Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
A Adatfolyam tevékenység használatával átalakíthatja és áthelyezheti az adatokat leképezési adatfolyamokkal. Ha még új az adatfolyamok területén, tekintse meg az Adattérkép adatfolyamának áttekintése
Adatfolyam tevékenység létrehozása felhasználói felülettel
Ha Adatfolyam tevékenységet szeretne használni egy folyamatban, hajtsa végre a következő lépéseket:
Keresse meg a Adatfolyam a folyamattevékenységek panelen, és húzzon egy Adatfolyam tevékenységet a folyamatvászonra.
Jelölje ki az új Adatfolyam tevékenységet a vásznon, ha még nincs kijelölve, és a Settings lapot a részletek szerkesztéséhez.
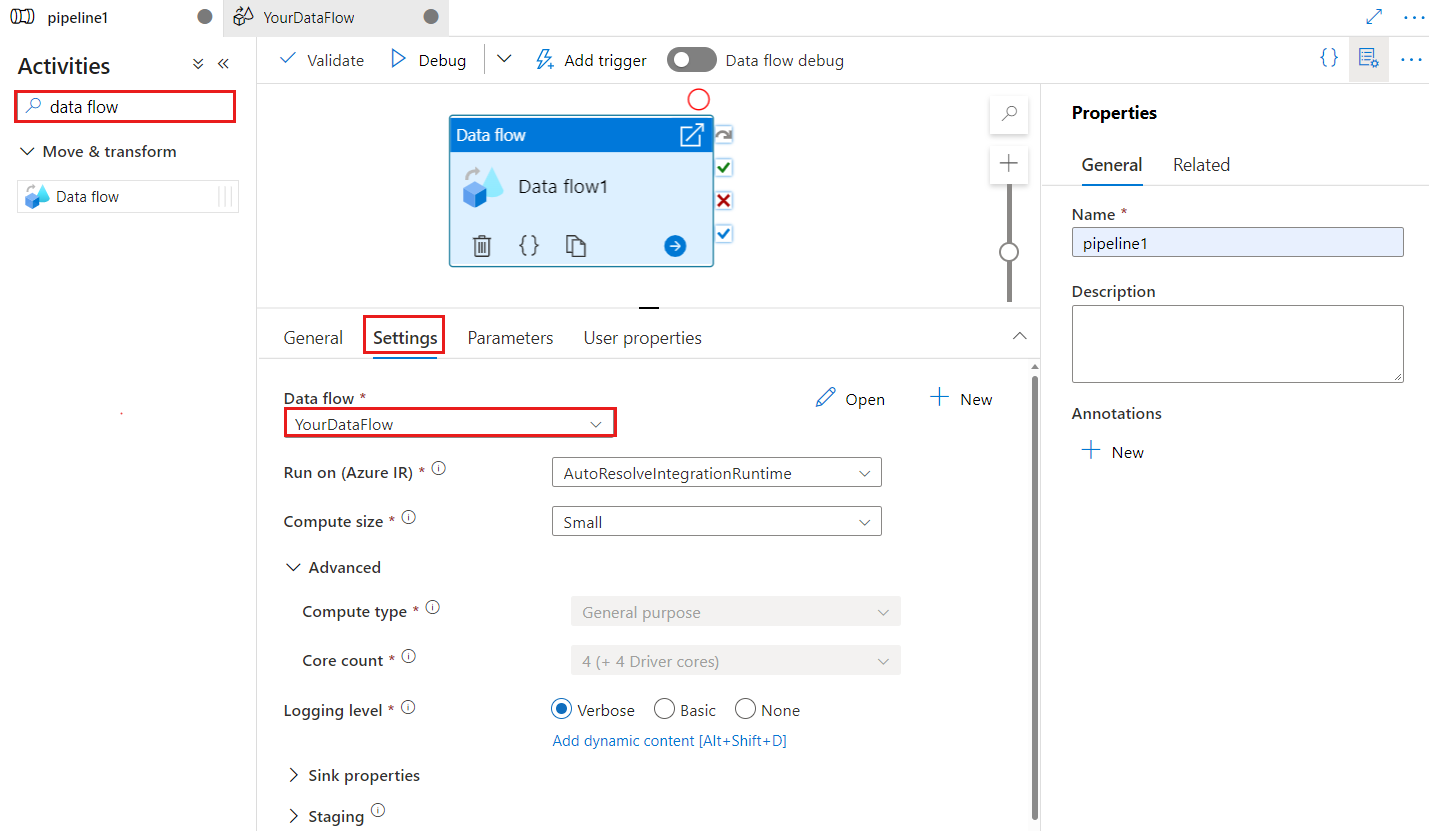
