Egyéni extrakciós modell létrehozása és betanítása
Ez a tartalom a következőre vonatkozik:![]() v4.0 (előzetes verzió) | Korábbi verziók:
v4.0 (előzetes verzió) | Korábbi verziók:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1
v2.1
Fontos
Az egyéni generatív modell betanítási viselkedése eltér az egyéni sablontól és a neurális modell betanításától. Az alábbi dokumentum csak egyéni sablonok és neurális modellek betanítását ismerteti. Az egyéni generatív modellel kapcsolatos útmutatásért tekintse meg az egyéni generatív modellt
A Document Intelligence egyéni modelljeihez néhány betanítási dokumentum szükséges az első lépésekhez. Ha rendelkezik legalább öt dokumentummal, hozzákezdhet az egyéni modell betanításához. Egyéni sablonmodellt (egyéni űrlapot) vagy egyéni neurális modellt (egyéni dokumentumot) vagy egyéni sablonmodellt (egyéni űrlapot) taníthat be. Ez a dokumentum végigvezeti az egyéni modellek betanításának folyamatán.
Egyéni modell bemeneti követelményei
Először győződjön meg arról, hogy a betanítási adatkészlet megfelel a dokumentumintelligencia bemeneti követelményeinek.
Támogatott fájlformátumok:
Modell PDF Kép: JPEG/JPG,PNG,BMP,TIFFHEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLOlvasás ✔ ✔ ✔ Elrendezés ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Általános dokumentum ✔ ✔ Előre összeállított ✔ ✔ Egyéni kinyerés ✔ ✔ Egyéni besorolás ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) A legjobb eredmény érdekében dokumentumonként egy tiszta fényképet vagy kiváló minőségű vizsgálatot biztosít.
PDF és TIFF esetén legfeljebb 2000 oldal dolgozható fel (ingyenes szintű előfizetéssel csak az első két oldal dolgozható fel).
A dokumentumok elemzéséhez használt fájlméret 500 MB a fizetős (S0) szint, az
4ingyenes (F0) szint esetén pedig MB.A képméreteknek 50 képpont x 50 képpont és 10 000 képpont x 10 000 képpont között kell lenniük.
Ha a PDF-eket jelszó védi, akkor beküldés előtt el kell távolítania a védelmet.
A kinyerni kívánt szöveg minimális magassága 12 képpont egy 1024 x 768 képpontos képhez. Ez a dimenzió körülbelül
8150 pont/hüvelyk (DPI) pontszövegnek felel meg.Egyéni modell betanítása esetén a betanítási adatok oldalainak maximális száma az egyéni sablonmodell esetében 500, az egyéni neurális modell esetében pedig 50 000.
Egyéni extrakciós modell betanítása esetén a betanítási adatok teljes mérete 50 MB a sablonmodellhez, a neurális modellhez pedig
1GB.Egyéni besorolási modell betanítása esetén a betanítási adatok
1teljes mérete GB, legfeljebb 10 000 oldal. A 2024-07-31-es és újabb verziókban a betanítási adatok2teljes mérete GB, legfeljebb 10 000 oldal.
Betanítási adattippek
Az alábbi tippeket követve tovább optimalizálhatja az adathalmazt a betanításhoz:
- Képalapú dokumentumok helyett szöveges PDF-dokumentumokat használjon. A beolvasott PDF-dokumentumokat képként kezeli a rendszer.
- Használjon olyan példákat, amelyekben az összes mező kitöltve van a beviteli mezőkkel rendelkező űrlapokhoz.
- Minden mezőben más értékkel rendelkező űrlapot használjon.
- Használjon nagyobb adatkészletet (10-15 kép), ha az űrlapképek minősége alacsonyabb.
Betanítási adatok feltöltése
Miután összegyűjtött egy űrlapokat vagy dokumentumokat a betanításhoz, fel kell töltenie egy Azure Blob Storage-tárolóba. Ha nem tudja, hogyan hozhat létre Azure Storage-fiókot egy tárolóval, kövesse az Azure Storage Azure Portalhoz készült rövid útmutatóját. Az ingyenes tarifacsomag (F0) használatával kipróbálhatja a szolgáltatást, és később frissíthet egy fizetős szintre az éles környezetben.
