Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Tip
Microsoft Fabric Data Warehouse egy nagyvállalati szintű relációs raktár egy Data Lake-alaprendszeren, jövőre kész architektúrával, beépített AI-vel és új funkciókkal. Ha még nem ismerkedik adattárházzal, kezdje a Fabric Data Warehouse. A meglévő dedikált SQL-készlet számítási feladatai frissíthetők Fabric az adatelemzés, a valós idejű elemzés és a jelentéskészítés új képességeinek eléréséhez.
Ez a csalólap hasznos tippeket és ajánlott eljárásokat nyújt a dedikált SQL-készlet (korábbi nevén SQL DW) megoldások létrehozásához.
Az alábbi ábra egy dedikált SQL-készlettel (korábban SQL DW) rendelkező adattárház tervezésének folyamatát mutatja be:
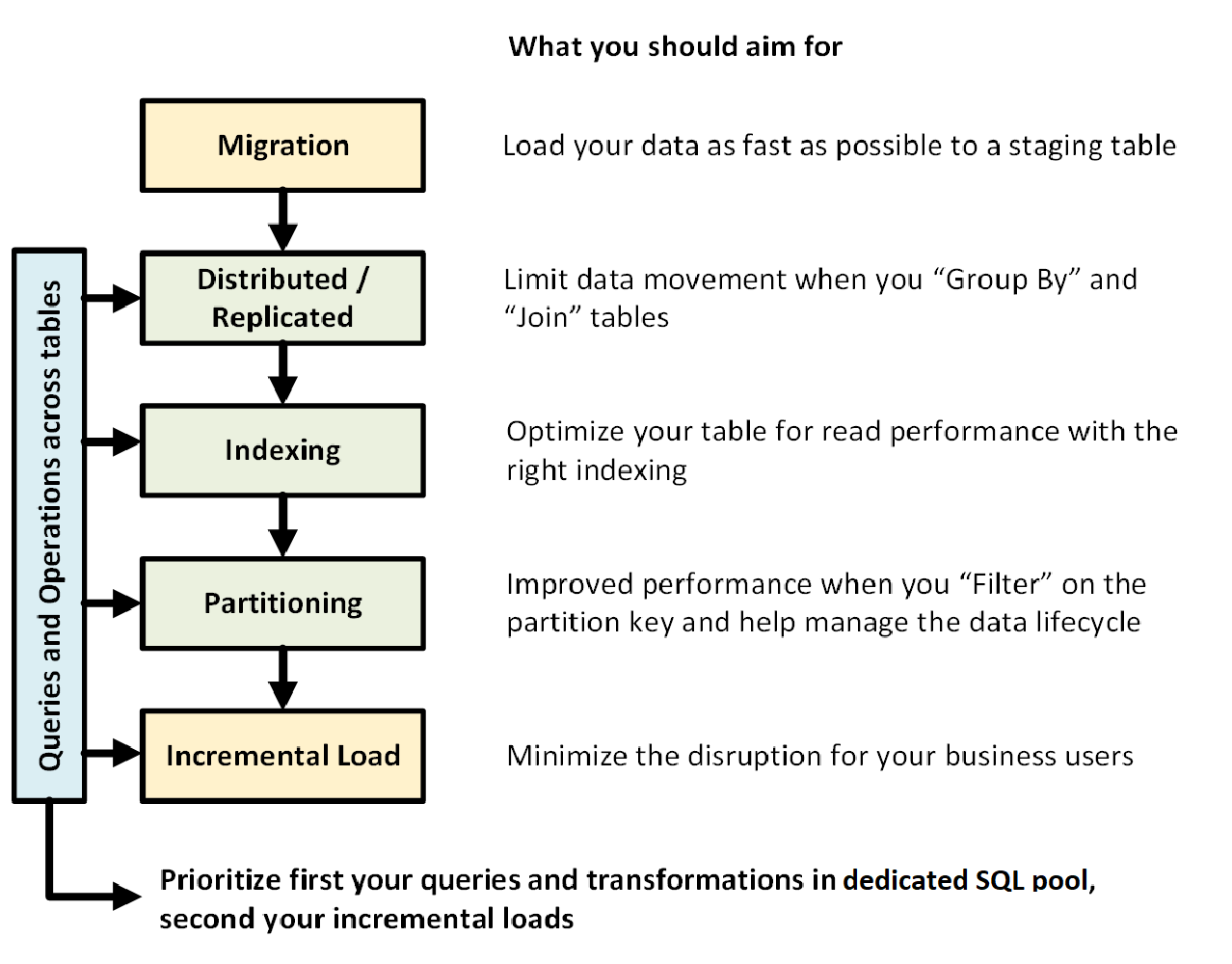
Táblák közötti lekérdezések és műveletek
Ha előre ismeri az adattárházban futtatandó elsődleges műveleteket és lekérdezéseket, rangsorolhatja az adattárház architektúráját ezekhez a műveletekhez. Ezek a lekérdezések és műveletek a következők lehetnek:
- Egy vagy két ténytábla dimenziótáblákkal való összekapcsolása, a kombinált tábla szűrése, majd az eredmények hozzáfűzése egy adatpiachoz.
- Nagy vagy kis mértékű frissítések alkalmazása az adatértékesítésekben.
- Csak adatok hozzáfűzése a táblákhoz.
A műveletek típusainak előzetes ismerete segít optimalizálni a táblák kialakítását.
Adatok áttelepítése
Először töltse be az adatokat Azure Data Lake Storage vagy Azure Blob Storage. Ezután a COPY utasítással töltse be az adatokat az előkészítési táblákba. Használja a következő konfigurációt:
| Dizájn | Ajánlás |
|---|---|
| Disztribúció | Körkörös ütemezés |
| Indexelés | Heap |
| Particionálás | Egyik sem |
| Erőforrásosztály | largerc vagy xlargerc |
További információ az adatmigrálásról, az adatok betöltéséről, valamint a kinyerési, betöltési és átalakítási (ELT) folyamatról.
Elosztott vagy replikált táblák
A táblázat tulajdonságaitól függően használja az alábbi stratégiákat:
| Típus | Kiválóan alkalmas... | Vigyázz, ha... |
|---|---|---|
| Replikált | * Kis méretű táblák csillagsémában, tömörítés után kevesebb mint 2 GB tárterülettel (~5x tömörítés) | * Sok írási tranzakció van a táblán (például beszúrás, upsert, törlés, frissítés) * Gyakran módosítja a Data Warehouse Units (DWU) konfigurálását * Csak 2-3 oszlopot használ, de a táblázat sok oszlopot tartalmaz * Replikált tábla indexelése |
| Round Robin (alapértelmezett) | * Ideiglenes/tároló tábla * Nincs nyilvánvaló csatlakozási kulcs vagy jó jelölt oszlop |
* A teljesítmény az adatáthelyezés miatt lassú |
| Hash | * Ténytáblák * Nagyméretű dimenziótáblák |
* A terjesztési kulcs nem frissíthető |
Tips:
- Kezdje a Round Robin használatával, de törekedjen egy kivonatterjesztési stratégiára, hogy kihasználhassa a nagymértékben párhuzamos architektúra előnyeit.
- Győződjön meg arról, hogy a gyakori kivonatkulcsok adatformátuma megegyezik.
- Ne ossza meg varchar formátumban.
- Az olyan dimenziótáblák, amelyek közös hashkulcsot használnak egy ténytábla gyakori illesztési műveleteihez, hash alapon eloszthatók.
- A sys.dm_pdw_nodes_db_partition_stats használatával elemezheti az adatok esetleges eltéréseit.
- A sys.dm_pdw_request_steps használatával elemezheti a lekérdezések mögötti adatmozgásokat, figyelheti az időközvetítést és a shuffle műveleteket. Ez hasznos a terjesztési stratégia áttekintéséhez.
További információ a replikált táblákról és az elosztott táblákról.
Táblázat indexelése
Az indexelés hasznos a táblázatok gyors olvasásához. A technológiák egyedi készlete áll rendelkezésre, amelyeket az igényeinek megfelelően használhat:
| Típus | Kiválóan alkalmas... | Vigyázz, ha... |
|---|---|---|
| Heap | * Átmeneti/ideiglenes tábla * Kis táblák kis kereséssel |
* Minden keresés megvizsgálja a teljes táblázatot |
| Klaszterezett index | * Táblázatok akár 100 millió sorral * Nagy táblák (több mint 100 millió sor), amelyekben csak 1-2 oszlop van erősen használva |
* Replikált táblában használatos * Összetett lekérdezésekkel rendelkezik, amelyek több csatlakozást és csoportosítási műveleteket foglalnak magukban * Frissítéseket készít az indexelt oszlopokon: memóriát igényel |
| Fürtözött oszlopalapú index (CCI) (alapértelmezett) | * Nagy táblák (több mint 100 millió sor) | * Replikált táblában használatos * Nagyszabású frissítési műveleteket hajt végre a tábláján * Túlságosan felosztja a tábláját: a sorcsoportok nem terjednek át a különböző elosztási csomópontokra és partíciókra |
Tips:
- A fürtözött index fölött érdemes lehet egy nem fürtözött indexet hozzáadni egy olyan oszlophoz, amelyet intenzíven használnak szűrésre.
- Legyen óvatos, hogyan kezelheti a memóriát egy táblázatban a CCI használatával. Az adatok betöltésekor azt szeretné, hogy a felhasználó (vagy a lekérdezés) kihasználhassa a nagy erőforrásosztály előnyeit. Ügyeljen arra, hogy elkerülje a vágást, és ne hozzon létre sok kis tömörített sorcsoportot.
- A Gen2-ben a CCI-táblák helyileg gyorsítótárazva vannak a számítási csomópontokon a teljesítmény maximalizálása érdekében.
- A CCI esetében a lassú teljesítmény a sorcsoportok gyenge tömörítése miatt fordulhat elő. Ha ez történik, újraépítheti vagy átrendezheti a CCI-t. Tömörített sorcsoportokonként legalább 100 000 sort szeretne. Az ideális egy sorcsoportban 1 millió sor.
- A növekményes terhelés gyakorisága és mérete alapján automatizálnia kellene az indexek átrendezését vagy újraépítését. A tavaszi tisztítás mindig hasznos.
- Legyen stratégiája, amikor sorcsoportot szeretne módosítani. Mekkoraak a nyitott sorcsoportok? Mennyi adatot fog betölteni a következő napokban?
További információ az indexekről.
Particionálás
A táblát particionálhatja, ha nagy ténytáblával rendelkezik (több mint 1 milliárd sor). Az esetek 99%-ában a partíciókulcsnak dátumon kell alapulnia.
Az ELT-t igénylő előkészítési táblákkal kihasználhatja a particionálás előnyeit. Megkönnyíti az adatok életciklusának kezelését. Ügyeljen arra, hogy a tény- vagy az elosztó tábla ne legyen túlparticionálva, különösen fürtözött oszlop-tároló index esetén.
További információ a partíciókról.
Növekményes terhelés
Ha növekményesen szeretné betölteni az adatokat, először győződjön meg arról, hogy nagyobb erőforrásosztályokat foglal le az adatok betöltéséhez. Ez különösen akkor fontos, ha fürtözött oszlopalapú indexekkel rendelkező táblákba tölt be. További részletekért tekintse meg az erőforrásosztályokat .
Javasoljuk, hogy a PolyBase és az ADF V2 használatával automatizálja az ELT-pipeline-okat az adattárházba.
Az előzményadatok nagy mennyiségű frissítéséhez érdemes lehet CTAS-t használni a táblában tartani kívánt adatok megírására az INSERT, UPDATE és DELETE helyett.
Statisztikák karbantartása
Fontos frissíteni a statisztikákat, mivel jelentős változások történnek az adatokban. Tekintse meg a frissítési statisztikákat annak megállapításához, hogy jelentős változások történtek-e. A frissített statisztikák optimalizálják a lekérdezési terveket. Ha úgy találja, hogy túl sokáig tart az összes statisztika karbantartása, szelektívebb legyen, hogy mely oszlopok rendelkeznek statisztikával.
A frissítések gyakoriságát is meghatározhatja. Előfordulhat például, hogy naponta frissíteni szeretné a dátumoszlopokat, ahol új értékeket adhat hozzá. A leghasznosabb az illesztésekben részt vevő oszlopokra, a WHERE záradékban használt oszlopokra és a GROUP BY-ban található oszlopokra vonatkozó statisztikák.
További információ a statisztikákról.
Erőforrásosztály
Az erőforráscsoportok a lekérdezések memóriáinak lefoglalására szolgálnak. Ha több memóriára van szüksége a lekérdezési vagy betöltési sebesség javításához, magasabb erőforrásosztályokat kell lefoglalnia. Másrészt, a nagyobb erőforrás-kategóriák használata hatással van az egyidejűségre. Ezt figyelembe kell vennie, mielőtt az összes felhasználót áthelyezi egy nagy erőforrásosztályba.
Ha azt tapasztalja, hogy a lekérdezések túl hosszúak, ellenőrizze, hogy a felhasználók nem nagy erőforrásosztályokban futnak-e. A nagy erőforrásosztályok számos egyidejűségi tárolóhelyet használnak fel. Más lekérdezéseket sorra állíthatnak.
Végül, a Gen2 dedikált SQL-készlet (korábbi nevén SQL DW) használatával minden erőforrásosztály 2,5-szer több memóriát kap, mint a Gen1.
További információ az erőforrásosztályok és az egyidejűség használatáról.
Költség csökkentése
A Azure Synapse egyik fő funkciója a számítási erőforrások kezelése. Ha nem használja, szüneteltetheti a dedikált SQL-készletet (korábban SQL DW), ami leállítja a számítási erőforrások számlázását. Az erőforrásokat skálázhatja a teljesítményigények kielégítése érdekében. A szüneteltetéshez használja a Azure portált vagy PowerShell. A méretezéshez használja a Azure portált, PowerShell, T-SQL vagy REST API.
Automatikus skálázás az Azure Functions segítségével a kívánt időpontban mostantól.

Az architektúra optimalizálása a teljesítményhez
Javasoljuk, hogy vegye fontolóra az SQL Database-et és az Azure Analysis Services-t egy hub-and-spoke architektúrában. Ez a megoldás biztosíthatja a számítási feladatok elkülönítését a különböző felhasználói csoportok között, miközben az SQL Database és a Azure Analysis Services speciális biztonsági funkcióit is használhatja. Ezzel a módszerrel korlátlan egyidejűséget biztosíthat a felhasználóknak.
További információ a tipikus architektúrákról, amelyek kihasználják a dedikált SQL-készlet (korábbi nevén SQL DW) előnyeit, az Azure Synapse Analytics során.
Csomópontok üzembe helyezése SQL-adatbázisokban dedikált SQL-készletből (korábban SQL DW):