Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
Los flujos de datos son una tecnología de preparación de datos basada en la nube y de autoservicio. En este artículo, creará su primer flujo de datos, obtendrá datos para este y, después, transformará los datos y publicará el flujo de datos.
Requisitos previos
Antes de empezar, es preciso cumplir los siguientes requisitos previos:
- Una cuenta de cliente de Microsoft Fabric con una suscripción activa. Crear una cuenta gratuita.
- Asegúrese de que tiene un área de trabajo habilitada para Microsoft Fabric: Crear un área de trabajo.
Crear un flujo de datos
En esta sección, creará su primer flujo de datos.
Nota:
A partir de abril de 2026, todos los nuevos elementos de Dataflow Gen2 se crean con soporte para la integración de CI/CD y Git por defecto. La opción para crear elementos de Dataflow Gen2 sin compatibilidad con CI/CD ya no está disponible. Los flujos de datos que no son de CI/CD existentes siguen funcionando.
Vaya al área de trabajo de Microsoft Fabric; para ello, vaya al portal Microsoft Fabric, seleccione Workspaces en el panel de navegación izquierdo y, a continuación, seleccione el área de trabajo en la lista.
Seleccione +Nuevo elemento y, a continuación, seleccione Dataflow Gen2.
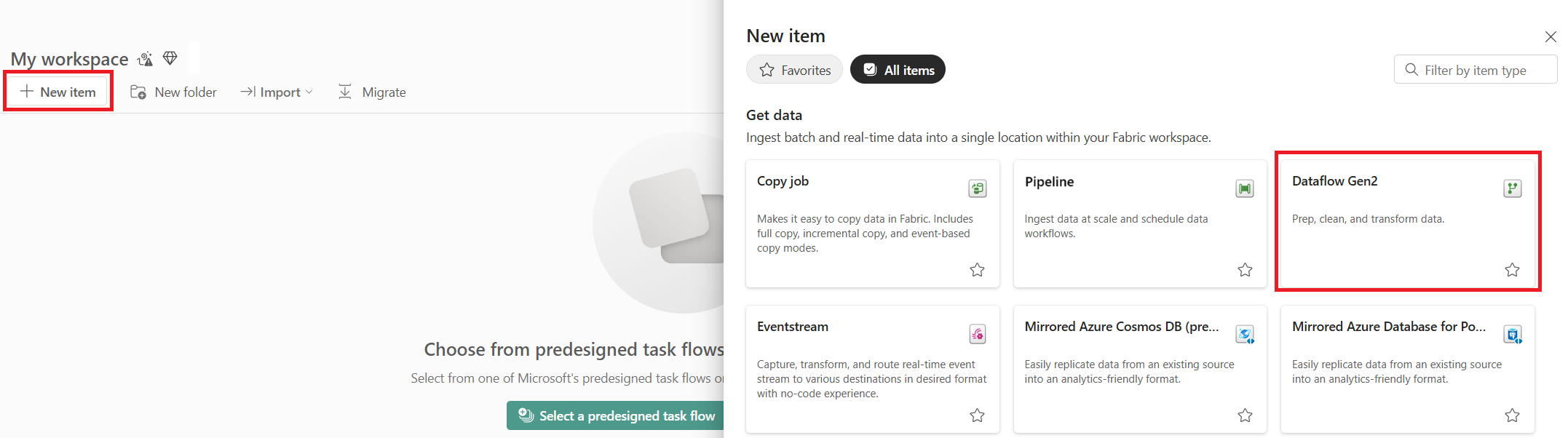
Obtención de datos
Vamos a obtener algunos datos. En este ejemplo, obtendrá datos de un servicio de OData. Siga estos pasos para obtener datos en el flujo de datos.
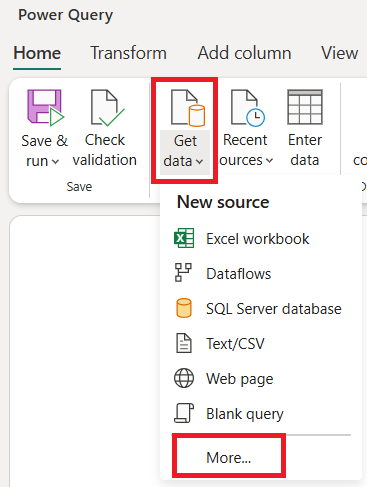
En el editor de flujos de datos, seleccione Obtener datos y, a continuación, seleccione Más.
En Elegir origen de datos, seleccione Ver más.
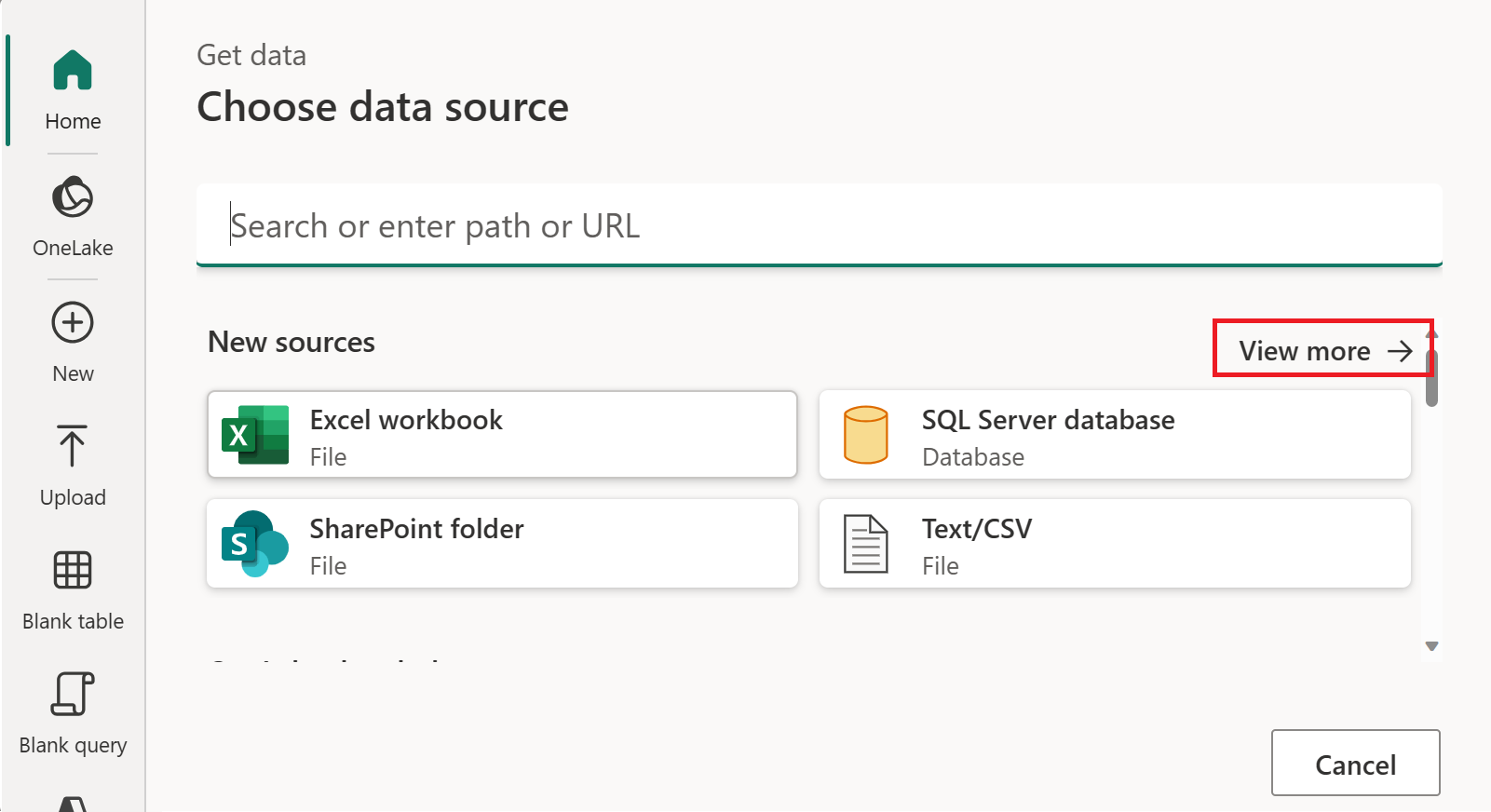
En Nuevo origen, seleccione Otros>OData como origen de datos.

Escriba la dirección URL
https://services.odata.org/v4/northwind/northwind.svc/y, a continuación, seleccione Siguiente.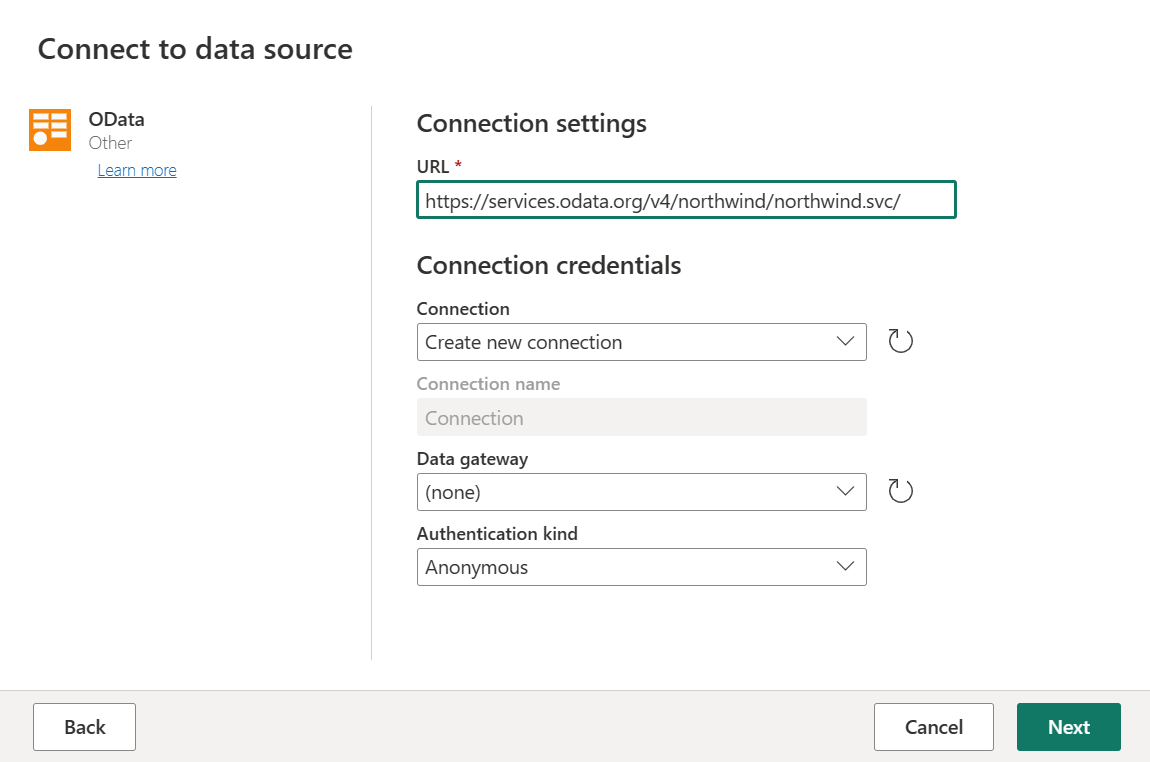
Seleccione las tablas Orders (Pedidos) y Customers (Clientes), y después seleccione Crear.