A checkpoint billentyű az ellenőrzőpont beállítására szolgál, amikor az adatfolyamot a módosított adatrögzítéshez használják. Felülírhatja. Az adatfolyam-tevékenységek a "folyamat + tevékenység neve" helyett GUID értéket használnak ellenőrzőpontkulcsként, hogy mindig nyomon követhessék az ügyfél változáskövetési állapotát, még akkor is, ha vannak átnevezési műveletek. Minden meglévő adatfolyam-tevékenység a régi mintakulcsot használja a visszamenőleges kompatibilitás érdekében. Az új adatfolyam-tevékenység módosítási adatrögzítéssel engedélyezett adatfolyam-erőforrással való közzététele után az ellenőrzőpontkulcs-beállítás az alábbi módon jelenik meg.
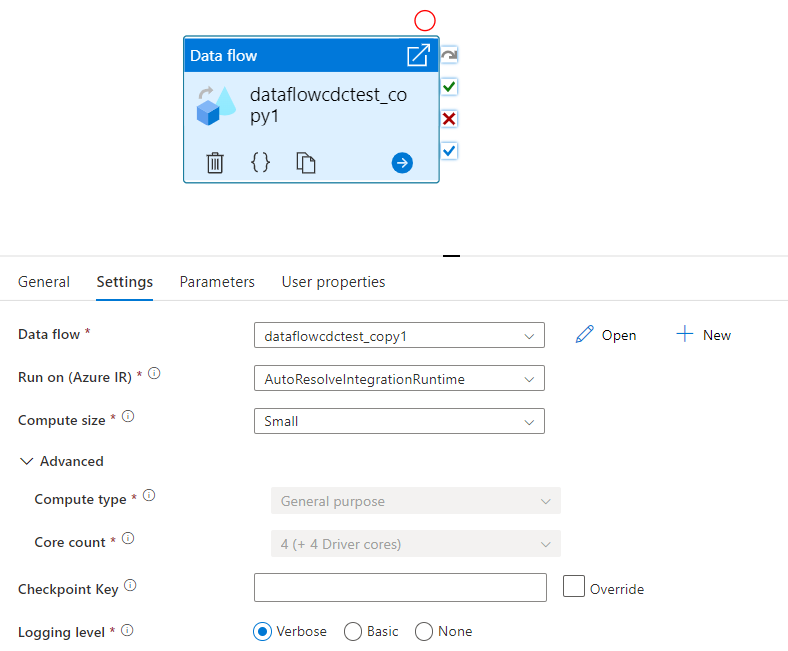
Válasszon ki egy meglévő adatfolyamot, vagy hozzon létre egy újat az Új gombbal. A konfiguráció befejezéséhez szükség szerint válasszon más beállításokat.
