Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Vonatkozik: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Ebben az oktatóanyagban a Azure portálon hozhat létre Azure Data Factory folyamatot. Ez a folyamat egy Spark-tevékenység és egy igény szerinti Azure HDInsight társított szolgáltatás használatával alakítja át az adatokat.
Az oktatóanyagban az alábbi lépéseket fogja végrehajtani:
- Adat-előállító létrehozása
- Hozzon létre egy Spark-tevékenységet használó folyamatot.
- Egy pipeline futtatásának kezdeményezése.
- A csővezeték futásának monitorozása.
Ha nem rendelkezik Azure előfizetéssel, a kezdés előtt hozzon létre egy felszabadító fiókot.
Előfeltételek
Megjegyzés
Javasoljuk, hogy az Azure Az PowerShell-modult használja a Azure használatához. Első lépésként lásd: Install Azure PowerShell. Az Az PowerShell-modulra való migrálásról az Migrate Azure PowerShell az AzureRM-ből az Az című témakörben olvashat.
- Azure tárolófiók. Létrehoz egy Python szkriptet és egy bemeneti fájlt, és feltölti őket a Azure Storage. A Spark-program kimenetét ebben a tárfiókban tárolja a rendszer. Az igény szerinti Spark-fürt ugyanazt a tárfiókot használja elsődleges tárolóként.
Megjegyzés
A HdInsight csak az általános célú, standard szintű tárfiókokat támogatja. Győződjön meg arról, hogy a fiók nem prémium szintű vagy nemcsak blobok tárolására szolgáló tárfiók.
- Azure PowerShell. Kövesse a Hogyan telepítse és konfigurálja Azure PowerShell utasításait.
Töltse fel a Python szkriptet a Blob Storage-fiókba
Hozzon létre egy Python WordCount_Spark.py nevű fájlt a következő tartalommal:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Cserélje le a <storageAccountName> elemet a Azure tárfiók nevére. Ezután mentse a fájlt.
Azure Blob Storage-ban hozzon létre egy adftutorial nevű tárolót, ha nem létezik.
Hozzon létre egy spark mappát.
Hozzon létre egy script almappát a spark mappában.
Töltse fel a WordCount_Spark.py fájlt a szkript almappába.
A bemeneti fájl feltöltése
- Hozzon létre egy minecraftstory.txt nevű fájlt némi szöveges tartalommal. A Spark-program megszámolja a szavak számát ebben a szövegben.
- Hozzon létre egy inputfiles nevű almappát a spark mappában.
- Töltse fel a minecraftstory.txt fájlt az inputfiles almappába.
Adat-előállító létrehozása
Kövesse a Gyors útmutató: Adatgyár létrehozása az Azure portál használatával című cikk lépéseit egy adatgyár létrehozásához, ha még nem rendelkezik ilyennel.
Társított szolgáltatások létrehozása
Ebben a szakaszban két társított szolgáltatást hoz létre:
- Egy Azure Storage társított szolgáltatás amely egy Azure storage fiókot csatol az adat-előállítóhoz. Ezt a tárterületet az igény szerinti HDInsight-fürt használja. Ez tartalmazza a futtatni kívánt Spark-szkriptet is.
- Egy igény szerinti HDInsight társított szolgáltatást. Azure Data Factory automatikusan létrehoz egy HDInsight-fürtöt, és lefuttatja a Spark alkalmazást. Ezt követően törli a HDInsight-fürtöt, miután a fürt egy előre beállított ideig tétlen volt.
Azure Storage társított szolgáltatás létrehozása
A kezdőlapon váltson a bal oldali panel Kezelés lapjára.
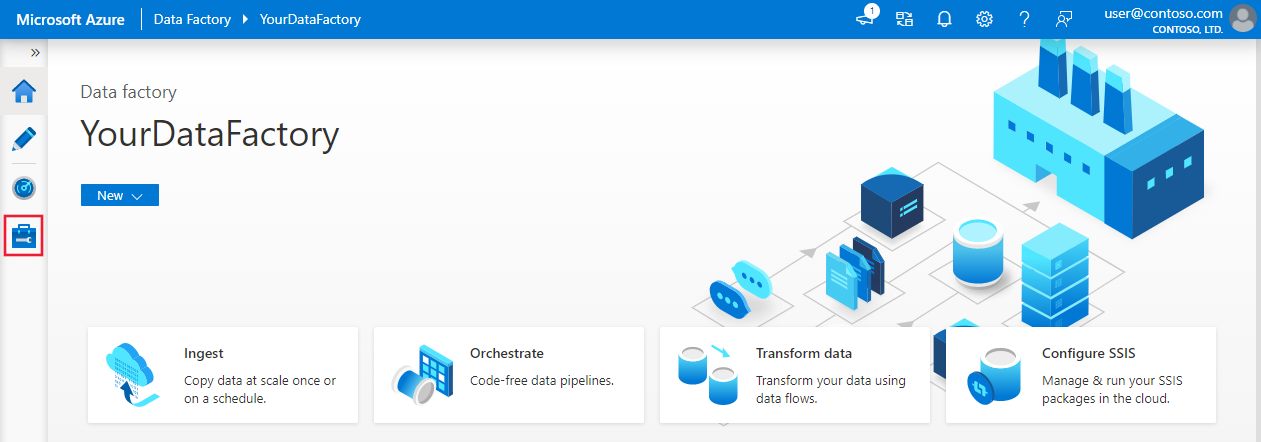
Kattintson az ablak alján látható Kapcsolatok, majd az + Új elemre.
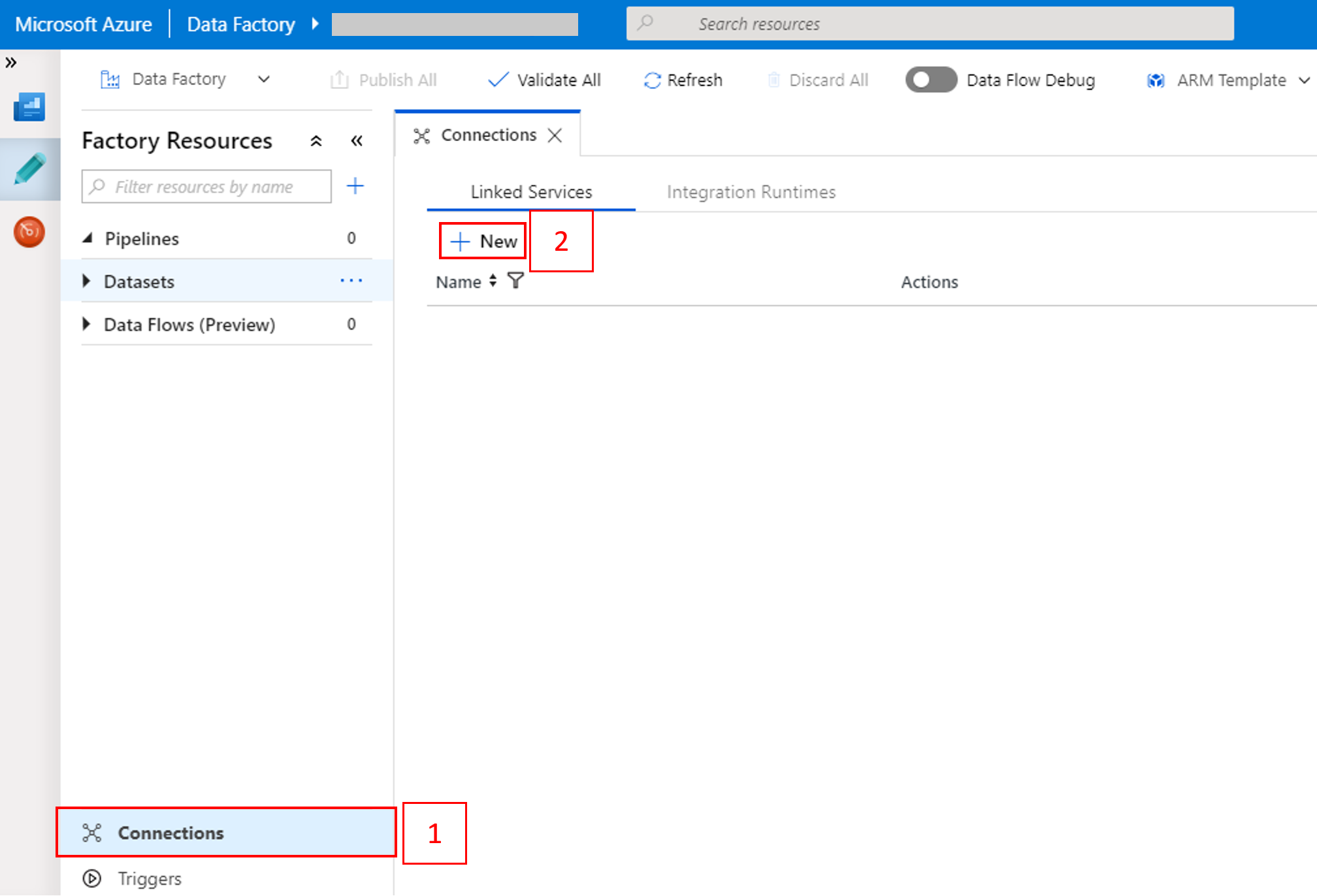
A New Linked Service ablakban válassza a Adattároló>Azure Blob Storage, majd a Continue lehetőséget.

A Storage-fiók neve mezőben válassza ki a nevet a listából, majd kattintson a Mentés gombra.
Igény szerinti HDInsight társított szolgáltatás létrehozása
Kattintson ismét az + Új gombra egy további társított szolgáltatás létrehozásához.
A New Linked Service ablakban válassza a Compute>Azure HDInsight, majd a Continue lehetőséget.

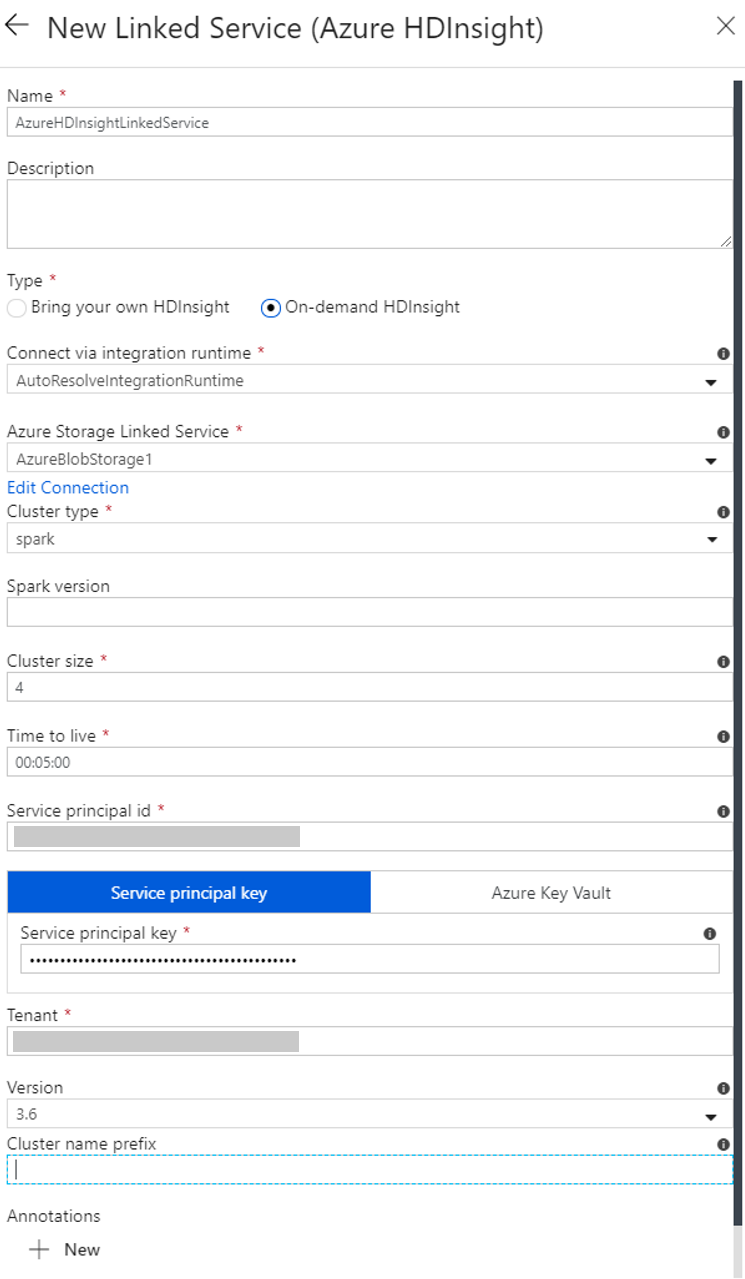
Az Új társított szolgáltatás ablakban végezze el az alábbi lépéseket:
a. A Név mezőben adja meg a következőt: AzureHDInsightLinkedService.
b. Győződjön meg arról, hogy az On-demand HDInsight (Igény szerinti HDInsight) van kiválasztva a Típus elemnél.
c. A Azure Storage társított szolgáltatás esetében válassza a AzureBlobStorage1 lehetőséget. Ezt a társított szolgáltatást korábban hozta létre. Ha másik nevet használt, adja meg a megfelelő nevet.
d. A fürttípus esetében válassza a spark-ot.
e. Adja meg a szolgáltatás-főazonosító azon azonosítóját, amely rendelkezik a HDInsight-fürt létrehozásához szükséges engedéllyel.
A szolgáltatás azonosítónak a cluster létrehozására szolgáló előfizetés vagy erőforráscsoport Közreműködő szerepkörének tagjává kell válnia. További információ: A Microsoft Entra alkalmazás és szolgáltatásnév létrehozása. A szolgáltatásnév azonosítója megegyezik az alkalmazásazonosítóval, a szolgáltatásnévkulcs pedig egyenértékű az ügyfélkód értékével.
f. A Szolgáltatásnév kulcsa mezőben adja meg a kulcsot.
g. Az Erőforráscsoport beállításnál válassza ki az adat-előállító létrehozásához használt erőforráscsoportot. Ekkor a Spark-fürt létrejön ebben az erőforráscsoportban.
h. Bontsa ki az OS type (Operációs rendszer típusa) elemet.
i. Adjon egy nevet a Cluster user name (Fürt felhasználóneve) mezőben.
j. Adja meg a Cluster password jelszót a felhasználónak.
k. Válassza a Befejezés lehetőséget.
Megjegyzés
Azure HDInsight korlátozza az egyes támogatott Azure régiókban használható magok teljes számát. Az igény szerinti HDInsight kapcsolt szolgáltatás esetében a HDInsight-fürt ugyanazon az Azure Storage helyen jön létre, amelyet elsődleges tárolóként használnak. Ellenőrizze, hogy a magkvótája elegendő-e a fürt sikeres létrehozásához. További információk: Fürtök beállítása a HDInsightban Hadoop, Spark, Kafka stb. használatával.
Folyamat létrehozása
Kattintson a + (plusz) gombra, majd a menüben válassza a Pipeline elemet.
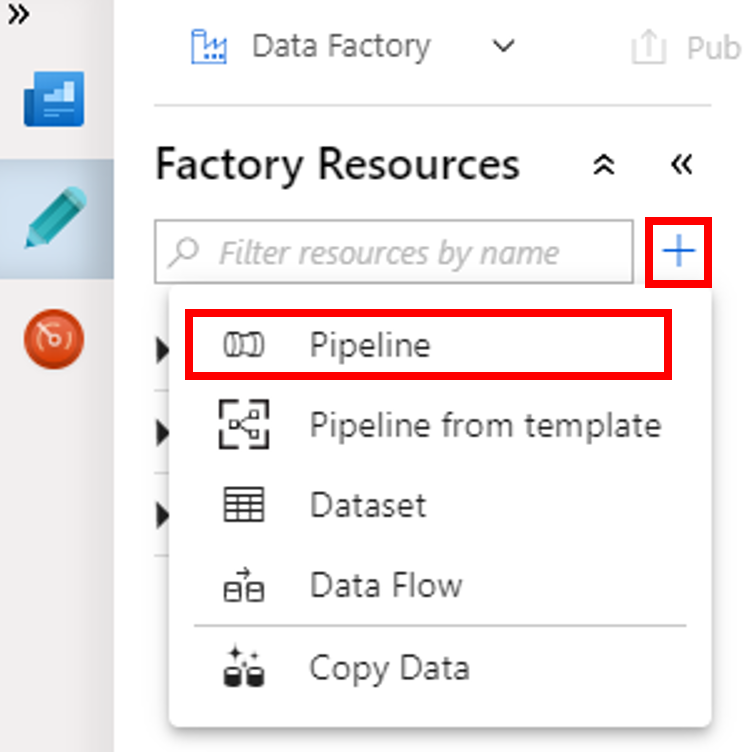
A Tevékenységek eszközkészletben bontsa ki a HDInsight elemet. Húzza a Spark tevékenységet a Tevékenységek eszközkészletből a folyamat tervezőfelületére.
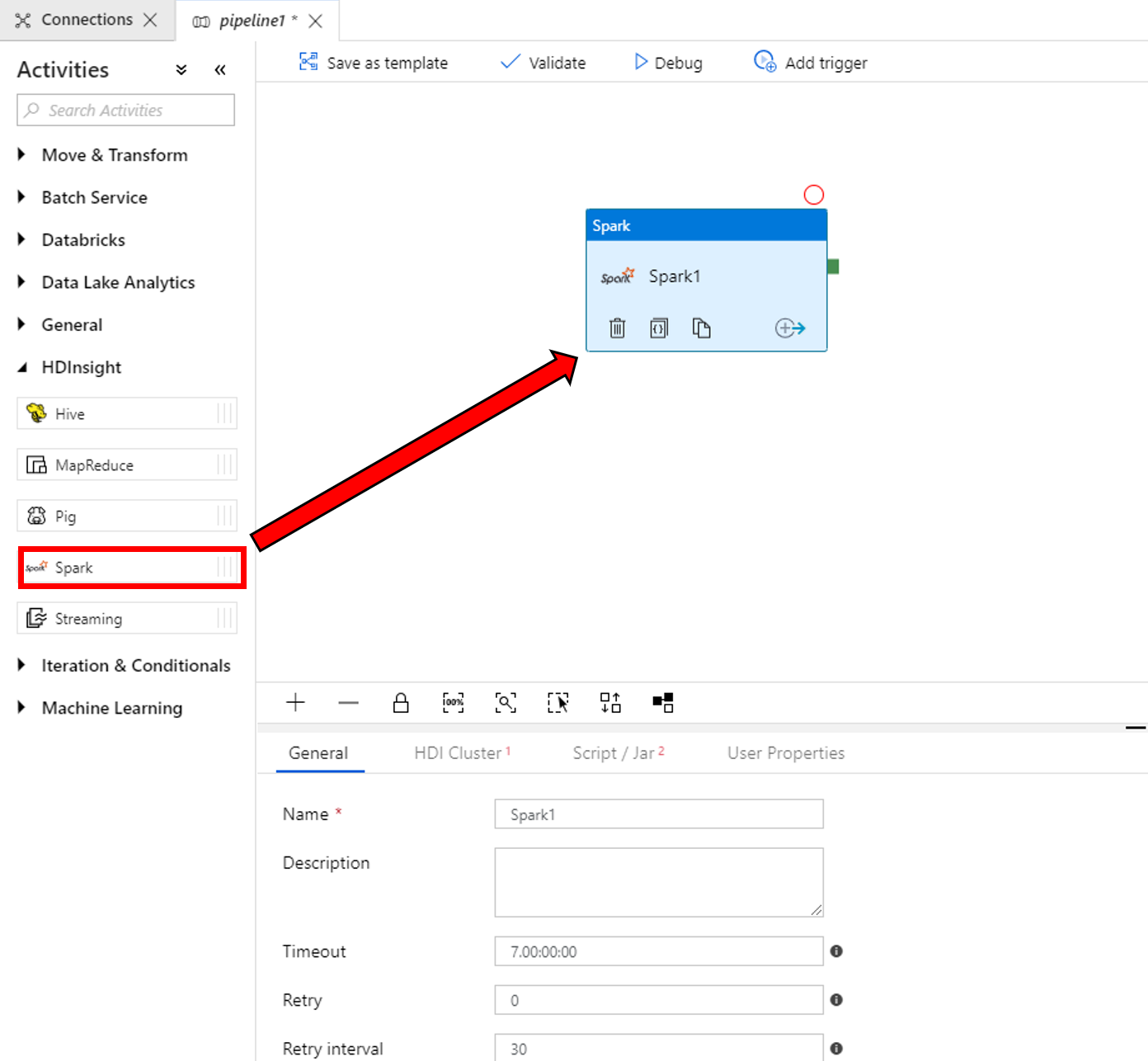
A Spark-tevékenység tulajdonságok ablakában végezze el az alábbi lépéseket:
a. Váltson a HDI Cluster fülre.
b. Válassza ki az előző lépésben létrehozott AzureHDInsightLinkedService elemet.
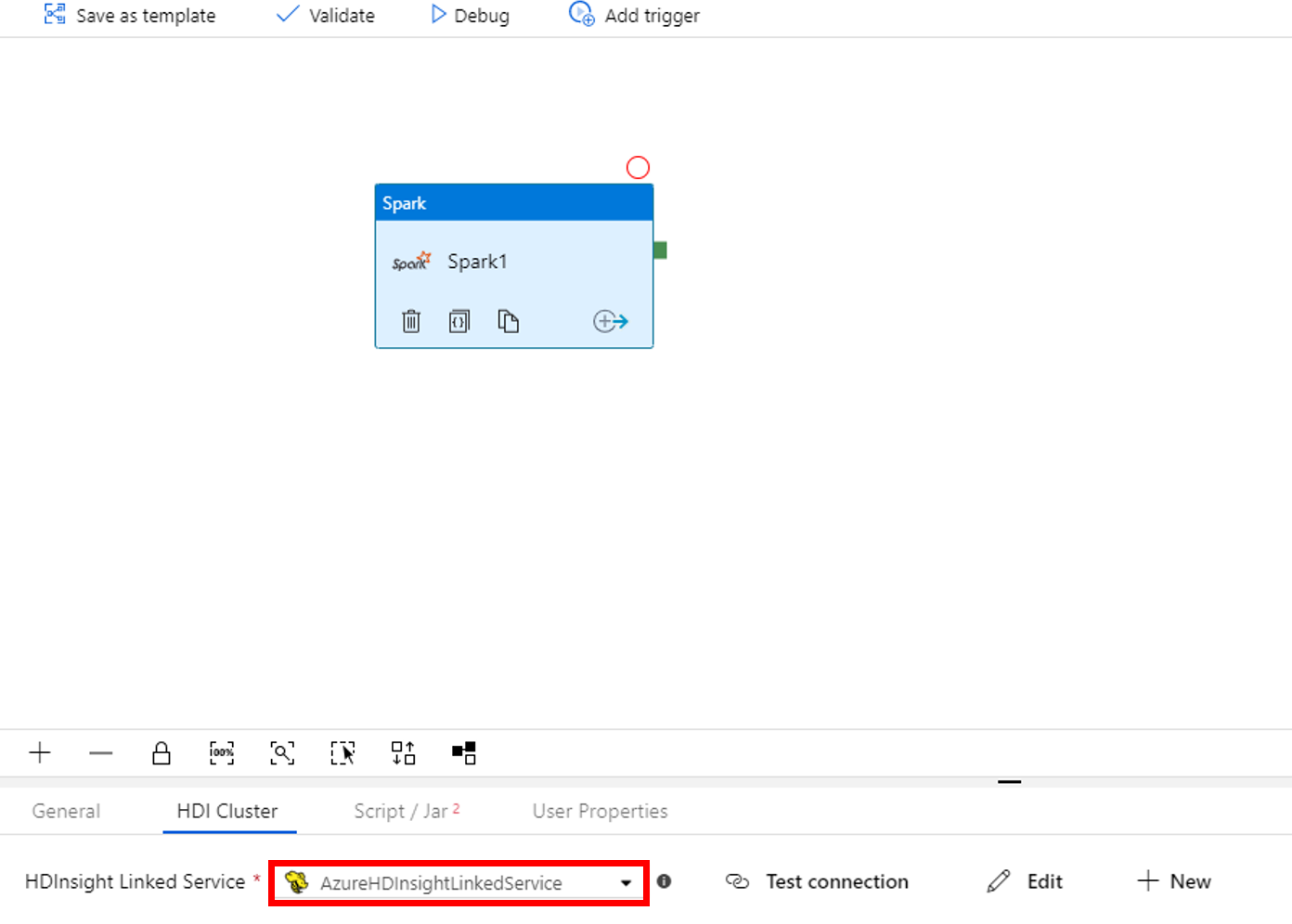
Váltson a Szkript/Jar lapra, és végezze el az alábbi lépéseket:
a. Feladathoz társított szolgáltatás esetén válassza az AzureBlobStorage1 lehetőséget.
b. Kattintson a Tallózás a tárolóban lehetőségre.

c. Keresse meg az adftutorial/spark/script mappát, válassza ki a WordCount_Spark.py fájlt, majd kattintson a Befejezés gombra.
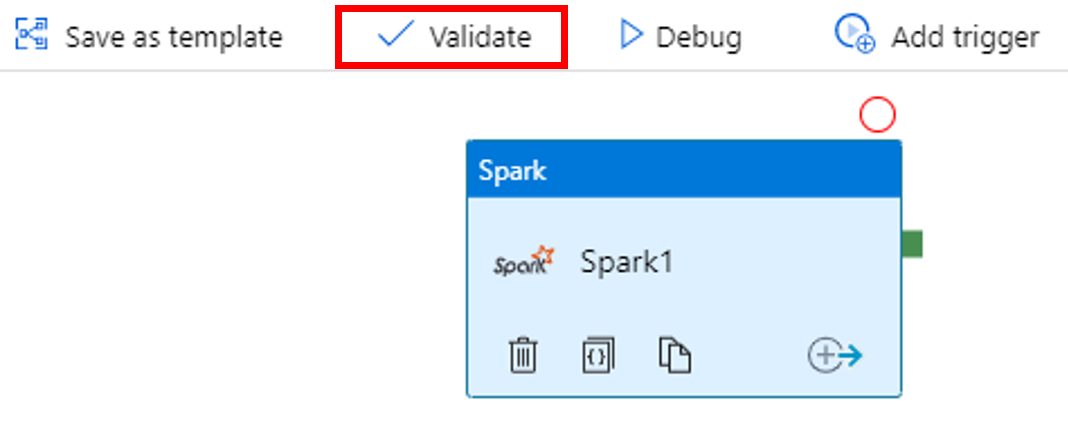
A folyamat érvényesítéséhez kattintson az Érvényesítés gombra az eszköztáron. Az érvényesítési ablak bezárásához kattintson a >> (jobbra mutató nyíl) gombra.
Válassza ki az Összes közzététele lehetőséget. A Data Factory felhasználói felülete entitásokat (társított szolgáltatásokat és folyamatot) tesz közzé a Azure Data Factory szolgáltatásban.
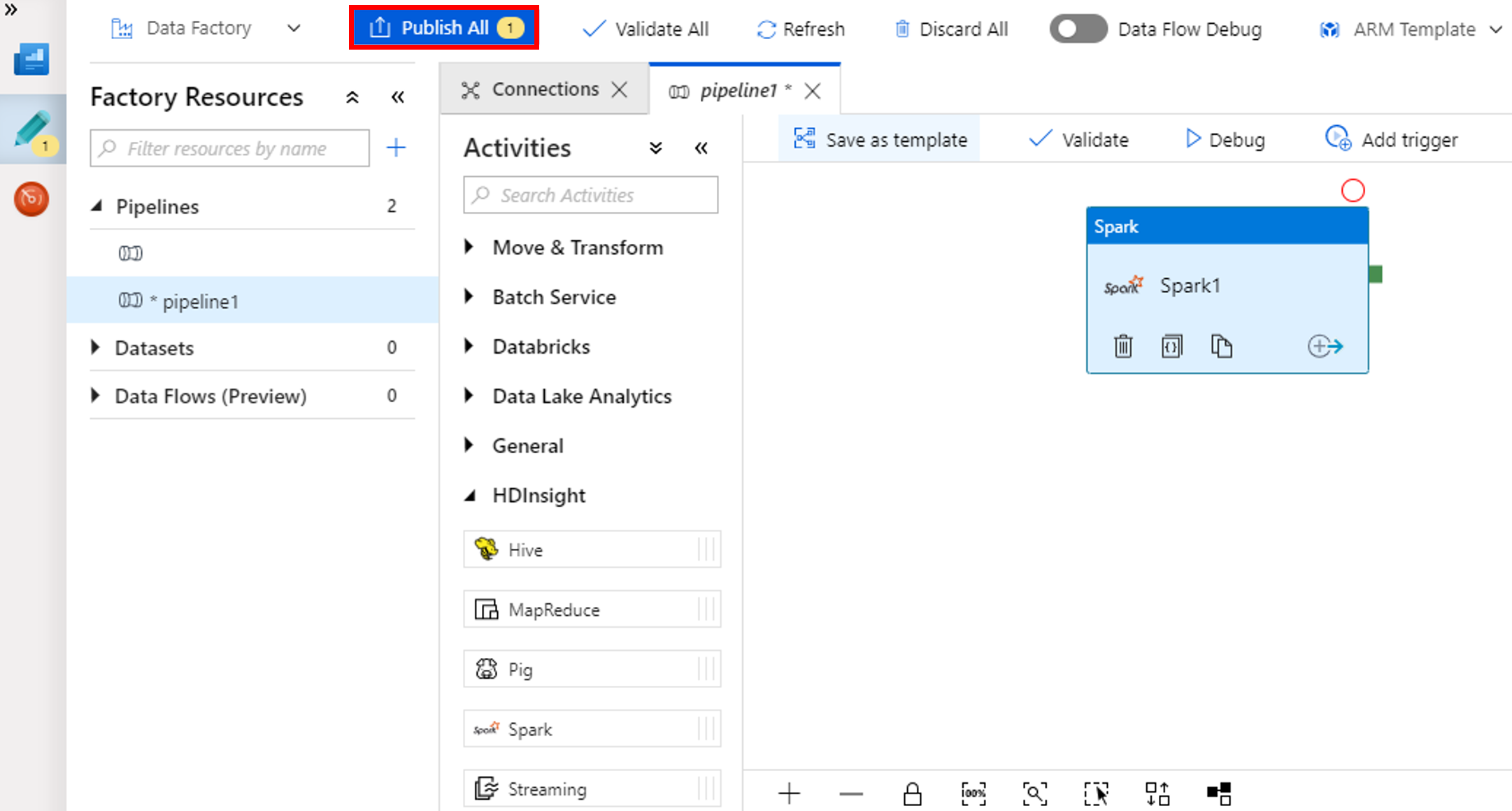
Folyamat futtatásának aktiválása
Válassza Eseményindító hozzáadása az eszköztáron, majd Indítsa el most.
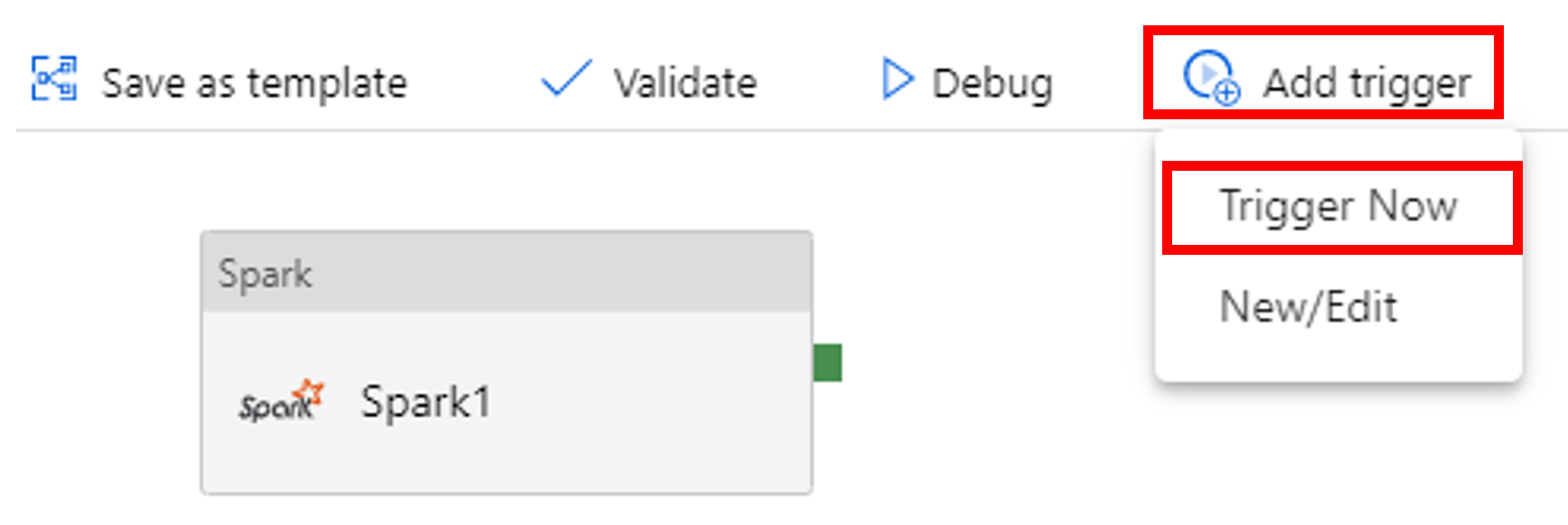
A folyamat futásának monitorozása
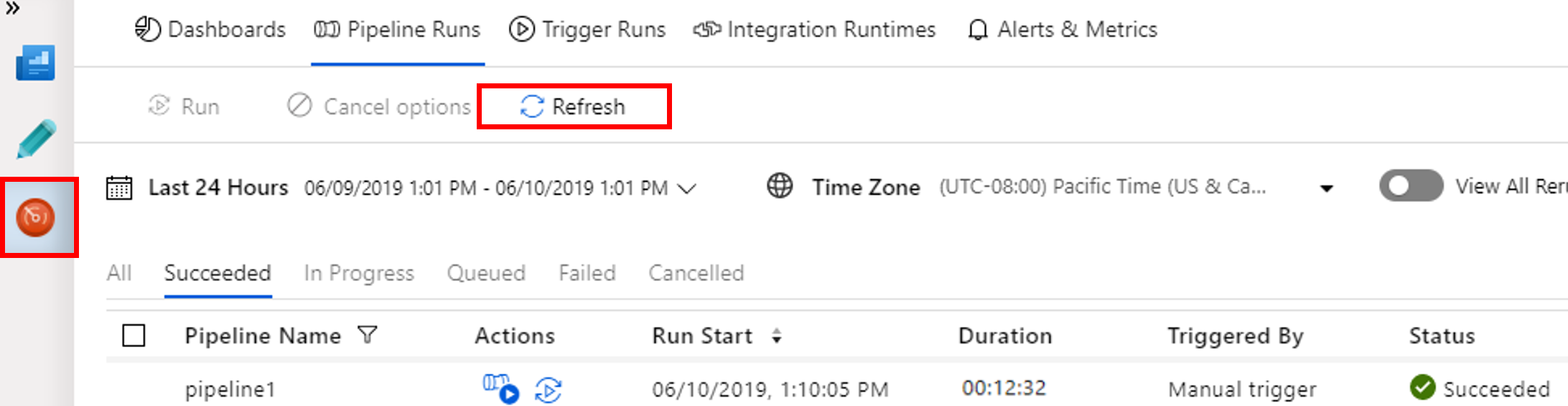
Váltson a Figyelés lapra. Ellenőrizze, hogy lát-e folyamatfuttatást. Spark-fürt létrehozása nagyjából 20 percet vesz igénybe.
Rendszeres időközönként kattintson a Frissítés gombra a folyamat futási állapotának ellenőrzéséhez.
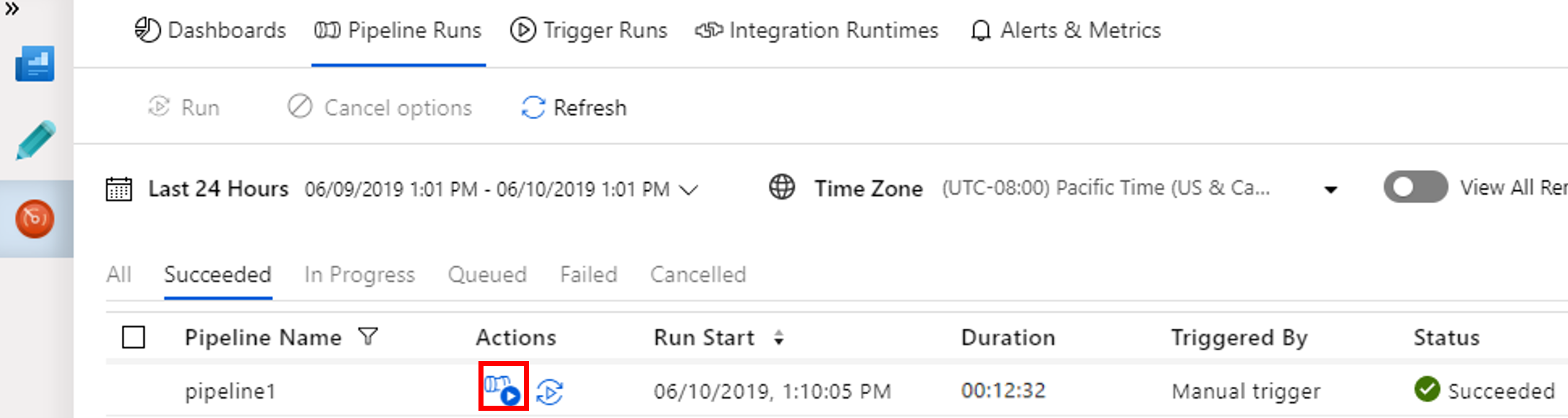
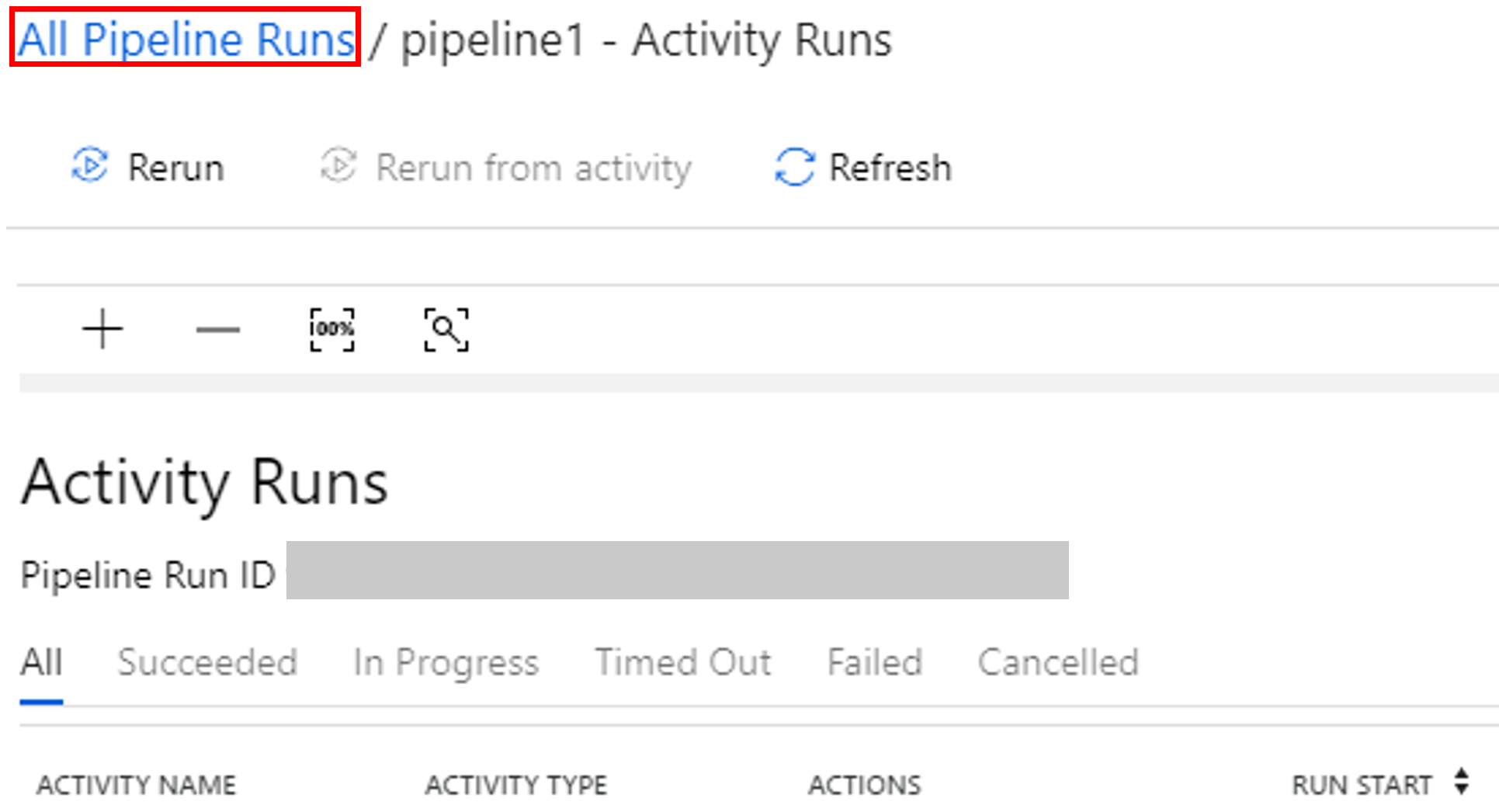
A folyamat futásához kapcsolódó tevékenységfuttatások megtekintéséhez kattintson a Tevékenységfuttatások megtekintése elemre a Műveletek oszlopban.
A folyamatfuttatások nézetre a tetején található Minden folyamatfuttatás hivatkozás kiválasztásával válthat vissza.
Kimenet ellenőrzése
Ellenőrizze, hogy a kimeneti fájl az adftutorial tároló spark/outputfiles/wordcount mappájában van-e létrehozva.
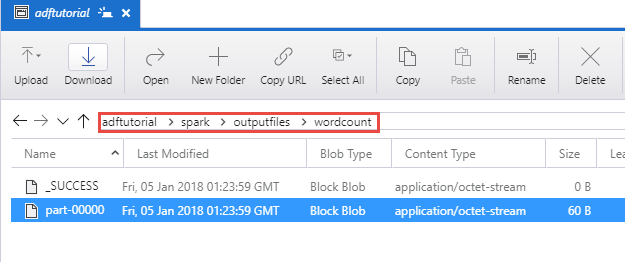
A fájlban a bemeneti szövegfájl összes szavának szerepelnie kell, valamint annak is, hogy az adott szó hányszor szerepel a fájlban. Példa:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Kapcsolódó tartalom
A mintában szereplő folyamat egy Spark-tevékenységgel és egy igény szerinti HDInsight társított szolgáltatással alakítja át az adatokat. Megtanulta végrehajtani az alábbi műveleteket:
- Adat-előállító létrehozása
- Hozzon létre egy Spark-tevékenységet használó folyamatot.
- Egy pipeline futtatásának kezdeményezése.
- A csővezeték futásának monitorozása.
Ha meg szeretné tudni, hogyan alakíthatja át az adatokat hive-szkript futtatásával egy virtuális hálózaton található Azure HDInsight fürtön, folytassa a következő oktatóanyagtal: