Comment fonctionne Azure HDInsight
Dans cette unité, vous allez découvrir le fonctionnement d’Azure HDInsight. Vous y trouverez des informations sur les composants suivants et sur la façon dont ils se combinent pour fournir un contrôle et une gestion des données :
- Apache Hadoop
- Stockage HDInsight
- Traitement HDInsight
Qu’est-ce qu’Apache Hadoop ?
Apache Hadoop est un système de traitement de données distribué sur le cloud qui forme le cœur de HDInsight. Il comporte trois composants, qui sont décrits dans le tableau ci-dessous :
| Composant Apache Hadoop | Description |
|---|---|
| HDFS | Le composant Apache HDFS (Hadoop Distributed File System) fournit le stockage pour le système Hadoop. |
| YARN | Le composant Apache Hadoop YARN (Yet Another Resource Negotiator) fournit le traitement pour le système. |
| MapReduce | MapReduce est un modèle de programmation qui vous permet de traiter et d’analyser des données. |
Comment les composants interagissent-ils ?
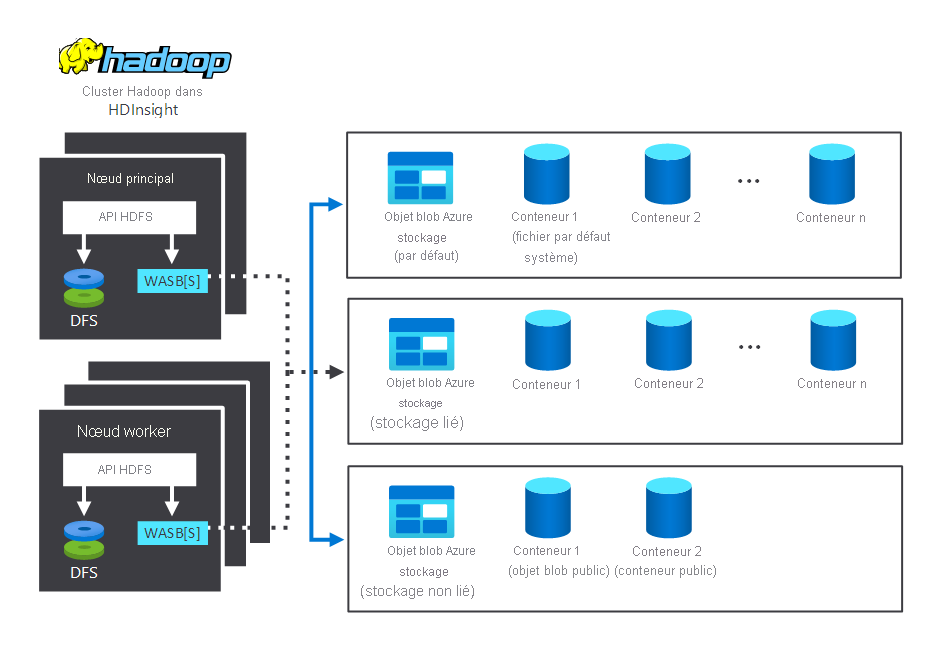
Le diagramme suivant illustre les composants de stockage et de traitement qui interagissent dans un cluster Hadoop HDInsight classique. Il illustre les composants suivants :
- Le nœud principal et les nœuds Worker, qui effectuent le traitement.
- Plusieurs centres de stockage WASB (Windows Azure Storage Blob), au sein des nœuds. HDFS interagit avec ces conteneurs.
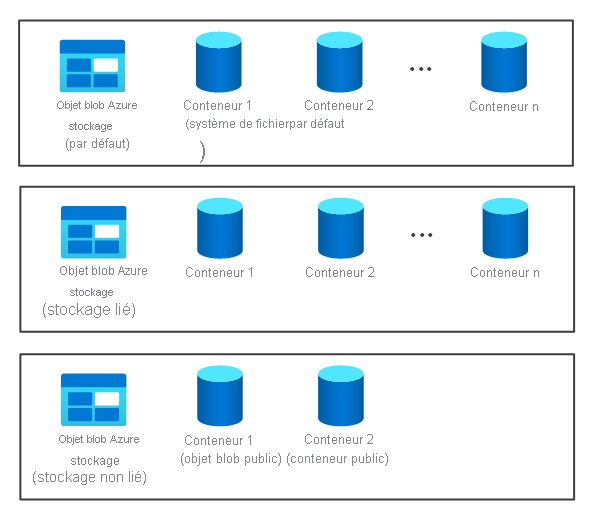
- Plusieurs conteneurs de stockage par défaut, liés et non liés. Ils sont disponibles pour les deux nœuds.
Examinons maintenant le fonctionnement du stockage et du traitement.
Comment fonctionne le stockage ?
Le composant de stockage d’un cluster n’est pas créé automatiquement quand vous provisionnez un cluster HDInsight. Il est fourni par un système conforme HDFS, par exemple le Stockage Azure ou Azure Data Lake.
La séparation du composant de stockage d’un cluster du composant de traitement présente des avantages. Par exemple, vous pouvez supprimer de manière sécurisée les clusters HDInsight utilisés uniquement pour le calcul sans vous soucier d’une perte de données. Quand vous ajoutez un cluster HDInsight, vous devez définir un système de fichiers par défaut.
Important
Pour le stockage Azure, vous devez spécifier un conteneur d’objets blob comme système de fichiers par défaut.
Le fait de fournir un système de fichiers par défaut permet à HDInsight de résoudre les références relatives à des fichiers lors de la recherche de fichiers.
Conseil
Quand vous souhaitez augmenter le stockage disponible, vous pouvez lier et dissocier des systèmes de fichiers supplémentaires selon vos besoins.
Comment fonctionne le traitement ?
Lors du traitement des données, le composant de calcul d’un cluster Hadoop sur HDInsight se répartit en deux zones logiques. Le tableau suivant décrit ces deux zones :
| Composant | Description |
|---|---|
| Nœud principal | Le nœud principal accepte et gère les demandes des clients et transmet celles-ci aux nœuds Worker. |
| Nœud Worker | Les nœuds Worker traitent les données. |
Notes
Le nœud principal est parfois appelé nœud maître.
La plupart des clusters contiennent deux nœuds principaux, notamment :
- Un nœud principal actif, qui gère les connexions clientes.
- Un nœud principal passif, qui assure la résilience si le nœud actif passe en mode hors connexion.
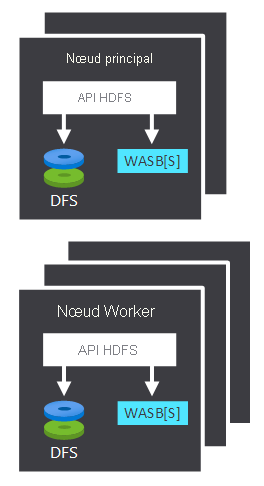
Les nœuds principaux et les nœuds Worker peuvent se connecter directement à un système HDFS attaché localement ou accéder aux données stockées dans un stockage Blob Azure ou dans Azure Data Lake. Deux facteurs déterminent les données qui sont managées :
- La façon dont le modèle de programmation MapReduce a défini le mode d’utilisation des données
- La façon dont le nœud principal alloue le travail
Que fait le composant YARN ?
Le composant YARN assure la gestion des ressources au sein d’un cluster HDInsight. Quand vous traitez des données, ce service gère les ressources et la planification des travaux.
Le composant YARN se situe entre le HDFS et le système de calcul du cluster HDInsight. Il fonctionne avec le nœud principal pour aider à distribuer un travail sur les nœuds Worker du cluster. Ainsi, les tâches de traitement des données se produisent en parallèle.