Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit et explique les concepts importants sur les datamarts.
Important
La fonctionnalité datamarts Power BI est mise hors service en octobre 2025. Pour éviter de perdre vos données et d'endommager les rapports construits à partir de datamarts, vous devez mettre à niveau votre datamart Power BI vers un entrepôt. Pour plus d’informations, consultez Unify Datamart avec Fabric Data Warehouse.
Compréhension du modèle sémantique (par défaut)
Les datamarts fournissent une couche sémantique qui est automatiquement générée et synchronisée avec le contenu des tables du datamart, leur structure et les données sous-jacentes. Cette couche est fournie dans un modèle sémantique généré automatiquement. Cette génération et cette synchronisation automatiques vous permettent de décrire davantage le domaine des données avec des éléments tels que les hiérarchies, les noms conviviaux et les descriptions. Vous pouvez également définir une mise en forme spécifique à vos paramètres régionaux ou à vos besoins métier. Avec les datamarts, vous pouvez créer des mesures et des métriques standardisées pour les rapports. Power BI (et d’autres outils clients) peut créer des visuels et fournir des résultats pour de tels calculs en fonction des données en contexte.
Grâce au modèle sémantique Power BI par défaut créé à partir d’un datamart, il n’est plus nécessaire de se connecter à un modèle sémantique distinct, de définir des calendriers d’actualisation et de gérer plusieurs éléments de données. Au lieu de cela, vous pouvez créer votre logique métier dans un datamart et ses données sont immédiatement disponibles dans Power BI, en activant les éléments suivants :
- Accès aux données datamart via le Hub de modèle sémantique.
- Capacité d’analyser dans Excel.
- Capacité de créer rapidement des rapports dans le service Power BI.
- Il n’est pas nécessaire d’actualiser, de synchroniser des données ou de comprendre les détails de connexion.
- Créer des solutions sur le web sans avoir besoin de Power BI Desktop.
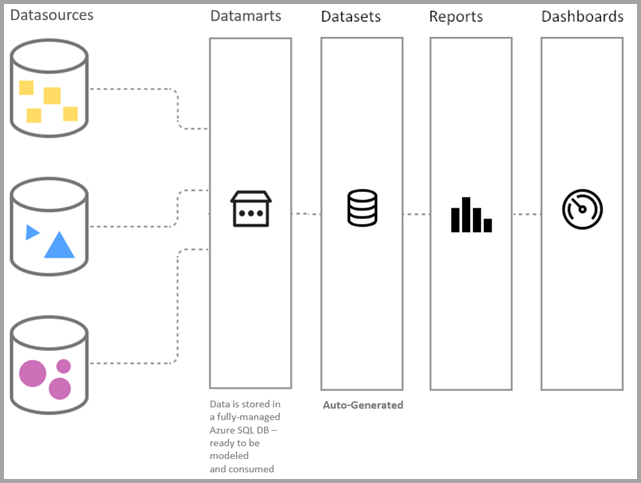
Pendant la préversion, la connectivité du modèle sémantique par défaut n’est disponible qu’à l’aide de DirectQuery. L’image suivante montre comment les datamarts s’intègrent dans le continuum des processus, depuis la connexion aux données jusqu’à la création de rapports.
Les modèles sémantiques par défaut sont différents des modèles sémantiques Power BI traditionnels de la manière suivante :
- Le point de terminaison XMLA prend en charge les opérations en lecture seule et les utilisateurs ne peuvent pas modifier directement le modèle sémantique. Avec l’autorisation XMLA en lecture seule, vous pouvez interroger les données dans une fenêtre de requête.
- Les modèles sémantiques par défaut n’ont pas de paramètres de source de données et les utilisateurs n’ont pas à saisir d’informations d’identification. Ils utilisent plutôt l’authentification unique (SSO) automatique pour les requêtes.
- Pour les opérations d’actualisation, les modèles sémantiques utilisent les informations d’identification de l’auteur du modèle sémantique pour se connecter au point de terminaison SQL du datamart managé.
Avec Power BI Desktop, les utilisateurs peuvent créer des modèles composites, ce qui vous permet de vous connecter au modèle sémantique du datamart et de faire ce qui suit :
- Sélectionner des tables spécifiques à analyser.
- Ajouter d’autres sources de données.
Enfin, si vous ne souhaitez pas utiliser directement le modèle sémantique par défaut, vous pouvez vous connecter au point de terminaison SQL du datamart. Pour plus d’informations, consultez Créer des rapports à l’aide de datamarts.
