Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Overview
Azure Data Factory és a Synapse Analytics-leképezési adatfolyam hibakeresési módja lehetővé teszi az adatalakzatok átalakításának interaktív megtekintését az adatfolyamok létrehozása és hibakeresése során. A hibakeresési munkamenet Adatfolyam tervezési munkamenetekben és az adatfolyamok folyamatkeresési végrehajtása során egyaránt használható. A hibakeresési mód bekapcsolásához használja az Adatfolyam Hibakeresés gombot az adatfolyam vászon vagy folyamatvászon felső sávjában, ha adatfolyam tevékenységeket végez.
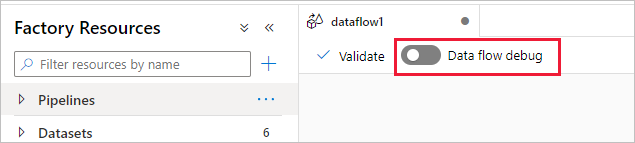

A csúszka bekapcsolása után a rendszer kérni fogja, hogy válassza ki a használni kívánt integrációs modul konfigurációját. Ha az AutoResolveIntegrationRuntime lehetőséget választja, a rendszer felpörget egy olyan fürtöt, amely nyolc magnyi általános számítással rendelkezik, és az alapértelmezett 60 perces élettartammal rendelkezik. Ha még több tétlen csapatot szeretne engedélyezni, mielőtt túllépi a munkamenet időkorlátját, választhat egy magasabb TTL-beállítást. Az adatfolyam-integrációs futtatókörnyezetekről további információt a Integration Runtime teljesítmény című témakörben talál.
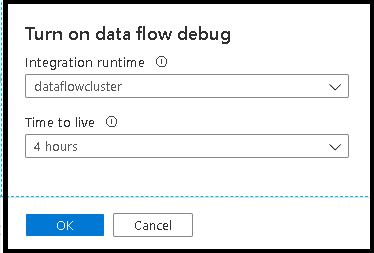
Ha a hibakeresési mód be van kapcsolva, interaktív módon építheti fel az adatfolyamot egy aktív Spark-fürttel. A munkamenet a hibakeresés kikapcsolása után bezárul. Tisztában kell lennie a Data Factory által a hibakeresési munkamenet bekapcsolása során felmerülő óránkénti díjakkal.
A legtöbb esetben célszerű hibakeresési módban létrehozni az adatfolyamokat, hogy a munka közzététele előtt érvényesíthesse az üzleti logikát, és megtekinthesse az adatátalakításokat. A folyamatpanel "Hibakeresés" gombjával tesztelheti az adatfolyamot egy folyamatban.
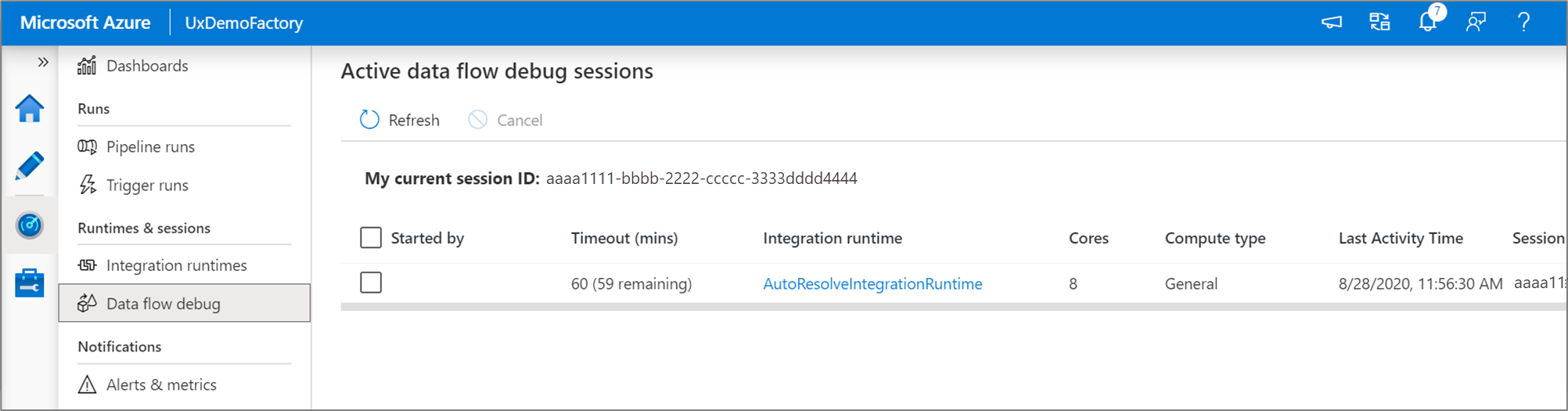
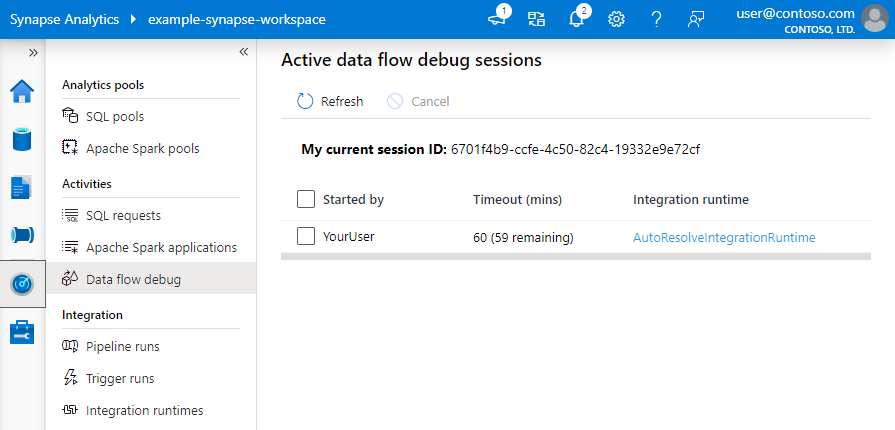
Note
Minden olyan hibakeresési munkamenet, amelyet a felhasználó a böngésző felhasználói felületéről indít, egy új munkamenet saját Spark-fürttel. Az előző képeken látható hibakeresési munkamenetek figyelési nézetével megtekintheti és kezelheti a hibakeresési munkameneteket. Mindegyik hibakeresési munkamenet futási idejére óránként díjat számítanak fel, beleértve a TTL-időt is.
Ez a videoklip tippeket, trükköket és ajánlott eljárásokat mutat be az adatfolyam-hibakeresési módhoz.
Klaszter állapota
Ha a fürt készen áll a hibakeresésre, a tervezési felület tetején lévő fürt állapotjelzője zöldre vált. Ha a fürt már meleg, akkor a zöld jelző szinte azonnal megjelenik. Ha a fürt még nem futott a hibakeresési mód megadásakor, a Spark-fürt hideg rendszerindítást hajt végre. A mutató addig pörög, amíg a környezet készen nem áll az interaktív hibakeresésre.
Ha végzett a hibakereséssel, kapcsolja ki a hibakeresési kapcsolót, hogy a Spark-fürt leálljon, és a továbbiakban nem kell fizetnie a hibakeresési tevékenységért.
Hibakeresési beállítások
A hibakeresési mód bekapcsolása után szerkesztheti, hogy az adatfolyam hogyan tekinti meg az adatokat. A hibakeresési beállítások a Adatfolyam vászon eszköztárán található Hibakeresési beállítások elemre kattintva szerkeszthetők. Itt kiválaszthatja az egyes forrásátalakításokhoz használni kívánt sorkorlátot vagy fájlforrást. Ebben a beállításban a sorkorlátok csak az aktuális hibakeresési munkamenetre vonatkoznak. Kiválaszthatja azt az átmeneti társított szolgáltatást is, amelyet egy Azure Synapse Analytics forráshoz szeretne használni.
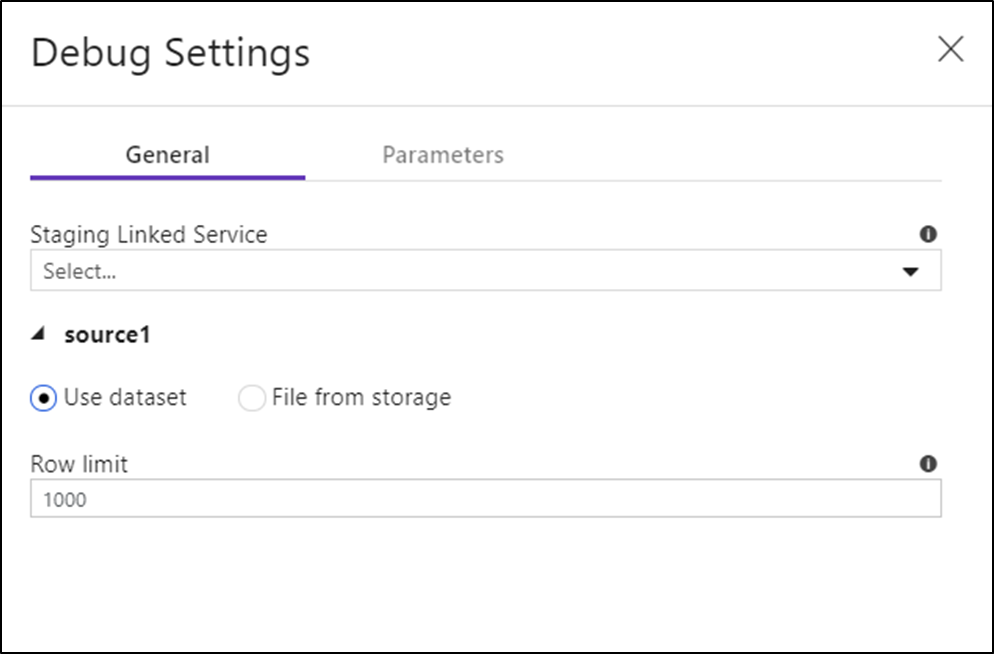
Ha a Adatfolyam vagy bármely hivatkozott adatkészletében vannak paraméterek, a hibakeresés során használandó értékeket a Parameters lap kiválasztásával adhatja meg.
Az itt található mintavételezési beállításokkal mintafájlokra vagy adattáblákra mutathat, hogy ne kelljen módosítania a forrásadatkészleteket. Ha itt egy mintafájlt vagy táblázatot használ, ugyanazokat a logikai és tulajdonságbeállításokat tarthatja fenn az adatfolyamban, miközben az adatok egy részhalmazán tesztel.
Adatfolyamok hibakeresési módjában az alapértelmezett Integration Runtime (IR) egy kisméretű, 4 magos egymunkás csomópont és egy 4 magos egyvezérlő csomópont. Ez jól működik kisebb adatmintákkal az adatfolyam-logika tesztelése során. Ha az adatok előnézete során kibontja a hibakeresési beállítások sorkorlátait, vagy a folyamat hibakeresése során nagyobb számú mintául szolgáló sort állít be a forrásban, érdemes lehet egy nagyobb számítási környezetet beállítani egy új Azure Integration Runtime. Ezután a nagyobb számítási környezettel újraindíthatja a hibakeresési munkamenetet.
Adatok előnézete
Ha be van kapcsolva a hibakeresés, az Adatok előnézete lap az alsó panelen jelenik meg. Hibakeresési mód bekapcsolása nélkül Adatfolyam az Ellenőrzés lapon csak az egyes átalakítások aktuális metaadatait jeleníti meg. Az adatelőnézet csak a hibakeresési beállításokban megadott korlátként beállított sorok számát kérdezi le. A Frissítés gombra kattintva frissítheti az adatok előnézetét az aktuális átalakítások alapján. Ha a forrásadatok megváltoztak, válassza a Forrás > frissítése lehetőséget.
Az oszlopokat az adat előnézetében rendezheti, és húzással átrendezheti az oszlopokat. Emellett az adatelőnézet panel tetején található egy exportálási gomb, amellyel az előnézeti adatokat egy CSV-fájlba exportálhatja offline adatfeltáráshoz. Ezzel a funkcióval legfeljebb 1000 sornyi előzetes adat exportálható.
Note
A fájlforrások csak a látható sorokat korlátozzák, az éppen beolvasott sorokat nem. Nagyon nagy adathalmazok esetén ajánlott a fájl egy kis részét bevenni, és használni a teszteléshez. A hibakeresési beállításokban kiválaszthat egy ideiglenes fájlt minden olyan forráshoz, amely fájladatkészlet-típus.
Ha hibakereső módban futtatja a Adatfolyam-t, az adatok nem íródnak a fogadó transzformációba. A hibakeresési munkamenetek az átalakítások tesztelésére szolgálnak. Az elnyelők nem szükségesek a hibakeresés során, és figyelmen kívül maradnak az adatfolyamban. Ha tesztelni szeretné az adatok írását az adatfogadó helyre, hajtsa végre az Adatáramlást egy folyamatból, és használja a hibakeresési futtatást a folyamatnál.
A Data Preview egy pillanatkép az átalakított adatokról sorkorlátokkal és adatmintákkal a Spark-memóriában lévő adatkeretekből. Ezért ebben a forgatókönyvben a kimeneti illesztőprogramokat nem használják vagy tesztelik.
Note
A Data Preview a böngésző területi beállításának megfelelően jeleníti meg az időt.
Illesztés feltételeinek tesztelése
Az egységtesztek során, amikor kapcsolat létrehozásokat, létezés vizsgálatokat vagy keresési átalakításokat tesztel, győződjön meg arról, hogy a teszt során egy kis ismert adathalmazt használ. A korábban ismertetett Hibakeresési beállítások lehetőséggel beállíthat egy ideiglenes fájlt a teszteléshez. Erre azért van szükség, mert ha nagy adathalmazból korlátozza vagy mintavételezi a sorokat, nem tudja előre megjósolni, hogy mely sorok és mely kulcsok legyenek beolvasva a folyamatba tesztelés céljából. Az eredmény nem determinisztikus, ami azt jelenti, hogy az illesztés feltételei meghiúsulhatnak.
Gyorsműveletek
Miután megtekinti az adatok előnézetét, gyors átalakítást hozhat létre az oszlop beírásához, eltávolításához vagy módosításához. Jelölje ki az oszlopfejlécet, majd válassza ki az adatelőnézet eszköztárának egyik beállítását.
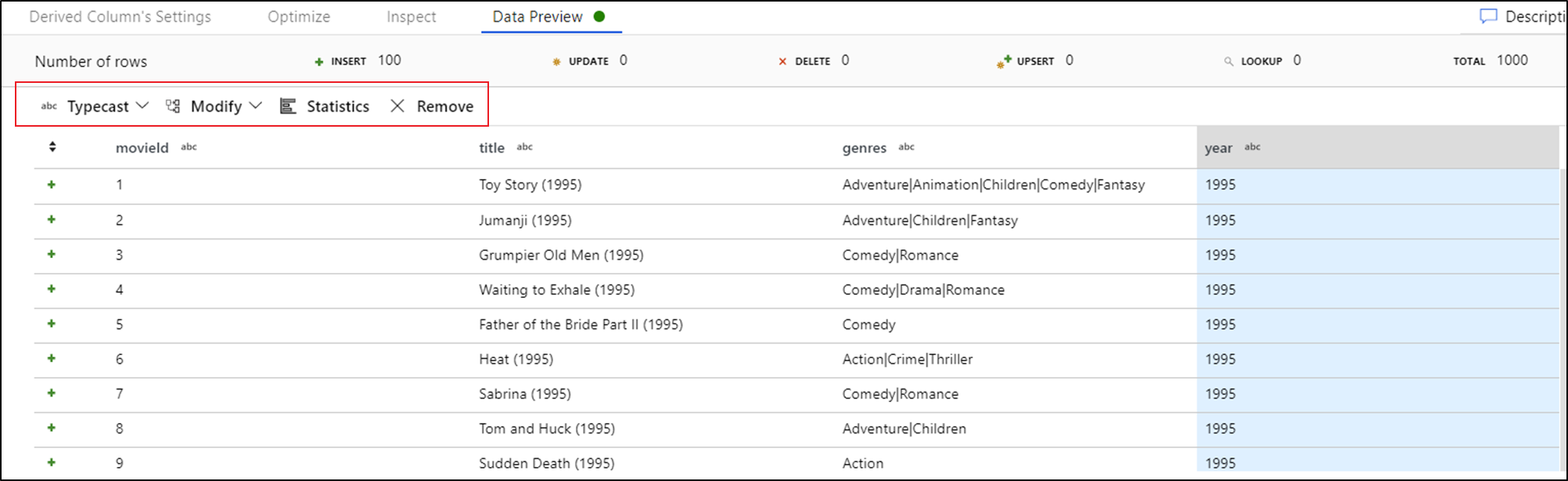
Miután kiválasztott egy módosítást, az adatok előnézete azonnal frissülni fog. Új átalakítás létrehozásához válassza a jobb felső sarokban található Megerősítés lehetőséget.
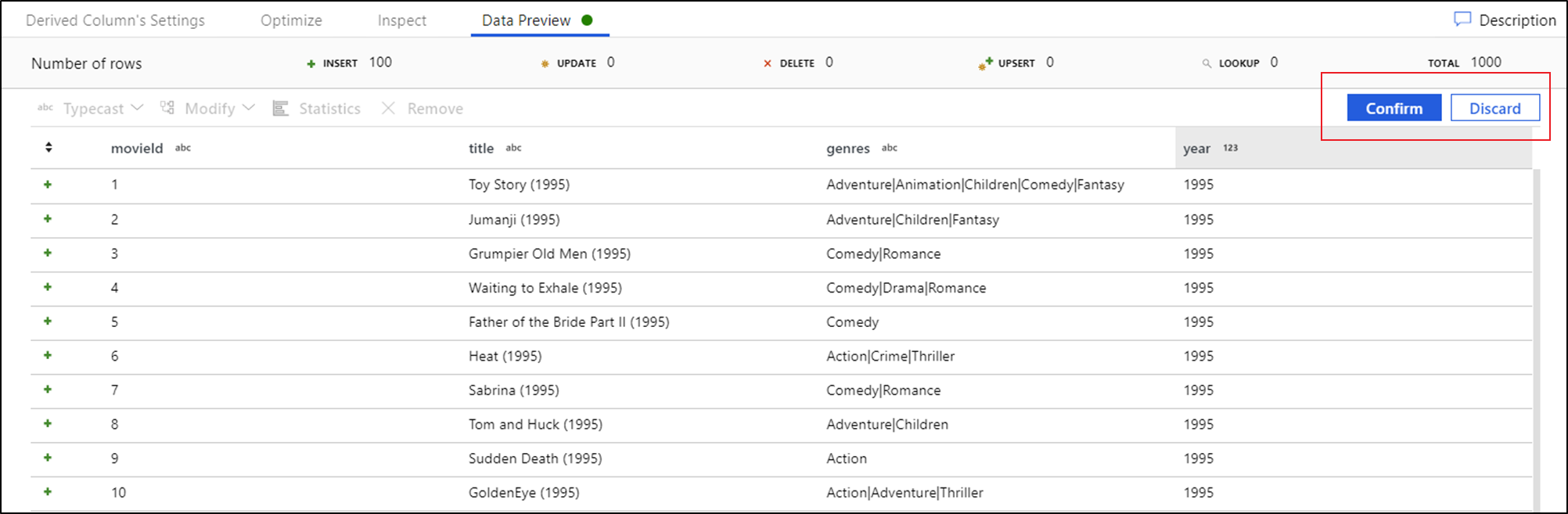
A Typecast és a Modify létrehoz egy származtatott oszlopátalakítást, a Remove pedig Select átalakítást hoz létre.