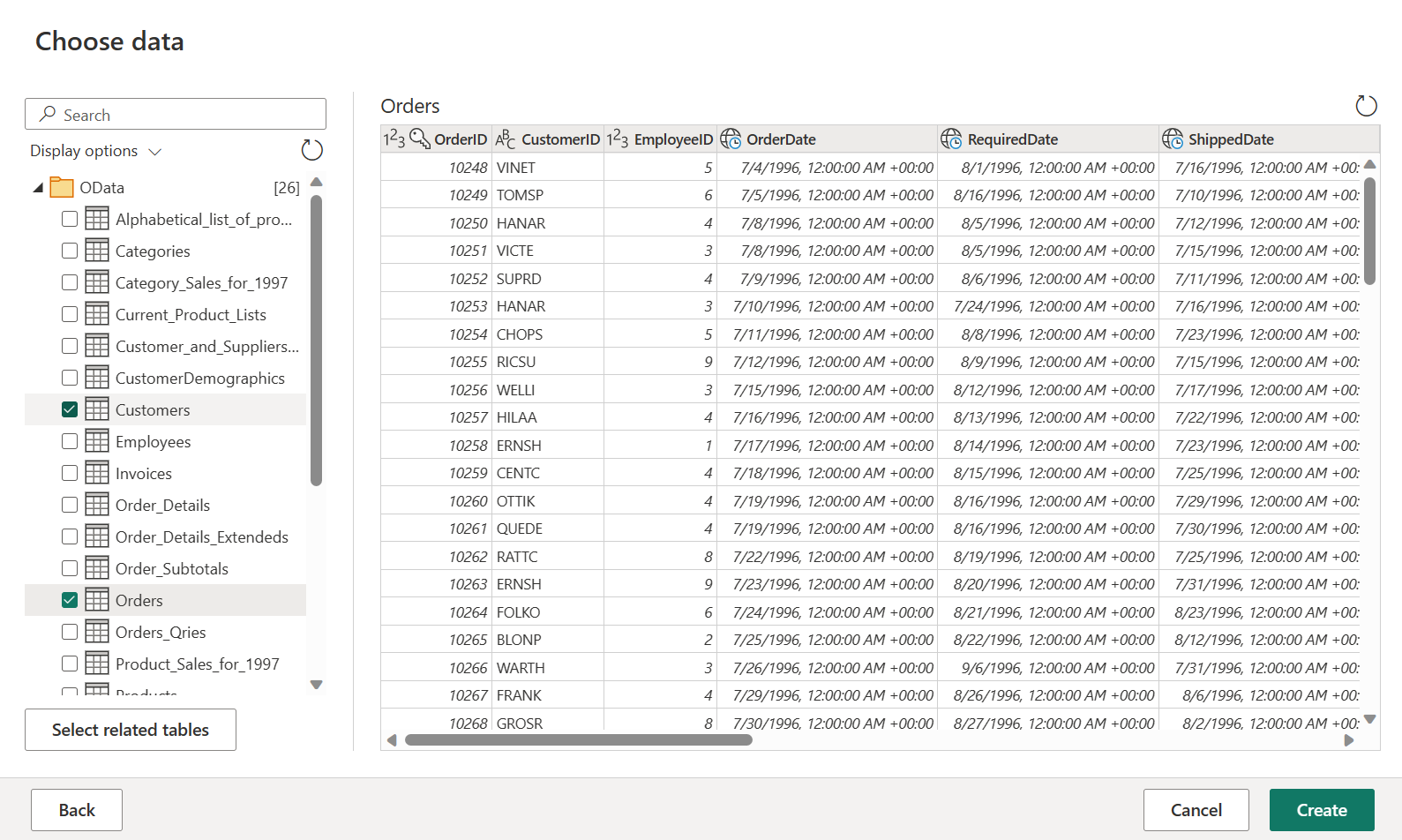



Puede obtener más información sobre la experiencia y la funcionalidad de obtención de datos en la introducción a la obtención de datos.
Aplicación de transformaciones y publicación
Cargó sus datos en su primer flujo de datos. ¡Felicitaciones! Ahora es el momento de aplicar un par de transformaciones para incorporar estos datos a la forma que necesitamos.
Transformas los datos en el editor de Power Query. Puede encontrar información general detallada del editor de Power Query en La interfaz de usuario de Power Query, pero esta sección le guía por los pasos básicos:
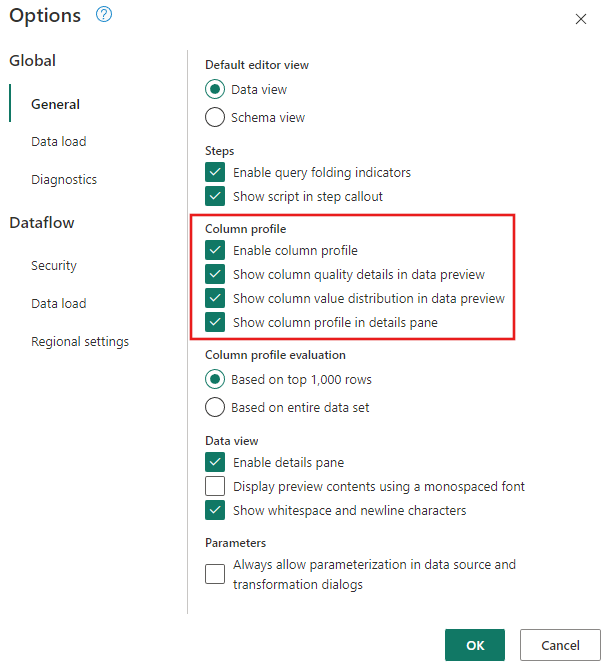
Asegúrese de que las herramientas de generación de perfiles de datos están activadas. Vaya a Opciones de inicio>Opciones>globales y, a continuación, seleccione todas las opciones en Perfil de columna.
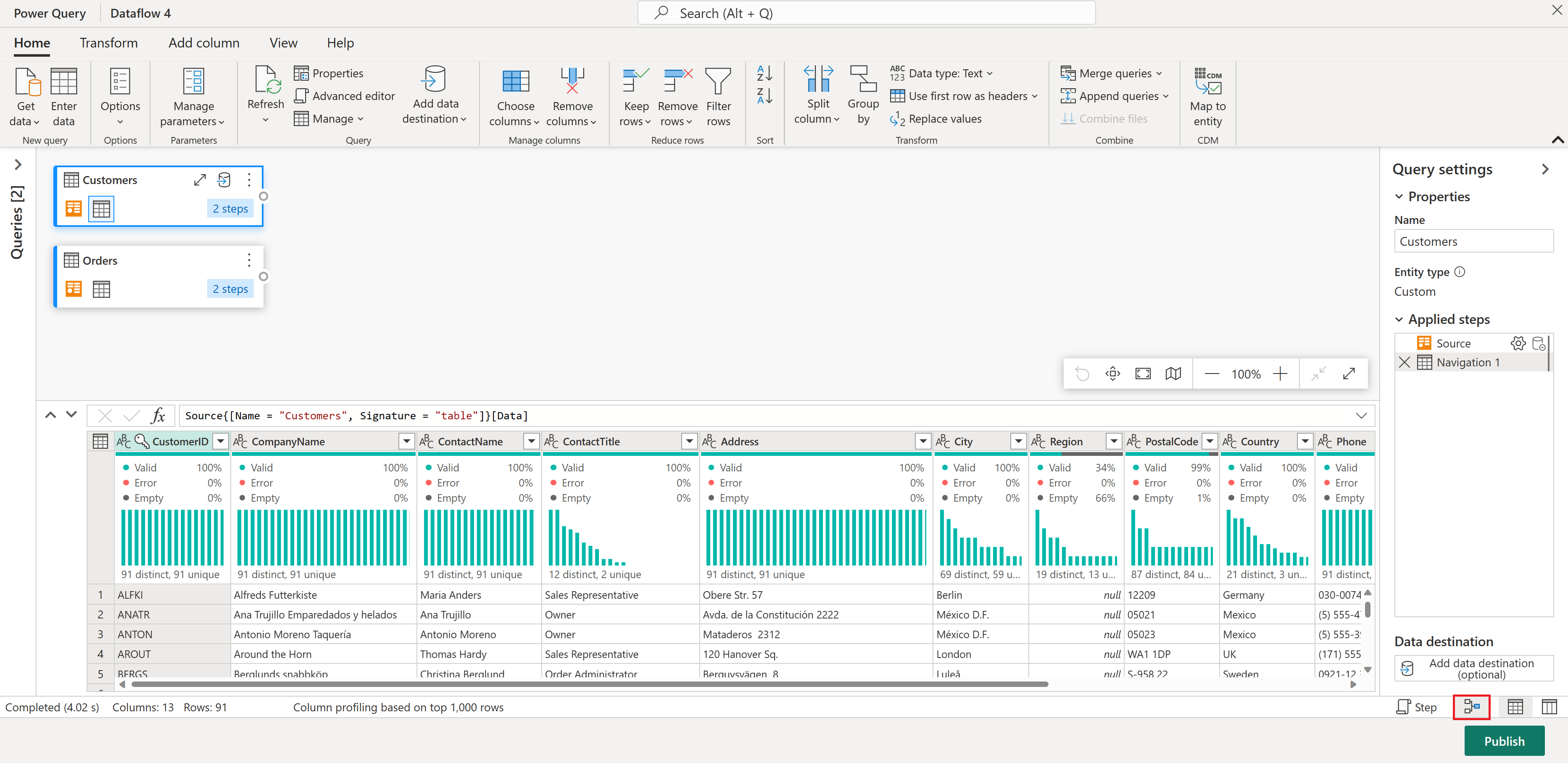
Asegúrese también de habilitar la vista diagrama mediante las configuraciones de diseño en la View de la cinta de opciones del editor de Power Query o seleccionando el icono de vista de diagrama en la parte inferior derecha de la ventana de Power Query.
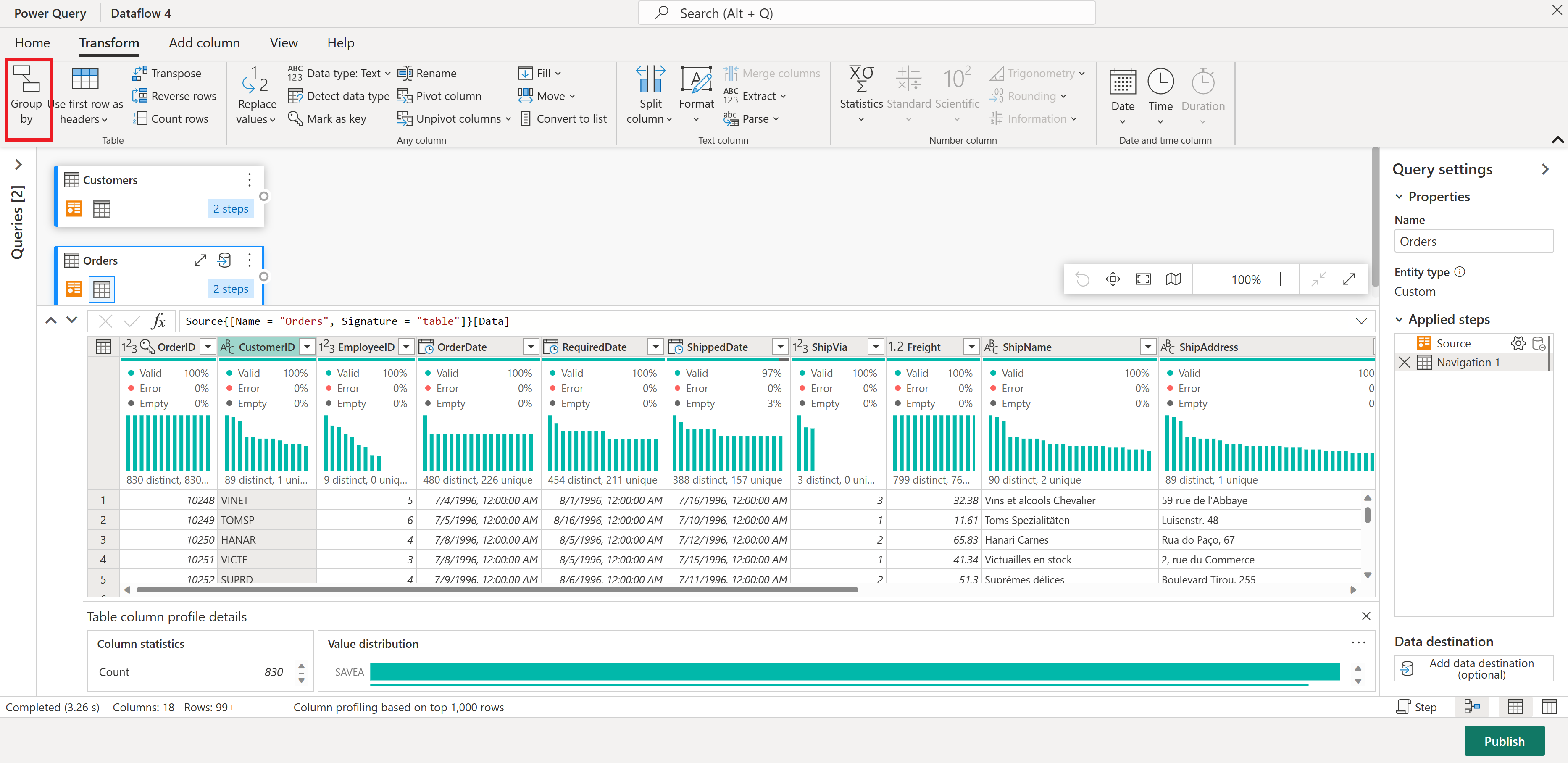
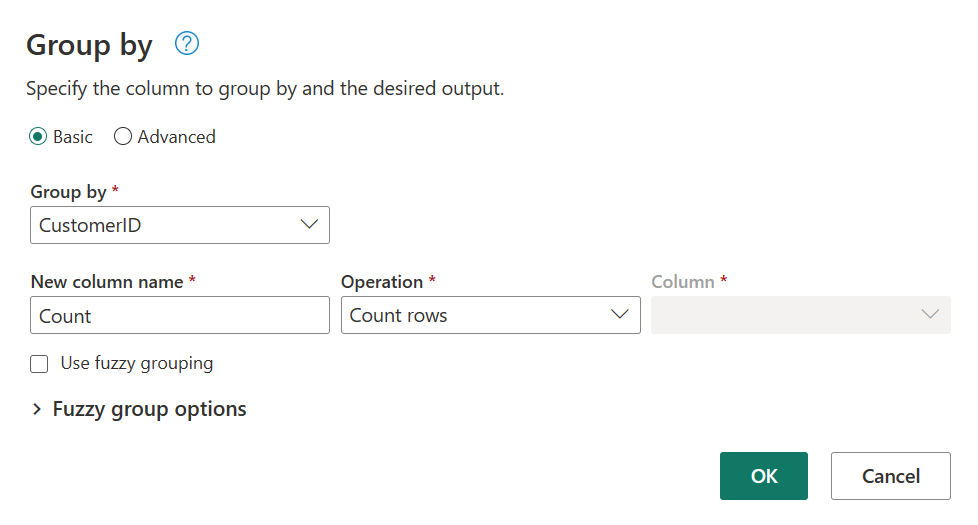
En la tabla Pedidos, calcule el número total de pedidos por cliente: seleccione la columna CustomerID en la vista previa de datos y, a continuación, seleccione Agrupar por en la pestaña Transformar de la cinta de opciones.
Realice un recuento de filas como agregación dentro de Agrupar por. Puede obtener más información sobre las funcionalidades de Group By en Agrupación o resumen de filas.
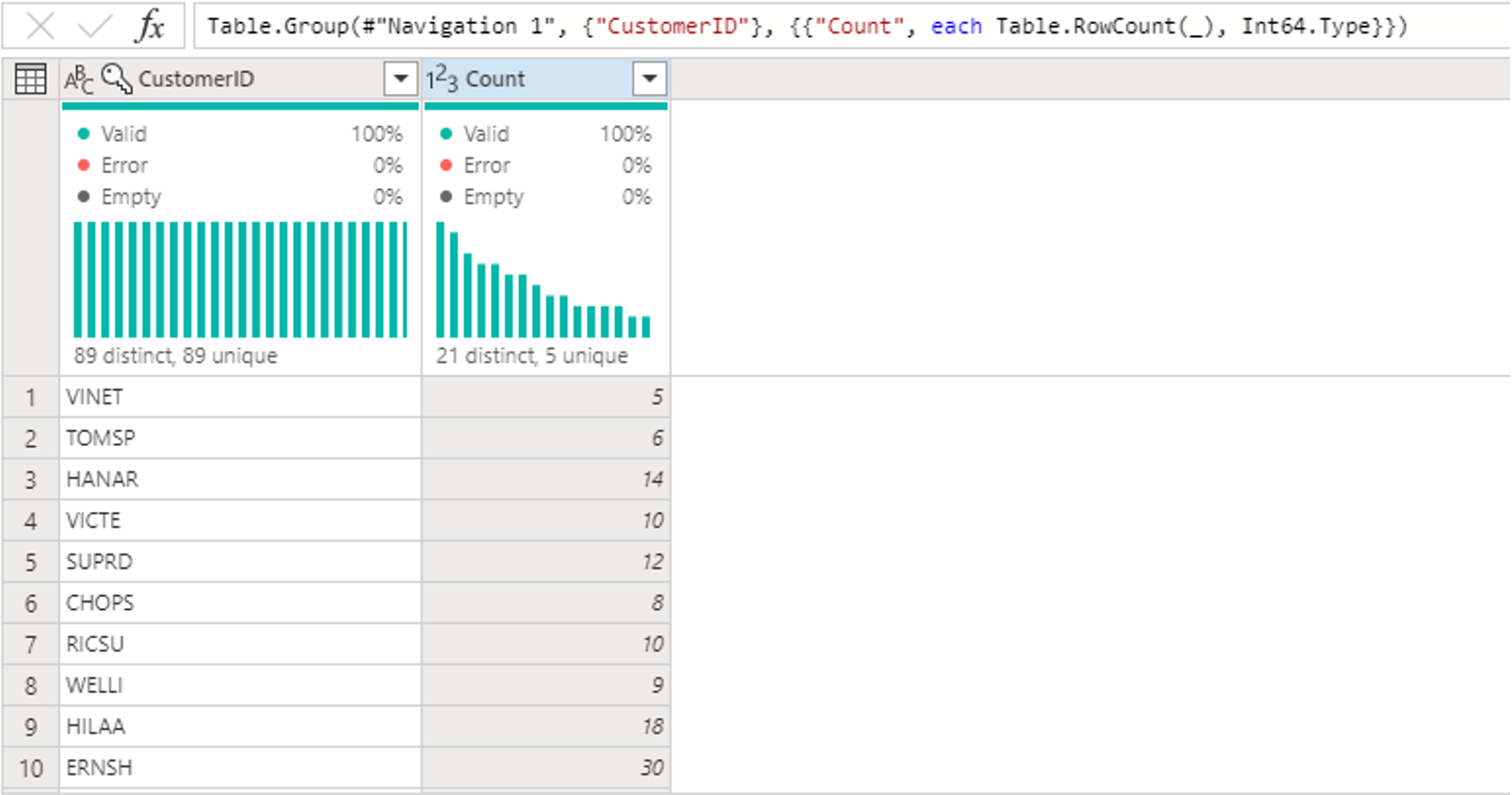
Después de agrupar los datos en la tabla Orders, obtendremos una tabla de dos columnas con CustomerID y Count como columnas.