Szintaxis
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Típustulajdonságok
| Tulajdonság | Leírás | Megengedett értékek | Kötelező |
|---|---|---|---|
| adatfolyam | A végrehajtás alatt álló Adatfolyam-ra való hivatkozás | DataFlowReference | Igen |
| integrationRuntime | Az adatfolyam által futtatott számítási környezet. Ha nincs megadva, a rendszer az automegoldó Azure integrációs futtatókörnyezetet használja. | IntegrationRuntimeReference | Nem |
| compute.coreCount | A Spark-fürtben használt magok száma. Csak akkor adható meg, ha az Azure automatikus megoldási integrációs futásideje van használatban | 8, 16, 32, 48, 80, 144, 272 | Nem |
| compute.computeType | A Spark-fürtben használt számítási erőforrás típusa. Csak akkor adható meg, ha az Azure automatikus megoldási integrációs futásideje van használatban | Általános | Nem |
| staging.linkedService | Ha Azure Synapse Analytics forrást vagy fogadót használ, adja meg a PolyBase-előkészítéshez használt tárfiókot. Ha az Azure Storage virtuális hálózati szolgáltatásvégponttal van konfigurálva, akkor a "megbízható Microsoft szolgáltatások engedélyezése" beállítással ellátott tárfiókon felügyelt identitáshitelesítést kell használnia. További információért tekintse meg a A virtuális hálózati szolgáltatásvégpontok hatása az Azure Storage használatára. Megismerheti a Azure Blob és Azure Data Lake Storage Gen2 szükséges konfigurációit is. |
LinkedServiceReference | Csak akkor, ha az adatfolyam olvas vagy ír egy Azure Synapse Analytics munkaterületre. |
| staging.folderPath | Ha Azure Synapse Analytics forrást vagy fogadót használ, a PolyBase-előkészítéshez használt Blob Storage-fiók mappaútvonala | Sztring | Csak akkor, ha az adatfolyam beolvasás vagy írás céljából az Azure Synapse Analytics-hez kapcsolódik. |
| nyomkövetési szint | Az adatfolyam-tevékenység végrehajtásának naplózási szintjének beállítása | Finom, Durva, Nincs | Nem |
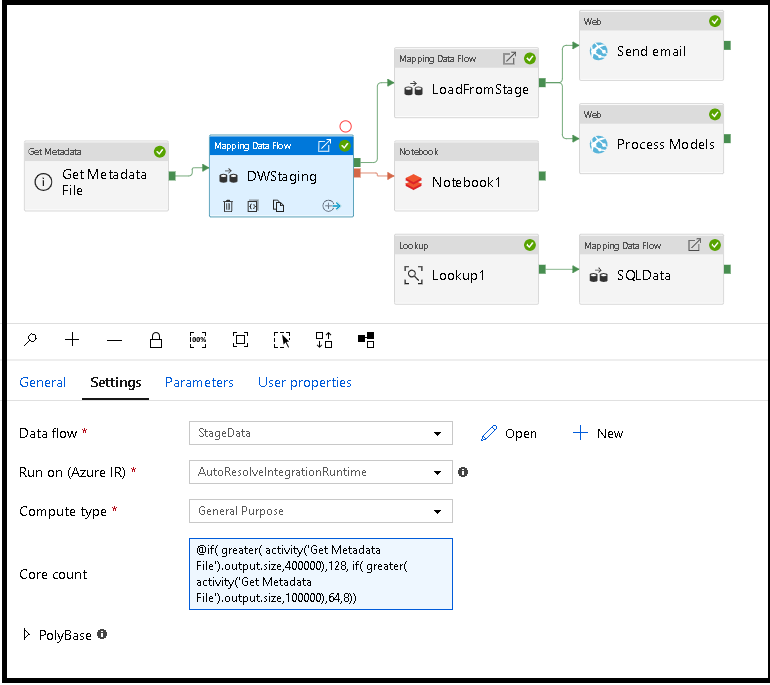
Futásidőben dinamikusan méretezze az adatfolyamat feldolgozást
Az alapszám és a számítási típus tulajdonságai dinamikusan állíthatók be, hogy futásidőben a bejövő forrásadatok méretéhez igazodjanak. A forrásadatkészlet-adatok méretének megkereséséhez használjon folyamattevékenységeket, például keresést vagy metaadatok lekérését. Ezután használja a Dinamikus tartalom hozzáadása lehetőséget a Adatfolyam tevékenységtulajdonságokban. Választhat kis, közepes vagy nagy számítási méreteket. Opcionálisan válassza az "Egyéni" lehetőséget, és konfigurálja manuálisan a számítási típusokat és a magok számát.
Íme egy rövid oktatóvideó, amely ismerteti ezt a technikát
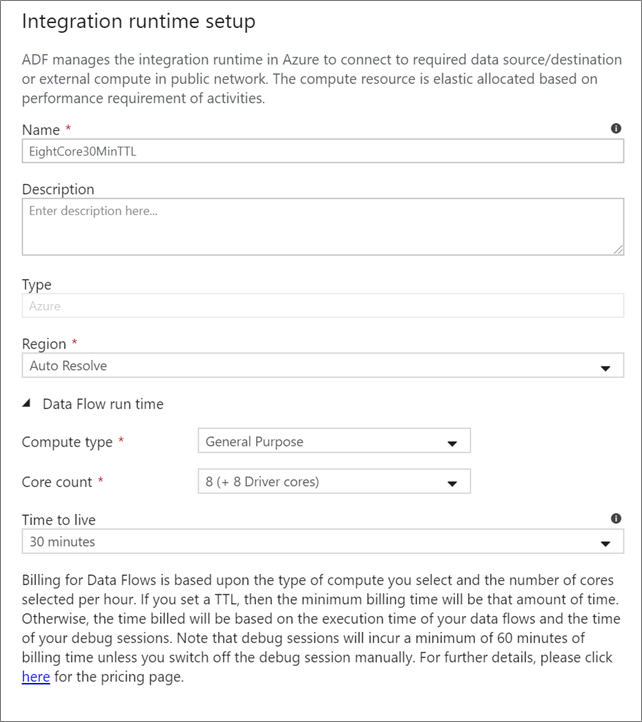
Adatfolyam integrációs futtatókörnyezet
Válassza ki a Adatfolyam tevékenység végrehajtásához használni kívánt Integration Runtime. A szolgáltatás alapértelmezés szerint az automatikusan feloldott Azure integrációs modult használja négy feldolgozómaggal. Ez az integrációs modul általános célú számítási típussal rendelkezik, és ugyanabban a régióban fut, mint a szolgáltatáspéldány. Az operatív folyamatok esetében kifejezetten ajánlott saját Azure integrációs futtatókörnyezeteket létrehozni, amelyek meghatározott régiókat, számítási típust, magszámokat és TTL-t határoznak meg az adatfolyam-tevékenységek végrehajtásához.
Az általános célú minimális számítási típus 8+8 (összesen 16 virtuális mag) konfigurációval és 10 perces élettartammal (TTL) a legtöbb éles számítási feladatra vonatkozó minimális javaslat. Egy kis TTL beállításával az Azure IR képes fenntartani egy "ready cluster"-t, amely nem jár több percnyi indítási idővel egy "cold cluster" esetében. További információ: Azure integrációs modul.
Fontos
A Adatfolyam tevékenységen belüli Integration Runtime választás csak a folyamat indított végrehajtásokra vonatkozik. A folyamat hibakeresése adatfolyamokkal a hibakeresési munkamenetben megadott fürtön fut.
PolyBase
Ha Ön Azure Synapse Analytics rendszert használ célként vagy forrásként, ki kell választania egy előfeldolgozási helyszínt a PolyBase kötegbetöltéshez. A PolyBase lehetővé teszi az adatok tömeges kötegelt betöltését az adatsorok egyenkénti betöltése helyett. A PolyBase drasztikusan csökkenti a betöltési időt az Azure Synapse Analytics-be.
Ellenőrzőpont-kulcs
Az adatfolyam-források változásrögzítési beállításának használatakor az ADF automatikusan fenntartja és kezeli az ellenőrzőpontot. Az alapértelmezett ellenőrzőpontkulcs az adatfolyam nevének és a folyamat nevének kivonata. Ha dinamikus mintát használ a forrástáblákhoz vagy mappákhoz, érdemes lehet felülbírálni ezt a kivonatot, és itt beállíthatja a saját ellenőrzőpont kulcsértékét.
