Exporta Dataverse datos en formato Delta Lake
Usa Azure Synapse Link for Dataverse para exportar os teus Microsoft Dataverse datos a Azure Synapse Analytics en formato Delta Lake. Despois explora os teus datos e acelera o tempo para obter información. Este artigo ofrece a seguinte información e móstralle como realizar as seguintes tarefas:
- Explica Delta Lake e Parquet e por que deberías exportar datos neste formato.
- Exporta os teus Dataverse datos ao teu Azure Synapse Analytics espazo de traballo en formato Delta Lake co Azure Synapse Link.
- Supervisa a túa Azure Synapse Link e a conversión de datos.
- Consulta os teus datos de Azure Data Lake Storage Gen2.
- Consulta os teus datos desde Synapse Workspace.
Importante
- Se estás a actualizar de CSV a Delta Lake con vistas personalizadas existentes, recomendámosche que actualices o script para substituír todas as táboas particionadas por non_particionadas. Fai isto buscando exemplos de
_partitionede substitúeos por unha cadea baleira. - Para a Dataverse configuración, só o anexo está habilitado de forma predeterminada para exportar datos CSV no modo
appendonly. Pero a táboa de Delta Lake terá unha estrutura de actualización no lugar porque a conversión de Delta Lake inclúe un proceso de combinación periódico. - Non hai custos incorridos coa creación de Spark pools. Os cargos só se incorren unha vez que se executa un traballo de Spark no grupo de Spark de destino e a instancia de Spark é instanciada baixo demanda. Estes custos están relacionados co uso de Azure Synapse espazo de traballo Spark e factúranse mensualmente. O custo de realizar Spark computing depende principalmente do intervalo de tempo para a actualización incremental e dos volumes de datos. Máis información: Azure Synapse Analytics prezos
- É importante ter en conta estes custos adicionais á hora de decidir usar esta función, xa que non son opcionais e deben pagarse para seguir usando esta función.
- O fin de vida útil anunciado (EOLA) para Azure Synapse O tempo de execución de Apache Spark 3.1 anunciouse o 26 de xaneiro de 2023. De acordo coa política de ciclo de vida de Apache Spark Synapse, Azure Synapse o tempo de execución de Apache Spark 3.1 retirarase e desactivarase a partir do 26 de xaneiro de 2024. Despois da data de EOL, os tempos de execución retirados non están dispoñibles para os novos grupos de Spark e os fluxos de traballo existentes non se poden executar. Os metadatos permanecerán temporalmente no espazo de traballo de Synapse. Máis información: Azure Synapse Período de execución para Apache Spark 3.1 (EOLA). Para que o teu Synapse Link para Dataverse con exportación ao formato Delta Lake se actualice a Spark 3.3, fai unha actualización local dos teus perfís existentes. Máis información: Actualización local a Apache Spark 3.3 con Delta Lake 2.2
- A partir do 4 de xaneiro de 2024, só se admitirá a versión 3.3 de Spark Pool cando se cree inicialmente a ligazón.
Nota
O Azure Synapse Link estado en Power Apps (make.powerapps.com) reflicte o estado de conversión de Delta Lake:
Countmostra o número de rexistros na táboa Delta Lake.Last synchronized onDatetime representa a última marca de tempo de conversión exitosa.Sync statusmóstrase como activo unha vez que se complete a sincronización de datos e a conversión de Delta Lake, o que indica que os datos están listos para o seu consumo.
Que é o lago Delta?
Delta Lake é un proxecto de código aberto que permite construír unha arquitectura lakehouse encima dos lagos de datos. Delta Lake ofrece transaccións ACID (atomicidade, coherencia, illamento e durabilidade), manexo escalable de metadatos e unifica o procesamento de datos por lotes e transmisión por riba dos lagos de datos existentes. Azure Synapse Analytics é compatible con Linux Foundation Delta Lake. A versión actual de Delta Lake incluída con Azure Synapse soporta idiomas para Scala, PySpark e .NET. Máis información: Que é o lago Delta?. Tamén podes obter máis información co vídeo de Introdución ás táboas Delta.
Apache Parquet é o formato base para Delta Lake, que lle permite aproveitar os esquemas de codificación e compresión eficientes que son nativos do formato. O formato de ficheiro Parquet usa a compresión por columnas. É eficiente e aforra espazo de almacenamento. As consultas que obteñen valores de columna específicos non precisan ler todos os datos da fila, mellorando así o rendemento. Polo tanto, o grupo SQL sen servidor necesita menos tempo e menos solicitudes de almacenamento para ler os datos.
Por que usar Delta Lake?
- Escalabilidade: Delta Lake está construído sobre a licenza Apache de código aberto, que está deseñada para cumprir os estándares do sector para xestionar cargas de traballo de procesamento de datos a gran escala.
- Fiabilidade: Delta Lake ofrece transaccións ACID, o que garante a coherencia e fiabilidade dos datos mesmo ante fallos ou accesos simultáneos.
- Rendemento: Delta Lake aproveita o formato de almacenamento en columnas de Parquet, proporcionando mellores técnicas de compresión e codificación, o que pode mellorar o rendemento das consultas en comparación cos ficheiros CSV de consulta.
- Rentable: o formato de ficheiro Delta Lake é unha tecnoloxía de almacenamento de datos moi comprimida que ofrece un aforro potencial de almacenamento significativo para as empresas. Este formato está deseñado especificamente para optimizar o procesamento de datos e, potencialmente, reducir a cantidade total de datos procesados ou o tempo de execución necesario para a computación baixo demanda.
- Cumprimento da protección de datos: Delta Lake con Azure Synapse Link ofrece ferramentas e funcións, que inclúen a eliminación suave e a eliminación completa para cumprir varias normativas de privacidade de datos, incluíndo Regulamento xeral de protección de datos (RXPD).
Como funciona Delta Lake con Azure Synapse Link for Dataverse?
Ao configurar un Azure Synapse Link for Dataverse, podes activar a función exportar a Delta Lake e conectarse cun espazo de traballo de Synapse e un grupo Spark. Azure Synapse Link exporta as Dataverse táboas seleccionadas en formato CSV a intervalos de tempo designados, procesándoas mediante un traballo Spark de conversión de Delta Lake. Ao completar este proceso de conversión, os datos CSV limparanse para gardar o almacenamento. Ademais, unha serie de traballos de mantemento están programados para executarse a diario, realizando automaticamente procesos de compactación e aspiración para combinar e limpar ficheiros de datos para optimizar aínda máis o almacenamento e mellorar o rendemento das consultas.
Requisitos previos
- Dataverse: Debes ter o Dataverse administrador do sistema rol de seguranza. Ademais, as táboas que queres exportar mediante Azure Synapse Link deben ter activada a propiedade Rastrexar cambios . Máis información: Opcións avanzadas
- Azure Data Lake Storage Gen2: debe ter unha conta de Azure Data Lake Storage Gen2 e acceso de rol de Propietario e Colaborador de datos de Blob de almacenamento. A túa conta de almacenamento debe activar Espazo de nomes xerárquico e acceso á rede pública tanto para a configuración inicial como para a sincronización delta. Permitir o acceso á chave da conta de almacenamento só é necesario para a configuración inicial.
- Espazo de traballo de Synapse: debes ter un espazo de traballo de Synapse e Propietario papel no control de acceso (IAM) e Administrador de Synapse acceso ao rol dentro de Synapse Studio. O espazo de traballo de Synapse debe estar na mesma rexión que a súa conta de Azure Data Lake Storage Gen2. A conta de almacenamento debe engadirse como un servizo ligado dentro de Synapse Studio. Para crear un espazo de traballo de Synapse, vaia a Creación dun espazo de traballo de Synapse.
- Un Apache Spark grupo no Azure Synapse espazo de traballo conectado con Apache Spark versión 3.3 que utiliza esta configuración de Spark Pool recomendada. Para obter información sobre como crear un grupo Spark, vai a Crear un novo Apache Spark grupo.
- O Microsoft Dynamics requisito mínimo de versión 365 para usar esta función é 9.2.22082. Máis información: Activa as actualizacións de acceso anticipado
Configuración de Spark Pool recomendada
Esta configuración pódese considerar un arranque paso para casos de uso medios.
- Tamaño do nodo: pequeno (4 vCores / 32 GB)
- Escala automática: activada
- Número de nodos: 5 a 10
- Pausa automática: activada
- Número de minutos inactivos: 5
- Apache Spark: 3.3
- Asignación dinámica de executores: activado
- Número predeterminado de executores: 1 a 9
Importante
Use o grupo Spark exclusivamente para a operación de conversación de Delta Lake con Synapse Link para Dataverse. Para obter unha fiabilidade e un rendemento óptimos, evite executar outros traballos de Spark usando o mesmo grupo Spark.
Conéctate Dataverse ao espazo de traballo de Synapse e exporta os datos en formato Delta Lake
Inicie sesión Power Apps e seleccione o entorno que desexe.
No panel de navegación esquerdo, seleccione Azure Synapse Link. Se o elemento non está no panel lateral, seleccione …Máis e, a seguir, seleccione o elemento que desexe.
Na barra de comandos, selecciona + Nova ligazón
Seleccione Conectarse ao seu Azure Synapse Analytics espazo de traballo e, a continuación, seleccione Subscrición, Grupo de recursos e Nome do espazo de traballo.
Seleccione Usar grupo de Spark para procesar e, a continuación, seleccione o grupo de Spark precreado e Conta de almacenamento.
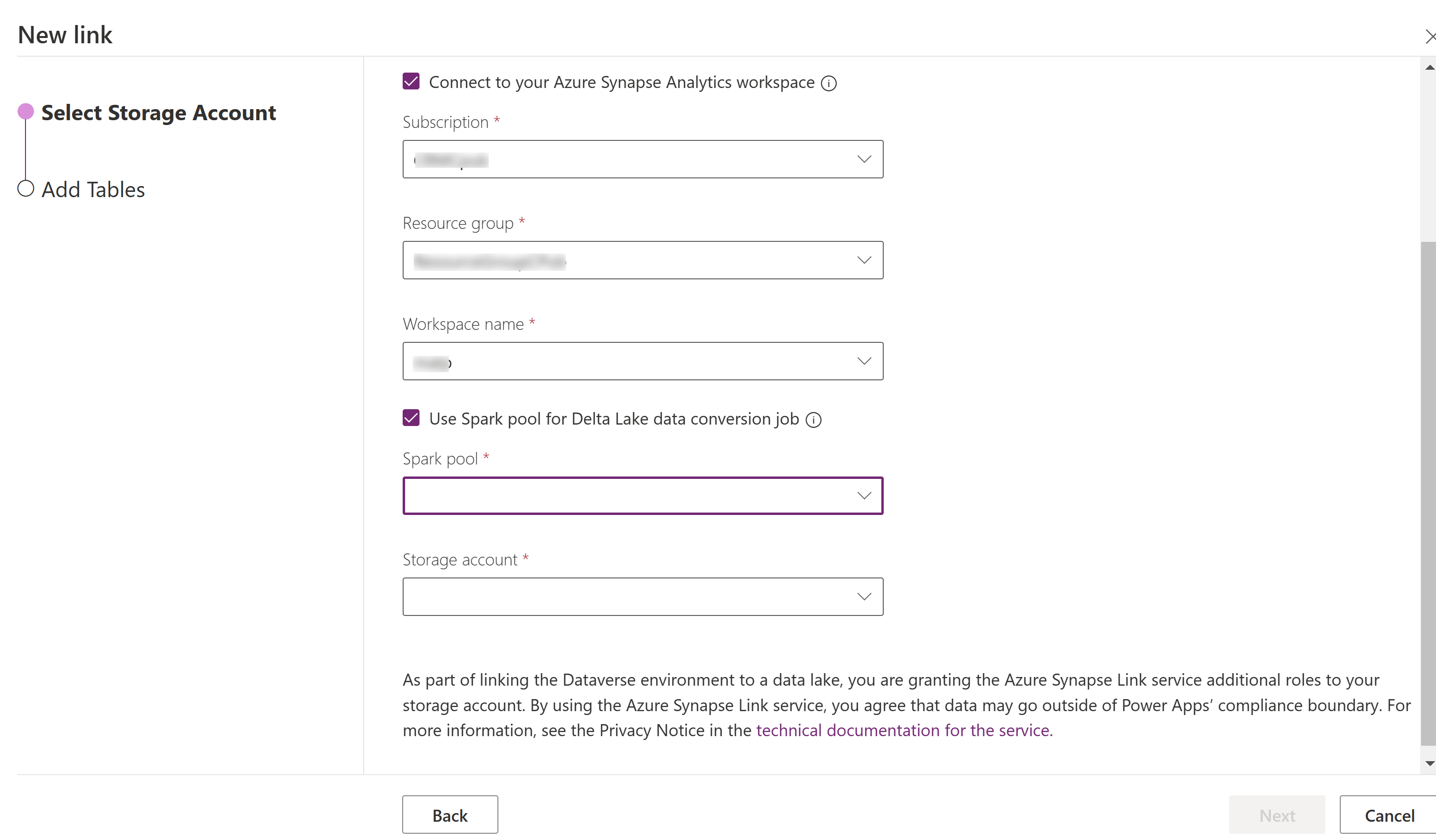
Seleccione Seguinte.
Engade as táboas que queres exportar e, a continuación, selecciona Avanzado.
Opcionalmente, selecciona Mostrar opcións de configuración avanzadas e introduce o intervalo de tempo, en minutos, para a frecuencia con que se deben capturar as actualizacións incrementais.
Seleccione Gardar.
Supervisa a túa Azure Synapse Link e a conversión de datos
- Seleccione o Azure Synapse Link que desexe e, a continuación, seleccione Ir a Azure Synapse Analytics espazo de traballo na barra de comandos.
- Seleccione Monitorizar > Apache Spark aplicacións. Máis información: Usa Synapse Studio para supervisar as túas Apache Spark aplicacións
Consulta os teus datos desde o espazo de traballo de Synapse
- Seleccione o Azure Synapse Link que desexe e, a continuación, seleccione Ir a Azure Synapse Analytics espazo de traballo na barra de comandos.
- Expanda Bases de datos do lago no panel esquerdo, seleccione dataverse-* environmentNameorganizationUniqueName* e a continuación, expanda Táboas. Todas as táboas de Parquet están listadas e dispoñibles para a súa análise coa convención de nomenclatura DataverseTableName. (Táboa non_particionada).
Nota
Non use táboas coa convención de nomenclatura _partitioned. Cando escolles o parquet Delta como formato, as táboas coa convención de nomenclatura _partition utilízanse como táboas de preparación e elimínanse despois de que o sistema as utilice.
Consulta os teus datos de Azure Data Lake Storage Gen2
- Seleccione o Azure Synapse Link que desexe e, a continuación, seleccione Ir a Azure data lake na barra de comandos.
- Seleccione os Contenedores en Almacenamento de datos.
- Seleccione *dataverse- *environmentName-organizationUniqueName. Todos os ficheiros de parquet almacénanse no cartafol deltalake .
Actualización no lugar a Apache Spark 3.3 con Delta Lake 2.2
Requisitos previos
- Debes ter un perfil Azure Synapse Link for Dataverse Delta Lake existente en execución cunha versión 3.1 de Synapse Spark.
- Debes crear un novo grupo de Synapse Spark coa versión 3.3 de Spark, utilizando a mesma configuración de hardware de nodos ou superior dentro do mesmo espazo de traballo de Synapse. Para obter información sobre como crear un grupo Spark, vai a Crear un novo Apache Spark grupo. Este grupo Spark debe crearse independentemente do grupo 3.1 actual.
Actualización local a Spark 3.3:
- Inicia sesión en Power Apps e selecciona o teu ambiente preferido.
- No panel de navegación esquerdo, seleccione Azure Synapse Link. Se o elemento non está no panel de navegación esquerdo, selecciona …Máis e, a continuación, selecciona o elemento que desexes.
- Abre o Azure Synapse Link perfil e, a continuación, selecciona Actualizar a Apache Spark 3.3 con Delta Lake 2.2.
- Seleccione o grupo de Spark dispoñible na lista e, a continuación, seleccione Actualizar.
Nota
A actualización do grupo Spark só se produce cando se activa un novo traballo Spark de conversión de Delta Lake. Asegúrate de ter polo menos un cambio de datos despois de seleccionar Actualizar.