Failover groups overview & best practices (Azure SQL Database)
Applies to: ![]() Azure SQL Database
Azure SQL Database
The failover groups feature allows you to manage the replication and failover of some or all databases on a logical server to a logical server in another region. This article provides an overview of the failover group feature with best practices and recommendations for using it with Azure SQL Database.
To get started using the feature, review Configure failover group.
Note
This article covers failover groups for Azure SQL Database. For Azure SQL Managed Instance, see Failover groups in Azure SQL Managed Instance.
To learn more about Azure SQL Database disaster recovery, watch this video:
Overview
The failover groups feature allows you to manage the replication and failover of databases to another Azure region. You can choose all, or a subset of, user databases in a logical server to be replicated to another logical server. It's a declarative abstraction on top of the active geo-replication feature, designed to simplify deployment and management of geo-replicated databases at scale.
For geo-failover RPO and RTO, see overview of business continuity.
Endpoint redirection
Failover groups provide read-write and read-only listener end-points that remain unchanged during geo-failovers. You don't have to change the connection string for your application after a geo-failover, because connections are automatically routed to the current primary. A geo-failover switches all secondary databases in the group to the primary role. After geo-failover completes, the DNS record is automatically updated to redirect the endpoints to the new region.
Offload read-only workloads
To reduce traffic to your primary databases, you can also use the secondary databases in a failover group to offload read-only workloads. Use the read-only listener to direct read-only traffic to a readable secondary database.
Recovering an application
To achieve full business continuity, adding regional database redundancy is only part of the solution. Recovering an application (service) end-to-end after a catastrophic failure requires recovery of all components that constitute the service and any dependent services. Examples of these components include the client software (for example, a browser with a custom JavaScript), web front ends, storage, and DNS. It's critical that all components are resilient to the same failures and become available within the recovery time objective (RTO) of your application. Therefore, you need to identify all dependent services and understand the guarantees and capabilities they provide. Then, you must take adequate steps to ensure that your service functions during the failover of the services on which it depends.
Failover policy
Failover groups support two failover policies:
- Customer managed (recommended) - Customers can perform a failover of a group when they notice an unexpected outage impacting one or more databases in the failover group. When using command line tools such as PowerShell, the Azure CLI, or the Rest API, the failover policy value for customer managed is
manual. - Microsoft managed - In the event of a widespread outage that impacts a primary region, Microsoft initiates failover of all impacted failover groups that have their failover policy configured to be Microsoft-managed. Microsoft managed failover won't be initiated for individual failover groups or a subset of failover groups in a region. When using command line tools such as PowerShell, the Azure CLI, or the Rest API, the failover policy value for Microsoft-managed is
automatic.
Each failover policy has a unique set of use cases and corresponding expectations on the failover scope and data loss, as the following table summarizes:
| Failover policy | Failover scope | Use case | Potential data loss |
|---|---|---|---|
| Customer managed (Recommended) |
Failover group(s) | One or more databases in a failover group(s) is impacted by an outage and become unavailable. You can choose to fail over. | Yes |
| Microsoft managed | All failover groups in the region | A widespread outage in a datacenter, availability zone, or region causes unavailability of databases and the Microsoft Azure SQL service team decides to trigger a forced failover. Use this option only when you want to delegate the disaster recovery responsibility to Microsoft and the application is tolerant to RTO (downtime) of at least one hour or more. |
Yes |
Customer managed
On rare occasions, the built-in availability or high availability isn't enough to mitigate an outage, and your databases in a failover group might be unavailable for a duration that isn't acceptable to the service level agreement (SLA) of the applications using the databases. Databases can be unavailable due to a localized issue impacting just a few databases, or it could be at the datacenter, availability zone, or region level. In any of these cases, to restore business continuity, you can initiate a forced failover.
Setting your failover policy to customer managed is highly recommended, as it keeps you in control of when to initiate a failover and restore business continuity. You can initiate a failover when you notice an unexpected outage impacting one or more databases in the failover group.
Microsoft managed
With a Microsoft managed failover policy, disaster recovery responsibility is delegated to the Azure SQL service. For the Azure SQL service to initiate a forced failover, the following conditions must be met:
- Datacenter, availability zone, or region level outage caused by a natural disaster event, configuration changes, software bugs or hardware component failures and many databases in the region are impacted.
- Grace period is expired. Because verifying the scale of, and mitigating, the outage depends on human actions, the grace period can't be set below one hour.
When these conditions are met, the Azure SQL service initiates forced failovers for all failover groups in the region that have the failover policy set to Microsoft managed.