Naplózási szint
Ha nem követeli meg az adatfolyam-tevékenységek minden folyamatvégrehajtását az összes részletes telemetriai napló teljes naplózásához, a naplózási szintet igény szerint "Alapszintű" vagy "Nincs" értékre állíthatja. Amikor az adatfolyamokat "Részletes" módban (alapértelmezett) hajtja végre, az adatátalakítás során minden egyes partíciószinten teljes körű naplózási tevékenységet kér a szolgáltatástól. Ez költséges művelet lehet, ezért csak a részletes hibaelhárítás engedélyezése javíthatja a teljes adatfolyamot és a folyamat teljesítményét. Az "Alapszintű" mód csak az átalakítási időtartamokat naplózza, míg a "Nincs" csak az időtartamok összegzését adja meg.

Adatsín tulajdonságai
Az adatfolyamok csoportosítási funkciója lehetővé teszi a célok végrehajtási sorrendjének beállítását, valamint a célok csoportosítását ugyanazzal a csoportszámmal. A csoportok kezeléséhez megkérheti a szolgáltatást, hogy ugyanabban a csoportban, párhuzamosan futtassa a sinks-eket. Beállíthatja azt is, hogy a fogadó csoport folytatódjon akkor is, ha az egyik fogadó hibát észlel.
Az adatfolyam kimenetek alapértelmezett viselkedése az, hogy egymás után sorosan hajtják végre a kimeneteket, és ha hiba lép fel a kimenetben, a teljes adatfolyam hibát jelez. Emellett az összes fogadó alapértelmezés szerint ugyanarra a csoportra van beállítva, hacsak nem lép be az adatfolyam tulajdonságaiba, és nem állít be különböző prioritásokat a fogadók számára.

Csak az első sor
Ez a beállítás csak olyan adatfolyamok esetén érhető el, amelyeknél engedélyezve van a gyorsítótár a "Tevékenységhez való kimenet" funkcióhoz. A folyamatba közvetlenül injektált adatfolyam kimenete legfeljebb 2 MB lehet. A "csak az első sor" beállításával korlátozhatja az adatfolyamból származó adatkimenetet, amikor az adatfolyam tevékenységi kimenetét közvetlenül a munkafolyamatba integrálja.
Adatfolyam paraméterezése
Paraméteres adatkészletek
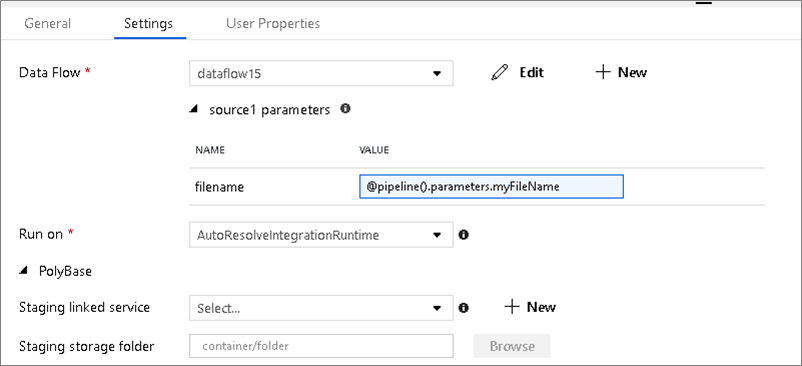
Ha az adatfolyam paraméteres adatkészleteket használ, állítsa be a paraméterértékeket a Beállítások lapon.
Paraméteres adatfolyamok
Ha az adatfolyam paraméterezve van, állítsa be az adatfolyam paramétereinek dinamikus értékeit a Paraméterek lapon. Dinamikus vagy literális paraméterértékek hozzárendeléséhez használhatja a folyamatkifejezés nyelvét vagy az adatfolyam-kifejezés nyelvét. További információ: Adatfolyam Paraméterek.
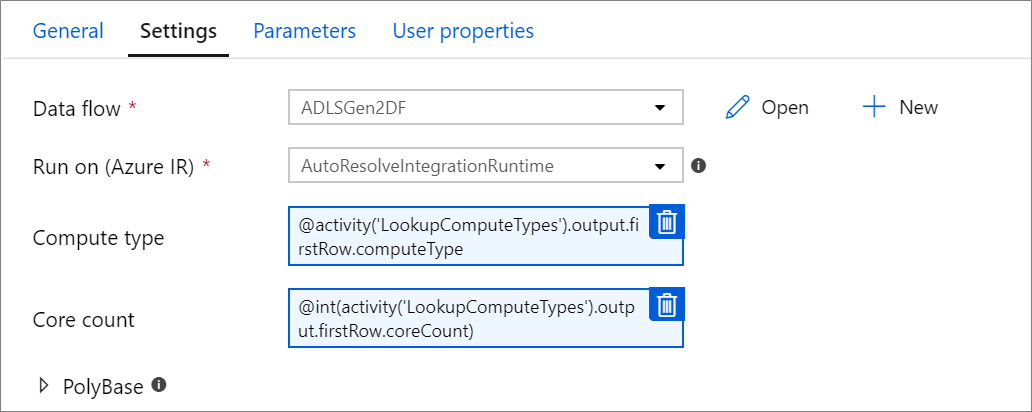
Paraméteres számítási tulajdonságok.
Az alapszámot vagy a számítási típust paraméterezheti, ha az automatikusan feloldott Azure integrációs modult használja, és megadja a compute.coreCount és a compute.computeType értékeit.
Adatfolyam tevékenység hibakeresése csővezetékben
Ha Adatfolyam tevékenységgel szeretne hibakeresési folyamatot futtatni, a felső sávon lévő Adatfolyam Hibakeresés csúszkával kell bekapcsolnia data flow hibakeresési módot. A hibakeresési mód lehetővé teszi az adatfolyam aktív Spark-fürtön való futtatását. További információ: Hibakeresési mód.

A hibakeresési folyamat az aktív hibakeresési fürtön fut, nem a Adatfolyam tevékenységbeállításokban megadott integrációs futtatókörnyezeten. A hibakeresési mód indításakor kiválaszthatja a hibakeresési számítási környezetet.
A Adatfolyam tevékenység figyelése
A Adatfolyam tevékenység speciális figyelési felülettel rendelkezik, ahol megtekintheti a particionálást, a fázisidőt és az adatsoradatokat. Nyissa meg a monitorozási panelt a Szemüveg ikonnal a Műveletek területen. További információ: Monitorozási Adatfolyam.
A Adatfolyam tevékenység eredményének felhasználása egy későbbi tevékenység során
Az adatfolyam-tevékenység metrikákat ad ki az egyes fogadókba írt sorok és az egyes forrásból beolvasott sorok számával kapcsolatban. Ezek az eredmények a tevékenységfuttatás eredményének output szakaszában jelennek meg. A visszaadott metrikák formátuma az alábbi json.
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
Ha például egy "sink1" nevű fogadóba írt sorok számát szeretné elérni egy "dataflowActivity" nevű tevékenységben, használja a következőt @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten: .
A "source1" nevű forrásból beolvasott sorok számának lekéréséhez, amelyet az adott fogadóban használtak, használja a @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead kifejezést.
Feljegyzés
Ha egy kimenethez nincs írt sor, az nem jelenik meg a metrikákban. A létezés a contains függvény használatával ellenőrizhető. Például ellenőrzi, contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') hogy írtak-e bármilyen sort a sink1-be.
Kapcsolódó tartalom
Lásd a támogatott vezérlési folyamatok tevékenységeit: