Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Power BI Dataflow Gen1 est désormais dans un état hérité et ne recevra pas de nouveaux investissements de fonctionnalités. Pour les clients Premium disposant d’un accès Fabric, Dataflow Gen2 est le chemin recommandé, offrant des améliorations des performances, de la mise à l’échelle, de la fiabilité, des fonctionnalités et de l’IA intégrée. Les clients Pro/PPU peuvent continuer à utiliser Gen1, car les orientations pour Gen2 concernant ces scénarios sont en cours d'élaboration. Pour obtenir des conseils sur la mise à niveau, consultez La mise à niveau de Dataflow Gen1 vers Dataflow Gen2 .
Avec les dataflows, vous pouvez unifier les données de plusieurs sources et préparer ces données unifiées pour la modélisation. Chaque fois que vous créez un dataflow, vous êtes invité à actualiser les données du flux de données. L’actualisation d’un flux de données est nécessaire avant de pouvoir être consommé dans un modèle sémantique dans Power BI Desktop, ou référencé en tant que table liée ou calculée.
Note
Les flux de données peuvent ne pas être disponibles dans le service Power BI pour tous les clients du Département de la Défense du gouvernement des États-Unis. Pour plus d’informations sur les fonctionnalités disponibles et non, consultez la disponibilité des fonctionnalités Power BI pour les clients du gouvernement américain.
Configurer un dataflow
Pour configurer l’actualisation d’un flux de données, sélectionnez Autres options (points de suspension) et choisissez Paramètres.
Les options Paramètres fournissent de nombreuses options pour votre dataflow, comme décrit dans les sections suivantes.

Prenez possession : Si vous n’êtes pas le propriétaire du flux de données, la plupart de ces paramètres sont désactivés. Pour prendre possession du flux de données, sélectionnez Reprendre le contrôle. Vous êtes invité à fournir des informations d’identification pour vous assurer que vous disposez du niveau d’accès nécessaire.
Connexion de passerelle : Dans cette section, vous pouvez choisir si le flux de données utilise une passerelle et sélectionner la passerelle utilisée. Si vous avez spécifié la passerelle lors de la modification du flux de données, une fois la prise en charge effectuée, il se peut que vous deviez mettre à jour vos informations d'identification en utilisant l'option de modification du flux de données.
Informations d’identification de la source de données : Dans cette section, vous choisissez les informations d’identification utilisées et pouvez modifier la façon dont vous vous authentifiez auprès de la source de données.
Étiquette de confidentialité : Ici, vous pouvez définir la sensibilité des données dans le flux de données. Pour en savoir plus sur les étiquettes de confidentialité, consultez Comment appliquer des étiquettes de confidentialité dans Power BI.
Actualisation planifiée : Ici, vous pouvez définir les heures de la journée où les actualisations de flux de données sélectionnées sont actualisées. Un dataflow peut être actualisé à la même fréquence qu’un modèle sémantique.
Paramètres du moteur de calcul améliorés : Ici, vous pouvez définir si le flux de données est stocké dans le moteur de calcul. Le moteur de calcul permet aux dataflows suivants, qui font référence à ce flux de données, d’effectuer des fusions et des jointures et d’autres transformations plus rapidement que vous le feriez autrement. Il permet également d'effectuer DirectQuery sur le flux de données. Sélectionner Activé garantit que le flux de données fonctionne toujours en mode DirectQuery et que toutes les références tirent parti du moteur. La sélection d’Optimized signifie que le moteur est utilisé uniquement s’il existe une référence à ce flux de données. La sélection désactivée désactive le moteur de calcul et la fonctionnalité DirectQuery pour ce flux de données.
Approbation : Vous pouvez définir si le flux de données est certifié ou promu.
Note
Les utilisateurs disposant d’une licence Pro ou d’une licence Premium par utilisateur (PPU) peuvent créer un flux de données dans un espace de travail Premium.
Caution
Si un espace de travail est supprimé qui contient des dataflows, tous les flux de données de cet espace de travail sont également supprimés. Même si la récupération de l’espace de travail est possible, vous ne pouvez pas récupérer les flux de données supprimés, directement ou via le support de Microsoft.
Actualiser un flux de données
Les flux de données agissent comme des blocs de construction les uns sur les autres. Supposons que vous disposez d’un dataflow appelé Données brutes et d’une table liée appelée Données transformées, qui contient une table liée au dataflow de données brut . Lorsque l’actualisation planifiée du déclencheur du dataflow Raw Data se déclenche, elle déclenche tout flux de données qui y font référence une fois terminée. Cette fonctionnalité crée un effet de chaîne d’actualisations, ce qui vous permet d’éviter d’avoir à planifier manuellement des flux de données. Il existe quelques nuances à prendre en compte lors de la gestion des actualisations des tables liées :
Une table liée est déclenchée par une actualisation uniquement si elle existe dans le même espace de travail.
Une table liée est verrouillée pour modification si une table source est actualisée ou si l’actualisation de la table source est annulée. Si l’un des dataflows d’une chaîne de référence ne parvient pas à s’actualiser, tous les dataflows sont rétablis dans les anciennes données (les actualisations de flux de données sont transactionnelles dans un espace de travail).
Seules les tables référencées sont actualisées lorsqu'elles sont déclenchées par l'achèvement d'une actualisation de la source. Pour planifier toutes les tables, vous devez également définir une actualisation de planification sur la table liée. Évitez de définir une planification d’actualisation sur les dataflows liés pour éviter une double actualisation.
Annuler l’actualisation Les dataflows prennent en charge la possibilité d’annuler une actualisation, contrairement aux modèles sémantiques. Si une actualisation est en cours d’exécution pendant longtemps, vous pouvez sélectionner d’autres options (points de suspension en regard du flux de données), puis sélectionner Annuler l’actualisation.
Actualisation incrémentielle (Premium uniquement) Les flux de données peuvent également être définis pour s’actualiser de manière incrémentielle. Pour ce faire, sélectionnez le flux de données que vous souhaitez configurer pour l’actualisation incrémentielle, puis choisissez l’icône Actualisation incrémentielle .

La définition de l’actualisation incrémentielle ajoute des paramètres au dataflow pour spécifier la plage de dates. Pour plus d’informations sur la configuration de l’actualisation incrémentielle, consultez Utilisation de l’actualisation incrémentielle avec des dataflows.
Il existe certaines circonstances dans lesquelles vous ne devez pas définir l’actualisation incrémentielle :
Les tables liées ne doivent pas utiliser l’actualisation incrémentielle si elles référencent un flux de données. Les dataflows ne prennent pas en charge le pliage des requêtes (même si la table est activée pour DirectQuery).
Les modèles sémantiques référençant des dataflows ne doivent pas utiliser l’actualisation incrémentielle. Les actualisations des flux de données sont généralement performantes, de sorte que les actualisations incrémentielles ne doivent pas être nécessaires. Si les actualisations prennent trop de temps, envisagez d’utiliser le moteur de calcul ou le mode DirectQuery.
Consommer un flux de données
Un dataflow peut être consommé de trois façons :
Créez une table liée à partir du dataflow pour permettre à un autre auteur de flux de données d’utiliser les données.
Créez un modèle sémantique à partir du dataflow pour permettre à un utilisateur d’utiliser les données pour créer des rapports.
Créez une connexion à partir d’outils externes qui peuvent lire à partir du format CDM (Common Data Model).
Utiliser à partir de Power BI Desktop Pour utiliser un dataflow, ouvrez Power BI Desktop et sélectionnez Dataflows dans la liste déroulante Obtenir des données .
Note
Le connecteur Dataflows utilise un ensemble d’informations d’identification différent de celui de l’utilisateur connecté actuel. Cela est conçu pour prendre en charge les utilisateurs multilocataires.
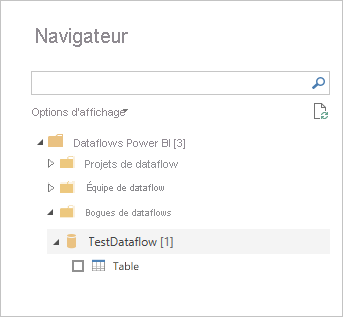
Sélectionnez le flux de données et les tables auxquels vous souhaitez vous connecter.
Note
Vous pouvez vous connecter à n’importe quel flux de données ou table, quel que soit l’espace de travail dans lequel il réside, et s’il a été défini ou non dans un espace de travail Premium ou non Premium.
Si DirectQuery est disponible, vous êtes invité à choisir si vous souhaitez vous connecter aux tables via DirectQuery ou Import.
En mode DirectQuery, vous pouvez interroger rapidement des modèles sémantiques à grande échelle localement. Toutefois, vous ne pouvez pas effectuer de transformations supplémentaires.
L’utilisation de l’importation amène les données dans Power BI et nécessite que le modèle sémantique soit actualisé indépendamment du flux de données.
Contenu connexe
Les articles suivants vous permettront d’en savoir plus sur les dataflows et Power BI :
- Introduction aux flux de données et à la préparation des données en libre-service
- Création d’un flux de données
- Configuration du stockage dataflow pour utiliser Azure Data Lake Gen 2
- Fonctionnalités Premium des dataflows
- Planification de l’implémentation de Power BI - Intégration à d’autres services
- Considérations et limitations relatives aux flux de données
- Bonnes pratiques pour les dataflows