Compréhension de ce qui se trouve dans le modèle sémantique par défaut
Actuellement, les tables du datamart sont automatiquement ajoutées au modèle sémantique par défaut. Les utilisateurs peuvent également sélectionner manuellement les tables ou vues du datamart qu’ils souhaitent inclure dans le modèle pour plus de flexibilité. Les objets qui se trouvent dans le modèle sémantique par défaut sont créés en tant que disposition dans la vue du modèle.
La synchronisation en arrière-plan qui inclut des objets (tables et vues) attend que le modèle sémantique en aval ne soit pas utilisé pour mettre à jour le modèle sémantique, respectant l’obsolescence limitée. Les utilisateurs peuvent toujours choisir manuellement les tables qu’ils souhaitent ou non dans le modèle sémantique.
Comprendre l’actualisation incrémentielle et les datamarts
Vous pouvez créer et modifier l’actualisation incrémentielle des données, similaire à l’actualisation incrémentielle des flux de données et du modèle sémantique, en utilisant l’éditeur de datamart. L’actualisation incrémentielle étend les opérations d’actualisation planifiées en fournissant une création et une gestion de partition automatisées pour les tables de datamart qui chargent fréquemment des données nouvelles et mises à jour.
Pour la plupart des datamarts, l’actualisation incrémentielle implique une ou plusieurs tables qui contiennent des données de transaction qui changent souvent et peuvent croître de manière exponentielle, comme une table de faits dans un schéma de base de données relationnelle ou étoile. Si vous utilisez une stratégie d’actualisation incrémentielle pour partitionner la table et l’actualisation des partitions importées le plus récemment uniquement, vous pouvez réduire de manière significative la quantité de données qui doivent être actualisées.
L’actualisation incrémentielle et les données en temps réel pour les datamarts offrent les avantages suivants :
- Moins de cycles d’actualisation pour les données qui changent rapidement
- Les actualisations sont plus rapides
- Les actualisations sont plus fiables
- La consommation des ressources est réduite
- Permet de créer des datamarts de grande taille
- Facile à configurer
Présentation de la mise en cache proactive
La mise en cache proactive permet l’importation automatique des données sous-jacentes du modèle sémantique par défaut. Ainsi, vous n’avez pas besoin de gérer ni d’orchestrer le mode de stockage. Le mode d’importation du modèle sémantique par défaut offre une accélération des performances pour le modèle sémantique de datamart à l’aide du rapide moteur Vertipaq. Lorsque vous utilisez la mise en cache proactive, Power BI modifie le mode de stockage de votre modèle à importer, qui utilise le moteur en mémoire dans Power BI et Analysis Services.
La mise en cache proactive fonctionne de la manière suivante : après chaque actualisation, le mode de stockage du modèle sémantique par défaut est modifié en DirectQuery. La mise en cache proactive génère un modèle d’importation côte à côte de façon asynchrone. Elle est gérée par le datamart et n’affecte pas la disponibilité ou les performances du datamart. Les requêtes qui entrent après la fin du modèle sémantique par défaut utilisent le modèle d’importation.
La génération automatique du modèle d’importation se produit au bout de 10 minutes environ si aucune modification n’est détectée dans le datamart. Le modèle sémantique d’importation change de la manière suivante :
- Actualisations
- Nouvelles sources de données
- Modifications du schéma :
- Nouvelles sources de données
- Mises à jour apportées aux étapes de préparation des données dans Power Query Online
- Toutes les mises à jour de modélisation, telles que :
- Mesures
- Hiérarchies
- Descriptions
Meilleures pratiques pour la mise en cache proactive
Utilisez les pipelines de déploiement pour garantir les meilleures performances et vous assurer que les utilisateurs utilisent le modèle d’importation. L’utilisation de pipelines de déploiement est déjà une bonne pratique pour créer des datamarts, mais cela vous permet aussi de tirer parti de la mise en cache proactive plus souvent.
Considérations et limitations relatives à la mise en cache proactive
- Power BI limite actuellement la durée des opérations de mise en cache à 10 minutes.
- Les contraintes d’unicité/non null pour des colonnes particulières sont appliquées dans le modèle d’importation et la génération de cache échoue si les données ne sont pas conformes.
Contenu connexe
Cet article vous a donné un aperçu des concepts importants à comprendre en matière de datamart.
Les articles suivants vous permettront d’en savoir plus sur les datamarts et Power BI :
- Introduction aux datamarts
- Prise en main des datamarts
- Analyse des datamarts
- Créer des rapports à l’aide de datamarts
- Contrôler l’accès aux datamarts
- Administration des datamarts
Pour plus d’informations sur les flux de données et la transformation des données, consultez les articles suivants :