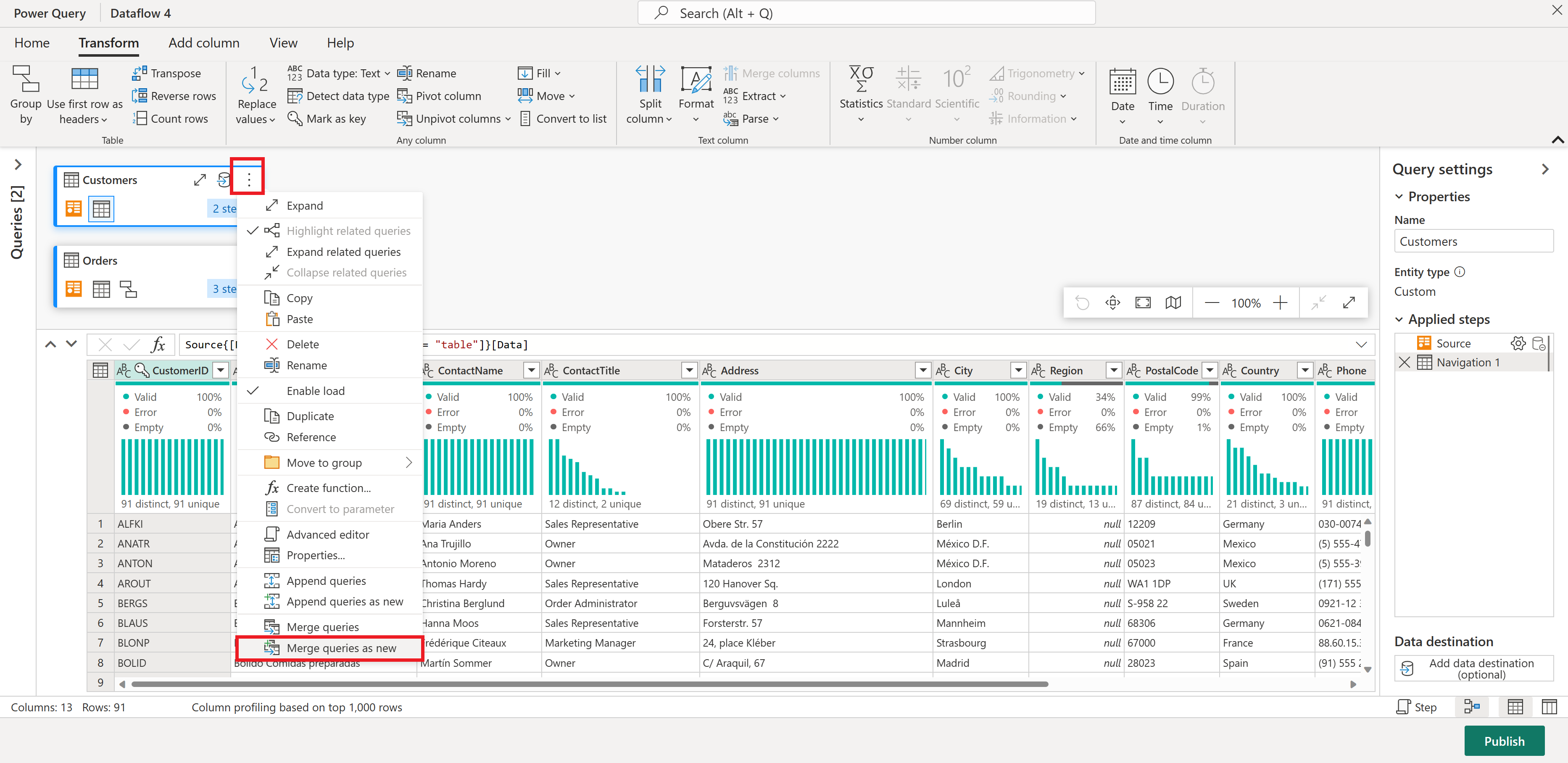
A continuación, usted quiere combinar datos de la tabla Clientes con el recuento de pedidos por cliente: seleccione la consulta Clientes en la Vista de diagrama y use el menú "⋮" para acceder a la transformación Combinar consultas como nueva.
Configure la operación Merge seleccionando CustomerID como columna coincidente en ambas tablas. Después, seleccione Aceptar.
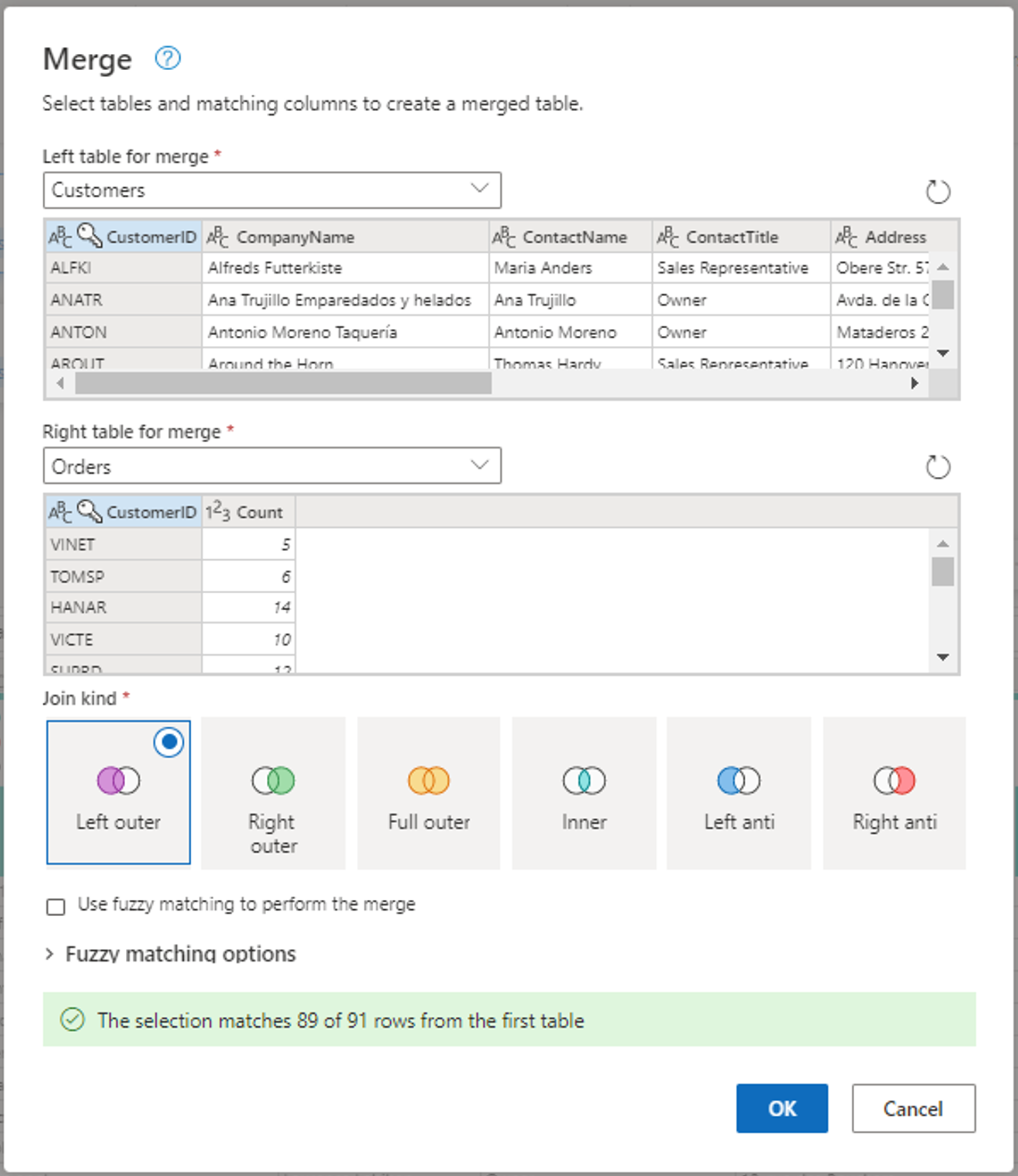
Captura de pantalla de la ventana Combinar, con la tabla izquierda para combinar establecida en la tabla Customers y la tabla derecha para combinar establecida en la tabla Orders. La columna CustomerID está seleccionada para las tablas Customers y Orders. Además, el Tipo de unión se establece en Externa izquierda. Todas las demás selecciones se establecen en su valor predeterminado.
Ahora hay una nueva consulta con todas las columnas de la tabla Customers y una columna con datos anidados de la tabla Orders.

Vamos a centrarnos en unas pocas columnas de la tabla Customers. Para ello, active la vista de esquema seleccionando el botón vista de esquema en la esquina inferior derecha del editor de flujo de datos.
