Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az Azure SQL Database kivételével minden forrás esetében ajánlott az aktuális particionálás használata a kiválasztott értékként. Ha minden más forrásrendszerből olvas, az adatfolyamok automatikusan egyenletesen particionálják az adatokat az adatok mérete alapján. Körülbelül minden 128 MB adat után létrejön egy új partíció. Az adatméret növekedésével a partíciók száma nő.
Az egyéni particionálás azután történik, hogy a Spark beolvassa az adatokat, és negatívan befolyásolja az adatfolyam teljesítményét. Mivel az adatok olvasáskor egyenletesen vannak particionálva, nem ajánlott, hacsak először nincs tisztában az adatok alakjával és számosságával.
Megjegyzés:
Az olvasási sebességet a forrásrendszer átviteli sebessége korlátozhatja.
Azure SQL Database-források
Az Azure SQL Database rendelkezik egy "Forrás" particionálás nevű egyedi particionálási lehetőséggel. A forrásparticionálás engedélyezése javíthatja az Azure SQL Database olvasási idejét a forrásrendszer párhuzamos kapcsolatainak engedélyezésével. Adja meg a partíciók számát és az adatok particionálásának módját. Használjon magas számosságú partícióoszlopot. Olyan lekérdezést is megadhat, amely megfelel a forrástábla particionálási sémájának.
Jótanács
A forrásparticionálás során az SQL Server I/O jelenti a szűk keresztmetszetet. Ha túl sok partíciót ad hozzá, azzal telítheti a forrásadatbázist. A beállítás használatakor általában négy vagy öt partíció ideális.
Forrásparticionálás
Elkülönítési szint
Az Azure SQL-forrásrendszer olvasásának elkülönítési szintje hatással van a teljesítményre. A "Nem véglegesített olvasás" lehetőség a leggyorsabb teljesítményt nyújtja, és megakadályozza az adatbázis zárolását. Az SQL-elkülönítési szintekről az elkülönítési szintek ismertetése című témakörben olvashat bővebben.
Olvasás lekérdezéssel
Az Azure SQL Database-ből táblázat vagy SQL-lekérdezés használatával olvashat. Ha SQL-lekérdezést hajt végre, a lekérdezésnek be kell fejeződnie, mielőtt az átalakítás elkezdődhetne. Az SQL-lekérdezések hasznosak lehetnek olyan műveletek leküldéséhez, amelyek gyorsabban hajthatók végre, és csökkenthetik az SQL Serverről beolvasott adatok mennyiségét, például a SELECT, a WHERE és a JOIN utasításokat. A műveletek leküldésekor nem tudja nyomon követni az átalakítások menetét és teljesítményét, mielőtt az adatok bekerülnek az adatfolyamba.
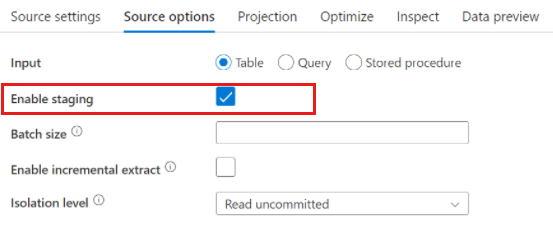
Azure Synapse Analytics-források
Az Azure Synapse Analytics használata esetén a forrásbeállítások között létezik az Előkészítés engedélyezése nevű beállítás. Ez lehetővé teszi, hogy a szolgáltatás a Synapse-en keresztül Staging olvasson, ami jelentősen javítja az olvasási teljesítményt a legjobb teljesítményű tömeges betöltési lehetőségek, például a CETAS és a COPY parancsok használatával. Az Staging engedélyezéshez meg kell adnia egy Azure Blob Storage- vagy Azure Data Lake Storage Gen2-előkészítési helyet az adatfolyam-tevékenység beállításai között.
Fájlalapú források
Parquet és határolt szöveg
Bár az adatfolyamok különböző fájltípusokat támogatnak, a Spark-natív parquet formátum ajánlott az optimális olvasási és írási idő érdekében.
Ha ugyanazt az adatfolyamot futtatja egy fájlkészleten, javasoljuk, hogy egy mappából olvasson, helyettesítő karaktereket használjon, vagy olvasson a fájlok listájából. Egyetlen adatfolyam-tevékenységfuttatással az összes fájl feldolgozható kötegben. A beállítások konfigurálásáról további információt az Azure Blob Storage-összekötő dokumentációjának Forrásátalakítási szakaszában talál.
Ha lehetséges, ne használja a For-Each tevékenységet adatfolyamok fájlhalmazon való futtatásához. Ez azt eredményezi, hogy minden for-each iteráció elindítja a saját Spark-fürtöt, ami gyakran szükségtelen és költséges lehet.
Beágyazott adathalmazok és megosztott adathalmazok
Az ADF- és Synapse-adatkészletek a gyárakban és munkaterületeken megosztott erőforrások. Ha azonban nagy számú forrásmappát és fájlt olvas elhatárolt szöveggel és JSON-forrásokkal, javíthatja az adatfolyam-fájlok felderítésének teljesítményét a "Felhasználó által előrejelzett séma" lehetőség beállításával a Projection | Sémabeállítások párbeszédpanel. Ez a beállítás kikapcsolja az ADF alapértelmezett séma automatikus észlelését, és jelentősen javítja a fájlfelderítés teljesítményét. Mindenképpen importálja a vetítést a beállítás megadása előtt, hogy az ADF rendelkezzen meglévő vetületi sémával. Ez a beállítás nem működik a sémaeltolódással.
Kapcsolódó tartalom
- Adatfolyamok teljesítményének áttekintése
- Szinkek optimalizálása
- Átalakítások optimalizálása
- Adatfolyamok használata csővezetékekben
Tekintse meg a teljesítményre vonatkozó egyéb adatfolyam-cikkeket: