Egyéni besorolási modell létrehozása és betanítása
Ez a tartalom a következőre vonatkozik:![]() v4.0 (előzetes verzió) | Korábbi verziók:
v4.0 (előzetes verzió) | Korábbi verziók: ![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Fontos
Az egyéni besorolási modell jelenleg nyilvános előzetes verzióban érhető el. A funkciók, a megközelítések és a folyamatok az általános rendelkezésre állás (GA) előtt változhatnak a felhasználói visszajelzések alapján.
Az egyéni besorolási modellek osztályozhatják egy bemeneti fájl minden oldalát egy vagy több dokumentum azonosításához. Az osztályozómodellek több dokumentumot vagy egy dokumentum több példányát is azonosíthatják a bemeneti fájlban. A Dokumentumintelligencia egyéni modelljeihez dokumentumosztályonként legfeljebb öt betanítási dokumentum szükséges az első lépésekhez. Az egyéni besorolási modellek betanításának megkezdéséhez minden osztályhoz és két dokumentumosztályhoz legalább öt dokumentumra van szükség.
Egyéni besorolási modell bemeneti követelményei
Győződjön meg arról, hogy a betanítási adatkészlet megfelel a Dokumentumintelligencia bemeneti követelményeinek.
Támogatott fájlformátumok:
Modell PDF Kép: JPEG/JPG,PNG,BMP,TIFFHEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLOlvasás ✔ ✔ ✔ Elrendezés ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Általános dokumentum ✔ ✔ Előre összeállított ✔ ✔ Egyéni kinyerés ✔ ✔ Egyéni besorolás ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) A legjobb eredmény érdekében dokumentumonként egy tiszta fényképet vagy kiváló minőségű vizsgálatot biztosít.
PDF és TIFF esetén legfeljebb 2000 oldal dolgozható fel (ingyenes szintű előfizetéssel csak az első két oldal dolgozható fel).
A dokumentumok elemzéséhez használt fájlméret 500 MB a fizetős (S0) szint, az
4ingyenes (F0) szint esetén pedig MB.A képméreteknek 50 képpont x 50 képpont és 10 000 képpont x 10 000 képpont között kell lenniük.
Ha a PDF-eket jelszó védi, akkor beküldés előtt el kell távolítania a védelmet.
A kinyerni kívánt szöveg minimális magassága 12 képpont egy 1024 x 768 képpontos képhez. Ez a dimenzió körülbelül
8150 pont/hüvelyk (DPI) pontszövegnek felel meg.Egyéni modell betanítása esetén a betanítási adatok oldalainak maximális száma az egyéni sablonmodell esetében 500, az egyéni neurális modell esetében pedig 50 000.
Egyéni extrakciós modell betanítása esetén a betanítási adatok teljes mérete 50 MB a sablonmodellhez, a neurális modellhez pedig
1GB.Egyéni besorolási modell betanítása esetén a betanítási adatok
1teljes mérete GB, legfeljebb 10 000 oldal. A 2024-07-31-es és újabb verziókban a betanítási adatok2teljes mérete GB, legfeljebb 10 000 oldal.
Betanítási adattippek
Az alábbi tippeket követve tovább optimalizálhatja az adathalmazt a betanításhoz:
Ha lehetséges, képes dokumentumok helyett használjon szöveges PDF-dokumentumokat. A beolvasott PDF-dokumentumokat képként kezeli a rendszer.
Ha az űrlapképek alacsonyabb minőségűek, használjon nagyobb adathalmazt (például 10–15 képet).
Betanítási adatok feltöltése
Miután összeállította a betanításhoz szükséges űrlapokat vagy dokumentumokat, fel kell töltenie egy Azure Blob Storage-tárolóba. Ha nem tudja, hogyan hozhat létre Azure Storage-fiókot egy tárolóval, kövesse az Azure Portal Azure Storage rövid útmutatóját. Az ingyenes tarifacsomag (F0) használatával kipróbálhatja a szolgáltatást, és később frissíthet egy fizetős szintre az éles környezetben. Ha az adathalmaz mappákként van rendszerezve, őrizze meg ezt a struktúrát, mivel a Studio a mappák neveivel egyszerűsítheti a címkézési folyamatot.