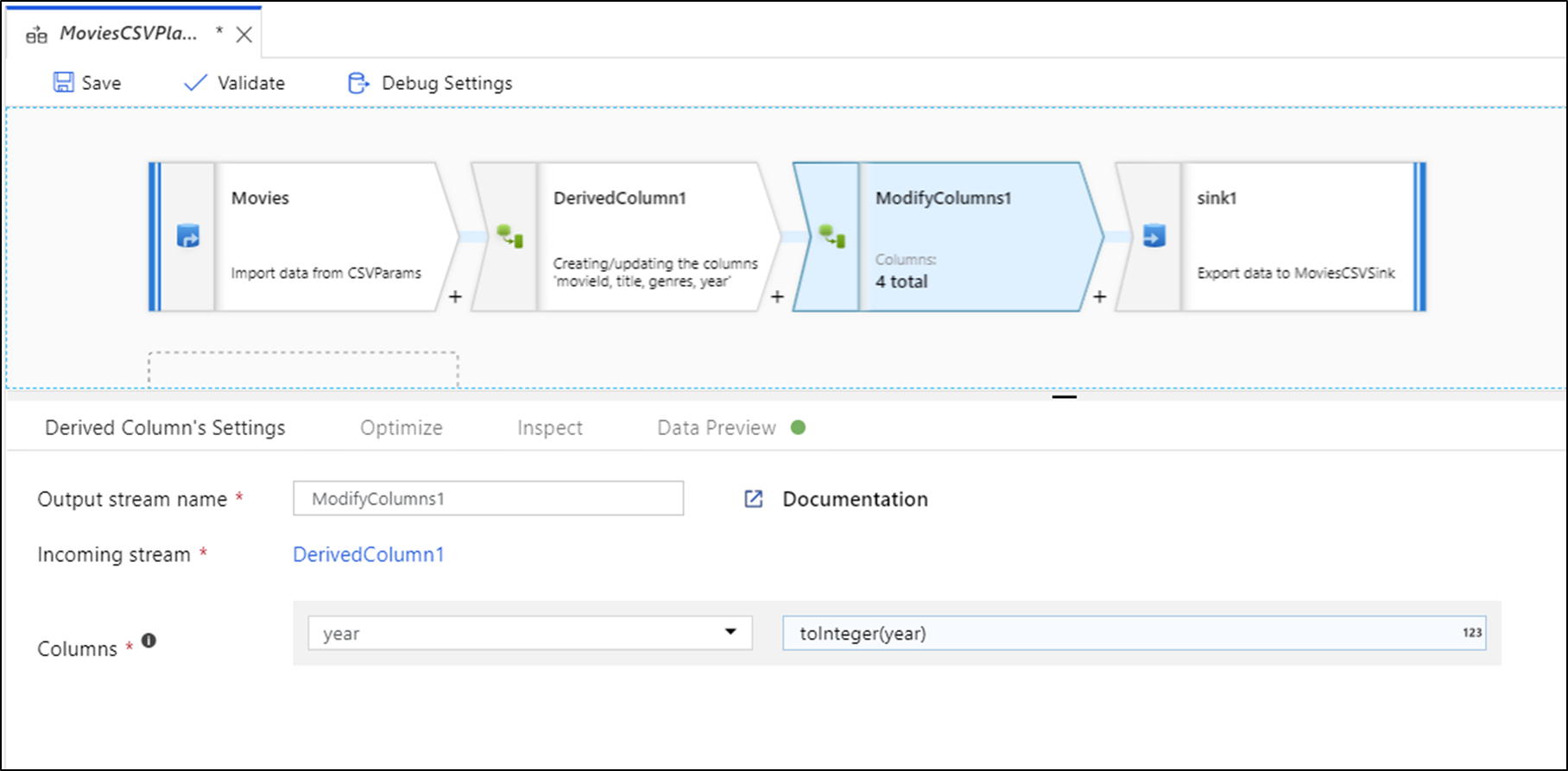
Note
Ha szerkeszti az adatfolyamot, az adatok előnézetének újbóli lekérése szükséges, mielőtt gyors átalakítást ad hozzá.
Adatprofilozás
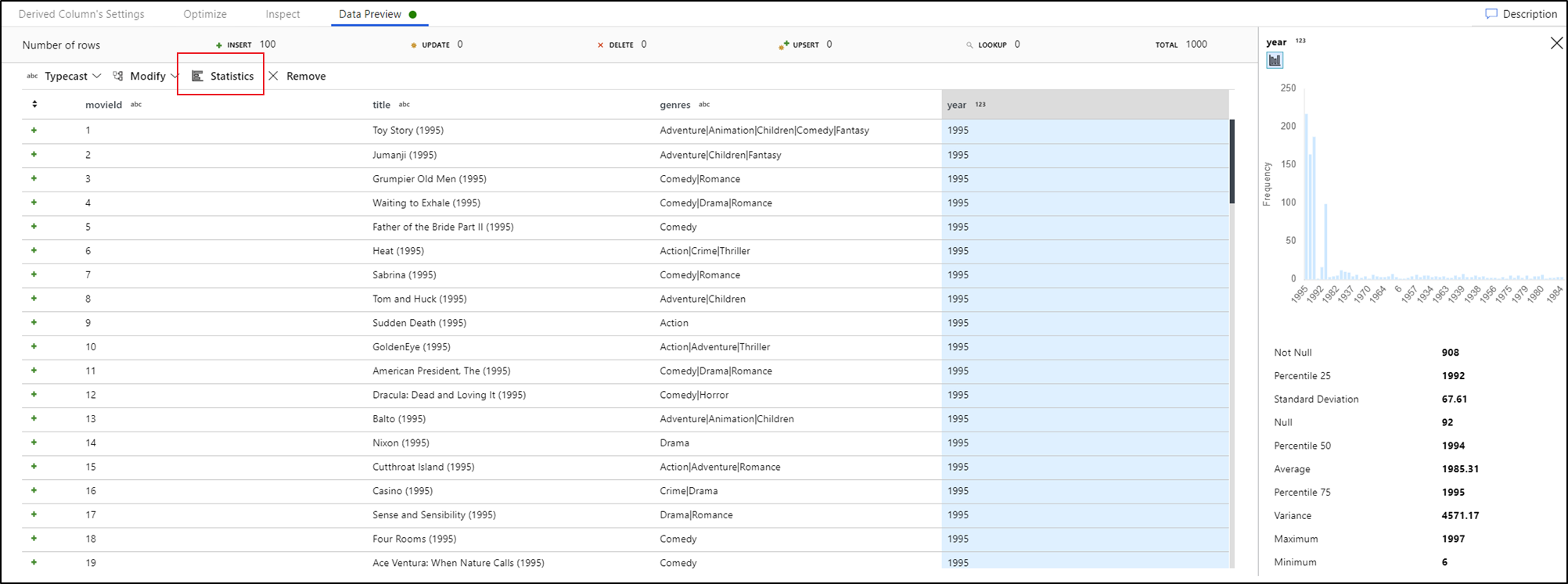
Ha kijelöl egy oszlopot az adatelőnézet lapján, és az adatelőnézet eszköztárÁban a Statisztika elemre kattint, megjelenik egy diagram az adatrács jobb szélén, és részletes statisztikákat jelenít meg az egyes mezőkről. A szolgáltatás a megjelenítendő diagram típusának adatmintázatán alapul. A magas számosságú mezők alapértelmezés szerint NULL/NOT NULL diagramok, míg az alacsony számosságú kategorikus és numerikus adatok az adatérték gyakoriságát megjelenítő sávdiagramokat jelenítik meg. A sztringmezők maximális/hosszhosszát, a numerikus mezőkben a minimális/maximális értékeket, a standard devet, a percentiliseket, a darabszámokat és az átlagot is láthatja.
Kapcsolódó tartalom
- Miután befejezte az adatfolyam összeállítását és hibakeresését, futtassa le egy csővezetékből.
- Amikor adatfolyammal teszteli a folyamatot, használja a folyamat hibakeresési futtatási lehetőségét.