Continuidade de negocio e recuperación de desastres
A plataforma de aplicacións empresariais (BAP) de Microsoft ofrece capacidades de continuidade empresarial e recuperación ante desastres (BCDR) a todos os entornos de tipo de produción en aplicacións de Dynamics 365 e Power Platform SAAS. Este artigo describe detalles e prácticas que fai Microsoft para garantir que os seus datos de produción sexan resistentes durante a interrupción rexional.
Copia de seguridade e replicación de contornos de produción
Microsoft dedícase a garantir os máis altos niveis de disponibilidade do servizo para as túas aplicacións e datos críticos. Microsoft garante que a infraestrutura de referencia e os servizos da plataforma estean dispoñibles a través da súa arquitectura de continuidade empresarial e recuperación de desastres por:
Activando a redundancia xeográfica, onde se fai unha copia de seguranza de todos os datos dos contornos de produción (excluídos os contornos predeterminados) na rexión asociada/secundaria. Estas réplicas denomínanse réplicas xeo-secundarias que se configuran durante o tempo en que se implanta o ambiente principal.
As réplicas xeosecundarias mantéñense sincronizadas co contorno primario a través da replicación continua de datos. Aínda que en calquera momento, unha rexión secundaria pode estar lixeiramente por detrás da rexión principal, os datos dun secundario están garantidos para ser coherentes transaccionalmente. Para obter máis información sobre a replicación xeográfica, visite Replicación xeográfica activa - Azure SQL Database
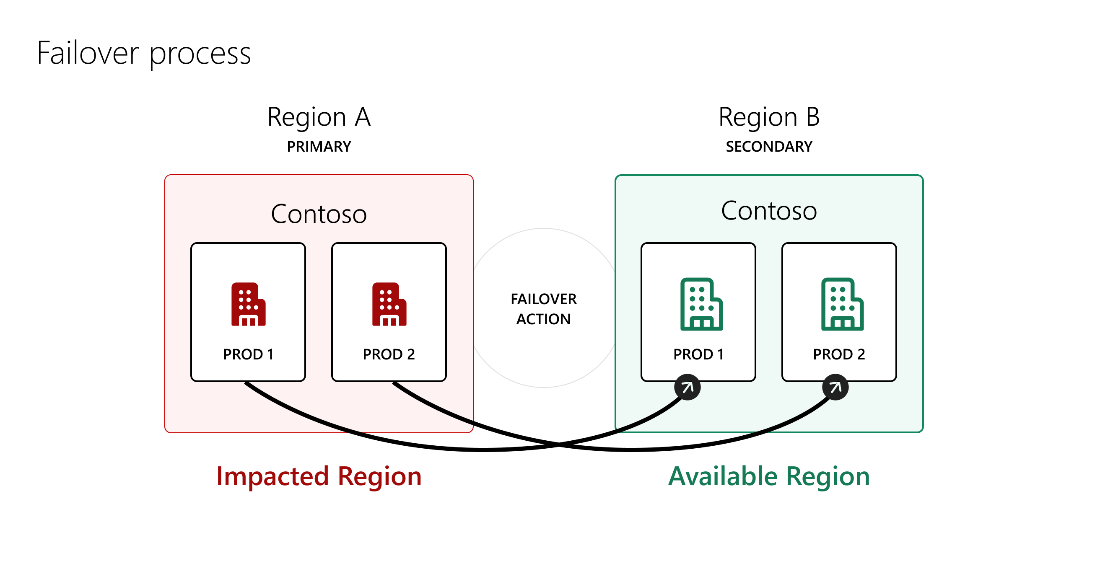
A ilustración anterior mostra que cando a Rexión A primaria se ve afectada durante unha interrupción, os ambientes de tipo de produción van desde a Rexión A a conmutación por erro á Rexión B secundaria, que é saudable. Non se realiza ningunha acción noutro tipo de entornos como o predeterminado, de proba, de proba, de proba, de equipos ou de programador.
Para obter máis información sobre a protección de datos en ambientes que non son de produción, consulta Fai unha copia de seguranza e restauración de ambientes.
Como se lle notificará unha interrupción?
A canle de comunicación principal é a través do Panel de control de saúde do servizo (SHD) dentro dos centros de administración da plataforma de Microsoft e Power. O equipo de comunicacións de Microsoft iniciará o proceso publicando comunicacións iniciais para notificarlle a interrupción e publicar as actualizacións necesarias no SHD segundo sexa necesario. Para obter máis información sobre como ver as túas mensaxes no centro de administración, consulta Panel de control da páxina de inicio. Para estar mellor preparado, visita a páxina de preparación.
Procesos de failover e failback e criterios para a continuidade do negocio
Failover e failback son as dúas tarefas principais que se realizan durante o proceso de continuidade do negocio e recuperación ante desastres (BCDR). O obxectivo é minimizar o impacto dun desastre na dispoñibilidade e o rendemento das funcións e aplicacións empresariais críticas.
Failover é o proceso de cambiar a unha réplica xeo-secundaria designada de todos os sistemas e datos do teu sitio de produción principal. Ao completar a operación de conmutación por fallo, o seu ambiente de produción será accesible desde o sitio xeo-secundario.
Importante
Aínda que as aplicacións de Finanzas e Operacións funcionan na rexión secundaria despois dun mantemento por falla, as implementacións de paquetes, os informes financeiros e os Power BI informes non están dispoñibles.
A operación de retroceso é o proceso de devolver a produción á súa localización orixinal despois dun desastre ou dun período de mantemento programado.
Como parte do estándar de continuidade comercial e recuperación ante desastres (BCDR) de Microsoft, os clientes poden asegurarse de que cada servizo en liña de Microsoft revisa, proba e actualiza o seu plan BCDR anualmente. O informe de validación do plan de continuidade empresarial e recuperación ante desastres de Microsoft Cloud está dispoñible para os clientes do Portal de confianza do servizo.
No caso de producirse unha interrupción imprevista en toda a rexión, como un desastre natural que afecte a toda a rexión de Azure, a continuación móstranse a secuencia de pasos e procesos que terán lugar.
| Responsabilidade de Microsoft | Responsabilidades dos clientes |
|---|---|
| Se Microsoft detecta unha interrupción e ve que os clientes se ven afectados, entón o equipo de comunicación de Microsoft enviará as comunicacións necesarias e manterá o Panel de control de saúde do servizo actualizado coa información necesaria. | Nada |
| Se se produce unha interrupción, Microsoft realizará unha conmutación automática por fallo das instancias de produción na rexión secundaria se NON hai PERDA DE DATOS para o cliente. | Nada |
| Se no caso dunha interrupción, Microsoft determina que hai PERDA DE DATOS, a falla no ambiente non se inicia sen o consentimento/aprobación do cliente. | Unha vez que o cliente é consciente da interrupción en curso e ve o IMPACTO, é responsabilidade do cliente: - Para contactar con Microsoft a través do servizo de asistencia e coñecer o nivel de perda de datos que se produciría se se iniciase unha conmutación por fallo. - Se a perda de datos está nun nivel aceptable para os estándares da súa organización, os clientes deben proporcionar o seu consentimento a través de soporte para que Microsoft inicie unha conmutación por falla. |
| Cando Microsoft determina que a rexión principal volve estar en liña e está totalmente operativa, realízase unha FAILBACK nas instancias de produción. Non hai perda de datos durante o proceso de recuperación por falla planificada, pero os usuarios poden sufrir interrupcións ou desconexións breves durante esta xanela. | Nada |