Important
Use customer managed failover policy to test and implement your disaster recovery plan. Do not rely on Microsoft managed failover, which might only be executed by Microsoft in extreme circumstances. A Microsoft managed failover would be initiated for all failover groups in the region that have failover policy set to Microsoft managed. It can't be initiated for individual failover group. If you need the ability to selectively failover your failover group, use customer managed failover policy.
Set the failover policy to Microsoft managed only when:
- You want to delegate disaster recovery responsibility to the Azure SQL service.
- The application is tolerant to your database being unavailable for at least one hour or more.
- It's acceptable to trigger forced failovers some time after the grace period expires as the actual time for the forced failover can vary significantly.
- It's acceptable that all databases within the failover group fail over, regardless of their zone redundancy configuration or availability status. Although databases configured for zone redundancy are resilient to zonal failures and might not be impacted by an outage, they'll still be failed over if they're part of a failover group with a Microsoft managed failover policy.
- It's acceptable to have forced failovers of databases in the failover group without taking into consideration the application's dependency on other Azure services or components used by the application, which can cause performance degradation or unavailability of the application.
- It's acceptable to incur an unknown amount of data loss, as the exact time of forced failover can't be controlled, and ignores the synchronization status of the secondary databases.
- All the primary and secondary database(s) in the failover group and any geo replication relationships have the same service tier, compute tier (provisioned or serverless) & compute size (DTUs or vCores). If the service level objective (SLO) of all the databases don't match, then the failover policy will be eventually updated from Microsoft Managed to Customer Managed by Azure SQL service.
When a failover is triggered by Microsoft, an entry for the operation name Failover Azure SQL failover group is added to the Azure Monitor activity log. The entry includes the name of the failover group under Resource, and Event initiated by displays a single hyphen (-) to indicate the failover was initiated by Microsoft. This information can also be found on the Activity log page of the new primary server or instance in the Azure portal.
Terminology and capabilities
Failover group (FOG)
A failover group is a named group of databases managed by a single logical server in Azure that can fail over as a unit to another Azure region in case all or some primary databases become unavailable due to an outage in the primary region.
Important
The name of the failover group must be globally unique within the
.database.windows.netdomain.Servers
Some or all of the user databases on a logical server can be placed in a failover group. Also, a server supports multiple failover groups on a single server.
Primary
The logical server that hosts the primary databases in the failover group.
Secondary
The logical server that hosts the secondary databases in the failover group. The secondary can't be in the same Azure region as the primary.
Failover (no data loss)
Failover performs full data synchronization between primary and secondary databases before the secondary switches to the primary role. This guarantees no data loss. Failover is only possible when the primary is accessible. Failover is used in the following scenarios:
- Perform disaster recovery (DR) drills in production when data loss isn't acceptable
- Relocate the workload to a different region
- Return the workload to the primary region after the outage has been mitigated (failback)
Forced failover (potential data loss)
Forced failover immediately switches the secondary to the primary role without waiting for recent changes to propagate from the primary. This operation can result in potential data loss. Forced failover is used as a recovery method during outages when the primary isn't accessible. When the outage is mitigated, the old primary will automatically reconnect and become a new secondary. A failover can be executed to fail back, returning the replicas to their original primary and secondary roles.
Grace period with data loss
Because data is replicated to the secondary using asynchronous replication, forced failover of groups with Microsoft managed failover policies can result in data loss. You can customize the failover policy to reflect your application's tolerance to data loss. By configuring
GracePeriodWithDataLossHours, you can control how long the Azure SQL service waits before initiating a forced failover, which can result in data loss.
Adding single databases to failover group
You can put several single databases on the same logical server into the same failover group. If you add a single database to the failover group, it automatically creates a secondary database using the same edition and compute size on secondary server you specified when the failover group was created. If you add a database that already has a secondary database in the secondary server, that geo-replication link is inherited by the group. When you add a database that already has a secondary database in a server that isn't part of the failover group, a new secondary database is created on the secondary server.
Important
- Make sure the secondary logical server doesn't have a database with the same name unless it is an existing secondary database.
- If a database contains in-memory OLTP objects, the primary database and the secondary geo-replica database must have matching service tiers, as in-memory OLTP objects reside in memory. A lower service tier on the geo-replica database might result in out-of-memory issues. If this occurs, the geo-replica might fail to recover the database, causing unavailability of the secondary database along with in-memory OLTP objects on the geo-secondary. This, in turn, can cause failovers to be unsuccessful as well. To avoid this, ensure that the service tier of the geo-secondary database matches that of the primary database. Service tier upgrades can be size-of-data operations and might take a while to finish.
Adding databases in elastic pool to failover group
You can put all or several databases within an elastic pool into the same failover group. If the primary database is in an elastic pool, the secondary is automatically created in the elastic pool with the same name (secondary pool). You must ensure that the secondary server contains an elastic pool with the same exact name and enough free capacity to host the secondary databases that will be created by the failover group. If you add a database in the pool that already has a secondary database in the secondary pool, that geo-replication link is inherited by the group. When you add a database that already has a secondary database in a server that isn't part of the failover group, a new secondary database is created in the secondary pool.
Failover group read-write listener
A DNS CNAME record that points to the current primary. It's created automatically when the failover group is created and allows the read-write workload to transparently reconnect to the primary when the primary changes after failover. When the failover group is created on a server, the DNS CNAME record for the listener URL is formed as
<fog-name>.database.windows.net. After failover, the DNS record is automatically updated to redirect the listener to the new primary.Failover group read-only listener
A DNS CNAME record that points to the current secondary. It's created automatically when the failover group is created and allows the read-only SQL workload to transparently connect to the secondary when the secondary changes after failover. When the failover group is created on a server, the DNS CNAME record for the listener URL is formed as
<fog-name>.secondary.database.windows.net. By default, failover of the read-only listener is disabled as it ensures the performance of the primary isn't affected when the secondary is offline. However, it also means the read-only sessions won't be able to connect until the secondary is recovered. If you can't tolerate downtime for the read-only sessions and can use the primary for both read-only and read-write traffic at the expense of the potential performance degradation of the primary, you can enable failover for the read-only listener by configuring theAllowReadOnlyFailoverToPrimaryproperty. In that case, the read-only traffic is automatically redirected to the primary if the secondary isn't available.Note
The
AllowReadOnlyFailoverToPrimaryproperty only has effect if Microsoft managed failover policy is enabled and a forced failover has been triggered. In that case, if the property is set to True, the new primary will serve both read-write and read-only sessions.Multiple failover groups
You can configure multiple failover groups for the same pair of servers to control the scope of geo-failovers. Each group fails over independently. If your tenant-per-database application is deployed in multiple regions and uses elastic pools, you can use this capability to mix primary and secondary databases in each pool. This way you might be able to reduce the impact of an outage to only some tenant databases.
Failover group architecture
A failover group in Azure SQL Database can include one or multiple databases, typically used by the same application. A failover group must be configured on the primary server, which connects it to the secondary server in a different Azure region. The failover group can include all or some databases in the primary server. The following diagram illustrates a typical configuration of a geo-redundant cloud application using multiple databases in a failover group:
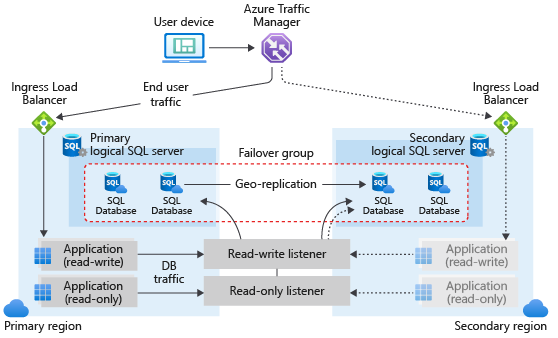
When designing a service with business continuity in mind, follow the general guidelines and best practices outlined in this article. When configuring a failover group, ensure that authentication and network access on the secondary is set up to function correctly after geo-failover, when the geo-secondary becomes the new primary. For details, see SQL Database security after disaster recovery. For more information, see Designing cloud solutions for disaster recovery.
Use paired regions
When creating your failover group between the primary and secondary server, use paired regions as failover groups in paired regions have better performance compared to unpaired regions.
Following safe deployment practices, Azure SQL Database generally doesn't update paired regions at the same time. However, it isn't possible to predict which region will be upgraded first, so the order of deployment isn't guaranteed. Sometimes, your primary server is upgraded first, and sometimes it's upgraded second.
If you have geo-replication or failover groups configured for databases that don't align with the Azure region pairing, use different maintenance window schedules for your primary and secondary databases. For example, you can select Weekday maintenance window for your secondary database and Weekend maintenance window for your primary database.
Initial seeding
When adding databases or elastic pools to a failover group, there's an initial seeding phase before data replication starts. The initial seeding phase is the longest and most expensive operation. Once initial seeding completes, data is synchronized, and then only subsequent data changes are replicated. The time it takes for the initial seeding to complete depends on the size of your data, number of replicated databases, the load on the primary databases, and the speed of the network link between the primary and secondary database. Under normal circumstances, possible seeding speed is up to 500 GB an hour for SQL Database. Seeding is performed for all databases in parallel.
Number of databases in failover group
The number of databases within a failover group directly impacts the duration of both Failover and Forced Failover operations.
- During a Failover (also known as Planned Failover), we ensure that all primary databases are fully synchronized with their secondary and reach a ready state. To avoid overwhelming the control plane, databases are prepared in batches. Therefore, it is highly recommended to limit the number of databases in a failover group.
- In the case of a Forced Failover, the preparation phase is expedited as data synchronization is not initiated. To achieve quicker and predictable failover durations, it might be beneficial to keep the number of databases in the failover group to a smaller number.
Use multiple failover groups to fail over multiple databases
One or many failover groups can be created between two servers in different regions (primary and secondary servers). Each group can include one or several databases that are recovered as a unit in case all or some primary databases become unavailable due to an outage in the primary region. Creating a failover group creates geo-secondary databases with the same service objective as the primary. If you add an existing geo-replication relationship to a failover group, make sure the geo-secondary is configured with the same service tier and compute size as the primary.
Use the read-write listener (primary)
For read-write workloads, use <fog-name>.database.windows.net as the server name in the connection string. Connections are automatically directed to the primary. This name doesn't change after failover. Note the failover involves updating the DNS record so the client connections are redirected to the new primary only after the client DNS cache is refreshed. The time to live (TTL) of the primary and secondary listener DNS record is 30 seconds.
Use the read-only listener (secondary)
If you have logically isolated read-only workloads that are tolerant to data latency, you can run them on the geo-secondary. For read-only sessions, use <fog-name>.secondary.database.windows.net as the server name in the connection string. Connections are automatically directed to the geo-secondary. It's also recommended that you indicate read intent in the connection string by using ApplicationIntent=ReadOnly.
In the Premium, Business Critical, and Hyperscale service tiers, SQL Database supports the use of read-only replicas to offload read-only query workloads, using the ApplicationIntent=ReadOnly parameter in the connection string. When you have configured a geo-secondary, you can use this capability to connect to either a read-only replica in the primary location or in the geo-secondary location:
To connect to a read-only replica in the secondary location, use ApplicationIntent=ReadOnly and <fog-name>.secondary.database.windows.net.
Potential performance degradation after failover
A typical Azure application uses multiple Azure services and consists of multiple components. Failover of a group is triggered based on the state of Azure SQL Database alone. Other Azure services in the primary region might not be affected by the outage and their components might still be available in that region. Once the primary databases switch to the secondary (DR) region, latency between dependent components can increase. To avoid the impact of higher latency on the application's performance, ensure the redundancy of all the application's components in the DR region, follow these network security guidelines, and orchestrate the geo-failover of relevant application components together with the database.
Potential data loss after forced failover
If an outage occurs in the primary region, recent transactions might not have been replicated to the geo-secondary and there might be data loss if a forced failover is performed.
Important
Elastic pools with 800 or fewer DTUs or 8 or fewer vCores, and more than 250 databases can encounter issues including longer planned geo-failovers and degraded performance. These issues are more likely to occur for write intensive workloads when geo-replicas are widely separated by geography, or when multiple secondary geo-replicas are used for each database. A symptom of these issues is an increase in geo-replication lag over time, potentially leading to a more extensive data loss in an outage. This lag can be monitored using sys.dm_geo_replication_link_status. If these issues occur, then mitigation includes scaling up the pool to have more DTUs or vCores, or reducing the number of geo-replicated databases in the pool.
Failback
When failover groups are configured with a Microsoft-managed failover policy, then forced failover to the geo-secondary server is initiated during a disaster scenario as per the defined grace period. Failback to the old primary must be initiated manually.
Permissions and limitations
Review the configure failover group guide for a list of permissions and limitations.
Programmatically manage failover groups
Failover groups can also be managed programmatically using Azure PowerShell, Azure CLI, and REST API. For more information, review Configure failover group.
Related content
- For sample scripts, see:
- For a business continuity overview and scenarios, see Business continuity overview
- To learn about Azure SQL Database automated backups, see SQL Database automated backups.
- To learn about using automated backups for recovery, see Restore a database from the service-initiated backups.
- To learn about authentication requirements for a new primary server and database, see SQL Database security after disaster recovery.