Tutorial: Análisis de datos en registros de Azure Monitor mediante un cuaderno
Los cuadernos son entornos integrados que permiten crear y compartir documentos con código dinámico, ecuaciones, visualizaciones y texto. La integración de un cuaderno con un área de trabajo de Log Analytics le permite crear un proceso de varios pasos que ejecute código en cada paso en función de los resultados del paso anterior. Puede usar estos procesos simplificados para crear canalizaciones de aprendizaje automático, herramientas de análisis avanzadas, guías de solución de problemas (TSG) para las necesidades de soporte técnico, etc.
La integración de un cuaderno con un área de trabajo de Log Analytics también le permite:
- Ejecutar consultas KQL y código personalizado en cualquier lenguaje.
- Introducir nuevas funcionalidades de análisis y visualización, como nuevos modelos de aprendizaje automático, escalas de tiempo personalizadas y árboles de proceso.
- Integrar conjuntos de datos fuera de los registros de Azure Monitor, como conjuntos de datos locales.
- Aprovechar los límites de servicio aumentados mediante los límites de API de consulta en comparación con el Azure Portal.
En este tutorial, aprenderá a:
- Integrar un cuaderno con el área de trabajo de Log Analytics mediante la biblioteca cliente de consultas de Azure Monitor y la biblioteca cliente de Identidad de Azure
- Explorar y visualizar los datos desde el área de trabajo de Log Analytics en un cuaderno
- Ingerir datos del cuaderno en una tabla personalizada en el área de trabajo de Log Analytics (opcional)
Para ver un ejemplo de cómo crear una canalización de aprendizaje automático para analizar datos en registros de Azure Monitor mediante un cuaderno, consulte este cuaderno de ejemplo: Detección de anomalías en los registros de Azure Monitor mediante técnicas de aprendizaje automático.
Sugerencia
Para solucionar las limitaciones relacionadas con la API, divida las consultas más grandes en varias consultas más pequeñas.
Prerrequisitos
En este tutorial, necesitará:
Un área de trabajo de Azure Machine Learning con una instancia de proceso CPU con:
- Un cuaderno.
- Kernel establecido en Python 3.8 o superior.
Los siguientes roles y permisos:
En los registros de Azure Monitor: el rol Colaborador de Logs Analytics para leer y enviar datos al área de trabajo de Logs Analytics. Para obtener más información, consulte Administración del acceso a las áreas de trabajo de Log Analytics.
En Azure Machine Learning:
- Un rol de propietario o colaborador de nivel de grupo de recursos, para crear una nueva área de trabajo de Azure Machine Learning si es necesario.
- Un rol de colaborador en el área de trabajo de Azure Machine Learning donde se ejecuta el cuaderno.
Para obtener más información, consulte Administración del acceso a un área de trabajo de Azure Machine Learning.
Herramientas y cuadernos
En este tutorial, usará estas herramientas:
| Herramienta | Descripción |
|---|---|
| Biblioteca cliente de consulta de Azure Monitor | Permite ejecutar consultas de solo lectura en los datos de los registros de Azure Monitor. |
| Biblioteca cliente de Azure Identity | Permite a los clientes de Azure SDK autenticarse con Microsoft Entra ID. |
| Biblioteca cliente de ingesta de Azure Monitor | Permite enviar registros personalizados a Azure Monitor mediante la API de ingesta de registros. Necesario para ingerir datos analizados en una tabla personalizada en el área de trabajo de Log Analytics (opcional) |
| Regla de recopilación de datos, punto de conexión de recopilación de datos y una aplicación registrada | Necesario para ingerir datos analizados en una tabla personalizada en el área de trabajo de Log Analytics (opcional) |
Otras bibliotecas de consultas que puede usar incluyen:
- La biblioteca Kqlmagic le permite ejecutar consultas de KQL directamente dentro de un cuaderno de la misma manera que ejecuta consultas KQL desde la herramienta Log Analytics.
- La biblioteca MSTICPY proporciona consultas con plantillas que invocan funcionalidades de aprendizaje automático y serie temporal de KQL integradas, y proporcionan herramientas de visualización avanzadas y análisis de datos en el área de trabajo de Log Analytics.
Otras experiencias de cuadernos de Microsoft para el análisis avanzado incluyen:
1. Integración del área de trabajo de Log Analytics con el cuaderno
Configure el cuaderno para consultar el área de trabajo de Log Analytics:
Instale las bibliotecas cliente de ingesta de Azure Monitor, Azure Identity y Azure Monitor, junto con la biblioteca de análisis de datos de Pandas, y la biblioteca de visualización de Plotly:
import sys !{sys.executable} -m pip install --upgrade azure-monitor-query azure-identity azure-monitor-ingestion !{sys.executable} -m pip install --upgrade pandas plotlyEstablezca la variable
LOGS_WORKSPACE_IDsiguiente en el identificador del área de trabajo de Log Analytics. La variable está establecida actualmente para usar el área de trabajo demostración de Azure Monitor, que puede usar para demostrar el cuaderno.LOGS_WORKSPACE_ID = "DEMO_WORKSPACE"Configure
LogsQueryClientpara autenticar y consultar registros de Azure Monitor.Este código configura
LogsQueryClientpara autenticarse medianteDefaultAzureCredential:from azure.core.credentials import AzureKeyCredential from azure.core.pipeline.policies import AzureKeyCredentialPolicy from azure.identity import DefaultAzureCredential from azure.monitor.query import LogsQueryClient if LOGS_WORKSPACE_ID == "DEMO_WORKSPACE": credential = AzureKeyCredential("DEMO_KEY") authentication_policy = AzureKeyCredentialPolicy(name="X-Api-Key", credential=credential) else: credential = DefaultAzureCredential() authentication_policy = None logs_query_client = LogsQueryClient(credential, authentication_policy=authentication_policy)Normalmente,
LogsQueryClientsolo admite la autenticación con credenciales de token de Microsoft Entra. Sin embargo, podemos pasar una directiva de autenticación personalizada para habilitar el uso de claves de API. Esto permite al cliente consultar el área de trabajo de demostración. La disponibilidad y el acceso a esta área de trabajo de demostración están sujetas a cambios, por lo que se recomienda usar su propio área de trabajo de Log Analytics.Defina una función auxiliar, denominada
query_logs_workspace, para ejecutar una consulta determinada en el área de trabajo de Log Analytics y devolver los resultados como DataFrame de Pandas.import pandas as pd import plotly.express as px from azure.monitor.query import LogsQueryStatus from azure.core.exceptions import HttpResponseError def query_logs_workspace(query): try: response = logs_query_client.query_workspace(LOGS_WORKSPACE_ID, query, timespan=None) if response.status == LogsQueryStatus.PARTIAL: error = response.partial_error data = response.partial_data print(error.message) elif response.status == LogsQueryStatus.SUCCESS: data = response.tables for table in data: my_data = pd.DataFrame(data=table.rows, columns=table.columns) except HttpResponseError as err: print("something fatal happened") print (err) return my_data
2. Explorar y visualizar los datos desde el área de trabajo de Log Analytics en su cuaderno
Echemos un vistazo a algunos datos del área de trabajo ejecutando una consulta desde el cuaderno:
Esta consulta comprueba la cantidad de datos (en Megabytes) que ingirió en cada una de las tablas (tipos de datos) del área de trabajo de Log Analytics cada hora en la semana pasada:
TABLE = "Usage" QUERY = f""" let starttime = 7d; // Start date for the time series, counting back from the current date let endtime = 0d; // today {TABLE} | project TimeGenerated, DataType, Quantity | where TimeGenerated between (ago(starttime)..ago(endtime)) | summarize ActualUsage=sum(Quantity) by TimeGenerated=bin(TimeGenerated, 1h), DataType """ df = query_logs_workspace(QUERY) display(df)El DataFrame resultante muestra la ingesta por hora en cada una de las tablas del área de trabajo de Log Analytics:
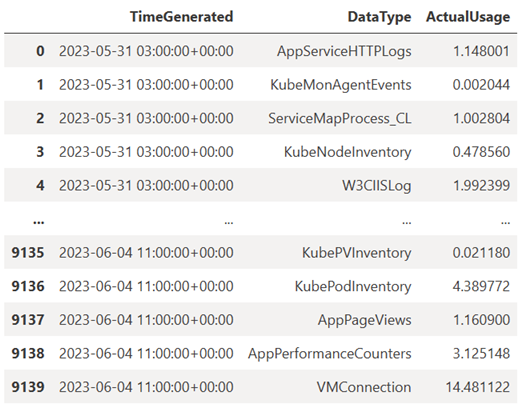
Ahora, veamos los datos como un gráfico que muestra el uso por hora de varios tipos de datos a lo largo del tiempo, en función del DataFrame de Pandas:
df = df.sort_values(by="TimeGenerated") graph = px.line(df, x='TimeGenerated', y="ActualUsage", color='DataType', title="Usage in the last week - All data types") graph.show()El grafo resultante tendrá este aspecto:
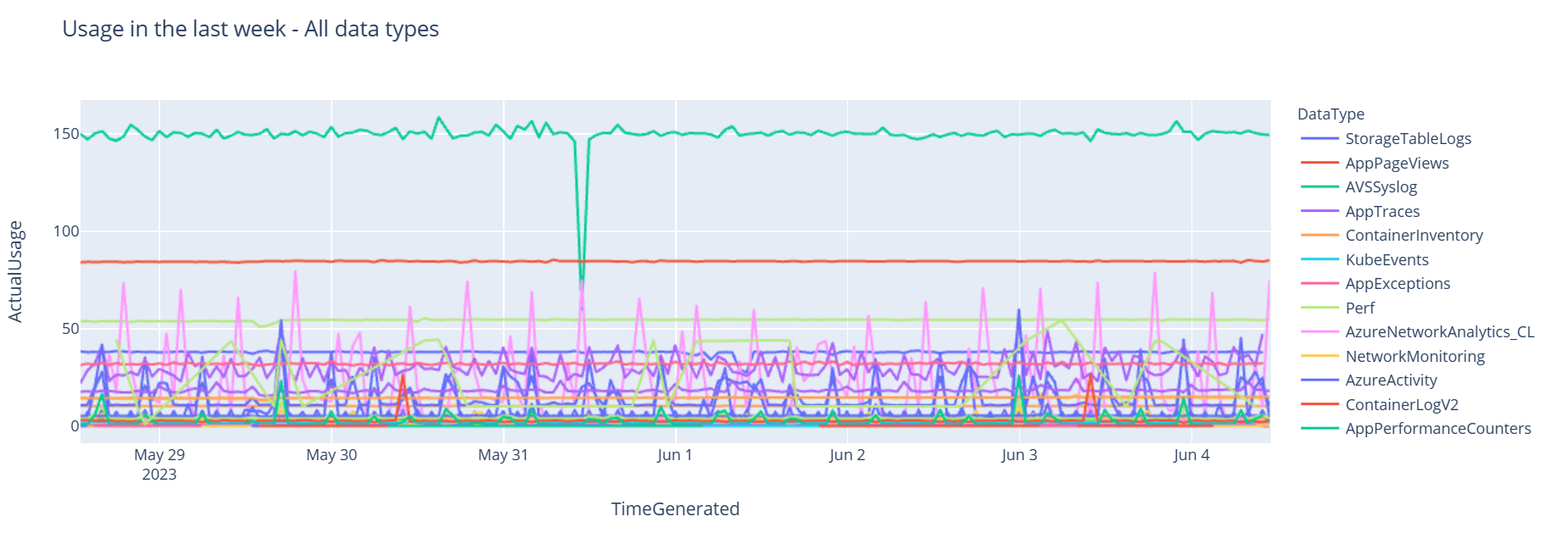
Ha consultado y visualizado correctamente los datos de registro desde el área de trabajo de Log Analytics en el cuaderno.

3. Análisis de datos
Como ejemplo sencillo, vamos a tomar las cinco primeras filas:
analyzed_df = df.head(5)
Para ver un ejemplo de cómo implementar técnicas de aprendizaje automático para analizar datos en registros de Azure Monitor, consulte este cuaderno de ejemplo: Detección de anomalías en los registros de Azure Monitor mediante técnicas de aprendizaje automático.
4. Ingesta de datos analizados en una tabla personalizada en el área de trabajo de Log Analytics (opcional)
Envíe los resultados del análisis a una tabla personalizada en el área de trabajo de Log Analytics para desencadenar alertas o para que estén disponibles para su análisis posterior.
Para enviar datos al área de trabajo de Log Analytics, necesita una tabla personalizada, un punto de conexión de recopilación de datos, una regla de recopilación de datos y una aplicación de Microsoft Entra registrada con permiso para usar la regla de recopilación de datos, como se explica en Tutorial: Envío de datos a registros de Azure Monitor con la API de ingesta de registros (Azure Portal).
Al crear la tabla personalizada:
Cargue este archivo de ejemplo para definir el esquema de tabla:
[ { "TimeGenerated": "2023-03-19T19:56:43.7447391Z", "ActualUsage": 40.1, "DataType": "AzureDiagnostics" } ]
Defina las constantes que necesita para la API de ingesta de registros:
os.environ['AZURE_TENANT_ID'] = "<Tenant ID>"; #ID of the tenant where the data collection endpoint resides os.environ['AZURE_CLIENT_ID'] = "<Application ID>"; #Application ID to which you granted permissions to your data collection rule os.environ['AZURE_CLIENT_SECRET'] = "<Client secret>"; #Secret created for the application os.environ['LOGS_DCR_STREAM_NAME'] = "<Custom stream name>" ##Name of the custom stream from the data collection rule os.environ['LOGS_DCR_RULE_ID'] = "<Data collection rule immutableId>" # immutableId of your data collection rule os.environ['DATA_COLLECTION_ENDPOINT'] = "<Logs ingestion URL of your endpoint>" # URL that looks like this: https://xxxx.ingest.monitor.azure.comIngiera los datos en la tabla personalizada en el área de trabajo de Log Analytics:
from azure.core.exceptions import HttpResponseError from azure.identity import ClientSecretCredential from azure.monitor.ingestion import LogsIngestionClient import json credential = ClientSecretCredential( tenant_id=AZURE_TENANT_ID, client_id=AZURE_CLIENT_ID, client_secret=AZURE_CLIENT_SECRET ) client = LogsIngestionClient(endpoint=DATA_COLLECTION_ENDPOINT, credential=credential, logging_enable=True) body = json.loads(analyzed_df.to_json(orient='records', date_format='iso')) try: response = client.upload(rule_id=LOGS_DCR_RULE_ID, stream_name=LOGS_DCR_STREAM_NAME, logs=body) print("Upload request accepted") except HttpResponseError as e: print(f"Upload failed: {e}")Nota
Al crear una tabla en el área de trabajo de Log Analytics, los datos ingeridos pueden tardar hasta 15 minutos en aparecer en la tabla.
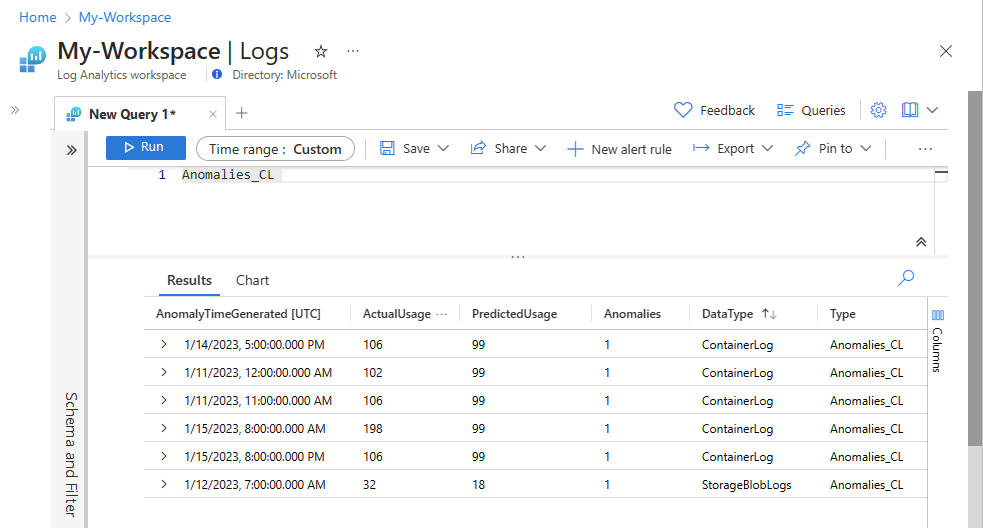
Compruebe que los datos ahora aparecen en la tabla personalizada.

Pasos siguientes
Obtén más información sobre cómo: