ग्राहक जीवनकाल मान (CLV) का पूर्वानुमान करें
संभावित मान (राजस्व) का पूर्वानुमान करें जिसे व्यक्तिगत सक्रिय ग्राहक आपके व्यवसाय में परिभाषित भविष्य की समयावधि में लाएंगे. यह पूर्वानुमान आपकी मदद करता है:
- उच्च-मूल्य वाले ग्राहकों की पहचान करें और इस अंतर्दृष्टि को संसाधित करें।
- लक्षित बिक्री, विपणन और समर्थन प्रयासों के साथ व्यक्तिगत अभियान चलाने के लिए उनके संभावित मूल्य के आधार पर रणनीतिक ग्राहक खंड बनाएं।
- ग्राहक मूल्य बढ़ाने वाली विशेषताओं पर ध्यान केंद्रित करके उत्पाद विकास का मार्गदर्शन करें।
- बिक्री या विपणन रणनीति को अनुकूलित करें और ग्राहक पहुंच के लिए बजट को अधिक सटीक रूप से आवंटित करें।
- वफादारी या पुरस्कार कार्यक्रमों के माध्यम से उच्च मूल्य वाले ग्राहकों को पहचानें और पुरस्कृत करें।
निर्धारित करें कि आपके व्यवसाय के लिए CLV का क्या अर्थ है। हम लेनदेन-आधारित CLV पूर्वानुमान का समर्थन करते हैं। किसी ग्राहक का अनुमानित मूल्य व्यावसायिक लेनदेन के इतिहास पर आधारित होता है। अलग-अलग इनपुट प्राथमिकताओं के साथ कई मॉडल बनाने पर विचार करें और मॉडल परिणामों की तुलना करके देखें कि कौन सा मॉडल परिदृश्य आपकी व्यावसायिक आवश्यकताओं के लिए सबसे उपयुक्त है।
टिप
नमूना डेटा का उपयोग करके CLV पूर्वानुमान आज़माएँ: ग्राहक आजीवन मूल्य (CLV) पूर्वानुमान नमूना मार्गदर्शिका।
पूर्वावश्यकताएँ
- कम से कम सहयोगी अनुमति
- वांछित पूर्वानुमान विंडो के भीतर कम से कम 1,000 ग्राहक प्रोफाइल
- ग्राहक पहचानकर्ता, एक व्यक्तिगत ग्राहक के लिए लेन-देन से मेल खाने के लिए एक विशिष्ट पहचानकर्ता
- कम से कम एक वर्ष का लेन-देन इतिहास, अधिमानतः दो से तीन वर्ष का। आदर्श रूप से, प्रति ग्राहक आईडी कम से कम दो से तीन लेन-देन, हो सके तो कई तिथियों में। लेन-देन इतिहास में निम्नलिखित शामिल होना चाहिए:
- लेनदेन आईडी: प्रत्येक लेनदेन का विशिष्ट पहचानकर्ता
- लेन-देन की तिथि: प्रत्येक लेन-देन की तिथि या समय मोहर
- लेन-देन राशि: प्रत्येक लेन-देन का मौद्रिक मूल्य (उदाहरण के लिए, राजस्व या लाभ मार्जिन)
- रिटर्न को निर्दिष्ट लेबल: बूलियन सत्य/असत्य मान यह दर्शाता है कि क्या लेनदेन रिटर्न है
- उत्पाद आईडी: लेन-देन में शामिल उत्पाद की उत्पाद आईडी
- ग्राहक गतिविधियों के बारे में डेटा:
- प्राथमिक कुंजी: किसी गतिविधि के लिए अद्वितीय पहचानकर्ता
- टाइमस्टैम्प: प्राथमिक कुंजी द्वारा पहचानी गई घटना की तिथि और समय
- इवेंट (गतिविधि का नाम): इवेंट का नाम जिसे आप उपयोग करना चाहते हैं
- विवरण (राशि या मूल्य): ग्राहक गतिविधि के बारे में विवरण
- अतिरिक्त डेटा जैसे:
- वेब गतिविधियाँ: वेबसाइट विज़िट इतिहास या ईमेल इतिहास
- वफादारी गतिविधियाँ: वफादारी पुरस्कार अंक अर्जित करना और मोचन इतिहास
- ग्राहक सेवा लॉग: सेवा कॉल, शिकायत या वापसी इतिहास
- ग्राहक प्रोफ़ाइल जानकारी
- आवश्यक फ़ील्ड में 20% से कम अनुपलब्ध मान
नोट
केवल एक लेनदेन इतिहास तालिका कॉन्फ़िगर की जा सकती है. यदि एक से अधिक खरीद या लेनदेन तालिकाएं हैं, तो डेटा अंतर्ग्रहण से पहले उन्हें संयोजित करें. Power Query
ग्राहक जीवनकाल मूल्य पूर्वानुमान बनाएं
पूर्वानुमान को ड्राफ्ट के रूप में सहेजने के लिए किसी भी समय ड्राफ्ट सहेजें का चयन करें। ड्राफ्ट पूर्वानुमान मेरी भविष्यवाणियां टैब में प्रदर्शित होता है।
अंतर्दृष्टि>भविष्यवाणियां पर जाएं.
बनाएँ टैब पर, मॉडल का उपयोग करें ग्राहक जीवनकाल मान टाइल पर चयन करें.
आरंभ करें चुनें.
इस मॉडल को और आउटपुट तालिका का नाम दें ताकि उन्हें अन्य मॉडलों या तालिकाओं से अलग किया जा सके।
अगला चुनें.
मॉडल वरीयताओं को परिभाषित करें
यह निर्धारित करने के लिए कि आप भविष्य में कितनी दूर तक CLV का पूर्वानुमान लगाना चाहते हैं, एक पूर्वानुमान समय अवधि निर्धारित करें। डिफ़ॉल्ट रूप से, इकाई को महीनों के अनुसार सेट किया जाता है.
टिप
निर्धारित समयावधि के लिए CLV का सटीक अनुमान लगाने के लिए तुलनात्मक अवधि के ऐतिहासिक आंकड़ों की आवश्यकता होती है। उदाहरण के लिए, यदि आप अगले 12 महीनों के लिए CLV का पूर्वानुमान लगाना चाहते हैं, तो कम से कम 18-24 महीनों का ऐतिहासिक डेटा रखें।
उस समय सीमा को सेट करें जिसमें ग्राहक को सक्रिय रहने के लिए कम से कम एक लेन-देन करना चाहिए. मॉडल केवल सक्रिय ग्राहकों के लिए CLV की भविष्यवाणी करता है।
- मॉडल को खरीद अंतराल की गणना करने दें (अनुशंसित): मॉडल आपके डेटा का विश्लेषण करता है और ऐतिहासिक खरीद के आधार पर समय अवधि निर्धारित करता है।
- अंतराल को मैन्युअल रूप से सेट करें: सक्रिय ग्राहक की आपकी परिभाषा के लिए समय अवधि.
उच्च-मूल्य वाले ग्राहक का प्रतिशत परिभाषित करें।
- मॉडल गणना (अनुशंसित): मॉडल 80/20 नियम का उपयोग करता है। ऐतिहासिक अवधि में आपके व्यवसाय के लिए 80% संचयी राजस्व में योगदान देने वाले ग्राहकों के प्रतिशत को उच्च मूल्य वाले ग्राहक माना जाता है. आमतौर पर, 30-40% से कम ग्राहक 80% संचयी राजस्व में योगदान करते हैं. हालांकि, यह संख्या आपके व्यवसाय और उद्योग के आधार पर भिन्न हो सकती है.
- शीर्ष सक्रिय ग्राहकों का प्रतिशत: उच्च-मूल्य वाले ग्राहक के लिए विशिष्ट प्रतिशत। उदाहरण के लिए, उच्च-मूल्य वाले ग्राहकों को भविष्य में भुगतान करने वाले शीर्ष 25% ग्राहकों के रूप में परिभाषित करने के लिए 25 दर्ज करें।
यदि आपका व्यवसाय उच्च मूल्य वाले ग्राहकों को किसी भिन्न तरीके से परिभाषित करता है, तो हमें बताएं, क्योंकि हमें सुनना अच्छा लगेगा। ...
अगला चुनें.
आवश्यक डेटा जोड़ें
ग्राहक लेनदेन इतिहास के लिए डेटा जोड़ें चुनें।
वह सिमेंटिक गतिविधि प्रकार, SalesOrder या SalesOrderLine चुनें, जिसमें लेनदेन इतिहास शामिल हो. यदि गतिविधि सेट नहीं की गई है, तो यहां चुनें और इसे बनाएं।
गतिविधियाँ के अंतर्गत, यदि गतिविधि बनाते समय गतिविधि विशेषताएँ शब्दार्थ रूप से मैप की गई थीं, तो वह विशिष्ट विशेषता या तालिका चुनें, जिस पर आप गणना को केंद्रित करना चाहते हैं। यदि सिमेंटिक मैपिंग नहीं हुई, तो संपादित करें का चयन करें और अपने डेटा को मैप करें।
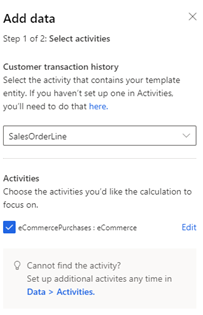
अगला चुनें और इस मॉडल के लिए आवश्यक विशेषताओं की समीक्षा करें.
सहेजें चुनें.
अधिक गतिविधियाँ जोड़ें या अगला चुनें .
वैकल्पिक गतिविधि डेटा जोड़ें
मुख्य ग्राहक इंटरैक्शन (जैसे वेब, ग्राहक सेवा और इवेंट लॉग) को दर्शाने वाला डेटा लेन-देन रिकॉर्ड के संदर्भ को जोड़ता है. आपकी ग्राहक गतिविधि डेटा में पाए जाने वाले अधिक पैटर्न पूर्वानुमानों की सटीकता में सुधार कर सकते हैं.
डेटा जोड़ें के अंतर्गत अतिरिक्त गतिविधि डेटा के साथ मॉडल अंतर्दृष्टि बढ़ाएँ का चयन करें.
एक गतिविधि प्रकार चुनें, जो आपके द्वारा जोड़े जा रहे ग्राहक गतिविधि के प्रकार से मेल खाता हो. यदि गतिविधि सेट नहीं की गई है, तो यहां चुनें और इसे बनाएं।
गतिविधियाँ के अंतर्गत, यदि गतिविधि बनाते समय गतिविधि विशेषताएँ मैप की गई थीं, तो वह विशिष्ट विशेषता या तालिका चुनें, जिस पर आप गणना को केंद्रित करना चाहते हैं। यदि मैपिंग नहीं हुई, तो संपादित करें चुनें और अपने डेटा को मैप करें।
अगला चुनें और इस मॉडल के लिए आवश्यक विशेषताओं की समीक्षा करें.
सहेजें चुनें.
अगला चुनें.
वैकल्पिक ग्राहक डेटा जोड़ें या अगला चुनें और अद्यतन शेड्यूल सेट करें पर जाएं.
वैकल्पिक ग्राहक डेटा जोड़ें
मॉडल में इनपुट के रूप में शामिल करने के लिए 18 सामान्यतः प्रयुक्त ग्राहक प्रोफ़ाइल विशेषताओं में से चयन करें। ये विशेषताएं आपके व्यावसायिक उपयोग मामलों के लिए अधिक वैयक्तिकृत, प्रासंगिक और कार्रवाई योग्य मॉडल परिणाम प्रदान कर सकती हैं।
उदाहरण के लिए: कॉन्टोसो कॉफी अपने नए एस्प्रेसो मशीन के लॉन्च से संबंधित व्यक्तिगत प्रस्ताव के साथ उच्च मूल्य वाले ग्राहकों को लक्षित करने के लिए ग्राहक आजीवन मूल्य की भविष्यवाणी करना चाहता है। कॉन्टोसो CLV मॉडल का उपयोग करता है और सभी 18 ग्राहक प्रोफ़ाइल विशेषताओं को जोड़ता है ताकि यह देखा जा सके कि कौन से कारक उनके उच्चतम मूल्य वाले ग्राहकों को प्रभावित करते हैं। उन्होंने पाया कि इन ग्राहकों के लिए ग्राहक का स्थान सबसे प्रभावशाली कारक है। इस जानकारी के साथ, वे एस्प्रेसो मशीन के लॉन्च के लिए एक स्थानीय कार्यक्रम आयोजित करते हैं और कार्यक्रम में व्यक्तिगत ऑफर और विशेष अनुभव के लिए स्थानीय विक्रेताओं के साथ साझेदारी करते हैं। इस जानकारी के बिना, कॉन्टोसो ने केवल सामान्य विपणन ईमेल भेजे होंगे और अपने उच्च मूल्य वाले ग्राहकों के इस स्थानीय खंड के लिए निजीकरण का अवसर खो दिया होगा।
डेटा जोड़ें के अंतर्गत अतिरिक्त ग्राहक डेटा के साथ मॉडल अंतर्दृष्टि को और भी अधिक बढ़ाएँ चुनें।
तालिका के लिए, ग्राहक विशेषता डेटा से मैप करने वाली एकीकृत ग्राहक प्रोफ़ाइल का चयन करने के लिए ग्राहक: CustomerInsights चुनें. ग्राहक आईडी के लिए, System.Customer.CustomerId चुनें.
यदि डेटा आपके एकीकृत ग्राहक प्रोफ़ाइल में उपलब्ध है, तो अधिक फ़ील्ड मैप करें.
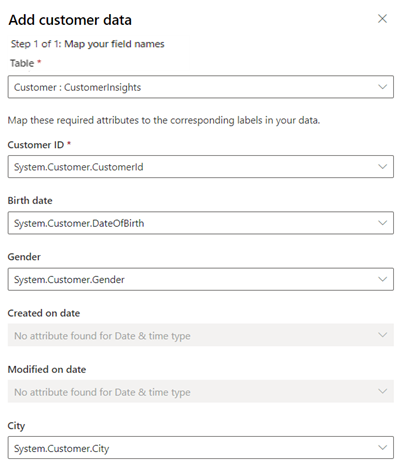
सहेजें चुनें.
अगला चुनें.
अपडेट शेड्यूल सेट करें
नवीनतम डेटा के आधार पर अपने मॉडल को पुनः प्रशिक्षित करने की आवृत्ति चुनें। नए डेटा को इन्जेस्ट करने के कारण यह सेटिंग पूर्वानुमानों की सटीकता को अद्यतन करने के लिए महत्वपूर्ण है. अधिकांश व्यवसाय प्रति माह एक बार फिर से सिखा सकते हैं और उनके पूर्वानुमान के लिए अच्छी सटीकता प्राप्त कर सकते हैं.
अगला चुनें.
मॉडल कॉन्फ़िगरेशन की समीक्षा करें और रन करें
समीक्षा करें और चलाएँ चरण कॉन्फ़िगरेशन का सारांश दिखाता है और आपको पूर्वानुमान बनाने से पहले परिवर्तन करने का अवसर प्रदान करता है।
समीक्षा करने और कोई भी परिवर्तन करने के लिए किसी भी चरण पर संपादित करें का चयन करें।
यदि आप अपने चयन से संतुष्ट हैं, तो मॉडल चलाना शुरू करने के लिए सहेजें और चलाएँ का चयन करें। पूर्ण चयन करें. पूर्वानुमान बनाते समय मेरी भविष्यवाणियां टैब प्रदर्शित होता है। पूर्वानुमान में उपयोग किए गए डेटा की मात्रा के आधार पर प्रक्रिया को पूरा करने में कई घंटे लग सकते हैं.
टिप
कार्यों और प्रक्रियाओं के लिए स्थितियाँ हैं। अधिकांश प्रक्रियाएं अन्य अपस्ट्रीम प्रक्रियाओं पर निर्भर करती हैं, जैसे कि डेटा स्रोत और डेटा प्रोफाइलिंग रीफ्रेश।
प्रगति विवरण फलक खोलने और कार्यों की प्रगति देखने के लिए स्थिति का चयन करें। कार्य रद्द करने के लिए, फलक के नीचे कार्य रद्द करें का चयन करें.
प्रत्येक कार्य के अंतर्गत, आप अधिक प्रगति जानकारी के लिए विवरण देखें का चयन कर सकते हैं, जैसे कि प्रसंस्करण समय, अंतिम प्रसंस्करण तिथि, तथा कार्य या प्रक्रिया से संबंधित कोई भी लागू त्रुटियाँ और चेतावनियाँ। सिस्टम में अन्य प्रक्रियाओं को देखने के लिए पैनल के नीचे सिस्टम स्थिति देखें का चयन करें।
पूर्वानुमान परिणाम देखें
अंतर्दृष्टि>भविष्यवाणियां पर जाएं.
मेरी भविष्यवाणियां टैब में, वह पूर्वानुमान चुनें जिसे आप देखना चाहते हैं।
नतीजे पृष्ठ के भीतर डेटा के तीन प्राथमिक अनुभाग हैं.
प्रशिक्षण मॉडल प्रदर्शन: ग्रेड A, B, या C पूर्वानुमान के प्रदर्शन को इंगित करते हैं और आउटपुट तालिका में संग्रहीत परिणामों का उपयोग करने का निर्णय लेने में आपकी सहायता कर सकते हैं।
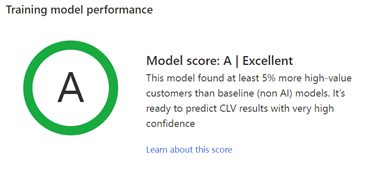
यह प्रणाली यह आकलन करती है कि बेसलाइन मॉडल की तुलना में उच्च मूल्य वाले ग्राहकों की भविष्यवाणी करने में एआई मॉडल का प्रदर्शन कैसा रहा।
ग्रेड निम्नलिखित नियमों के आधार पर निर्धारित किए जाते हैं:
- जब मॉडल ने बेसलाइन मॉडल की तुलना में कम से कम 5% अधिक उच्च-मूल्य वाले ग्राहकों की सटीक भविष्यवाणी की।
- जब मॉडल ने बेसलाइन मॉडल की तुलना में 0-5% अधिक उच्च-मूल्य वाले ग्राहकों की सटीक भविष्यवाणी की।
- C जब मॉडल ने बेसलाइन मॉडल की तुलना में कम उच्च-मूल्य वाले ग्राहकों की सटीक भविष्यवाणी की।
इस स्कोर के बारे में जानें चुनें और मॉडल रेटिंग पैन खोलें, जो AI मॉडल प्रदर्शन और बेसलाइन मॉडल के बारे में और अधिक जानकारी दिखाता है। इससे आपको अंतर्निहित मॉडल प्रदर्शन मीट्रिक्स को बेहतर ढंग से समझने में मदद मिलेगी और यह भी कि अंतिम मॉडल प्रदर्शन ग्रेड कैसे प्राप्त किया गया। बेसलाइन मॉडल मुख्य रूप से ग्राहकों द्वारा किए गए ऐतिहासिक खरीद के आधार पर ग्राहक जीवनकाल मूल्य की गणना करने के लिए गैर-A आधारित दृष्टिकोण का उपयोग करता है.
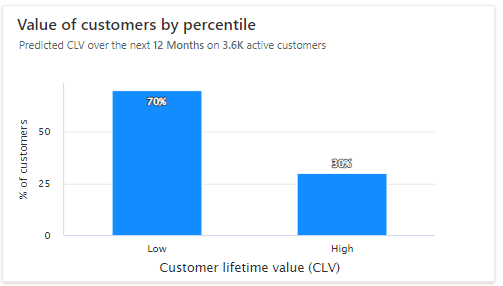
प्रतिशत के अनुसार ग्राहकों का मूल्य: कम मूल्य और उच्च मूल्य वाले ग्राहक एक चार्ट में प्रदर्शित होते हैं। प्रत्येक समूह में ग्राहकों की संख्या और उस समूह का औसत CLV देखने के लिए हिस्टोग्राम में बार पर माउस घुमाएं। वैकल्पिक रूप से, ग्राहकों के सेगमेंट बनाएं उनके CLV पूर्वानुमानों के आधार पर।
सबसे प्रभावशाली कारक: AI मॉडल को प्रदान किए गए इनपुट डेटा के आधार पर आपका CLV पूर्वानुमान बनाते समय विभिन्न कारकों पर विचार किया जाता है। प्रत्येक कारक की गणना समग्र पूर्वानुमानों के लिए महत्व के अनुसार की जाती है जिनको मॉडल बनाता है. अपने पूर्वानुमान परिणामों को मान्य करने में सहायता के लिए इन कारकों का उपयोग करें। ये कारक आपके सभी ग्राहकों में CLV का पूर्वानुमान करने में योगदान देने वाले सबसे प्रभावशाली कारकों के बारे में अधिक जानकारी प्रदान करते हैं.

स्कोर के बारे में जानें
बेसलाइन मॉडल द्वारा CLV की गणना करने के लिए उपयोग किया जाने वाला मानक फॉर्मूला:
प्रत्येक ग्राहक के लिए CLV = सक्रिय ग्राहक विंडो में ग्राहक द्वारा की गई औसत मासिक खरीदारी * CLV पूर्वानुमान अवधि में महीनों की संख्या * सभी ग्राहकों की कुल अवधारण दर
AI मॉडल की तुलना दो मॉडल प्रदर्शन मैट्रिक्स के आधार पर बेसलाइन मॉडल से की जाती है.
उच्च-मूल्य वाले ग्राहकों की भविष्यवाणी करने में सफलता दर
बेसलाइन मॉडल की तुलना में AI मॉडल का उपयोग करके उच्च-मूल्य वाले ग्राहकों का पूर्वानुमान करने में अंतर देखें. उदाहरण के लिए, 84% सफलता दर का मतलब है कि प्रशिक्षण डेटा में सभी उच्च-मूल्य वाले ग्राहकों में से, AI मॉडल 84% को सही ढंग से कैप्चर करने में सक्षम था. फिर हम इस सफलता दर की तुलना बेसलाइन मॉडल की सफलता दर के साथ सापेक्ष परिवर्तन की रिपोर्ट करने के लिए करते हैं. इस मूल्य का उपयोग मॉडल को एक ग्रेड आवंटित करने के लिए किया जाता है.
त्रुटि मीट्रिक्स
भविष्य के मूल्यों की भविष्यवाणी करने में त्रुटि के संदर्भ में मॉडल के समग्र प्रदर्शन को देखें। हम इस त्रुटि का आकलन करने के लिए समग्र रूट मीन स्क्वायर्ड एरर (RMSE) मीट्रिक का उपयोग करते हैं. RMSE मात्रात्मक डेटा का पूर्वानुमान करने में एक मॉडल की त्रुटि को मापने का एक मानक तरीका है. AI मॉडल के RMSE की तुलना बेसलाइन मॉडल के RMSE से की जाती है और सापेक्ष अंतर की रिपोर्ट की जाती है.
AI मॉडल आपके व्यवसाय में लाए गए मूल्य के अनुसार ग्राहकों की सटीक रैंकिंग को प्राथमिकता देता है. तो अंतिम मॉडल ग्रेड प्राप्त करने के लिए उच्च-मूल्य वाले ग्राहकों का पूर्वानुमान करने के लिए केवल सफलता दर का उपयोग किया जाता है. RMSE मीट्रिक आउटलीयर के लिए संवेदनशील है. ऐसे परिदृश्यों में जहां आपके पास असाधारण रूप से उच्च खरीद मूल्यों वाले कम प्रतिशत ग्राहक हैं, समग्र RMSE मीट्रिक मॉडल के प्रदर्शन की पूरी तस्वीर नहीं दे सकता है.