Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Selon votre source de données, des informations sur les types de données et les noms de colonnes peuvent ou non être fournies explicitement. Les API REST OData gèrent généralement cela à l’aide de la définition $metadata, et la méthode Power Query OData.Feed gère automatiquement l’analyse de ces informations et l’applique aux données retournées à partir d’une source OData.
De nombreuses API REST n’ont pas de moyen de déterminer par programme leur schéma. Dans ces cas, vous devez inclure une définition de schéma dans votre connecteur.
Approche codée en dur simple
L’approche la plus simple consiste à encoder en dur une définition de schéma dans votre connecteur. Cela suffit pour la plupart des cas d’usage.
Dans l’ensemble, l’application d’un schéma sur les données retournées par votre connecteur présente plusieurs avantages, tels que :
- Définition des types de données corrects.
- La suppression de colonnes qui n’ont pas besoin d’être affichées aux utilisateurs finaux (par exemple, les ID internes ou les informations d’état).
- S’assurer que chaque page de données a la même forme en ajoutant toutes les colonnes manquantes d’une réponse (les API REST indiquent généralement que les champs doivent être null en les omettant entièrement).
Affichage du schéma existant avec Table.Schema
Considérez le code suivant qui retourne une table simple à partir de l’exemple de service OData TripPin :
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
asTable
Note
TripPin est une source OData, de façon réaliste, il serait plus judicieux d’utiliser simplement la gestion automatique des schémas de la OData.Feed fonction. Dans cet exemple, vous allez traiter la source comme une API REST classique et utiliser Web.Contents pour illustrer la technique de codage en dur d’un schéma manuellement.
Ce tableau est le résultat :
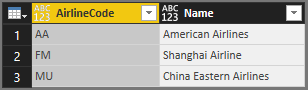
Vous pouvez utiliser la fonction pratique Table.Schema pour vérifier le type de données des colonnes :
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
Table.Schema(asTable)

AirlineCode et Name sont de any type.
Table.Schema retourne beaucoup de métadonnées sur les colonnes d’une table, notamment les noms, les positions, les informations de type et de nombreuses propriétés avancées telles que Precision, Scale et MaxLength. Pour l’instant, vous devez uniquement vous soucier du type attribué (TypeName), du type primitif (Kind) et si la valeur de la colonne peut être nulle (IsNullable).
Définition d’une table de schéma simple
Votre table de schéma se compose de deux colonnes :
| Colonne | Détails |
|---|---|
| Nom | Nom de la colonne. Cela doit correspondre au nom dans les résultats retournés par le service. |
| Type | Type de données M que vous allez définir. Il peut s’agir d’un type primitif (texte, nombre, datetime, etc.) ou d’un type inscrit (Int64.Type, Currency.Type, etc.). |
La table de schéma fixe pour la table Airlines définira ses colonnes AirlineCode et Name à text et ressemblera à ceci :
Airlines = #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
})
À mesure que vous examinez certains des autres points de terminaison, tenez compte des tableaux de schéma suivants :
La Airports table comporte quatre champs que vous souhaitez conserver (y compris l’un des types record) :
Airports = #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
})
La People table comporte sept champs, y compris lists (Emails, AddressInfo), une colonne nullable (Gender) et une colonne avec un type inscrit (Concurrency) :
People = #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})
Vous pouvez placer toutes ces tables dans une seule table SchemaTablede schéma maître :
SchemaTable = #table({"Entity", "SchemaTable"}, {
{"Airlines", Airlines},
{"Airports", Airports},
{"People", People}
})
Fonction d’assistance SchemaTransformTable
La SchemaTransformTablefonction d’assistance décrite ci-dessous est utilisée pour appliquer des schémas sur vos données. Il prend les paramètres suivants :
| Paramètre | Type | Descriptif |
|---|---|---|
| table | table | La table des données sur laquelle vous souhaitez appliquer votre schéma. |
| schéma | table | Table de schéma à partir de laquelle lire les informations de colonne, avec le type suivant : type table [Name = text, Type = type]. |
| enforceSchema | nombre | (facultatif) Énumération qui contrôle le comportement de la fonction. La valeur par défaut ( EnforceSchema.Strict = 1) garantit que la table de sortie correspond à la table de schéma fournie en ajoutant des colonnes manquantes et en supprimant des colonnes supplémentaires. L’option EnforceSchema.IgnoreExtraColumns = 2 peut être utilisée pour conserver des colonnes supplémentaires dans le résultat. Quand EnforceSchema.IgnoreMissingColumns = 3 elle est utilisée, les colonnes manquantes et les colonnes supplémentaires sont ignorées. |
La logique de cette fonction ressemble à ceci :
- Déterminez s’il existe des colonnes manquantes dans la table source.
- Déterminez s’il existe des colonnes supplémentaires.
- Ignorez les colonnes structurées (de type
list,recordettable) et les colonnes définies sur typeany. - Permet
Table.TransformColumnTypesde définir chaque type de colonne. - Réorganisez les colonnes en fonction de l’ordre dans lequel elles apparaissent dans la table de schémas.