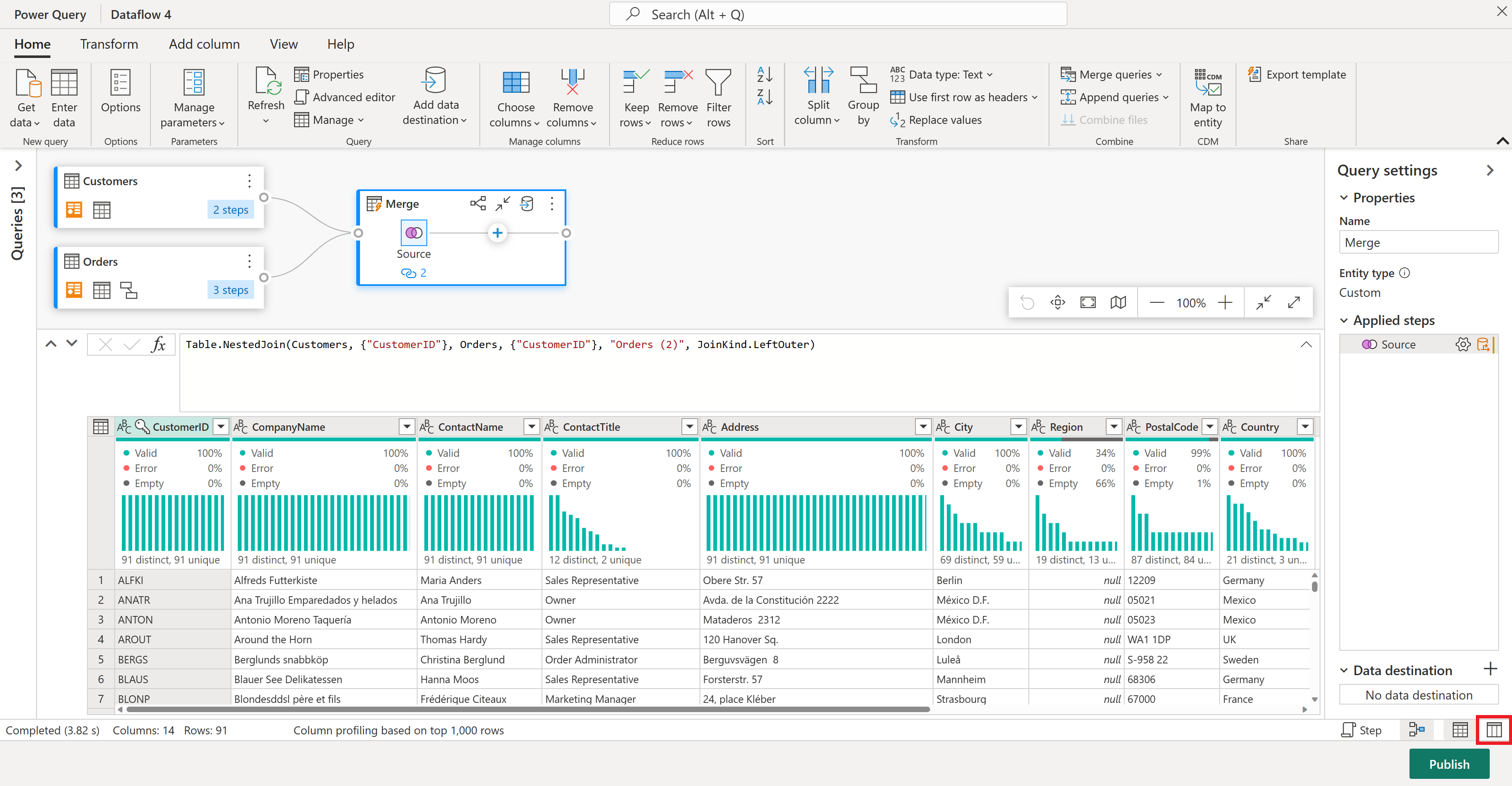
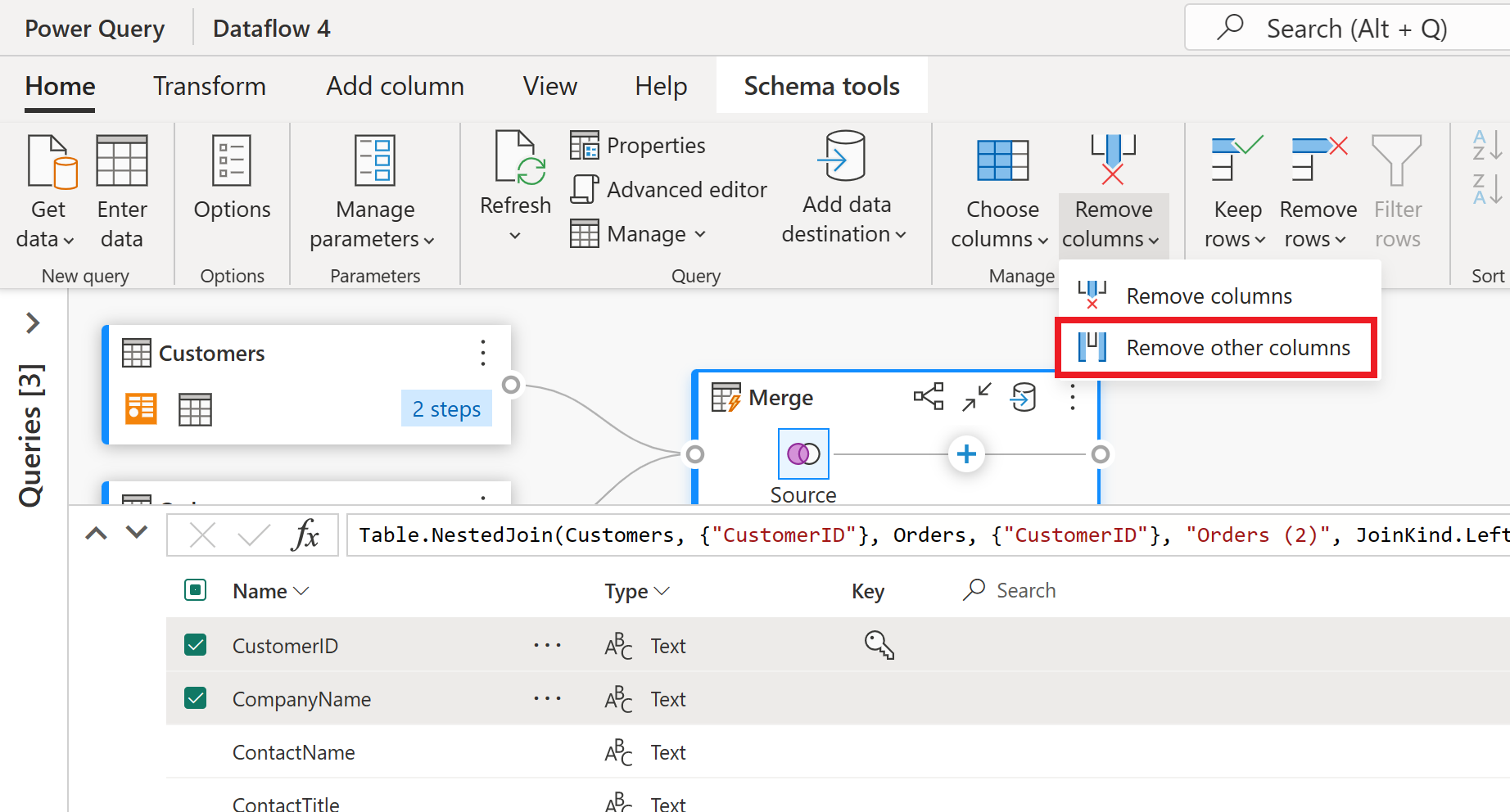
En la vista de esquema, verá todas las columnas de la tabla. Seleccione CustomerID, CompanyName y Orders (2) . A continuación, vaya a la pestaña Herramientas de esquema , seleccione Quitar columnas y elija Quitar otras columnas. Esto conserva solo las columnas que desea.
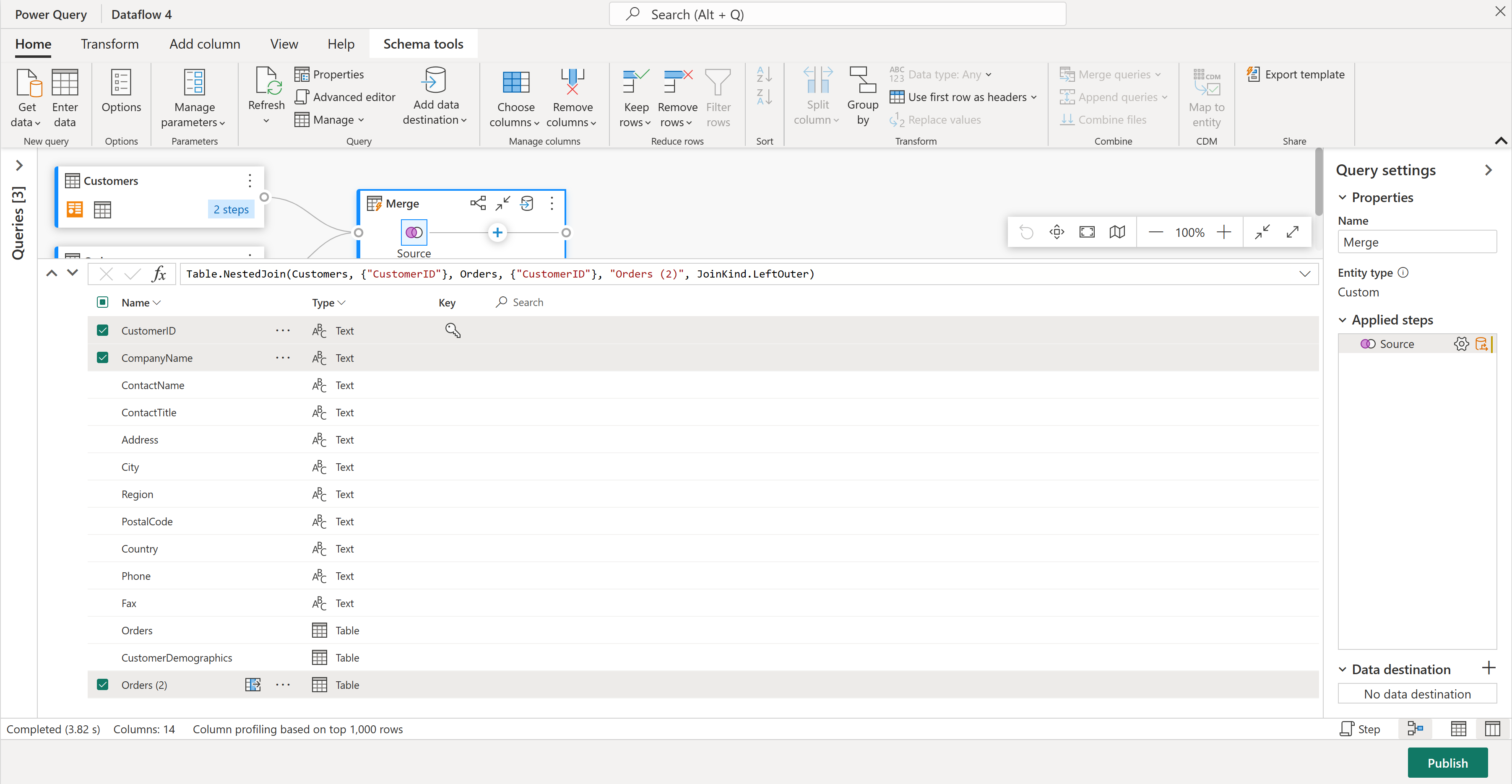
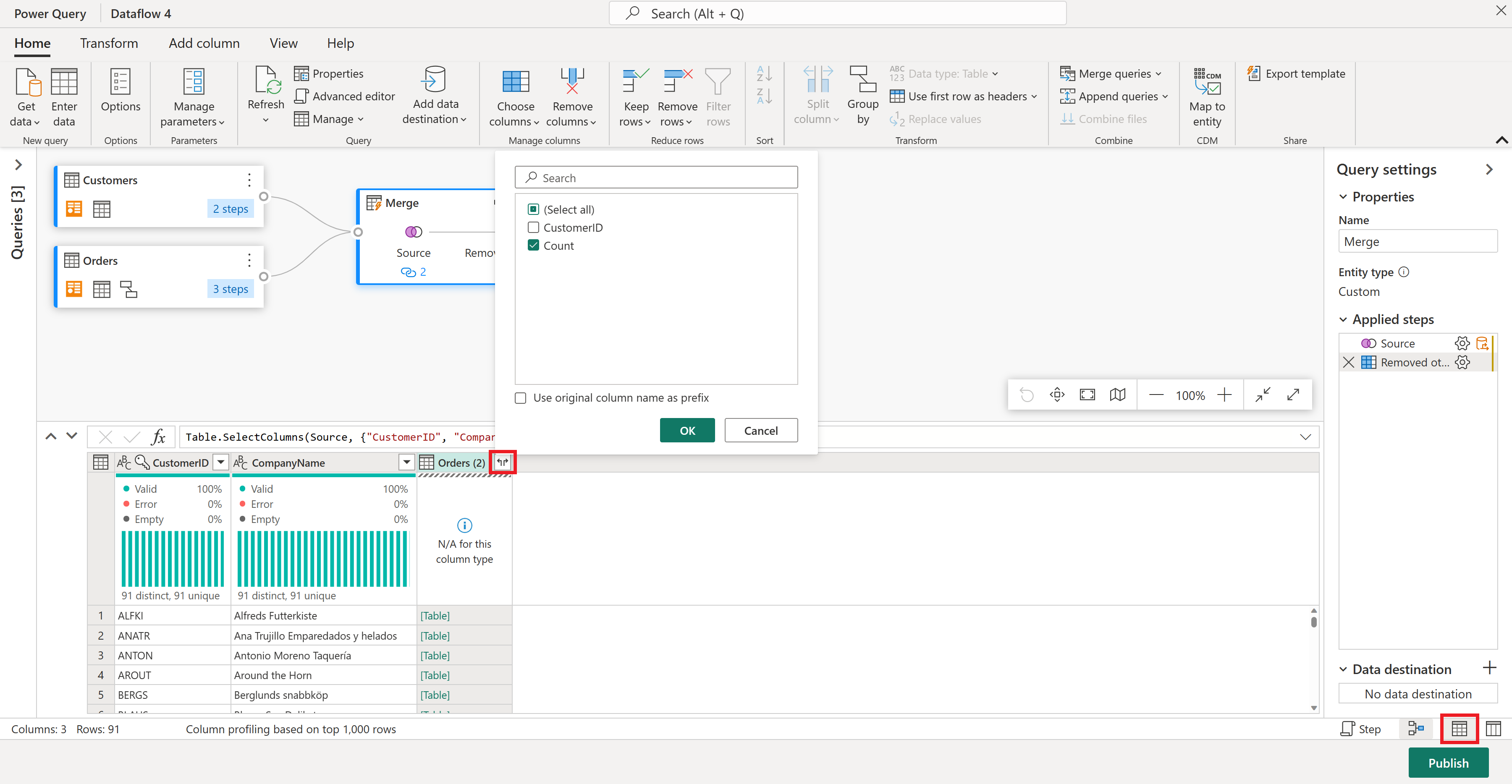
La columna Pedidos (2) contiene detalles adicionales del paso de combinación. Para ver y usar estos datos, seleccione el botón Mostrar vista de datos en la esquina inferior derecha, junto a Mostrar vista de esquema. A continuación, en el encabezado de columna Pedidos (2), seleccione el icono Expandir columna y elija la columna Recuento . Esto agrega el recuento de pedidos de cada cliente a la tabla.
Ahora vamos a clasificar a los clientes por cuántos pedidos han realizado. Seleccione la columna Count (Recuento), vaya a la pestaña Agregar columna y seleccione Rank column (Columna de clasificación). Esto agrega una nueva columna que muestra la clasificación de cada cliente en función de su recuento de pedidos.
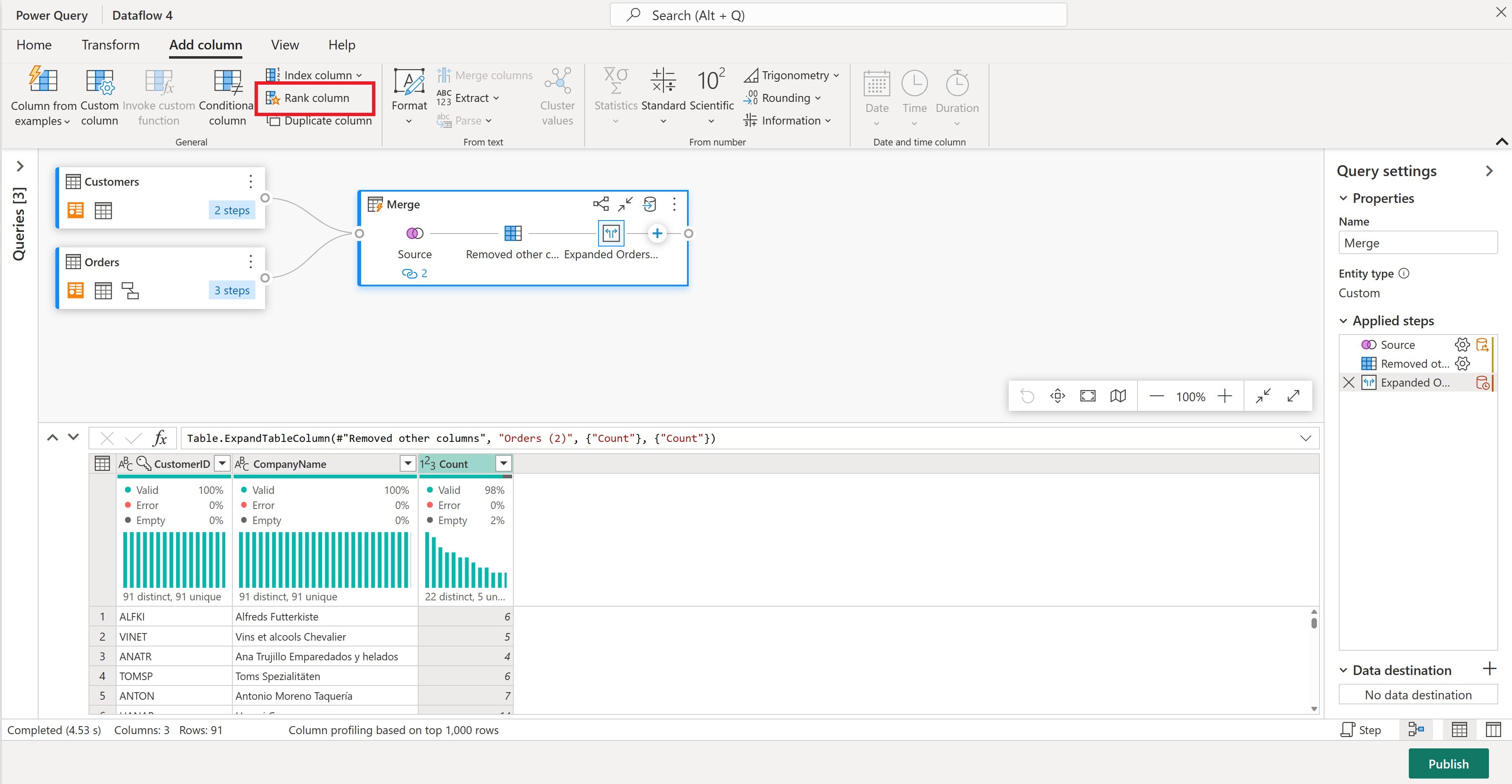
Mantenga los ajustes predeterminados en Rank Column. A continuación, seleccione Aceptar para aplicar esta transformación.
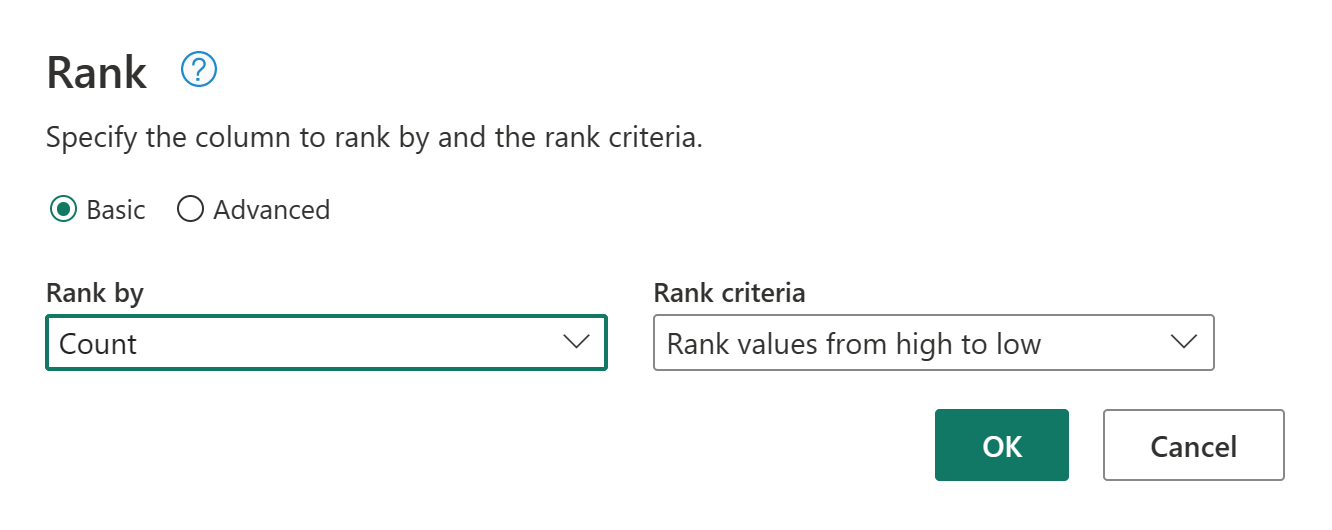
Ahora cambie el nombre de la consulta resultante a Ranked Customers (Clientes clasificados) usando el panel Configuración de consulta de la parte derecha de la pantalla.
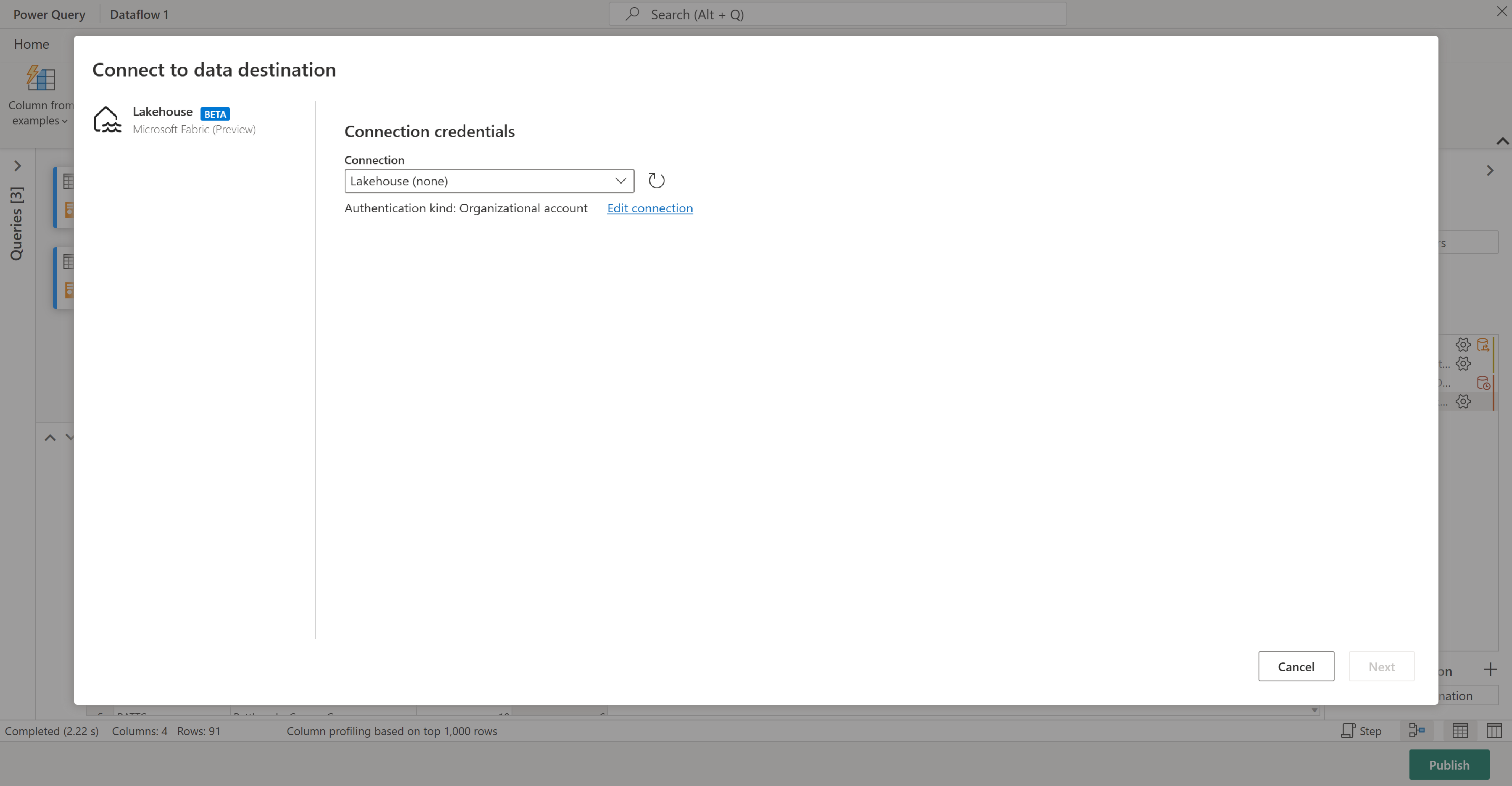
Está listo para establecer dónde van los datos. En el panel Configuración de consulta, desplácese hasta la parte inferior y seleccione Elegir destino de datos.
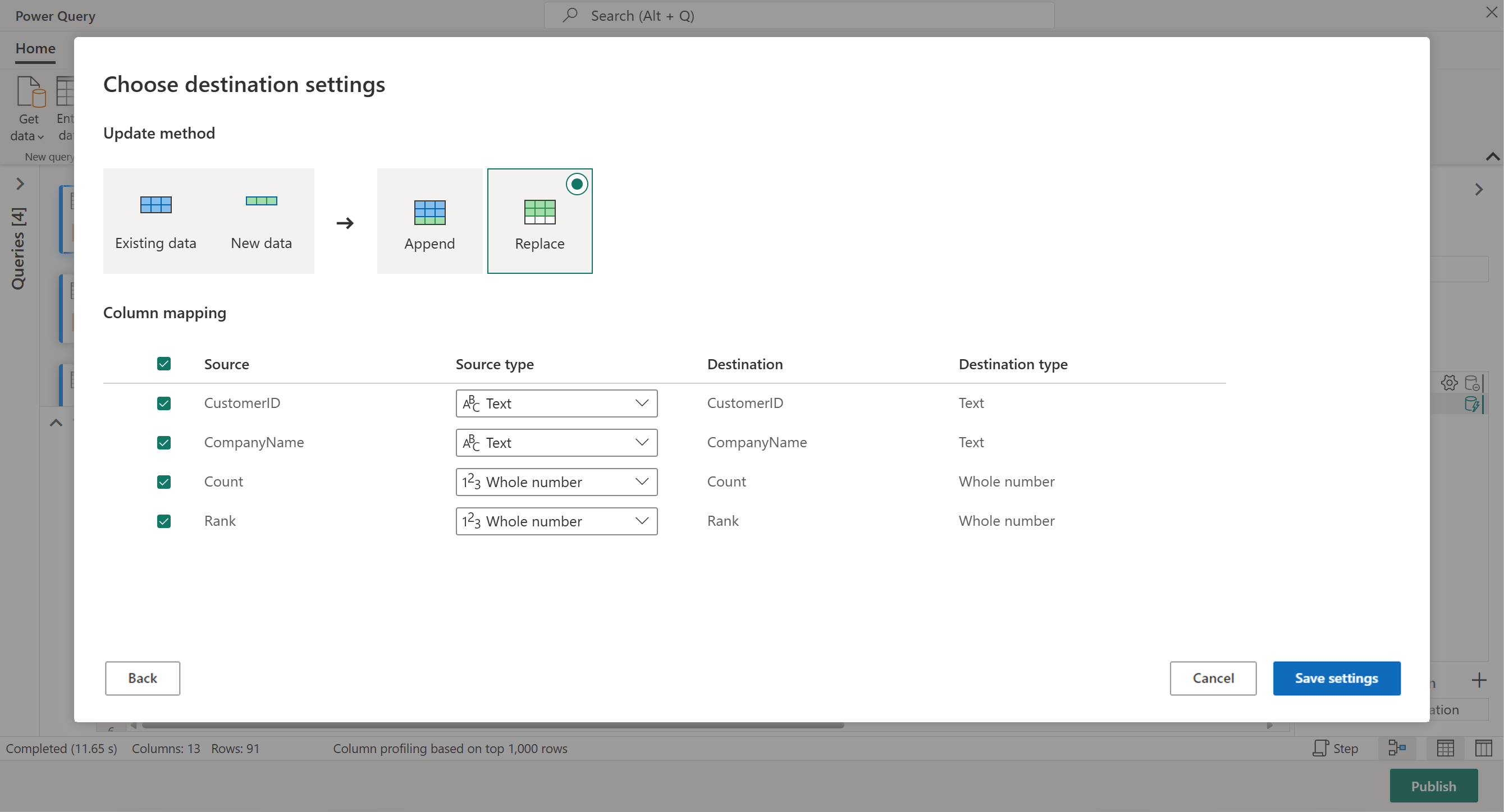
Puede enviar sus resultados a un lakehouse si dispone de alguno, o puede omitir este paso si no es el caso. Aquí puede seleccionar cuál lakehouse y tabla usar para sus datos, y elegir si desea agregar nuevos datos (Anexar) o reemplazar lo que hay allí (Reemplazar).
El flujo de datos ya está listo para publicarse. Revise las consultas en la vista de diagrama y, a continuación, seleccione Publicar.
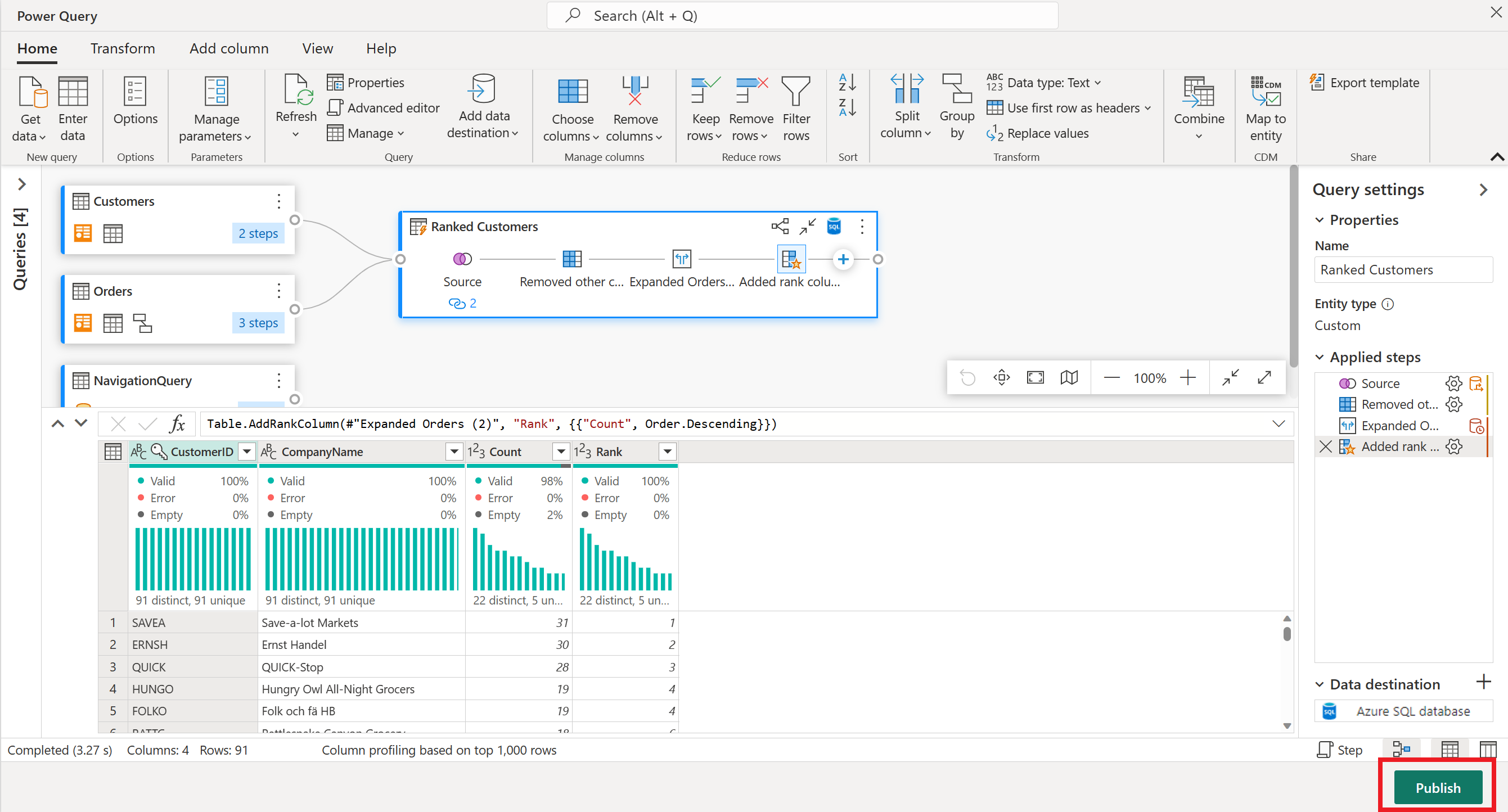
Seleccione Publicar en la esquina inferior derecha para guardar el flujo de datos. Volverá a su área de trabajo, donde un icono de carga junto al nombre del flujo de datos muestra que se está publicando. Cuando el girador desaparece, el flujo de datos está listo para actualizarse.
Importante
La primera vez que cree una instancia de Dataflow Gen2 en un área de trabajo, Fabric configure algunos elementos en segundo plano (Lakehouse y Warehouse) que ayuden a ejecutar el flujo de datos. Todos los flujos de datos del área de trabajo comparten estos elementos y no se deben eliminar. No están diseñados para usarse directamente y normalmente no son visibles en el área de trabajo, pero es posible que los vea en otros lugares, como cuadernos o análisis de SQL. Busque nombres que empiecen por
DataflowStagingpara detectarlos.En el área de trabajo, seleccione el icono Programar actualización.

Active la actualización programada, seleccione Agregar otra hora y configure la actualización como se muestra en la captura de pantalla siguiente.
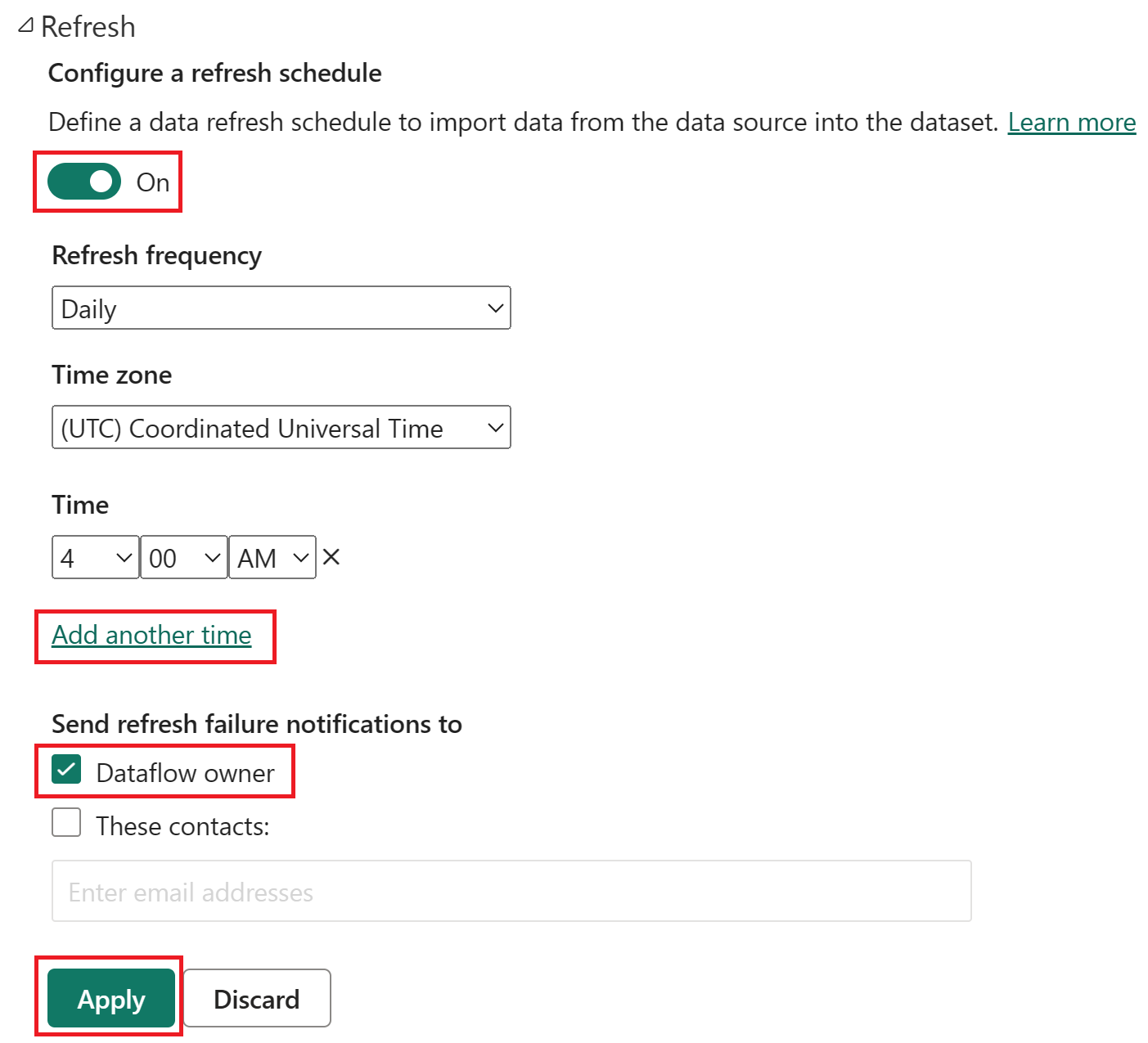
Captura de pantalla de las opciones de actualización programadas, con la actualización programada activada, la frecuencia de actualización establecida en Diaria, la zona horaria establecida en hora universal coordinada y la hora establecida en 4:00 a. m. El botón de encendido, la opción de agregar otra hora, el propietario del flujo de datos y el botón de aplicar están resaltados.













Limpieza de recursos
Si no va a seguir usando este flujo de datos, elimínelo siguiendo los pasos siguientes:
Vaya al área de trabajo de Microsoft Fabric.
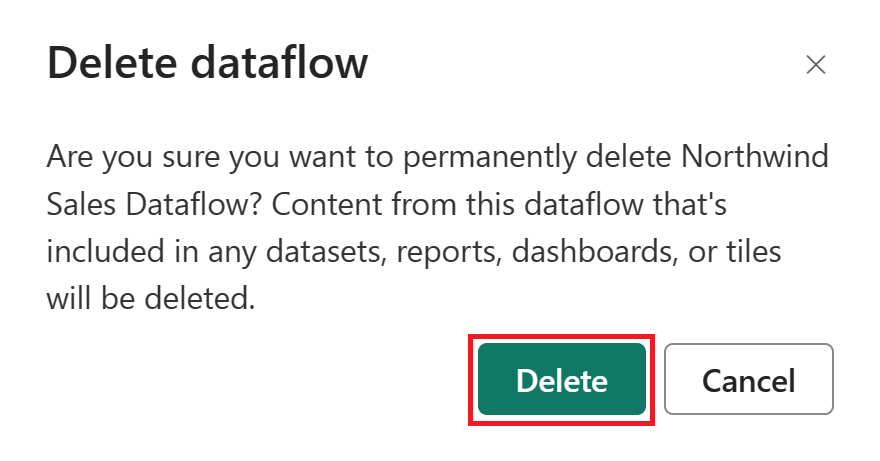
Seleccione los puntos suspensivos verticales junto al nombre del flujo de datos y, a continuación, seleccione Eliminar.
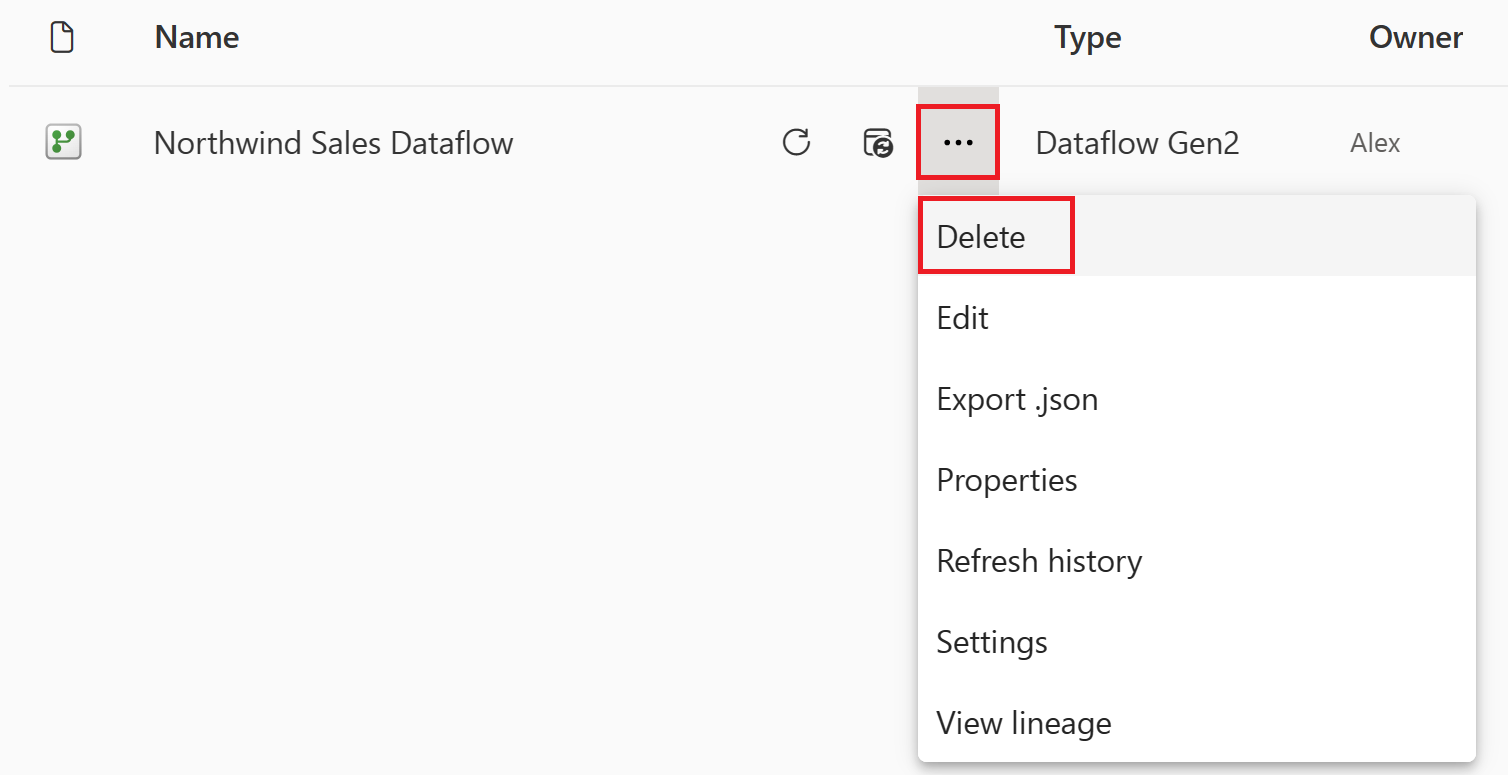
Seleccione Eliminar para confirmar la eliminación del flujo de datos.
Contenido relacionado
El flujo de datos de este ejemplo le muestra cómo cargar y transformar datos en el flujo de datos Gen2. Ha aprendido a:
- Cree un flujo de datos Gen2.
- Transformar los datos.
- Configure los valores de destino para los datos transformados.
- Ejecute y programe la canalización.
Vaya al siguiente artículo para aprender a crear la primera canalización.