Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À : Machine Learning Studio (classique)
Machine Learning Studio (classique)  Azure Machine Learning
Azure Machine Learning
Important
Le support de Machine Learning Studio (classique) prend fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
À partir du 1er décembre 2021, vous ne pourrez plus créer de nouvelles ressources Machine Learning Studio (classique). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les ressources Machine Learning Studio (classique) existantes.
- Consultez les informations sur le déplacement des projets de machine learning de ML Studio (classique) à Azure Machine Learning.
- En savoir plus sur Azure Machine Learning
La documentation ML Studio (classique) est en cours de retrait et ne sera probablement plus mise à jour.
Dans cet article, vous allez découvrir les métriques que vous pouvez utiliser pour surveiller les performances de modèles dans Machine Learning Studio (classique). L’évaluation des performances d’un modèle constitue l’une des étapes clés du processus de science des données. Elle indique l’efficacité de la notation (prédictions) d’un jeu de données par un modèle formé. Machine Learning Studio (classique) prend en charge l’évaluation des modèles via deux de ses principaux modules d’apprentissage automatique :
Ces modules vous permettent de déterminer l’efficacité de votre modèle sur le plan du nombre de métriques couramment utilisées dans les domaines de l’apprentissage automatique et des statistiques.
L’évaluation des modèles doit être envisagée avec les éléments suivants :
Il vous présente trois scénarios d’apprentissage supervisé courants :
- régression
- classification binaire ;
- classification multiclasse.
Évaluation et validation croisée
L’évaluation et la validation croisée constituent deux méthodes standard de mesure des performances d’un modèle. Elles génèrent toutes deux des métriques d’évaluation que vous pouvez inspecter ou comparer avec les métriques d’autres modèles.
Le module Évaluer le modèle attend un jeu de données noté en entrée (ou deux jeux si vous souhaitez comparer les performances de deux modèles distincts). Vous devez donc effectuer l’apprentissage de votre modèle à l’aide du module Former le modèle et générer des prédictions sur un jeu de données au moyen du module Noter le modèle avant d’être en mesure d’évaluer les résultats. L’évaluation repose sur les étiquettes/probabilités attribuées et les étiquettes réelles, toutes produites par le module Score Model.
Une autre possibilité consiste à utiliser la validation croisée pour appliquer automatiquement un certain nombre d'opérations d'entraînement, de notation, et d'évaluation (10 partitions) à différents sous-échantillons des données d'entrée. Les données d’entrée sont fractionnées en 10 sous-échantillons, dont l’un est destiné au test et les 9 autres à l’apprentissage. Ce processus est répété à 10 reprises, et la moyenne des métriques d’évaluation est calculée. Cette méthode permet de déterminer la capacité de généralisation d’un modèle pour de nouveaux jeux de données. Le module Effectuer la validation croisée du modèle prend un modèle non entraîné et un jeu de données étiquetées et génère les résultats d’évaluation de chacun des 10 plis, ainsi que les résultats moyens.
Dans les sections qui suivent, nous allons générer des modèles de régression et de classification simples et en évaluer les performances à l’aide des modules Évaluer le modèle et Effectuer la validation croisée du modèle.
Évaluation d’un modèle de régression
Supposons que vous souhaitiez prédire le prix d’une voiture à l’aide de caractéristiques comme les dimensions, le nombre de chevaux, les spécifications du moteur, etc. Il s’agit d’un problème de régression classique, dans lequel la variable cible, price (prix), est une valeur numérique continue. Nous pouvons ajuster un modèle de régression linéaire nous permettant de prédire le prix d’une voiture spécifique en nous basant sur les valeurs de caractéristiques de cette voiture. Il est possible d’utiliser ce modèle de régression pour évaluer le même ensemble de données que nous avons utilisé pour l'entraînement. Une fois que nous avons prédit les prix de toutes les voitures, nous pouvons évaluer les performances du modèle en examinant l’importance de l’écart entre les prédictions et les prix réels en moyenne. Pour illustrer cette approche, nous utilisons le jeu de données Données de prix d'automobile (brut) disponible dans la section Jeux de données enregistrés de Machine Learning Studio (classique).
Création de l’expérience
Ajoutez les modules ci-après à votre espace de travail dans Azure Machine Learning Studio (classique) :
- Données sur le prix des véhicules automobiles (brutes)
- Régression linéaire
- Former le modèle
- Modèle de score
- Évaluer le modèle
Connectez les ports comme illustré ci-après à la Figure 1, puis définissez la colonne Étiquette du module Former le modèle sur price.
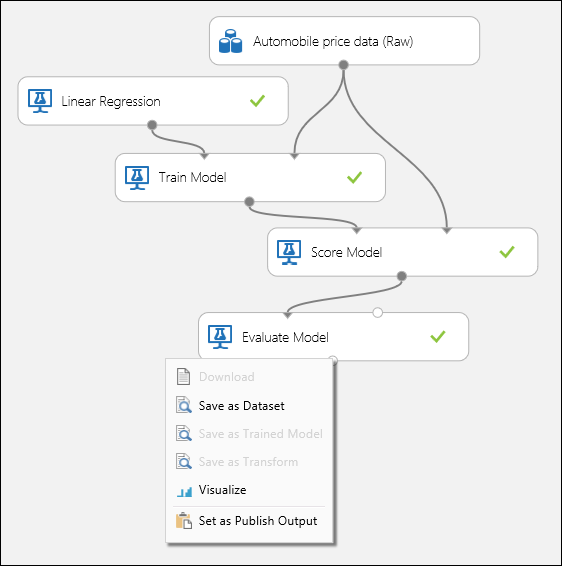
Figure 1. évaluation d’un modèle de régression
Inspection des résultats de l’évaluation
Après avoir exécuté l’expérience, vous pouvez cliquer sur le port de sortie du module Évaluer le modèle et sélectionner Visualiser pour visualiser les résultats de l’évaluation. Les mesures d’évaluation disponibles pour les modèles de régression sont les suivantes : Erreur d’absolue moyenne, Erreur d’absolue moyenne racine, Erreur d’absolue relative, Erreur carrée relative et Coefficient de détermination.
Le terme « erreur » utilisé ici représente la différence entre la valeur prédite et la valeur réelle. La valeur absolue ou le carré de cette différence est généralement calculé pour capturer l’ampleur totale de l’erreur sur l’ensemble des instances, car l’écart entre la valeur prédite et la valeur réelle pourrait être négatif dans certains cas. Les métriques d’erreur mesurent les performances prédictives d’un modèle de régression en termes d’écart moyen entre ses prédictions et les valeurs réelles. Plus les valeurs d’erreur sont faibles, plus les prédictions élaborées par le modèle sont exactes. Une métrique d’erreur globale de zéro signifie que le modèle est parfaitement ajusté par rapport aux données.
Le coefficient de détermination, également désigné sous le terme « R au carré », constitue également une méthode standard de mesure de l’adéquation entre le modèle et les données observées. Ce coefficient peut être considéré comme la proportion de la variance expliquée par le modèle. Dans ce cas précis, plus la proportion est élevée, meilleur est le résultat, la valeur 1 indiquant une adéquation parfaite.
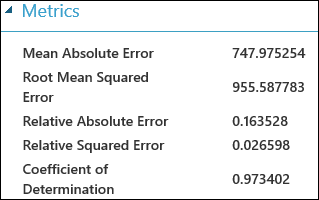
Figure 2 : métriques d’évaluation de régression linéaire
Utilisation de la validation croisée
Comme indiqué précédemment, vous pouvez exécuter automatiquement des opérations répétées d’apprentissage, de notation et d’évaluation à l’aide du module Effectuer la validation croisée du modèle. Pour mener à bien cette tâche, vous avez simplement besoin d’un jeu de données, d’un modèle non formé et d’un module Effectuer la validation croisée du modèle (voir la figure ci-après). Vous devez définir la colonne d’étiquette sur price dans les propriétés du module Cross-Validate Model (Validation croisée d’un modèle).
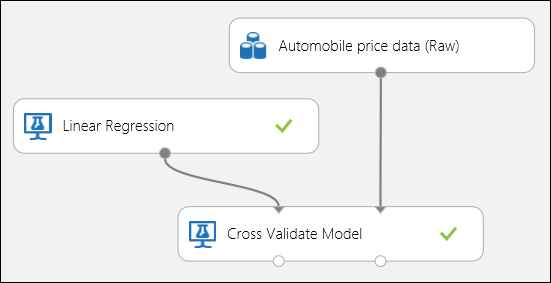
Figure 3. validation croisée d’un modèle de régression
Après avoir exécuté l’expérience, vous pouvez inspecter les résultats de l’évaluation en cliquant sur le port de sortie de droite du module Effectuer la validation croisée du modèle. Vous obtiendrez ainsi une vue détaillée des métriques pour chaque itération (pli), et de la moyenne des résultats de chacun des métriques (Figure 4).
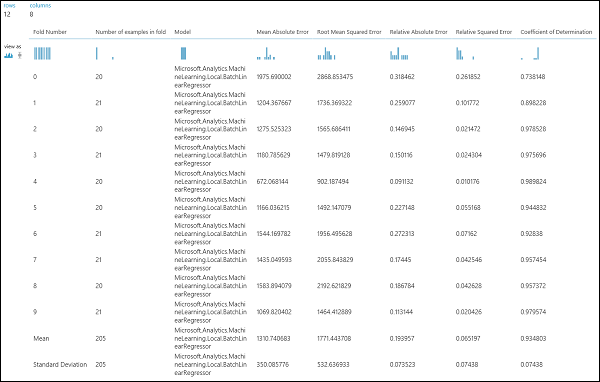
Figure 4. résultats de la validation croisée d’un modèle de régression
Évaluation d’un modèle de classification binaire
Dans un scénario de classification binaire, la variable cible ne peut avoir que deux résultats, par exemple : {0, 1} ou {faux, vrai}, {négatif, positif}. Supposons que vous disposiez d’un jeu de données des employés incluant certaines variables démographiques et d’emploi, et que vous souhaitiez prédire le niveau de revenu, qui constitue une variable binaire avec les valeurs {"<=50 K", ">50 K"}. En d’autres termes, la classe négative représente les employés dont le revenu annuel est inférieur ou égal à 50 K, tandis que la classe positive représente tous les autres employés. Comme dans le scénario de régression, nous allons former un modèle, noter certaines données, puis évaluer les résultats. La principale différence ici réside dans le choix des métriques calculées et générées en sortie par Machine Learning Studio (classique). Pour illustrer le scénario de prédiction du niveau de revenu, nous allons utiliser le jeu de données Adult afin de créer une expérience Studio (classique) et d’évaluer les performances d’un modèle de régression logistique à deux classes, qui constitue un classifieur binaire couramment utilisé.
Création de l’expérience
Ajoutez les modules ci-après à votre espace de travail dans Azure Machine Learning Studio (classique) :
- Jeu de données de classification binaire du revenu du recensement des adultes
- Régression logistique à deux classes
- Former le modèle
- Modèle de score
- Évaluer le modèle
Connectez les ports comme illustré ci-après à la Figure 5, puis définissez la colonne Étiquette du module Former le modèle sur income.
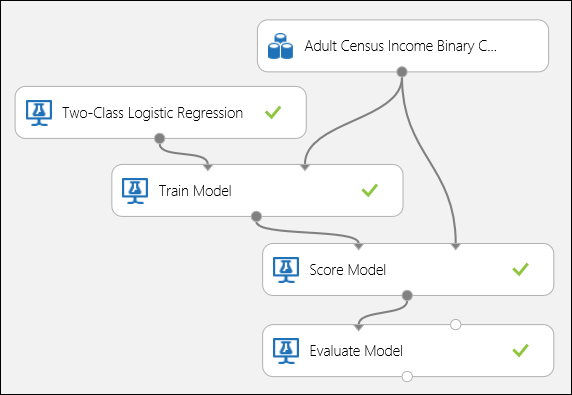
Figure 5. évaluation d’un modèle de classification binaire
Inspection des résultats de l’évaluation
Après avoir exécuté l’expérience, vous pouvez cliquer sur le port de sortie du module Évaluer le modèle et sélectionner Visualiser pour visualiser les résultats de l’évaluation (Figure 7). Les métriques d’évaluation disponibles pour les modèles de classification binaire sont les suivantes : Accuracy, Precision, Recall, F1 Score et AUC. En outre, le module génère une matrice de confusion présentant le nombre de vrais positifs, de faux négatifs, de faux positifs et de vrais négatifs, ainsi que les courbes ROC, Precision/Recall et Lift.
La métrique « Accuracy » (Exactitude) désigne simplement la proportion d’instances qui ont été classées correctement. Il s’agit généralement du premier métrique que vous examinez quand vous évaluez un classifieur. Toutefois, quand les données de test sont déséquilibrées (dans les cas où la plupart des instances appartiennent à l’une des classes), ou que vous êtes plus intéressé par les performances d’une seule des classes, l’exactitude ne permet pas de déterminer véritablement l’efficacité d’un classifieur. Dans le scénario de classification du niveau de revenu, supposons que vous testiez certaines données où 99 % des instances représentent des employés dont le revenu annuel est inférieur ou égal à 50 K. Il est alors possible d’atteindre une valeur d’exactitude de 0,99 en prédisant la classe « <=50 K » pour toutes les instances. Dans ce cas, le classifieur semble se révéler globalement efficace, alors qu’en réalité, il classe incorrectement tous les employés dont le revenu est plus élevé (les 1 % restants).
Il est donc utile de calculer d’autres métriques capturant des aspects plus spécifiques de l’évaluation. Avant d’examiner ces métriques en détail, il est important de comprendre en quoi consiste la matrice de confusion d’une évaluation de classification binaire. Les étiquettes de classe du jeu de données d’apprentissage ne peuvent prendre que deux valeurs, que nous désignons généralement en tant que valeurs positives ou négatives. Les instances positives et négatives correctement prédites par un classifieur sont respectivement appelées vrais positifs (VP) et vrais négatifs (VN). De la même façon, les instances classées incorrectement sont appelées faux positifs (FP) et faux négatifs (FN). La matrice de confusion est un simple tableau présentant le nombre d’instances appartenant à chacune de ces quatre catégories. Machine Learning Studio (classique) détermine automatiquement celle des deux classes du jeu de données qui correspond à la classe positive. Si les étiquettes de classe correspondent à des valeurs booléennes ou à des entiers, la classe positive est attribuée aux instances étiquetées « true » ou « 1 ». Si les étiquettes sont des chaînes, comme dans le cas du jeu de données de revenu, les étiquettes sont triées dans l’ordre alphabétique, et le premier niveau est désigné comme classe négative, tandis que le second niveau constitue la classe positive.
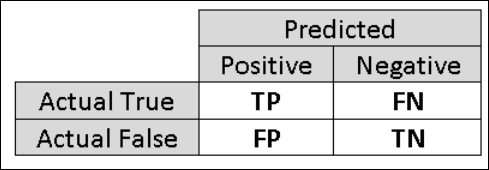
Figure 6. Matrice de Confusion de la Classification Binaire
Revenons au problème de classification du revenu et posons-nous plusieurs questions d’évaluation qui nous aideront à comprendre les performances du classifieur utilisé. Il est naturel de se poser la question suivante : « Sur le nombre d’employés pour lesquels le modèle a prédit un revenu >50 K (VP+FP), combien ont été classés correctement (VP) ? » Nous pouvons répondre à cette question en examinant la métrique Precision (Précision) du modèle, qui détermine le taux de positifs qui ont été classés correctement : VP/(VP+FP). Voici un autre question courante : « Sur le nombre total d’employés avec un revenu >50 K (VP+FN), combien ont été classés correctement par le classifieur (VP) ? ». La réponse nous est donnée par la métrique Recall(Rappel), correspondant au taux de vrais positifs : VP/(VP+FN) du classifieur. Vous pouvez remarquer qu’il existe un compromis évident entre la précision et le rappel. Par exemple, si l’on considère un jeu de données relativement équilibré, un classifieur capable de prédire la plupart des instances positives présente un rappel fort, mais une précision relativement faible, car de nombreuses instances négatives ne seront pas classées correctement, ce qui entraînera un grand nombre de faux positifs. Pour visualiser un diagramme représentant la variation de ces deux métriques, vous pouvez cliquer sur la courbe PRECISION/RECALL (PRÉCISION/RAPPEL) de la page de sortie des résultats de l’évaluation (partie supérieure gauche de la Figure 7).
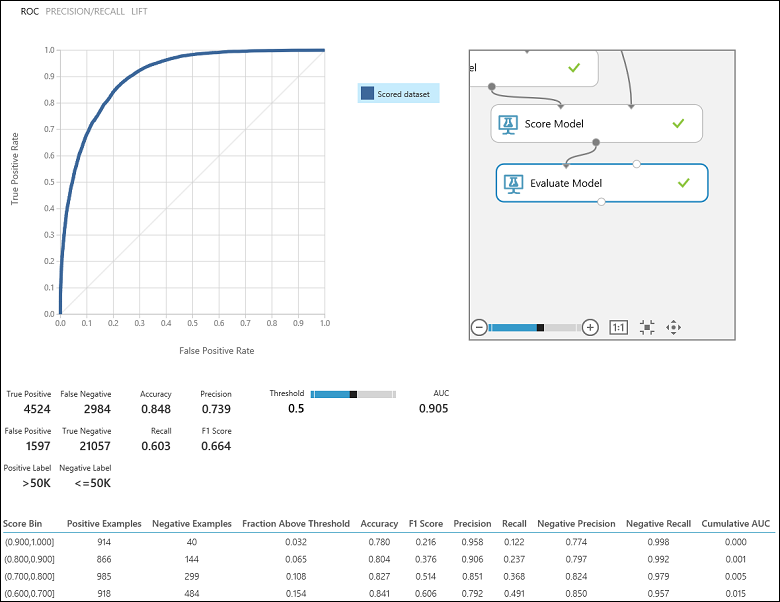
Figure 7. résultats de l’évaluation de la classification binaire
Un autre métrique connexe fréquemment utilisé est la métrique F1 Score(F-mesure), qui prend en compte à la fois la précision et le rappel. Il s’agit de la moyenne harmonique de ces deux métriques et est calculée comme tel : F1 = 2 (précision x rappel) / (précision + rappel). Le score F1 offre un bon moyen de résumer l’évaluation en une seule valeur ; toutefois, il est recommandé d’examiner systématiquement la précision et le rappel simultanément afin de mieux comprendre le comportement d’un classifieur.
En outre, il est possible d’inspecter le taux de vrais positifs par rapport au taux de faux positifs dans la courbe Receiver Operating Characteristic (ROC) (caractéristique de fonctionnement du récepteur) et la valeur Area Under the Curve (AUC) (aire sous la courbe) correspondante. Plus cette courbe se rapproche de l’angle supérieur gauche, plus le classifieur se comporte de manière efficace (autrement dit, il optimise le taux de vrais positifs et minimise le taux de faux positifs). Les courbes qui se rapprochent de la diagonale du diagramme résultent de classifieurs tendant à effectuer des prédictions proches d’une supposition aléatoire.
Utilisation de la validation croisée
Comme dans l’exemple de régression, nous pouvons effectuer une validation croisée afin d’appliquer automatiquement des opérations répétées d’apprentissage, de notation et d’évaluation à différents sous-échantillons des données. De même, nous pouvons utiliser le module Validation croisée de modèle, un modèle de régression logistique non entraîné, et un jeu de données. La colonne d’étiquette doit être définie sur income dans les propriétés du module Cross-Validate Model (Effectuer la validation croisée du modèle). Après avoir exécuté l'expérience et avoir cliqué sur le port de sortie droit du module Effectuer la validation croisée du modèle, nous pouvons visualiser les valeurs des métriques de classification binaire pour chaque pli, en plus de la moyenne et de l'écart-type de chaque pli.
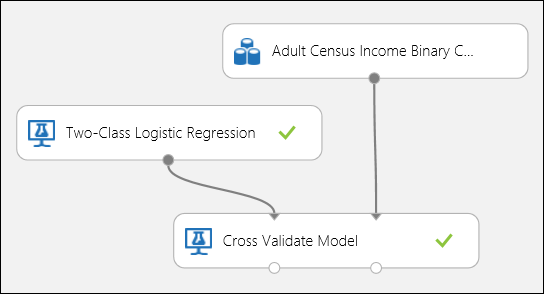
Figure 8. validation croisée d’un modèle de classification binaire
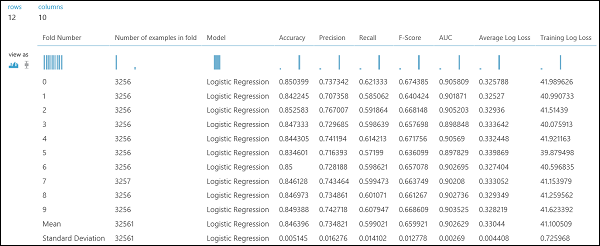
Figure 9. résultats de la validation croisée d’un classifieur binaire
Évaluation d’un modèle de classification multiclasse
Dans cette expérience, nous allons utiliser le fameux jeu de données Iris, qui contient des instances de trois différents types (classes) d’iris. Il existe quatre valeurs de caractéristique (longueur et largeur de sépale, longueur et largeur de pétale) pour chaque instance. Dans les expériences précédentes, nous avons formé et testé les modèles à l’aide des mêmes jeux de données. Ici, nous allons utiliser le module Fractionner les données pour créer deux sous-échantillons des données, former le modèle sur le premier sous-échantillon, puis noter et évaluer le modèle sur le second sous-échantillon. Le jeu de données Iris est publiquement accessible dans le UCI Machine Learning Repository (Référentiel Machine Learning UCI) et peut être téléchargé à l’aide d’un module Importer les données.
Création de l’expérience
Ajoutez les modules ci-après à votre espace de travail dans Azure Machine Learning Studio (classique) :
- Importer des données
- Forêt d’arbres décisionnels multiclasse
- Fractionner les données
- Entraîner le modèle
- Modèle de score
- Évaluer le modèle
Connectez les ports comme illustré ci-après à la Figure 10.
Définissez l’index de la colonne Étiquette du module Former le modèle sur 5. Le jeu de données ne comporte pas de ligne d’en-tête, mais nous savons que les étiquettes de classe figurent dans la cinquième colonne.
Cliquez sur le module Importer des données, puis définissez la propriété Source de données sur URL Web via HTTP, et la propriété URL sur http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data.
Définissez la fraction d’instances à utiliser pour l’apprentissage dans le module Fractionner les données (0,7 par exemple).
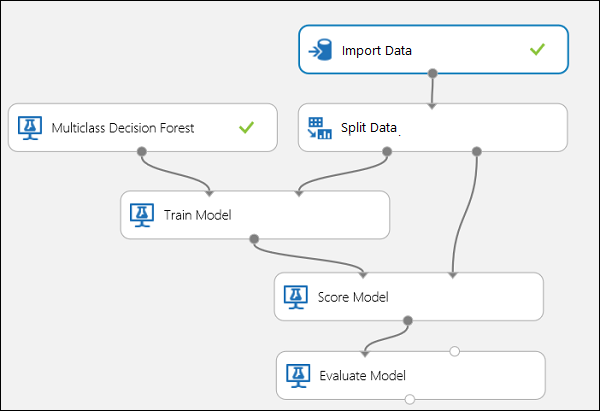
Figure 10. évaluation d’un classifieur multiclasse
Inspection des résultats de l’évaluation
Exécutez l’expérience et cliquez sur le port de sortie du module Évaluer le modèle. Dans notre cas, les résultats de l’évaluation sont présentés sous la forme d’une matrice de confusion. Cette matrice présente les instances réelles par rapport aux instances prédites pour les trois classes.
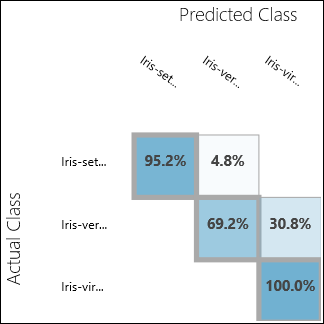
Figure 11. Résultats de l'évaluation de la classification multiclasse
Utilisation de la validation croisée
Comme indiqué précédemment, vous pouvez exécuter automatiquement des opérations répétées d’apprentissage, de notation et d’évaluation à l’aide du module Effectuer la validation croisée du modèle. Pour mener à bien cette tâche, vous avez besoin d’un jeu de données, d’un modèle non formé et d’un module Effectuer la validation croisée du modèle (voir la figure ci-dessous). Là encore, vous devez définir la colonne Étiquette du module Effectuer la validation croisée du modèle (index de colonne 5 dans notre cas). Après avoir exécuté l’expérience et cliqué sur le port de sortie de droite du module Effectuer la validation croisée du modèle, vous pouvez inspecter les valeurs des indicateurs pour chaque pli, ainsi que la moyenne et l’écart-type. Les métriques affichées ici sont semblables à ceux que nous avons présentés dans le cas de classification binaire. Toutefois, dans le cadre d’une classification multiclasse, le calcul des vrais positifs/négatifs et des faux positifs/négatifs s’effectue par le biais d’un décompte par classe, car il n’existe aucune classe entièrement positive ou négative. Par exemple, le calcul de la précision ou du rappel de la classe « Iris-setosa » repose sur l’hypothèse qu’il s’agit de la classe positive, et que toutes les autres classes sont négatives.
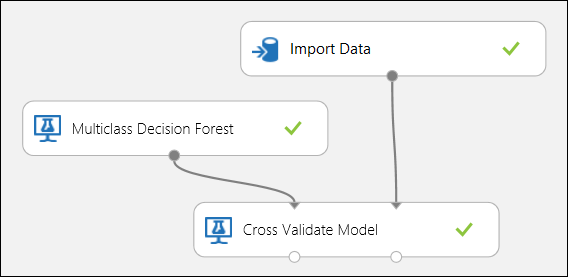
Figure 12. validation croisée d’un modèle de classification multiclasse
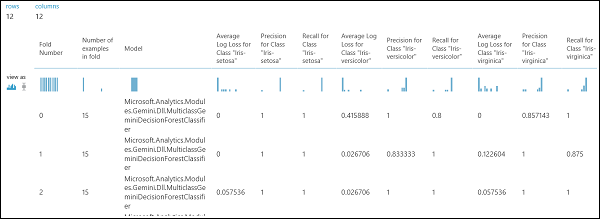
Figure 13. résultats de la validation croisée d’un modèle de classification multiclasse