination peut accéder aux données par le biais de cette table.
La lignée de données pour les utilisateurs privilégiés affiche également l’espace de travail référencé et permet aux utilisateurs de revenir en arrière pour comprendre entièrement le flux de données d'origine. Pour les utilisateurs qui ne sont pas privilégiés, la confidentialité est toujours respectée. Seul le nom de l’espace de travail s’affiche.
Ce diagramme illustre cette configuration. Le modèle architectural est présenté à gauche. À droite, on trouve un exemple montrant comment les données de ventes sont fractionnées et sécurisées par région.
Réduire les temps d’actualisation pour les flux de données
Imaginez que vous avez un flux de données important, mais que vous souhaitez gérer des modèles sémantiques à partir de ce flux de données et réduire le temps nécessaire à leur actualisation. En règle générale, l’actualisation prend beaucoup de temps de la source de données aux flux de données au modèle sémantique. La gestion et la maintenance des actualisations de longue durée s’avèrent difficiles.
Solution : utiliser des tables avec l’option Activer le chargement explicitement configurée pour les tables référencées et ne pas désactiver le chargement
Power BI prend en charge l’orchestration simple pour les flux de données, comme défini dans Compréhension et optimisation de l’actualisation des flux de données. Pour tirer parti de l’orchestration, l’option Activer le chargement doit être explicitement configurée pour les flux de données en aval.
La désactivation du chargement n’est généralement appropriée que lorsque la surcharge du chargement de requêtes supplémentaires annule l’avantage de l’entité avec laquelle vous effectuez le développement.
La désactivation du chargement signifie que Power BI n’évalue pas cette requête donnée quand elle est utilisée en tant qu’ingrédients, c’est-à-dire quand elle est référencée dans d’autres flux de données. Mais cela signifie également que Power BI ne la traite pas comme une table existante dans laquelle nous pouvons spécifier un pointeur et effectuer le Query Folding et les optimisations de requête. Dans ce sens, l’exécution de transformations en tant que jointure ou fusion revient simplement à joindre ou à fusionner deux requêtes de source de données. Ces opérations peuvent avoir un effet négatif sur les performances, car Power BI doit complètement recharger la logique déjà calculée, puis appliquer une logique supplémentaire.
Pour simplifier le traitement des requêtes de votre flux de données et vous assurer que toutes les optimisations du moteur sont effectuées, activez le chargement et assurez-vous que le moteur de calcul dans les flux de données Power BI Premium est défini sur le paramètre par défaut, à savoir Optimisé.
L’activation du chargement vous permet de conserver une vue complète de la traçabilité, car Power BI considère un flux de données de chargement non activé comme un nouvel élément. Si la traçabilité est importante pour vous, ne désactivez pas le chargement pour les entités ou les flux de données connectés à d’autres flux de données.
Réduire les temps d’actualisation pour les modèles sémantiques
Imaginons que vous avez un flux de données volumineux, mais que vous souhaitez générer des modèles sémantiques à partir de celui-ci et réduire l’orchestration. Les actualisations prennent beaucoup de temps de la source de données aux flux de données au modèle sémantique, ce qui augmente la latence.
Solution : utiliser des flux de données DirectQuery
DirectQuery peut être utilisé chaque fois que le paramètre de moteur de calcul amélioré d’un espace de travail (ECE) est explicitement Activé. Ce paramètre est utile pour les données qui n’ont pas besoin d’être chargées directement dans un modèle Power BI. Si vous configurez l'ECE pour la première fois sur Activé, les modifications qui autorisent DirectQuery s'appliqueront lors de la prochaine actualisation. Vous devez l’actualiser lorsque vous l’activez pour que les modifications soient effectuées immédiatement. Les actualisations sur le chargement de flux de données initial peuvent être plus lentes, car Power BI écrit des données dans le stockage et dans un moteur SQL managé.
En résumé, l’utilisation de DirectQuery avec des flux de données apporte les améliorations suivantes à Power BI et à vos processus de flux de données :
- Éviter les planifications d’actualisation distinctes : DirectQuery se connecte directement à un flux de données, ce qui élimine la nécessité de créer un modèle sémantique importé. Ainsi, l’utilisation de DirectQuery avec vos flux de données signifie que vous n’avez plus besoin de planifications d’actualisation distinctes pour le flux de données et pour le modèle sémantique pour garantir que vos données sont synchronisées.
- Filtrage des données : DirectQuery est pratique pour travailler sur une vue filtrée des données au sein d’un flux de données. Si vous voulez filtrer les données et ainsi travailler sur un sous-ensemble de données plus petit dans votre flux de données, vous pouvez utiliser DirectQuery (et le moteur ECE) pour filtrer les données du flux de données et utiliser le sous-ensemble filtré dont vous avez besoin.
En règle générale, l’utilisation de DirectQuery permet d’échanger des données à jour dans votre modèle sémantique avec des performances de rapport plus lentes par rapport au mode d’importation. Envisagez cette approche uniquement dans les cas suivants :
- Votre cas d’utilisation nécessite des données à faible latence provenant de votre flux de données.
- Les données du flux de données sont volumineuses.
- Une importation prendrait trop de temps.
- Vous êtes prêt à échanger les performances mises en cache pour les données à jour.
Solution : utiliser le connecteur de flux de données pour activer le repli de requête et l’actualisation incrémentielle pour l’importation
Le connecteur de flux de données unifié peut considérablement réduire le temps d’évaluation des étapes effectuées sur les entités calculées, telles que les opérations de jointure, de distincts, de filtres et de regroupement par. Il existe deux avantages spécifiques :
- Les utilisateurs en aval qui se connectent au connecteur Dataflows dans Power BI Desktop peuvent tirer parti de meilleures performances dans les scénarios de création, car le nouveau connecteur prend en charge le repli de requête.
- Les opérations d’actualisation du modèle sémantique peuvent également se replier sur le moteur de calcul amélioré, ce qui signifie que même l’actualisation incrémentielle à partir d’un modèle sémantique peut se replier sur un flux de données. Cette fonctionnalité améliore les performances d’actualisation et réduit potentiellement la latence entre les cycles d’actualisation.
Pour activer cette caractéristique pour tout flux de données Premium, assurez-vous que le moteur de calcul est explicitement défini sur Activé. Utilisez ensuite le connecteur Dataflows dans Power BI Desktop. Vous devez utiliser la version d’août 2021 de Power BI Desktop ou une version ultérieure pour tirer parti de cette caractéristique.
Pour utiliser cette caractéristique pour les solutions existantes, vous devez utiliser un abonnement Premium ou Premium par utilisateur. Vous devez peut-être également apporter des modifications à votre flux de données, comme décrit dans la section Utilisation du moteur de calcul amélioré. Vous devez mettre à jour les requêtes Power Query existantes pour utiliser le nouveau connecteur en remplaçant PowerBI.Dataflows dans la section Source par PowerPlatform.Dataflows.
Création de flux de données complexe dans Power Query
Imaginons que vous avez un flux de données qui représente des millions de lignes de données que vous souhaitez utiliser pour créer une logique métier et des transformations complexes. Vous souhaitez respecter les meilleures pratiques relatives à l’utilisation des flux de données volumineux. Vous avez également besoin des aperçus de flux de données pour effectuer des exécutions rapides. Toutefois, vous avez des dizaines de colonnes et des millions de lignes de données.
Solution : utiliser la vue Schéma
Vous pouvez utiliser la vue Schéma qui est conçue pour optimiser votre flux quand vous utilisez des opérations au niveau du schéma, en plaçant les informations sur les colonnes de votre requête à l’avant et au centre. La vue Schéma fournit des interactions contextuelles pour mettre en forme votre structure de données. La vue Schéma fournit également des opérations de latence inférieures, car elle a besoin uniquement du calcul des métadonnées de colonne et non des résultats de données complets.
Utiliser des sources de données plus volumineuses
Imaginez que vous exécutez une requête sur le système source, mais que vous ne souhaitez pas fournir un accès direct au système ou démocratiser l’accès. Vous envisagez de placer les données dans un flux de données.
Solution 1 : utiliser une vue pour la requête ou optimiser la requête
L’utilisation d’une source de données optimisée et d’une requête est la meilleure option. Souvent, la source de données fonctionne mieux avec les requêtes qui lui sont destinées. Power Query avance les fonctionnalités de pliage des requêtes pour déléguer ces charges de travail. Power BI fournit également des indicateurs de repli par étape dans Power Query Online. Pour en savoir plus sur les types d'indicateurs, consultez la documentation sur les indicateurs de repliement par étapes.
Solution 2 : utiliser une requête native
Vous pouvez également utiliser la fonction M Value.NativeQuery(). Vous définissez EnableFolding=true dans le troisième paramètre. Les requêtes natives sont documentées sur ce site web pour le connecteur Postgres. Elle fonctionne également pour le connecteur SQL Server.
Solution 3 : fractionner le flux de données en flux de données d’ingestion et de consommation pour tirer parti du moteur ECE et des entités liées
En fractionnant un flux de données en flux d'ingestion et de consommation distincts, vous pouvez tirer parti de l'ECE et des entités liées. Vous pouvez en savoir plus sur ce modèle et d’autres modèles dans la documentation sur les meilleures pratiques.
S’assurer que les clients utilisent des flux de données quand cela est possible
Imaginons que vous avez de nombreux flux de données à des fins courantes, telles que des dimensions conformes comme les clients, tables de données, produits et zones géographiques. Des flux de données sont déjà disponibles dans le ruban pour Power BI. Dans l’idéal, vous souhaitez que les clients utilisent principalement les flux de données que vous avez créés.
Solution : utiliser l’approbation pour certifier et promouvoir des flux de données
Pour en savoir plus sur le fonctionnement de l’approbation, consultez Approbation : promotion et certification de contenu Power BI.
Programmabilité et automatisation dans des flux de données Power BI
Imaginons que vous avez des exigences professionnelles d’automatisation des importations, des exportations ou des actualisations, ainsi que d’orchestration et d’actions supplémentaires en dehors de Power BI. Pour cela, vous avez le choix entre plusieurs options qui sont décrites dans le tableau suivant.
| Type | Mécanisme |
|---|---|
| Utilisez les modèles Power Automate. | Développement sans code |
| Utiliser des scripts d’automatisation dans PowerShell. | Scripts d’automatisation |
| Générer votre propre logique métier à l’aide des API. | API REST |
Pour plus d’informations sur l’actualisation, consultez Compréhension et optimisation de l’actualisation des flux de données.
Garantir la protection des ressources de données en aval
Vous pouvez utiliser des étiquettes de confidentialité pour appliquer une classification des données et toutes les règles que vous avez configurées sur les éléments en aval qui se connectent à vos flux de données. Pour en savoir plus sur les étiquettes de confidentialité, consultez Étiquettes de confidentialité dans Power BI. Pour examiner l’héritage, voir Héritage en aval de l’étiquette de confidentialité dans Power BI.
Prise en charge multigéographique
De nos jours, de nombreux clients ont besoin de respecter des exigences de souveraineté et de résidence des données. Vous pouvez effectuer une configuration manuelle de votre espace de travail de flux de données pour qu’elle soit multi-géographique.
Les flux de données prennent en charge les zones multigéographiques quand ils utilisent la caractéristique « Apportez votre propre compte de stockage ». Cette caractéristique est décrite à la section Configuration du stockage de flux de données pour utiliser Azure Data Lake Gen2. L’espace de travail doit être vide avant d’être joint pour cette fonctionnalité. Avec cette configuration spécifique, vous pouvez stocker des données de flux de données dans les zones géographiques spécifiques de votre choix.
Veillez à protéger les ressources de données derrière un réseau virtuel
De nos jours, de nombreux clients ont besoin de sécuriser les ressources de données derrière un point de terminaison privé. Pour cela, utilisez des réseaux virtuels et une passerelle pour rester conformes. Le tableau suivant décrit la prise en charge actuelle du réseau virtuel et explique comment utiliser des flux de données pour garantir la conformité et protéger vos ressources de données.
| Scénario | État |
|---|---|
| Lire des sources de données de réseau virtuel via une passerelle locale. | Pris en charge par le biais d’une passerelle locale |
| Écrire des données dans un compte associé à une étiquette de sensibilité derrière un réseau virtuel à l’aide d’une passerelle sur site. | Pas encore pris en charge |
Contenu connexe
Les articles suivants vous permettront d’en savoir plus sur les dataflows et Power BI :
- Introduction aux dataflows et à la préparation des données en libre-service
- Créer un flux de données
- Configurer et consommer un dataflow
- Fonctionnalités Premium des dataflows
- Planification de l’implémentation de Power BI - Intégration à d’autres services
- Considérations et limitations relatives aux flux de données
- Bonnes pratiques pour les dataflows