Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
Note
La función Fuente de cambios de datos de Lakebase está en versión preliminar pública.
Configura la fuente de datos modificados (CDF) de Lakebase en una tabla de Postgres y, a continuación, observa cómo los cambios a nivel de fila aparecen en la tabla Delta de destino.
Pasos: ① Habilitar la captura de cambios → ② Iniciar la fuente → ③ Seguir una fila hasta el lakehouse → ④ Cambiar la fila y ver cómo fluye
Note
Este es un inicio rápido. Para obtener documentación completa, consulte La fuente de distribución de datos modificados de Lakebase.
Antes de empezar
- Asegúrese de que ha completado La obtención de una base de datos de Postgres. Necesitas un proyecto de Lakebase con la tabla de ejemplo
playing_with_lakebase. - Un catálogo y un esquema de Unity Catalog en los que tiene permisos
CREATE TABLE.
Paso 1: Habilitación de la captura de cambios
Postgres necesita datos de fila completos en el registro de escritura anticipada para que CDF funcione. Configurar la identidad de réplica como full hace que Postgres registre tanto el estado anterior como el nuevo de la fila en cada cambio.
En el Editor de SQL de Lakebase, ejecute:
ALTER TABLE playing_with_lakebase REPLICA IDENTITY FULL;
Más información: Establecimiento de la identidad de réplica en todas las tablas de un esquema y aplicación automática en nuevas tablas
Paso 2: Iniciar la fuente
Lakebase CDF se configura a nivel de esquema. Todas las tablas actuales y futuras del esquema de origen se incluyen automáticamente, por lo que no se eligen tablas individuales.
En la rama de producción, abra la pestaña Fuente de distribución de datos modificados y haga clic en Iniciar. Seleccione public como esquema de origen y, a continuación, elija un catálogo y un esquema de destino de Unity Catalog. La instantánea inicial se inicia inmediatamente y lb_playing_with_lakebase_history aparece como una tabla Delta en su destino.
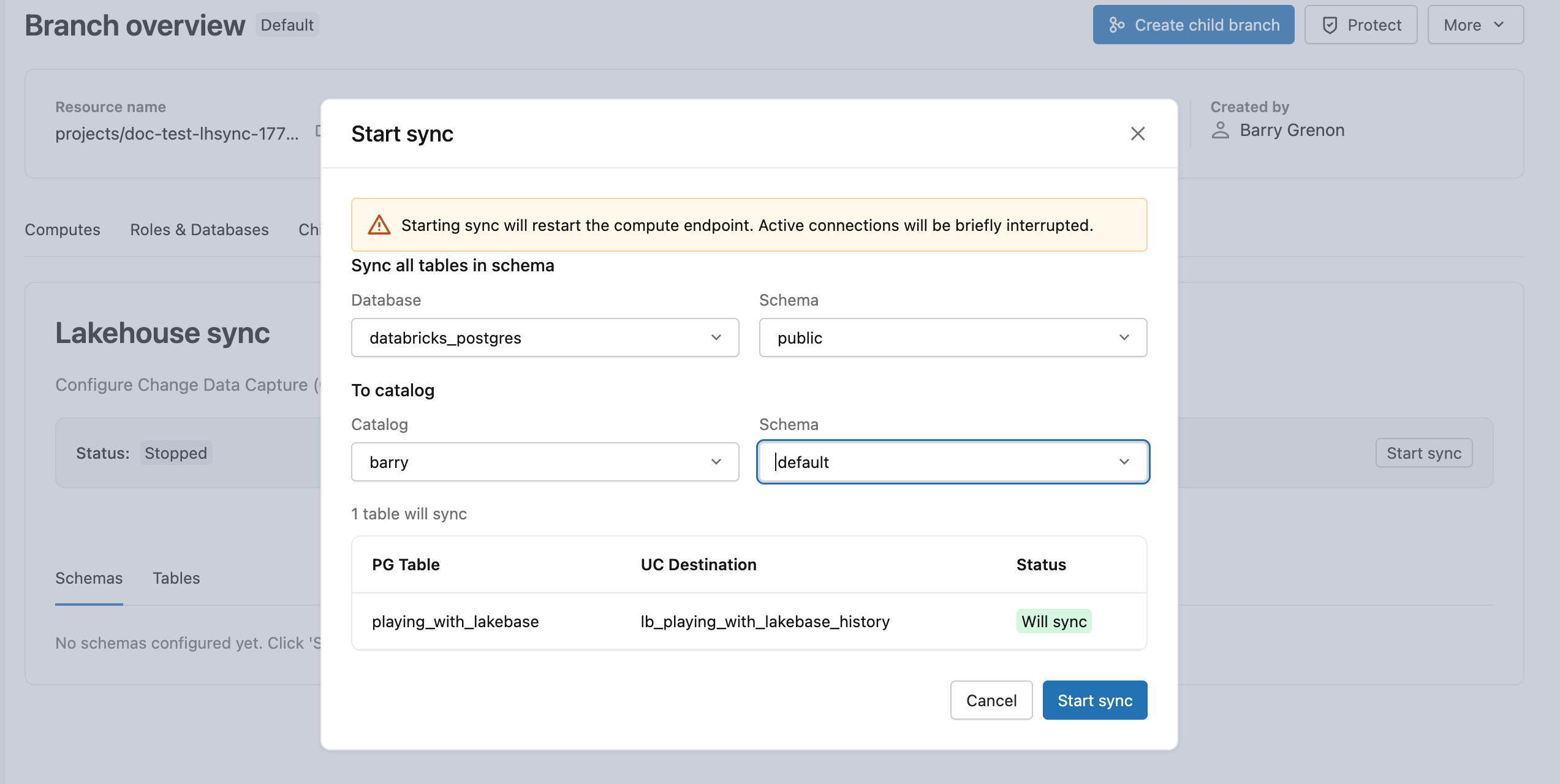
Más información: Inicie la fuente de cambios de datos
Paso 3: Rastrear una fila hasta el lakehouse
Seleccione una fila de Lakebase. Eche un vistazo a la fila id=2:
SELECT * FROM playing_with_lakebase WHERE id = 2;
Ahora busque la misma fila en la tabla de historial delta. Cambie a un cuaderno o almacenamiento de SQL de Databricks y ejecute:
SELECT * FROM <catalog>.<schema>.lb_playing_with_lakebase_history
WHERE id = 2;
Reemplace <catalog> y <schema> por el destino que eligió en el paso 2. Verá una fila id=2 con la misma name y value que en Lakebase, además de columnas adicionales. La instantánea inicial registró todas las filas existentes en Delta como un evento insert, que es lo que representa dicha fila.
Esas columnas adicionales describen qué tipo de evento representa cada fila (_pg_change_type), cuando se produjo (_timestamp) y la información de ordenación de Postgres (_pg_lsn, _pg_xid).
Más información: Esquema de la tabla de destino | Asignación de tipos de datos
Paso 4: Cambia la fila y observa cómo se propaga
De nuevo en el Editor de SQL de Lakebase, actualice la fila id=2:
UPDATE playing_with_lakebase SET value = 55.5 WHERE id = 2;
Espere unos segundos para que el cambio aparezca en la fuente y vuelva a consultar la tabla de historial:
SELECT id, value, _pg_change_type, _timestamp
FROM <catalog>.<schema>.lb_playing_with_lakebase_history
WHERE id = 2
ORDER BY _pg_lsn DESC;

La fila id=2 ahora aparece tres veces: el original , un insert con el valor anterior update_preimagey un update_postimage con el nuevo valor. Cada cambio en la fila se convierte en una nueva fila de historial, por lo que siempre tiene una pista de auditoría completa. Las eliminaciones funcionan de la misma manera, anexando una fila con _pg_change_type = 'delete'.
Más información: Patrones de cambio comunes | Crear canalizaciones posteriores
Pasos siguientes
- Cree una canalización de bajada: Convierta la tabla de historial en un agregado activo con una vista materializada, SDP o Structured Streaming.
- Ejecute análisis: Consulte las tablas de historial de Delta con Databricks SQL.
- Use la capa de bronce: Integre la tabla de historial en una arquitectura de medallones.
- Revise los límites de producción: Consulte limitaciones y solución de problemas yadministración de cambios de esquema.
- Exploración de Lakebase:Conceptos básicos | de Lakebase