« Exercice : Créer un flux de données de mappage Azure Data Factory »
Transformation des données avec le flux de données de mappage
Vous pouvez effectuer des transformations de données de manière native avec Azure Data Factory sans code à l’aide de la tâche de flux de données de mappage. Le mappage de flux de données offre une expérience entièrement visuelle sans qu’aucun codage ne soit nécessaire. Vos flux de données s’exécuteront sur votre propre cluster d’exécution pour un traitement des données faisant l’objet d’un scale-out. Les activités de flux de données peuvent être mises en œuvre à l’aide de fonctionnalités de planification, de contrôle, de flux et de supervision Data Factory existantes.
Quand vous créez des flux de données, vous pouvez activer le mode débogage, ce qui active un petit cluster Spark interactif. Activez le mode débogage en basculant le curseur en haut du module de création. Le préchauffage des clusters de débogage prend quelques minutes. Ils vous offriront cependant un aperçu interactif de la sortie de votre logique de transformation.

Une fois le flux de données de mappage ajouté et le cluster Spark en cours d’exécution, vous pourrez effectuer la transformation, exécuter le flux de données et prévisualiser les données. Aucune programmation n’est nécessaire. En effet, Azure Data Factory gère intégralement la traduction du code, l’optimisation du chemin et l’exécution de vos travaux de flux de données.
Ajout de données sources au flux de données de mappage
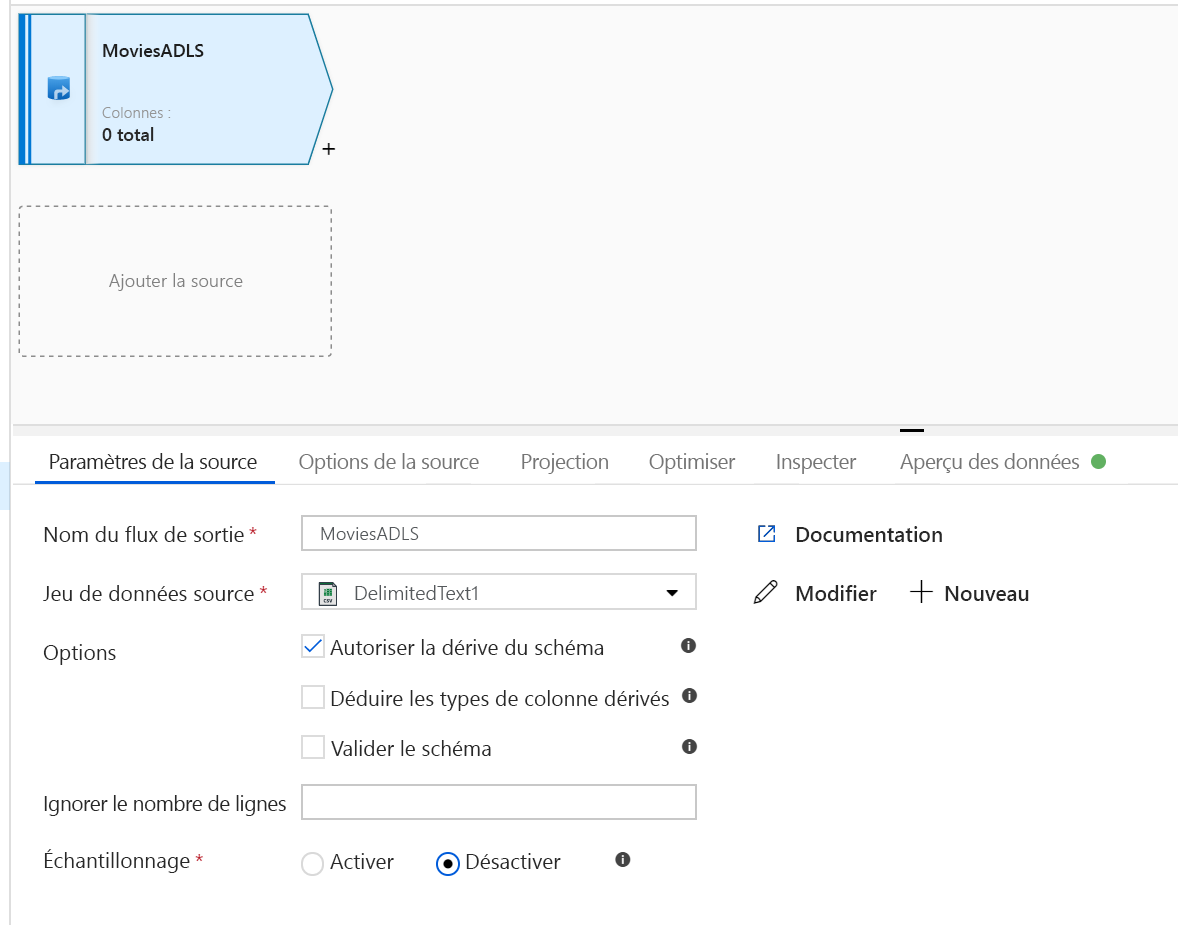
Ouvrez le canevas du flux de données de mappage. Cliquez sur le bouton Ajouter une source dans le canevas du flux de données. Dans la liste déroulante Jeu de données source, sélectionnez votre source de données. Pour cet exemple, nous utilisons le jeu de données ADLS Gen2.
Prenez note des points suivants :
- Si votre jeu de données pointe vers un dossier contenant d’autres fichiers et que vous ne souhaitez utiliser qu’un seul fichier, vous devrez peut-être créer un autre jeu de données ou utiliser le paramétrage pour vous assurer que seul un fichier spécifique est lu.
- Si vous n’avez pas importé votre schéma dans votre stockage ADLS mais que vous avez déjà ingéré vos données, accédez à l’onglet « Schéma » du jeu de données, puis cliquez sur « Importer un schéma » pour que votre flux de données connaisse la projection de schéma.
Le flux de données de mappage suit une approche basée sur l’extraction, le chargement et la transformation (ELT, extract, load, transform) et fonctionne avec des jeux de données intermédiaires qui se trouvent tous dans Azure. Actuellement, les jeux de données suivants peuvent être utilisés dans une transformation de source :
- Stockage Blob Azure (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen1 (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen2 (JSON, Avro, Text, Parquet)
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Azure Data Factory a accès à plus de 80 connecteurs natifs. Pour inclure dans votre flux de données des données provenant de ces autres sources, utilisez l’outil Copier l’activité pour charger ces données dans l’une des zones de transit prises en charge.
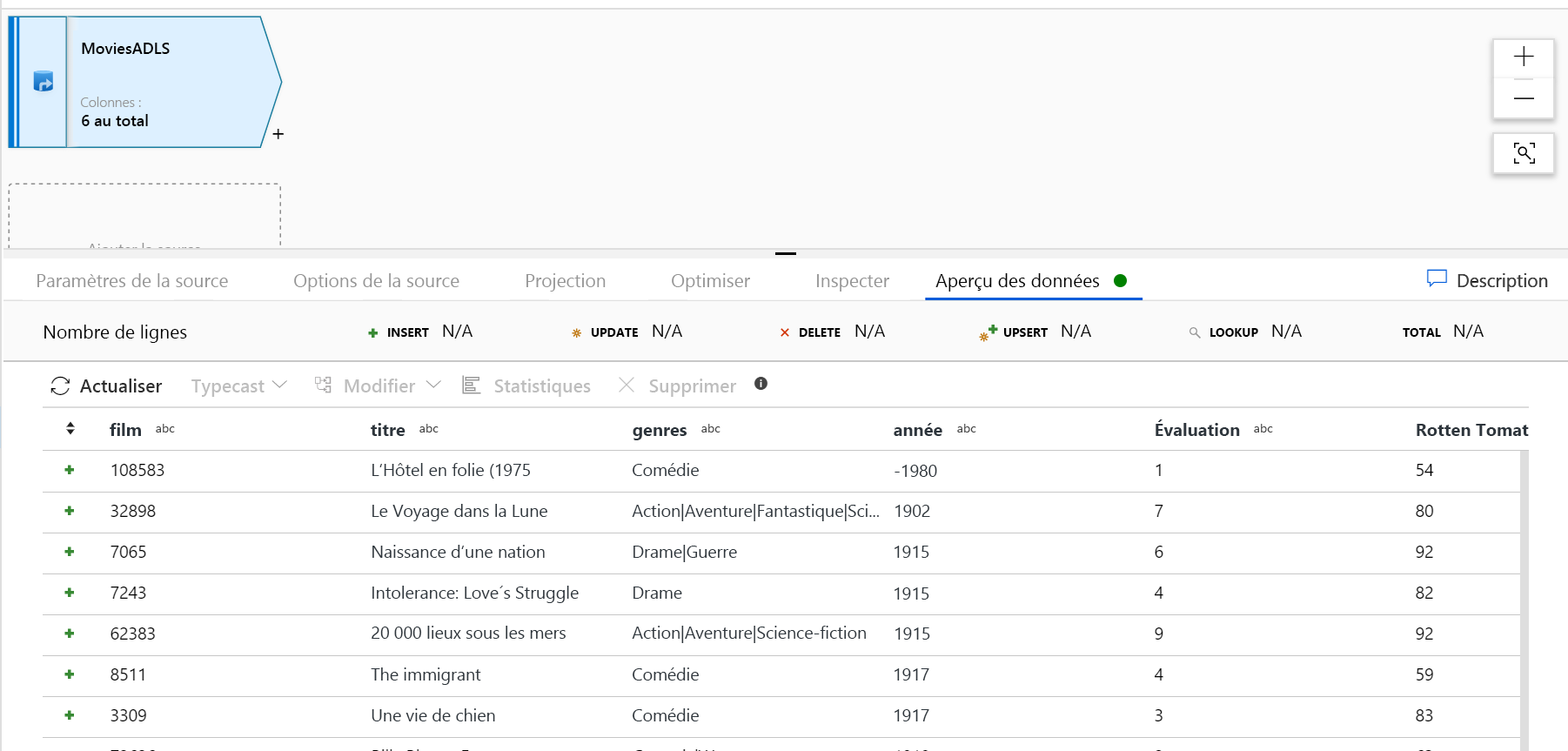
Une fois votre cluster de débogage préchauffé, vérifiez que vos données sont chargées correctement dans l’onglet Aperçu des données. Quand vous cliquez sur le bouton Actualiser, le flux de données de mappage affiche un instantané de vos données telles qu’elles se présentent à chaque transformation.
Utilisation des transformations dans le flux de données de mappage
Vous avez déplacé les données dans votre stockage Azure Data Lake Store Gen2. À présent, vous êtes prêt à créer un flux de données de mappage qui va transformer vos données à grande échelle par le biais d’un cluster Spark, puis les charger dans un entrepôt de données.
Pour cela, vous effectuerez les principales tâches suivantes :
Préparation de l’environnement
Ajout d'une source de données
Utilisation de la transformation de flux de données de mappage
Écriture dans un récepteur de données
Tâche 1 : Préparation de l’environnement
Activer le débogage du workflow de données - Activez le curseur Débogage du flux de données situé en haut du module de création.
Notes
Le préchauffage des clusters de flux de données prend 5 à 7 minutes.
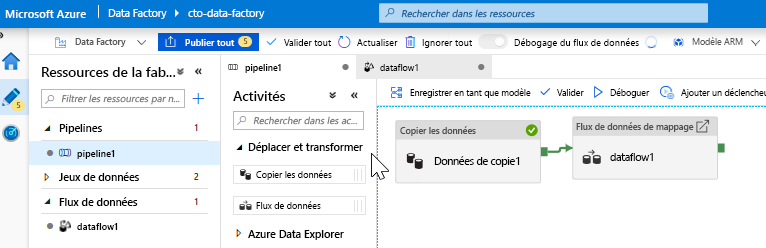
Ajouter une activité de flux de données - Dans le volet Activités, ouvrez l’accordéon Déplacer et transformer, puis faites glisser l’activité Flux de données vers le canevas du pipeline. Dans le volet qui s’affiche, cliquez sur Créer un flux de données, sélectionnez Flux de données de mappage, puis cliquez sur OK. Cliquez sur l’onglet pipeline1 et faites glisser la zone verte de votre activité Copy vers l’activité Data Flow pour créer une condition « en cas de réussite ». Vous voyez les éléments suivants dans le canevas :
Tâche 2 : Ajout d’une source de données
Ajouter une source ADLS - Double-cliquez sur l’objet de flux de données de mappage dans le canevas. Cliquez sur le bouton Ajouter une source dans le canevas du flux de données. Dans la liste déroulante Jeu de données source, sélectionnez le jeu de données ADLSG2 utilisé dans votre activité Copy.
- Si votre jeu de données pointe vers un dossier contenant d’autres fichiers, vous devrez peut-être créer un autre jeu de données ou utiliser le paramétrage pour vous assurer que seul le fichier moviesDB.csv est lu.
- Si vous n’avez pas importé votre schéma dans votre stockage ADLS mais que vous avez déjà ingéré vos données, accédez à l’onglet « Schéma » du jeu de données, puis cliquez sur « Importer un schéma » pour que votre flux de données connaisse la projection de schéma.
Une fois votre cluster de débogage préchauffé, vérifiez que vos données sont chargées correctement dans l’onglet Aperçu des données. Quand vous cliquez sur le bouton Actualiser, le flux de données de mappage affiche un instantané de vos données telles qu’elles se présentent à chaque transformation.
Tâche 3 : Utilisation de la transformation de flux de données de mappage
Ajouter une transformation de sélection pour renommer et supprimer une colonne - Dans l’aperçu des données, vous avez peut-être remarqué que le titre de colonne « Rotton Tomatoes » est mal orthographié. Pour le nommer correctement et supprimer la colonne Rating inutilisée, vous pouvez ajouter une transformation de sélection en cliquant sur l’icône + en regard de votre nœud source ADLS et en choisissant Sélection sous Modificateur de schéma.
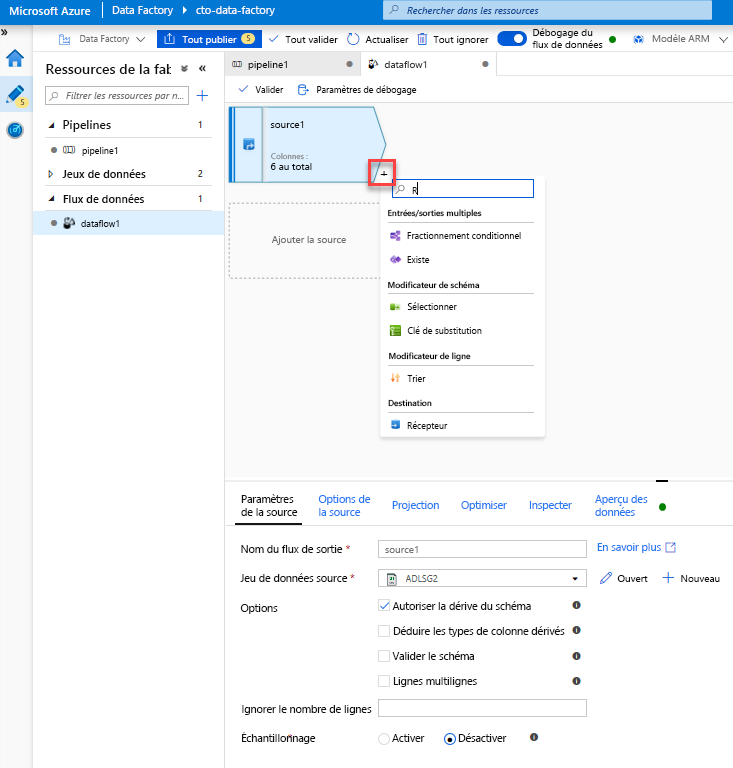
Dans le champ Nommer comme, remplacez « Rotton » par « Rotten ». Pour supprimer la colonne Rating, pointez dessus, puis cliquez sur l’icône de la corbeille.
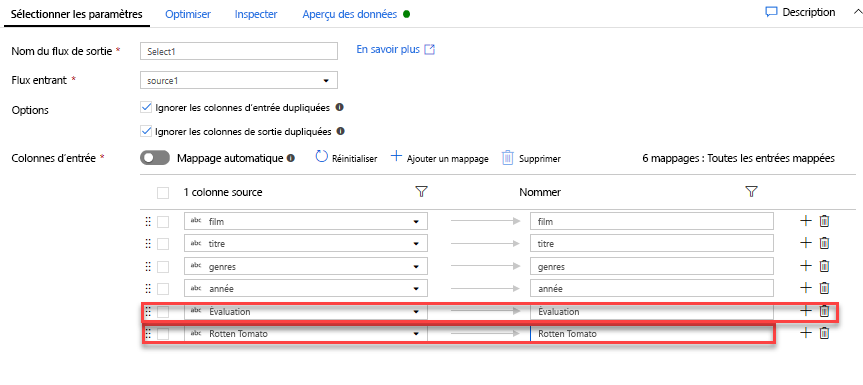
Ajouter une transformation de filtre pour filtrer les années à exclure - Imaginons que vous ne vous intéressiez qu’aux films sortis après 1951. Vous pouvez ajouter une transformation de filtre pour spécifier une condition de filtre en cliquant sur l’icône + en regard de votre transformation de sélection et en choisissant Filtre sous Modificateur de ligne. Cliquez sur la zone d’expression pour ouvrir le générateur d’expressions et entrez votre condition de filtre. Avec la syntaxe du langage d’expression de flux de données de mappage, toInteger(year) > 1950 convertit la chaîne de la valeur d’année en un entier et filtre les lignes si cette valeur est supérieure à 1950.
Vous pouvez utiliser le volet Aperçu des données intégré au générateur d’expressions pour vérifier que votre condition fonctionne correctement.
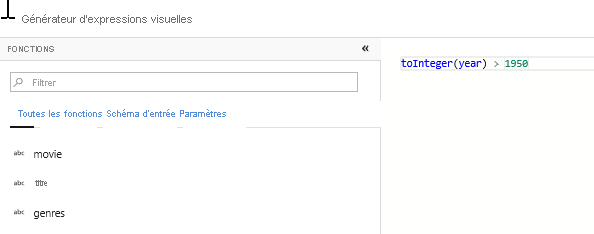
Ajouter une transformation de colonne dérivée pour calculer le genre principal - Comme vous l’avez peut-être remarqué, la colonne Genres est une chaîne délimitée par le caractère « | ». Si vous vous intéressez uniquement au premier genre de chaque colonne, vous pouvez dériver une nouvelle colonne nommée PrimaryGenre (Genre principal) à l’aide de la transformation de colonne dérivée en cliquant sur l’icône + en regard de votre transformation de filtre et en choisissant Derivée sous Modificateur de schéma. À l’instar de la transformation de filtre, la transformation de colonne dérivée utilise le générateur d’expressions du flux de données de mappage pour la spécification des valeurs de la nouvelle colonne.

Dans ce scénario, vous essayez d’extraire le premier genre dans la colonne Genres, qui est au format « genre1|genre2|...|genreN ». Utilisez la fonction locate pour obtenir le premier index basé sur 1 par rapport au symbole « | » dans la chaîne de genres. Avec la fonction iif, si cet index est supérieur à 1, le genre principal peut être calculé à l’aide de la fonction left, qui retourne tous les caractères d’une chaîne à gauche d’un index. Dans le cas contraire, la valeur PrimaryGenre est égale au champ genres. Vous pouvez vérifier la sortie dans le volet Aperçu des données du générateur d’expressions.
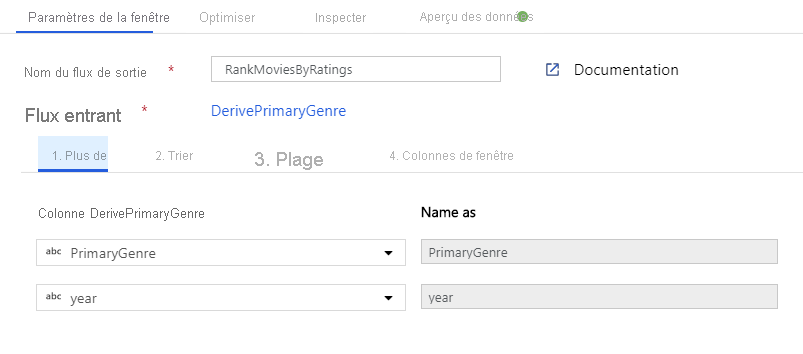
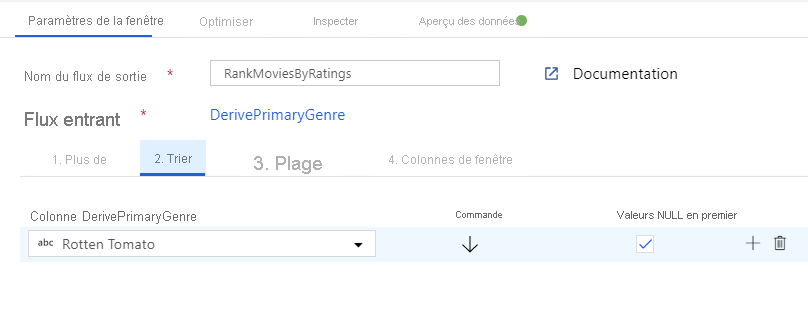
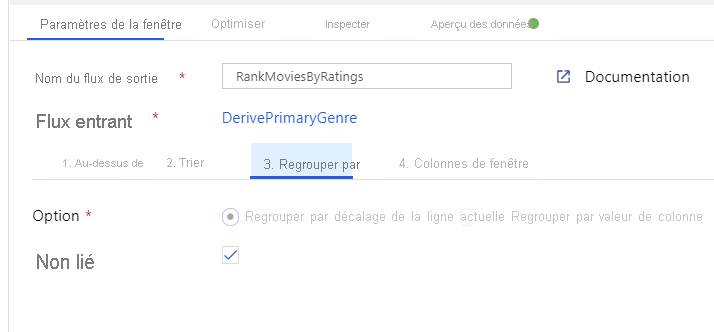
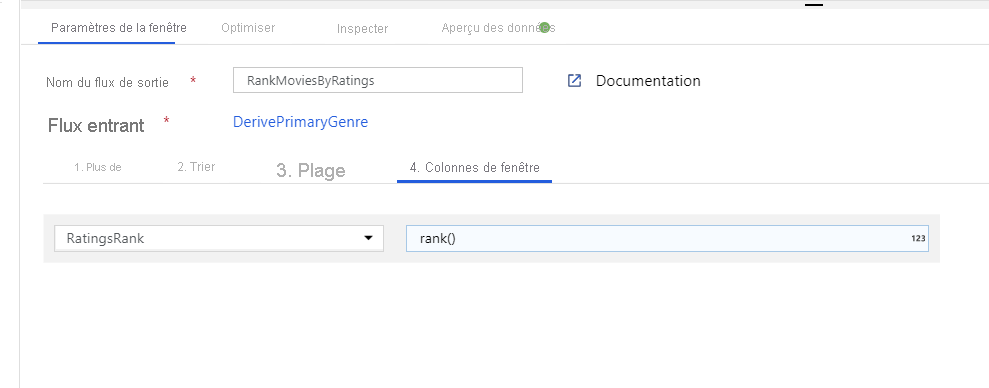
Classer les films à l’aide d’une transformation de fenêtre - Imaginons que vous souhaitiez connaître le classement d’un film pour une année et un genre spécifiques. Vous pouvez ajouter une transformation de fenêtre pour définir des agrégations basées sur des fenêtres en cliquant sur l’icône + en regard de votre transformation de colonne dérivée et en cliquant sur Fenêtre sous Modificateur de schéma. Pour cela, spécifiez l’objet du fenêtrage, votre index de tri, la plage et le mode de calcul des nouvelles colonnes de fenêtre. Dans cet exemple, le fenêtrage a pour objets PrimaryGenre et l’année avec une plage non limitée. Nous effectuons un tri décroissant sur Rotten Tomato et calculons une nouvelle colonne appelée RatingsRank (ClassementÉvaluations) correspondant au classement de chaque film pour le genre et l’année spécifiques.
Agréger des évaluations avec une transformation d’agrégation - Vous avez rassemblé et dérivé toutes les données nécessaires. Vous pouvez à présent ajouter une transformation d’agrégation pour calculer des métriques basées sur le groupe de votre choix en cliquant sur l’icône + en regard de votre transformation de fenêtre, puis en cliquant sur Agrégat sous Modificateur de schéma. Comme vous l’avez fait pour la transformation de fenêtre, vous allez grouper les films par genre principal (PrimaryGenre) et par année.
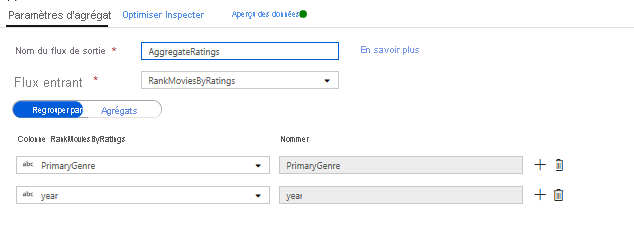
Sous l’onglet Agrégats, vous pouvez créer des agrégations calculées sur le groupe spécifié par colonnes. Pour chaque genre et année, vous allez obtenir l’évaluation moyenne de Rotten Tomatoes, le film avec la meilleure évaluation et le film avec la moins bonne évaluation (à l’aide de la fonction de fenêtrage) et le nombre de films dans chaque groupe. L’agrégation réduit considérablement le nombre de lignes dans votre flux de transformation et propage le groupe uniquement sur la base des colonnes d’agrégation spécifiées dans la transformation.
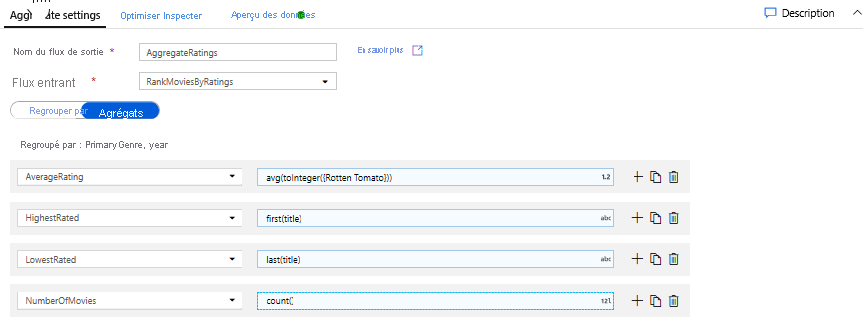
- Pour voir comment la transformation d’agrégation modifie vos données, utilisez l’onglet Aperçu des données.
Spécifier une condition d’upsert avec une transformation de modification de ligne - Si vous écrivez dans un récepteur tabulaire, vous pouvez spécifier des stratégies d’insertion, de suppression, de mise à jour et d’upsert sur les lignes à l’aide de la transformation de modification de ligne en cliquant sur l’icône + en regard de votre transformation d’agrégation, puis en cliquant sur Modification de ligne sous Modificateur de ligne. Étant donné que vous effectuez constamment des insertions et des mises à jour, vous pouvez spécifier un upsert systématique pour toutes les lignes.

Tâche 4 : Écriture dans un récepteur de données
- Écrire dans un récepteur Azure Synapse Analytics - Vous avez terminé toute votre logique de transformation. À présent, vous êtes prêt à écrire dans un récepteur.
Ajoutez un récepteur en cliquant sur l’icône + en regard de votre transformation d’upsert et en cliquant sur Récepteur sous Destination.
Dans l’onglet Récepteur, créez un jeu de données d’entrepôt de données à l’aide du bouton + Nouveau.
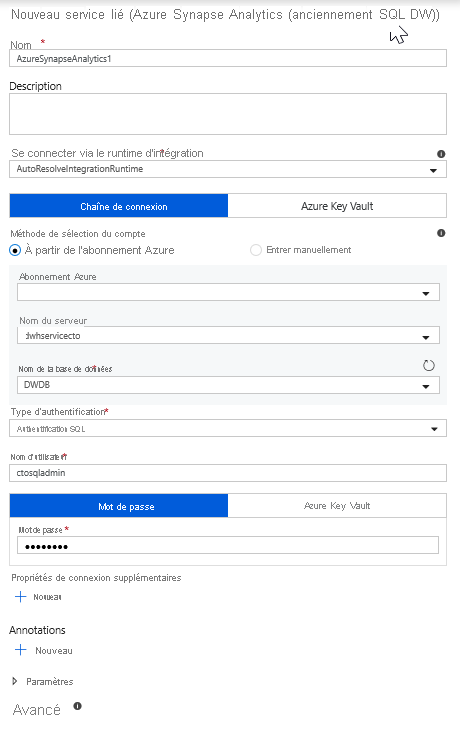
Sélectionnez Azure Synapse Analytics dans la liste des vignettes.
Sélectionnez un nouveau service lié et configurez votre connexion Azure Synapse Analytics pour vous connecter à la base de données DWDB. Une fois que vous avez fini, cliquez sur Créer.
Dans la configuration du jeu de données, sélectionnez Créer une table, puis entrez Dbo pour le schéma et Ratings (Évaluations) pour le nom de la table. Cliquez sur OK quand vous avez terminé.
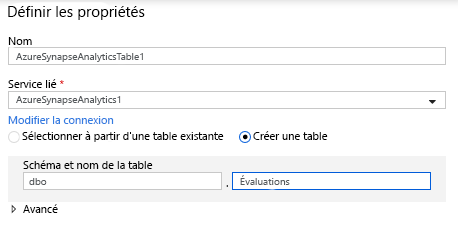
Comme une condition d’upsert a été spécifiée, vous devez accéder à l’onglet Paramètres et sélectionner « Autoriser l’upsert » en fonction des colonnes clés de genre principal (PrimaryGenre) et d’année.
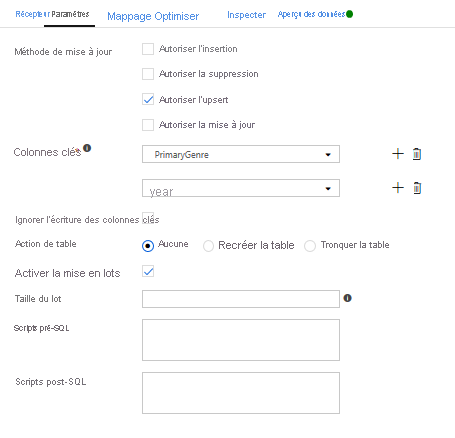
À ce stade, vous avez terminé la génération de votre flux de données de mappage à 8 transformations. Il est temps d’exécuter le pipeline et de voir les résultats.

Tâche 5 : Exécution du pipeline
Accédez à l’onglet pipeline1 dans le canevas. Étant donné qu’Azure Synapse Analytics dans Data Flow utilise PolyBase, vous devez spécifier un dossier blob ou ADLS intermédiaire. Dans l’onglet de paramètres de l’activité d’exécution du flux de données, ouvrez l’accordéon PolyBase. Sélectionnez votre service lié ADLS et spécifiez un chemin de dossier intermédiaire.
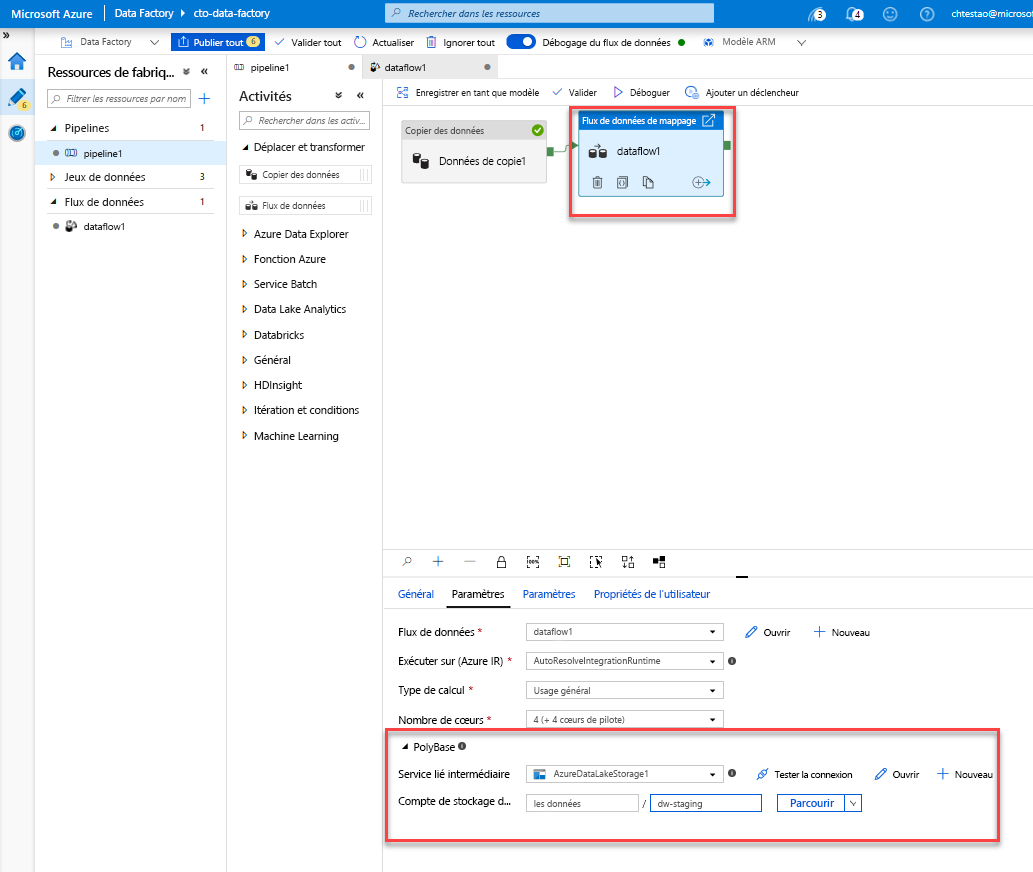
Avant de publier votre pipeline, exécutez un autre débogage pour vérifier qu’il fonctionne comme prévu. Dans l’onglet Sortie, vous pouvez superviser l’état des deux activités en cours d’exécution.
Quand les deux activités ont réussi, vous pouvez cliquer sur l’icône des lunettes en regard de l’activité de flux de données pour examiner l’exécution du flux de données plus en détail.
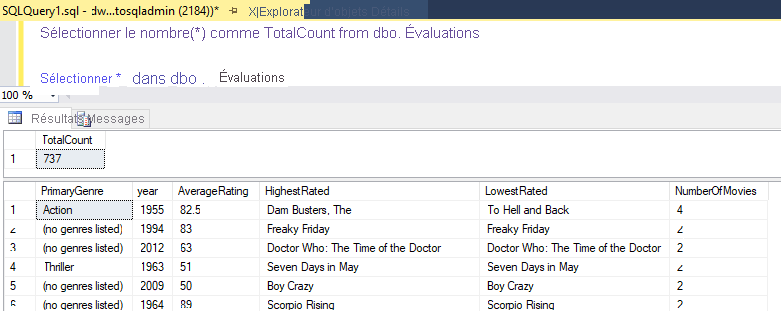
Si vous avez utilisé la logique décrite dans ce labo, votre flux de données écrit 737 lignes dans votre entrepôt de données SQL. Vous pouvez accéder à SQL Server Management Studio pour vérifier si le pipeline a fonctionné correctement et voir ce qui a été écrit.