- Définissez le type sur la table elle-même à l’aide de
Value.ReplaceType.
Note
La dernière étape pour définir le type de table supprime la nécessité pour l’interface utilisateur power Query de déduire les informations de type lors de l’affichage des résultats dans l’éditeur de requête, ce qui peut parfois entraîner un double appel à l’API.
Tout assembler
Dans le plus grand contexte d’une extension complète, la gestion des schémas aura lieu lorsqu’une table est retournée par l’API. En règle générale, cette fonctionnalité a lieu au niveau le plus bas de la fonction de pagination (le cas échéant), avec des informations d’entité transmises à partir d’une table de navigation.
Étant donné qu’une grande partie de l’implémentation des tables de pagination et de navigation est spécifique au contexte, l’exemple complet d’implémentation d’un mécanisme de gestion de schéma codé en dur ne s’affiche pas ici. Cet exemple TripPin montre comment une solution de bout en bout peut ressembler.
Approche sophistiquée
L’implémentation codée en dur décrite ci-dessus permet de s’assurer que les schémas restent cohérents pour les réponses JSON simples, mais il est limité à l’analyse du premier niveau de la réponse. Les jeux de données profondément imbriqués bénéficient de l’approche suivante, qui tire parti des types M.
Voici une actualisation rapide des types dans la langue M à partir de la spécification du langage :
Une valeur de type est une valeur qui classifie d’autres valeurs. Une valeur classifiée par un type est dite conforme à ce type. Le système de type M se compose des genres de types suivants :
- Types primitifs, qui classifient les valeurs primitives (
binary, ,datedatetimedatetimezonedurationlistlogicalnullnumberrecordtexttimetype) et incluent également un certain nombre de types abstraits (function, ,tableany, et ).none- Types d’enregistrements, qui classifient les valeurs d’enregistrement en fonction des noms de champs et des types valeur.
- Types de listes, qui classifient les listes à l’aide d’un type de base d’élément unique.
- Types de fonction, qui classifient les valeurs de fonction en fonction des types de leurs paramètres et des valeurs de retour.
- Types de tables, qui classifient les valeurs de table en fonction des noms de colonnes, des types de colonnes et des clés.
- Types nullables, qui classifient la valeur Null en plus de toutes les valeurs classées par un type de base.
- Types de type, qui classifient les valeurs qui sont des types.
À l’aide de la sortie JSON brute que vous obtenez (et/ou en recherchant les définitions dans le $metadata du service), vous pouvez définir les types d’enregistrements suivants pour représenter les types complexes OData :
LocationType = type [
Address = text,
City = CityType,
Loc = LocType
];
CityType = type [
CountryRegion = text,
Name = text,
Region = text
];
LocType = type [
#"type" = text,
coordinates = {number},
crs = CrsType
];
CrsType = type [
#"type" = text,
properties = record
];
Notez comment LocationType référence la CityType et les LocType pour représenter ses colonnes structurées.
Pour les entités de niveau supérieur que vous souhaitez représenter en tant que tables, vous pouvez définir des types de tables :
AirlinesType = type table [
AirlineCode = text,
Name = text
];
AirportsType = type table [
Name = text,
IataCode = text,
Location = LocationType
];
PeopleType = type table [
UserName = text,
FirstName = text,
LastName = text,
Emails = {text},
AddressInfo = {nullable LocationType},
Gender = nullable text,
Concurrency Int64.Type
];
Vous pouvez ensuite mettre à jour votre SchemaTable variable (que vous pouvez utiliser comme table de recherche pour les mappages d’entité à type) pour utiliser ces nouvelles définitions de type :
SchemaTable = #table({"Entity", "Type"}, {
{"Airlines", AirlinesType},
{"Airports", AirportsType},
{"People", PeopleType}
});
Vous pouvez vous appuyer sur une fonction commune (Table.ChangeType) pour appliquer un schéma sur vos données, comme vous l’avez utilisé SchemaTransformTable dans l’exercice précédent. Contrairement SchemaTransformTableà , Table.ChangeType prend un type de table M réel en tant qu’argument et applique votre schéma de manière récursive pour tous les types imbriqués. Sa signature est :
Table.ChangeType = (table, tableType as type) as nullable table => ...
Note
Pour plus de flexibilité, la fonction peut être utilisée sur des tables ainsi que sur des listes d’enregistrements (c’est-à-savoir la façon dont les tables sont représentées dans un document JSON).
Vous devez ensuite mettre à jour le code du connecteur pour modifier le schema paramètre d’un table vers un type, puis ajouter un appel à Table.ChangeType. Là encore, les détails de cette opération sont très spécifiques à l’implémentation et ne valent donc pas la peine d’entrer en détail ici.
Cet exemple de connecteur TripPin étendu illustre une solution de bout en bout implémentant cette approche plus sophistiquée de la gestion du schéma.