Besorolási projekt létrehozása a Document Intelligence Studióban
A Document Intelligence Studio biztosítja és vezényeli az adathalmaz befejezéséhez és a modell betanásához szükséges ÖSSZES API-hívást.
Először navigáljon a Document Intelligence Studióba. A Studio első használatakor inicializálnia kell az előfizetést, az erőforráscsoportot és az erőforrást. Ezután kövesse az egyéni projektek előfeltételeit, hogy konfigurálja a Studiót a betanítási adatkészlet eléréséhez.
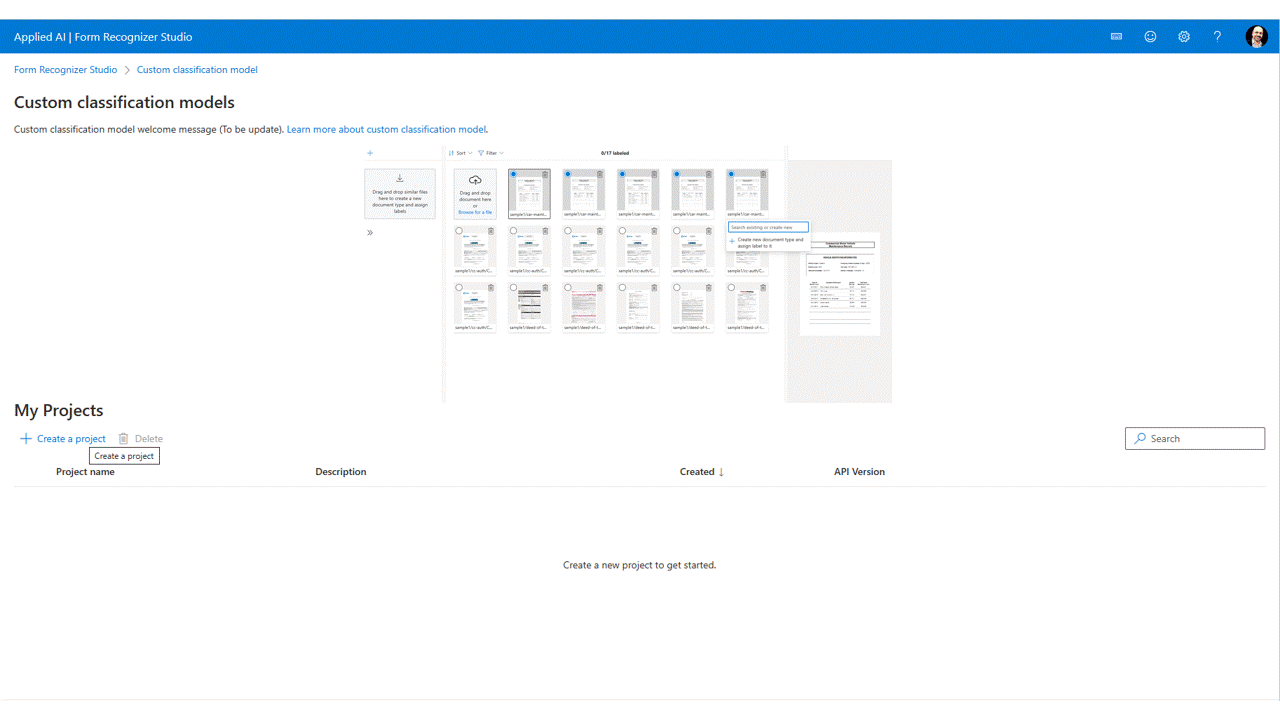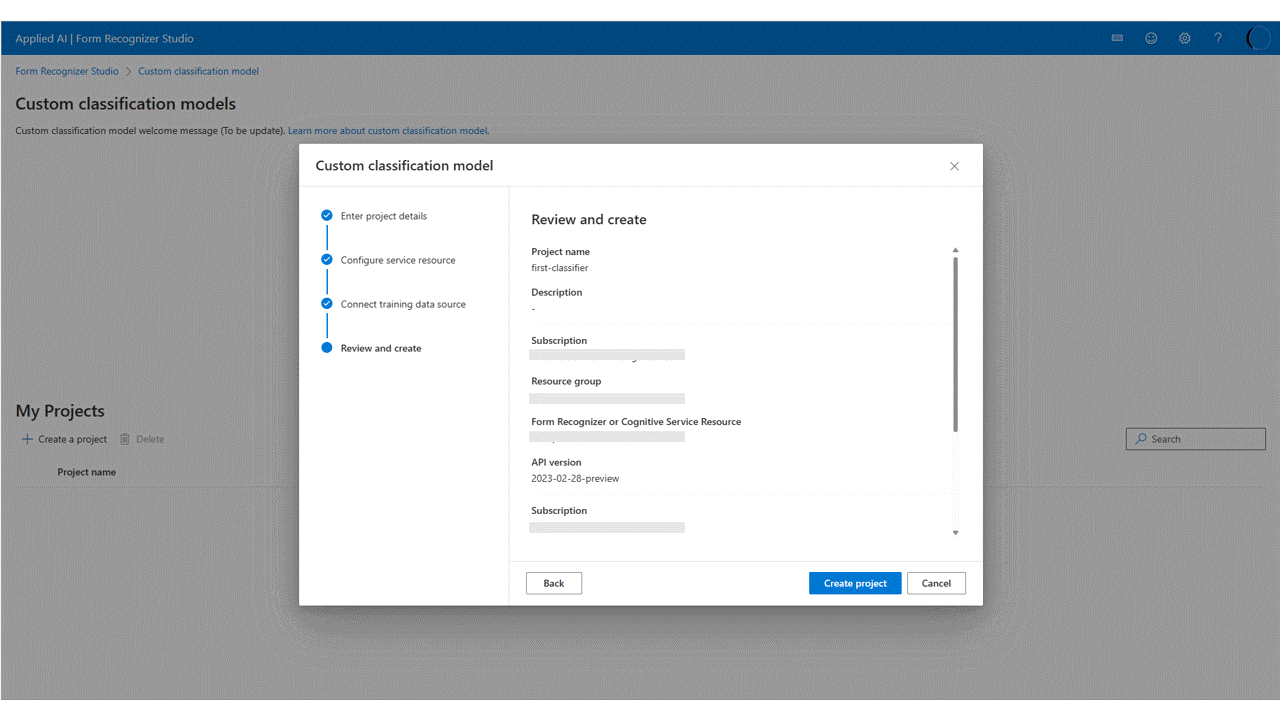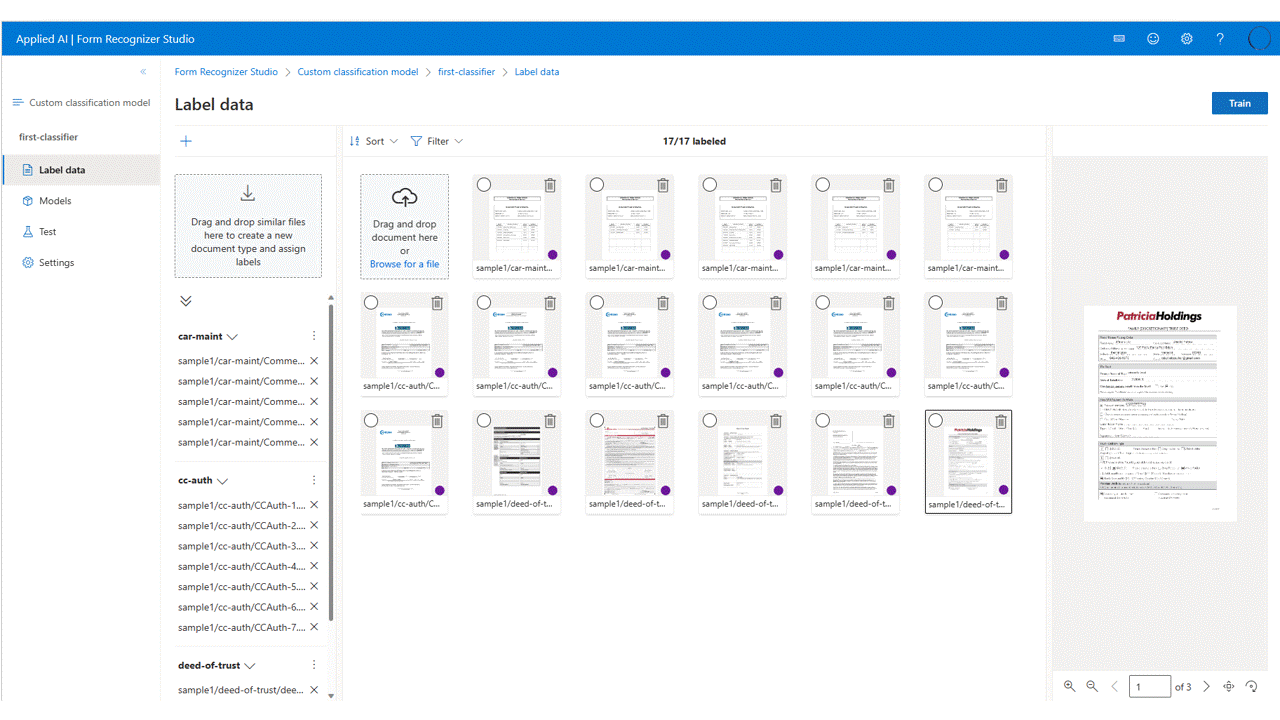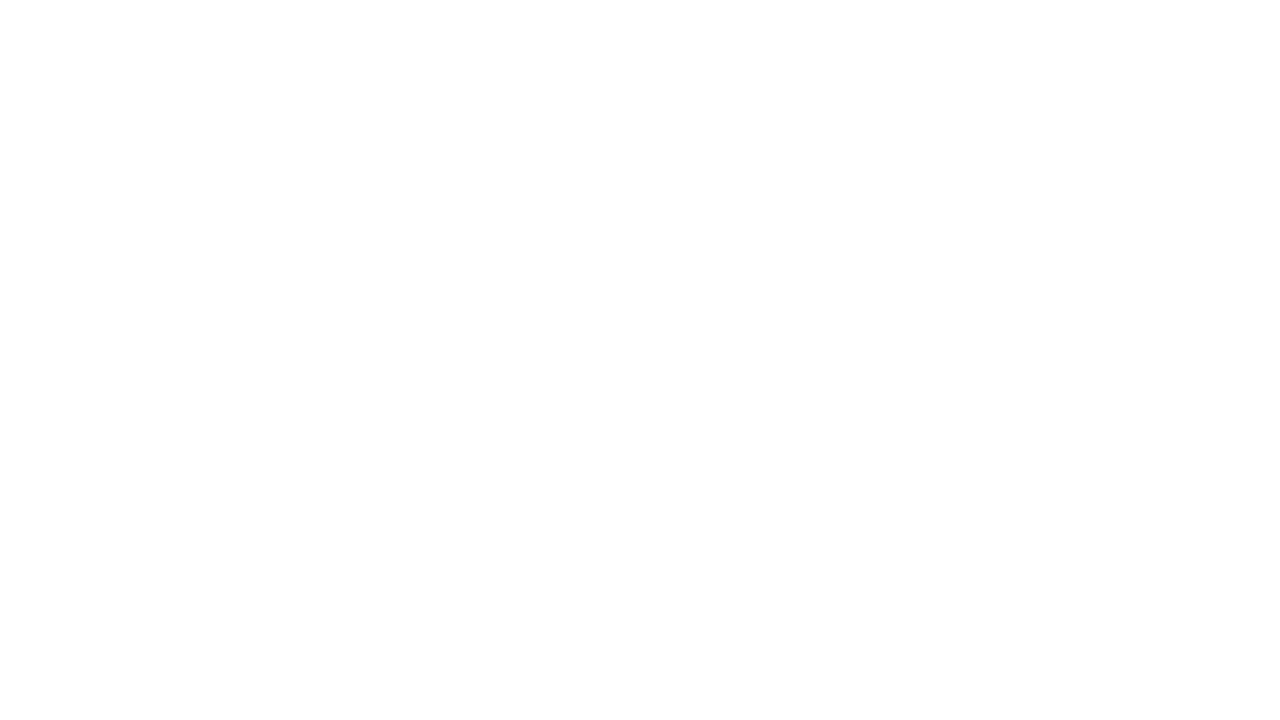
A Studióban válassza az Egyéni besorolási modell csempét a lap egyéni modellek szakaszában, és válassza a Projekt létrehozása gombot.
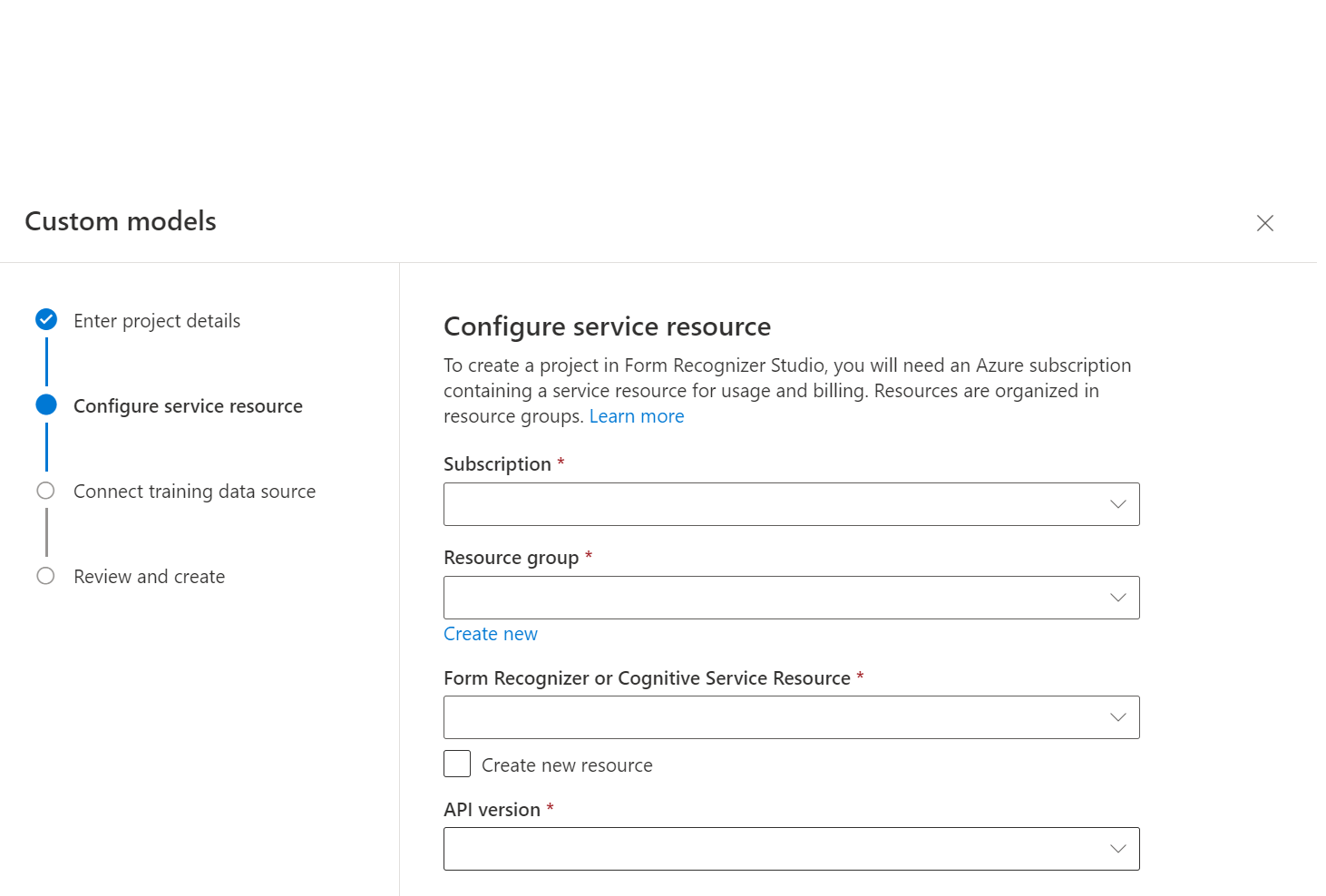
A párbeszédpanelen adja meg a
Create Projectprojekt nevét, opcionálisan adjon leírást, és válassza a Folytatás lehetőséget.Ezután válassza ki vagy válassza a Dokumentumintelligencia-erőforrás létrehozása lehetőséget a folytatás előtt.
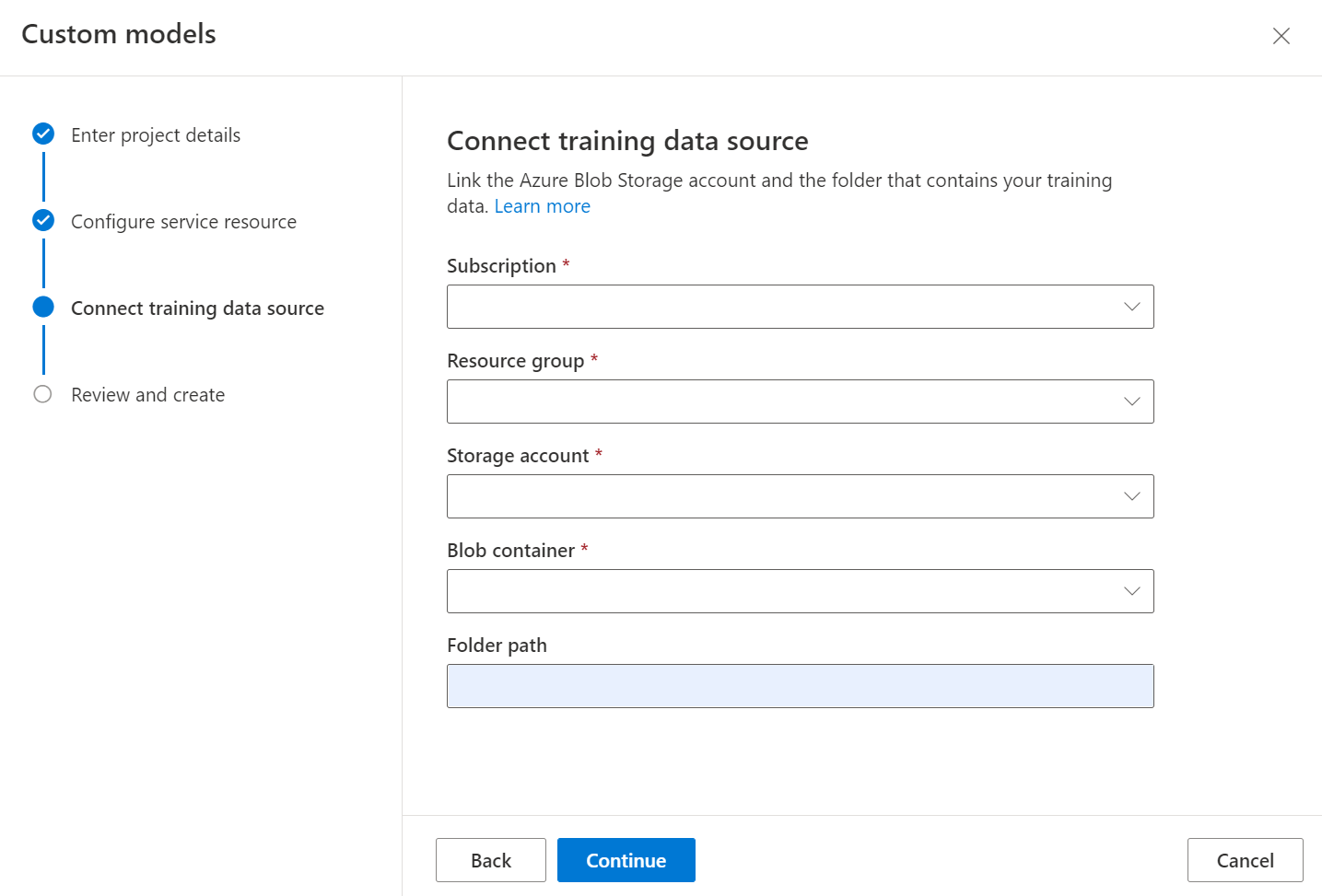
Ezután válassza ki az egyéni modell betanítási adatkészletének feltöltéséhez használt tárfiókot. A mappa elérési útjának üresnek kell lennie, ha a betanítási dokumentumok a tároló gyökerében találhatók. Ha a dokumentumok egy almappában találhatók, írja be a relatív elérési utat a mappagyökérből a Mappa elérési útja mezőbe. A tárfiók konfigurálása után válassza a Folytatás lehetőséget.
Fontos
A betanítási adatkészletet mappák szerint rendezheti, ahol a mappa neve a dokumentumok címkéje vagy osztálya, vagy létrehozhat egy egyszerű listát a dokumentumokról, amelyekhez címkét rendelhet a Studióban.
Az egyéni osztályozó betanításához az elrendezési modell kimenete szükséges az adathalmaz minden dokumentumához. A modell betanítási folyamata előtt futtassa az elrendezést az összes dokumentumon.
Végül tekintse át a projekt beállításait, és válassza a Projekt létrehozása lehetőséget egy új projekt létrehozásához. Most már a címkézési ablakban kell lennie, és látnia kell az adathalmaz fájljait a listában.
Adatok címkézése
A projektben csak a megfelelő osztálycímkével kell címkéznie az egyes dokumentumokat.
A tárba feltöltött fájlokat láthatja a fájllistában, és készen áll a címkézésre. Van néhány lehetősége az adatkészlet címkézésére.
Ha a dokumentumok mappákba vannak rendezve, a Studio megkéri, hogy használja a mappaneveket címkékként. Ez a lépés leegyszerűsíti a címkézést egyetlen kijelölésre.
Ha címkét szeretne hozzárendelni egy dokumentumhoz, jelölje ki a
add label selection markkívánt címkét.A több dokumentum kijelölésének vezérlése címke hozzárendeléséhez
Most már az adathalmaz összes dokumentumát fel kell címkéznie. Ha megtekinti a tárfiókot, .ocr.json olyan fájlokat talál, amelyek megfelelnek a betanítási adatkészlet minden dokumentumának, és egy új class-name.jsonl fájlt minden egyes címkével ellátott osztályhoz. Ez a betanítási adatkészlet a modell betanításához lesz elküldve.
Saját modell betanítása
A címkével ellátott adathalmaz most már készen áll a modell betanítása. Kattintson a jobb felső sarokban található betanítása gombra.
A modell betanítása párbeszédpanelen adjon meg egy egyedi osztályozóazonosítót és opcionálisan egy leírást. Az osztályozó azonosítója sztring típusú adattípust fogad el.
A betanítási folyamat elindításához válassza a Betanítás lehetőséget.
Az osztályozó modellek néhány perc alatt betanulnak.
A Modellek menüben megtekintheti a betanítási művelet állapotát.
A modell tesztelése
Miután a modell betanítása befejeződött, tesztelheti a modellt a modell kiválasztásával a modellek listájának oldalán.
Válassza ki a modellt, és válassza a Teszt gombot.
Új fájl hozzáadásához tallózással keresse meg a fájlt, vagy helyezzen egy fájlt a dokumentumválasztóba.
Ha ki van jelölve egy fájl, válassza az Elemzés gombot a modell teszteléséhez.
A modell eredményei megjelennek az azonosított dokumentumok listájával, az egyes azonosított dokumentumok megbízhatósági pontszámával és az egyes azonosított dokumentumok oldaltartományával.
Ellenőrizze a modellt az egyes azonosított dokumentumok eredményeinek kiértékelésével.
Egyéni osztályozó betanítása az SDK vagy az API használatával
A Studio vezényli az API-hívásokat, hogy betanítsanak egy egyéni osztályozót. Az osztályozó betanítási adatkészletéhez az elrendezési API kimenete szükséges, amely megfelel a betanítási modell API-verziójának. Ha egy régebbi API-verzióból származó elrendezési eredményeket használ, az alacsonyabb pontosságú modellt eredményezhet.
A Studio létrehozza a betanítási adathalmaz elrendezési eredményeit, ha az adathalmaz nem tartalmaz elrendezési eredményeket. Ha az API-val vagy az SDK-val tanít be egy osztályozót, hozzá kell adnia az elrendezés eredményeit az egyes dokumentumokat tartalmazó mappákhoz. Az elrendezés eredményének az API-válasz formátumában kell lennie, amikor közvetlenül meghívja az elrendezést. Az SDK-objektummodell eltérő. Győződjön meg arról, hogy azok layout results az API-eredmények, és nem a SDK response.
Hibaelhárítás
A besorolási modellhez az egyes betanítási dokumentumok elrendezési modelljének eredményeire van szükség. Ha nem adja meg az elrendezési eredményeket, a Studio megpróbálja futtatni az elrendezési modellt az egyes dokumentumokhoz, mielőtt betanítja az osztályozót. Ez a folyamat szabályozva van, és 429-et eredményezhet.
A Studióban a besorolási modell betanítása előtt futtassa az elrendezési modellt minden dokumentumon, és töltse fel az eredeti dokumentummal megegyező helyre. Az elrendezési eredmények hozzáadása után betanítja az osztályozómodellt a dokumentumokkal.