Videó: Egyéni modell betanítása
- Miután összegyűjtötte és feltöltötte a betanítási adatkészletet, készen áll az egyéni modell betanítására. Az alábbi videóban létrehozunk egy projektet, és megismerjük a modell sikeres címkézésének és betanításának alapjait.
Projekt létrehozása a Document Intelligence Studióban
A Document Intelligence Studio biztosítja és vezényeli az adathalmaz befejezéséhez és a modell betanásához szükséges ÖSSZES API-hívást.
Először navigáljon a Document Intelligence Studióba. A Studio első használatakor inicializálnia kell az előfizetést, az erőforráscsoportot és az erőforrást. Ezután kövesse az egyéni projektek előfeltételeit, hogy konfigurálja a Studiót a betanítási adatkészlet eléréséhez.
A Studióban válassza az Egyéni kinyerési modell csempét, és válassza a Projekt létrehozása gombot.

A párbeszédpanelen adja meg a
create projectprojekt nevét, opcionálisan adjon leírást, és válassza a Folytatás lehetőséget.A munkafolyamat következő lépésében válasszon vagy hozzon létre egy dokumentumintelligencia-erőforrást a folytatás kiválasztása előtt.
Fontos
Az egyéni neurális modellek csak néhány régióban érhetők el. Ha neurális modell betanítását tervezi, válasszon vagy hozzon létre egy erőforrást a támogatott régiók egyikében.

Ezután válassza ki az egyéni modell betanítási adatkészletének feltöltéséhez használt tárfiókot. A mappa elérési útjának üresnek kell lennie, ha a betanítási dokumentumok a tároló gyökerében találhatók. Ha a dokumentumok egy almappában találhatók, írja be a relatív elérési utat a mappagyökérből a Mappa elérési útja mezőbe. A tárfiók konfigurálása után válassza a Folytatás lehetőséget.

Végül tekintse át a projekt beállításait, és válassza a Projekt létrehozása lehetőséget egy új projekt létrehozásához. Most már a címkézési ablakban kell lennie, és látnia kell az adathalmaz fájljait a listában.
Adatok címkézése
A projektben az első feladata, hogy az adathalmazt a kinyerni kívánt mezőkkel címkézze.
A tárba feltöltött fájlok a képernyő bal oldalán jelennek meg, és az első fájl készen áll a címkézésre.
Kezdje el címkézni az adathalmazt, és hozza létre az első mezőt a képernyő jobb felső sarkában található plusz (➕) gombra kattintva.

Adja meg a mező nevét.
Érték hozzárendelése a mezőhöz egy szó vagy szó kiválasztásával a dokumentumban. Jelölje ki a mezőt a legördülő menüben vagy a jobb oldali navigációs sáv mezőlistájában. A címkézett érték a mezőnév alatt van a mezők listájában.
Ismételje meg a folyamatot az adathalmazhoz címkézni kívánt összes mező esetében.
Jelölje ki az adathalmaz többi dokumentumát úgy, hogy kijelöli az egyes dokumentumokat, és kijelöli a címkézni kívánt szöveget.
Mostantól az adathalmaz összes dokumentuma fel van címkézve. A .labels.json és .ocr.json fájlok megfelelnek a betanítási adatkészlet minden dokumentumának és egy új fields.json fájlnak. Ez a betanítási adatkészlet a modell betanításához lesz elküldve.
Saját modell betanítása
A címkével ellátott adathalmaz most már készen áll a modell betanítása. Kattintson a jobb felső sarokban található betanítása gombra.
A modell betanítása párbeszédpanelen adjon meg egy egyedi modellazonosítót és opcionálisan egy leírást. A modellazonosító sztring típusú adattípust fogad el.
A buildelési módhoz válassza ki a betanított modell típusát. További információ a modelltípusokról és képességekről.
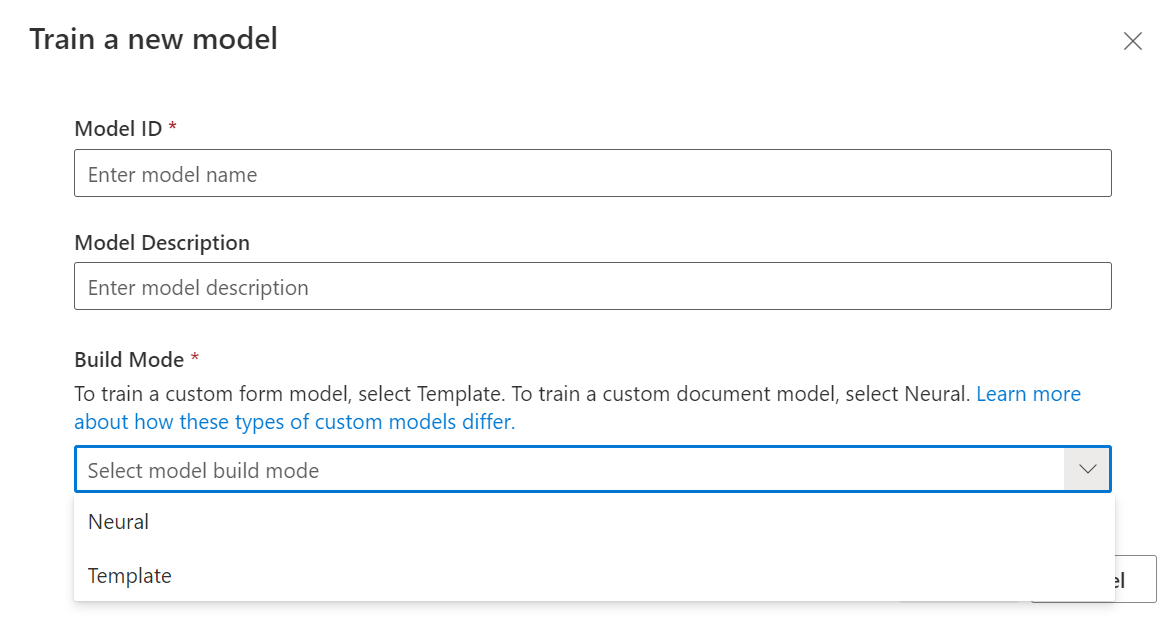
A betanítási folyamat elindításához válassza a Betanítás lehetőséget.
A sablonmodellek néhány perc alatt betanulnak. A neurális modellek betanítása akár 30 percet is igénybe vehet.
A Modellek menüben megtekintheti a betanítási művelet állapotát.
A modell tesztelése
Miután a modell betanítása befejeződött, tesztelheti a modellt a modell kiválasztásával a modellek listájának oldalán.
Válassza ki a modellt, és válassza a Teszt gombot.
+ AddA gombra kattintva kiválaszthat egy fájlt a modell teszteléséhez.Ha ki van jelölve egy fájl, válassza az Elemzés gombot a modell teszteléséhez.
A modell eredményei a főablakban jelennek meg, a kinyert mezők pedig a jobb oldali navigációs sávon jelennek meg.
Ellenőrizze a modellt az egyes mezők eredményeinek kiértékelésével.
A jobb oldali navigációs sávon található a modell és az API JSON-eredményeinek meghívására szolgáló mintakód is.
Gratulálunk, megtanult betaníteni egy egyéni modellt a Document Intelligence Studióban! A modell készen áll a REST API-val vagy az SDK-val a dokumentumok elemzésére.
A következőre vonatkozik: ![]() v2.1. Egyéb verziók: 3.0-s verzió
v2.1. Egyéb verziók: 3.0-s verzió
A Document Intelligence egyéni modell használatakor saját betanítási adatokat biztosít az egyéni modell betanítása művelethez, hogy a modell betanítsa az iparágspecifikus űrlapokat. Ebből az útmutatóból megtudhatja, hogyan gyűjthet és készíthet elő adatokat a modell hatékony betanítása érdekében.
Legalább öt, azonos típusú kitöltött űrlapra van szüksége.
Ha manuálisan címkézett betanítási adatokat szeretne használni, legalább öt, azonos típusú kitöltött űrlapot kell használnia. A szükséges adatkészleten kívül használhat címkézetlen űrlapokat is.
Egyéni modell bemeneti követelményei
Először győződjön meg arról, hogy a betanítási adatkészlet megfelel a dokumentumintelligencia bemeneti követelményeinek.
Támogatott fájlformátumok:
Modell PDF Kép: JPEG/JPG,PNG,BMP,TIFFHEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLOlvasás ✔ ✔ ✔ Elrendezés ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Általános dokumentum ✔ ✔ Előre összeállított ✔ ✔ Egyéni kinyerés ✔ ✔ Egyéni besorolás ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) A legjobb eredmény érdekében dokumentumonként egy tiszta fényképet vagy kiváló minőségű vizsgálatot biztosít.
PDF és TIFF esetén legfeljebb 2000 oldal dolgozható fel (ingyenes szintű előfizetéssel csak az első két oldal dolgozható fel).
A dokumentumok elemzéséhez használt fájlméret 500 MB a fizetős (S0) szint, az
4ingyenes (F0) szint esetén pedig MB.A képméreteknek 50 képpont x 50 képpont és 10 000 képpont x 10 000 képpont között kell lenniük.
Ha a PDF-eket jelszó védi, akkor beküldés előtt el kell távolítania a védelmet.
A kinyerni kívánt szöveg minimális magassága 12 képpont egy 1024 x 768 képpontos képhez. Ez a dimenzió körülbelül
8150 pont/hüvelyk (DPI) pontszövegnek felel meg.Egyéni modell betanítása esetén a betanítási adatok oldalainak maximális száma az egyéni sablonmodell esetében 500, az egyéni neurális modell esetében pedig 50 000.
Egyéni extrakciós modell betanítása esetén a betanítási adatok teljes mérete 50 MB a sablonmodellhez, a neurális modellhez pedig
1GB.Egyéni besorolási modell betanítása esetén a betanítási adatok
1teljes mérete GB, legfeljebb 10 000 oldal. A 2024-07-31-es és újabb verziókban a betanítási adatok2teljes mérete GB, legfeljebb 10 000 oldal.
Betanítási adattippek
Az alábbi tippeket követve tovább optimalizálhatja az adatkészletet a betanításhoz.
- Képalapú dokumentumok helyett szöveges PDF-dokumentumokat használjon. A beolvasott PDF-dokumentumokat képként kezeli a rendszer.
- Használjon példákat, amelyekben az összes mező kitöltve van a kitöltött űrlapokhoz.
- Minden mezőben más értékkel rendelkező űrlapot használjon.
- Használjon nagyobb adatkészletet (10-15 kép) a kitöltött űrlapokhoz.
Betanítási adatok feltöltése
Miután összegyűjtötte a betanításhoz szükséges dokumentumkészletet, fel kell töltenie egy Azure Blob Storage-tárolóba. Ha nem tudja, hogyan hozhat létre Azure Storage-fiókot egy tárolóval, kövesse az Azure Portal Azure Storage rövid útmutatóját. Használja a standard teljesítményszintet.
Ha manuálisan címkézett adatokat szeretne használni, töltse fel a betanítási dokumentumoknak megfelelő .labels.json és .ocr.json fájlokat. A mintacímkézési eszközzel (vagy saját felhasználói felületével) hozhatja létre ezeket a fájlokat.
Adatok rendszerezése almappákban (nem kötelező)
Alapértelmezés szerint az Egyéni modell betanítása API csak a tároló gyökerében található dokumentumokat használja. Az almappákban lévő adatokkal azonban betanítása is lehetséges, ha az API-hívásban adja meg. Az egyéni modell betanítása hívás törzse általában a következő formátummal rendelkezik, ahol <SAS URL> a tároló közös hozzáférésű jogosultságkód URL-címe található:
{
"source":"<SAS URL>"
}
Ha a következő tartalmat adja hozzá a kérelem törzséhez, az API az almappákban található dokumentumokkal fog beépülni. A "prefix" mező nem kötelező, és a betanítási adatkészletet olyan fájlokra korlátozza, amelyek elérési útjai az adott sztringgel kezdődnek. Így például egy érték "Test"miatt az API csak a Teszt szóval kezdődő fájlokat vagy mappákat vizsgálja meg.
{
"source": "<SAS URL>",
"sourceFilter": {
"prefix": "<prefix string>",
"includeSubFolders": true
},
"useLabelFile": false
}
Következő lépések
Most, hogy megtanulta, hogyan hozhat létre betanítási adatkészletet, kövesse az egyéni dokumentumintelligencia-modellek betanítását és az űrlapokon való használatát.