Rövid útmutató: Egyéni szövegbesorolás
Ebből a cikkből megtudhatja, hogyan hozhat létre egyéni szövegbesorolási projektet, ahol egyéni modelleket taníthat be a szövegbesoroláshoz. A modell egy olyan mesterségesintelligencia-szoftver, amely be van tanítva egy bizonyos feladat végrehajtására. Ebben a rendszerben a modellek osztályozzák a szöveget, és a címkézett adatokból tanulnak.
Az egyéni szövegbesorolás kétféle projektet támogat:
- Egycímkés besorolás – egyetlen osztályt rendelhet hozzá az adathalmaz minden dokumentumához. Egy filmszkript például csak "Romantikus" vagy "Vígjáték" besorolású lehet.
- Többcímke-besorolás – az adathalmaz minden dokumentumához több osztályt rendelhet. Egy filmszkript például "Vígjáték" vagy "Romantikus" és "Komédia" besorolású lehet.
Ebben a rövid útmutatóban a rendelkezésre álló mintaadatkészletekkel többcímkés besorolást hozhat létre, ahol a filmszkripteket egy vagy több kategóriába sorolhatja, vagy használhat egycímkés besorolású adatkészletet, ahol a tudományos dokumentumok kivonatait a megadott tartományok egyikébe sorolhatja.
Előfeltételek
- Azure-előfizetés – Hozzon létre egyet ingyenesen.
Új Azure AI-nyelvi erőforrás és Azure Storage-fiók létrehozása
Az egyéni szövegbesorolás használatához létre kell hoznia egy Azure AI Language-erőforrást, amely megadja a projekt létrehozásához és a modell betanításához szükséges hitelesítő adatokat. Szüksége lesz egy Azure Storage-fiókra is, ahol feltöltheti a modell létrehozásához használt adatkészletet.
Fontos
A gyors kezdéshez javasoljuk, hogy hozzon létre egy új Azure AI-nyelvi erőforrást a cikkben ismertetett lépések végrehajtásával. A cikkben ismertetett lépések segítségével egyszerre hozhatja létre a nyelvi erőforrást és a tárfiókot, ami egyszerűbb, mint később.
Ha rendelkezik egy már meglévő erőforrással , amelyet használni szeretne, azt a tárfiókhoz kell csatlakoztatnia.
Új erőforrás létrehozása az Azure Portalról
Lépjen az Azure Portalra egy új Azure AI-nyelvi erőforrás létrehozásához.
A megjelenő ablakban válassza az Egyéni szövegbesorolás > egyéni elnevezett entitásfelismerés lehetőséget az egyéni funkciók közül. A Folytatás gombra kattintva hozza létre az erőforrást a képernyő alján.
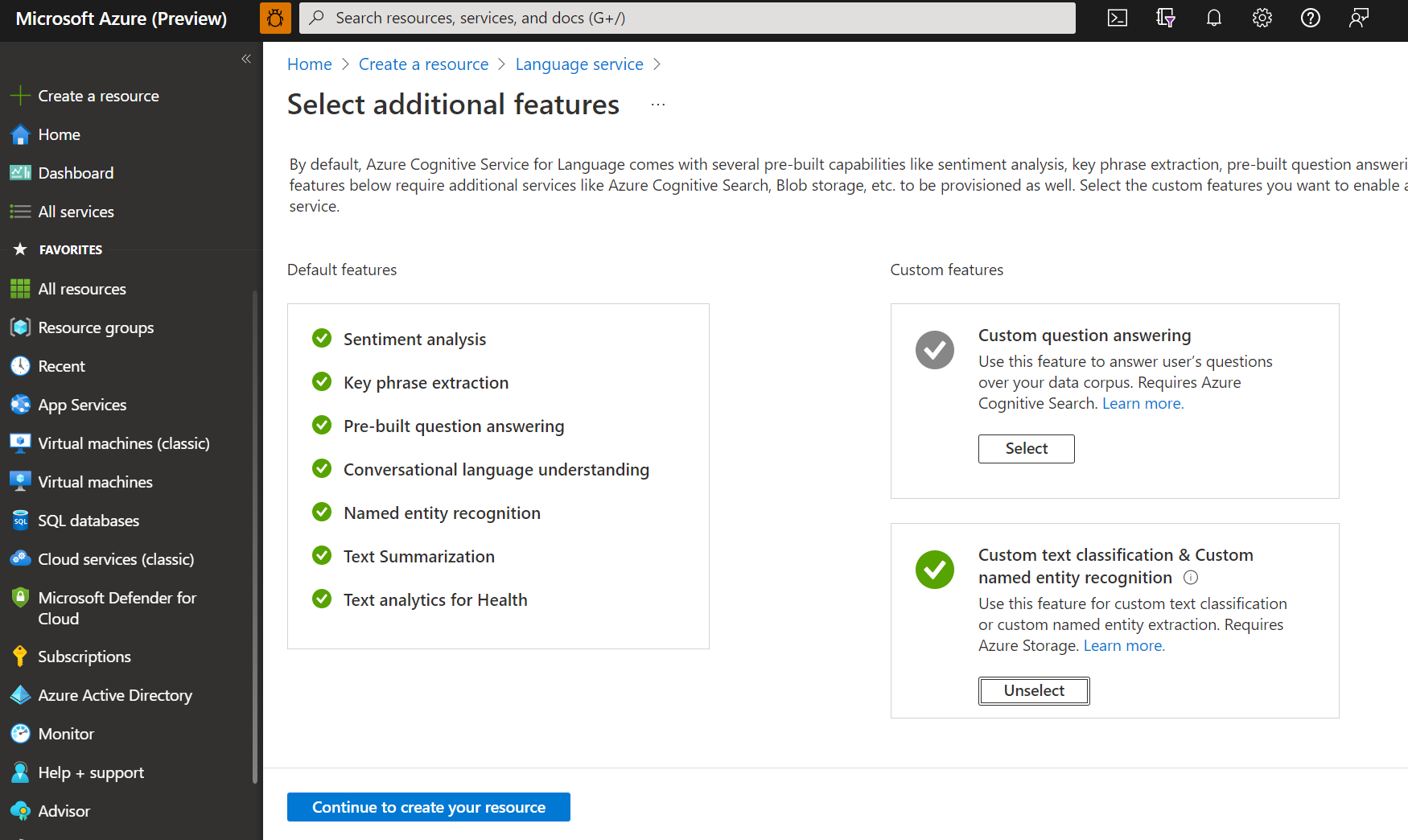
Hozzon létre egy nyelvi erőforrást a következő részletekkel.
Név Kötelező érték Előfizetés Az Azure-előfizetése. Erőforráscsoport Az erőforrást tartalmazó erőforráscsoport. Használhat egy meglévőt, vagy létrehozhat egy újat. Region Az egyik támogatott régió. Például: "USA 2. nyugati régiója". Név Az erőforrás neve. Tarifacsomag Az egyik támogatott tarifacsomag. Az ingyenes (F0) szinttel kipróbálhatja a szolgáltatást. Ha "a bejelentkezési fiókja nem a kiválasztott tárfiók erőforráscsoportjának tulajdonosa", akkor a nyelvi erőforrás létrehozása előtt a fióknak hozzá kell rendelnie egy tulajdonosi szerepkört az erőforráscsoporthoz. Segítségért forduljon az Azure-előfizetés tulajdonosához.
Az Azure-előfizetés tulajdonosának meghatározásához keresse meg az erőforráscsoportot , és kövesse a társított előfizetésre mutató hivatkozást. Ekkor:
- A Hozzáférés-vezérlés (IAM) lap kiválasztása
- Szerepkör-hozzárendelések kiválasztása
- Szűrés szerepkör:tulajdonos szerint.
Az Egyéni szöveg besorolása & egyéni elnevezett entitásfelismerés szakaszban válasszon ki egy meglévő tárfiókot, vagy válassza az Új tárfiók lehetőséget. Vegye figyelembe, hogy ezek az értékek segítenek az első lépésekben, és nem feltétlenül azok a tárfiókértékek , amelyeket éles környezetben szeretne használni. A projekt létrehozása során felmerülő késés elkerülése érdekében csatlakozzon a nyelvi erőforrással azonos régióban lévő tárfiókokhoz.
Tárfiók értéke Javasolt érték Storage account name Bármely név Tárfiók típusa Standard LRS Győződjön meg arról, hogy a Felelős AI-értesítés be van jelölve. Válassza a Véleményezés + létrehozás lehetőséget a lap alján.

Mintaadatok feltöltése blobtárolóba
Miután létrehozott egy Azure Storage-fiókot, és csatlakoztatta a nyelvi erőforráshoz, fel kell töltenie a dokumentumokat a mintaadatkészletből a tároló gyökérkönyvtárába. Ezek a dokumentumok később a modell betanítása gombra lesznek használva.
Töltse le a mintaadatkészletet többcímke-besorolási projektekhez.
Nyissa meg a .zip fájlt, és bontsa ki a dokumentumokat tartalmazó mappát.
A megadott mintaadatkészlet körülbelül 200 dokumentumot tartalmaz, amelyek mindegyike egy film összegzése. Minden dokumentum az alábbi osztályok egy vagy több osztályához tartozik:
- "Rejtély"
- "Dráma"
- "Thriller"
- "Komédia"
- "Művelet"
Az Azure Portalon keresse meg a létrehozott tárfiókot, és válassza ki. Ezt úgy teheti meg, hogy a Tárfiókok elemre kattint, és beírja a tárfiók nevét bármely mező szűrőjébe.
ha az erőforráscsoport nem jelenik meg, győződjön meg arról, hogy az Előfizetés egyenlő szűrő az Összes értékre van állítva.
A tárfiókban válassza a Tárolók lehetőséget a bal oldali menüBen, az Adattárolás alatt. A megjelenő képernyőn válassza a + Tároló lehetőséget. Adja meg a tárolónak a példaadatokat, és hagyja meg az alapértelmezett nyilvános hozzáférési szintet.

A tároló létrehozása után válassza ki. Ezután válassza a Feltöltés gombot a
.txtkorábban letöltött fájlok és.jsonfájlok kiválasztásához.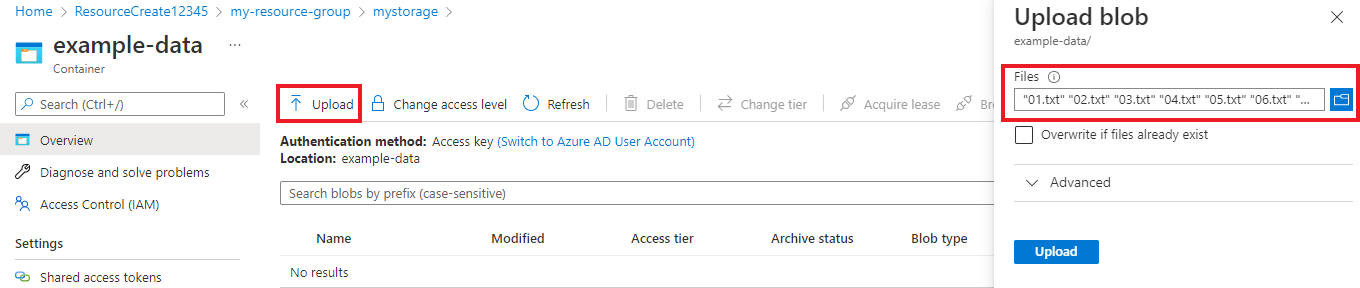


Egyéni szövegbesorolási projekt létrehozása
Miután konfigurálta az erőforrás- és tárolótárolót, hozzon létre egy új egyéni szövegbesorolási projektet. A projekt az adatokon alapuló egyéni ml-modellek készítésének munkaterülete. A projektet csak Ön és mások érhetik el, akik hozzáférnek a használt nyelvi erőforráshoz.
Jelentkezzen be a Language Studióba. Megjelenik egy ablak, amely lehetővé teszi az előfizetés és a nyelvi erőforrás kiválasztását. Válassza ki a nyelvi erőforrást.
A Language Studio Szövegbesorolás szakaszában válassza az Egyéni szövegbesorolás lehetőséget.

Válassza az Új projekt létrehozása lehetőséget a projektek lapjának felső menüjében. A projekt létrehozása lehetővé teszi az adatok címkézését, a modellek betanítása, kiértékelése, fejlesztése és üzembe helyezése.
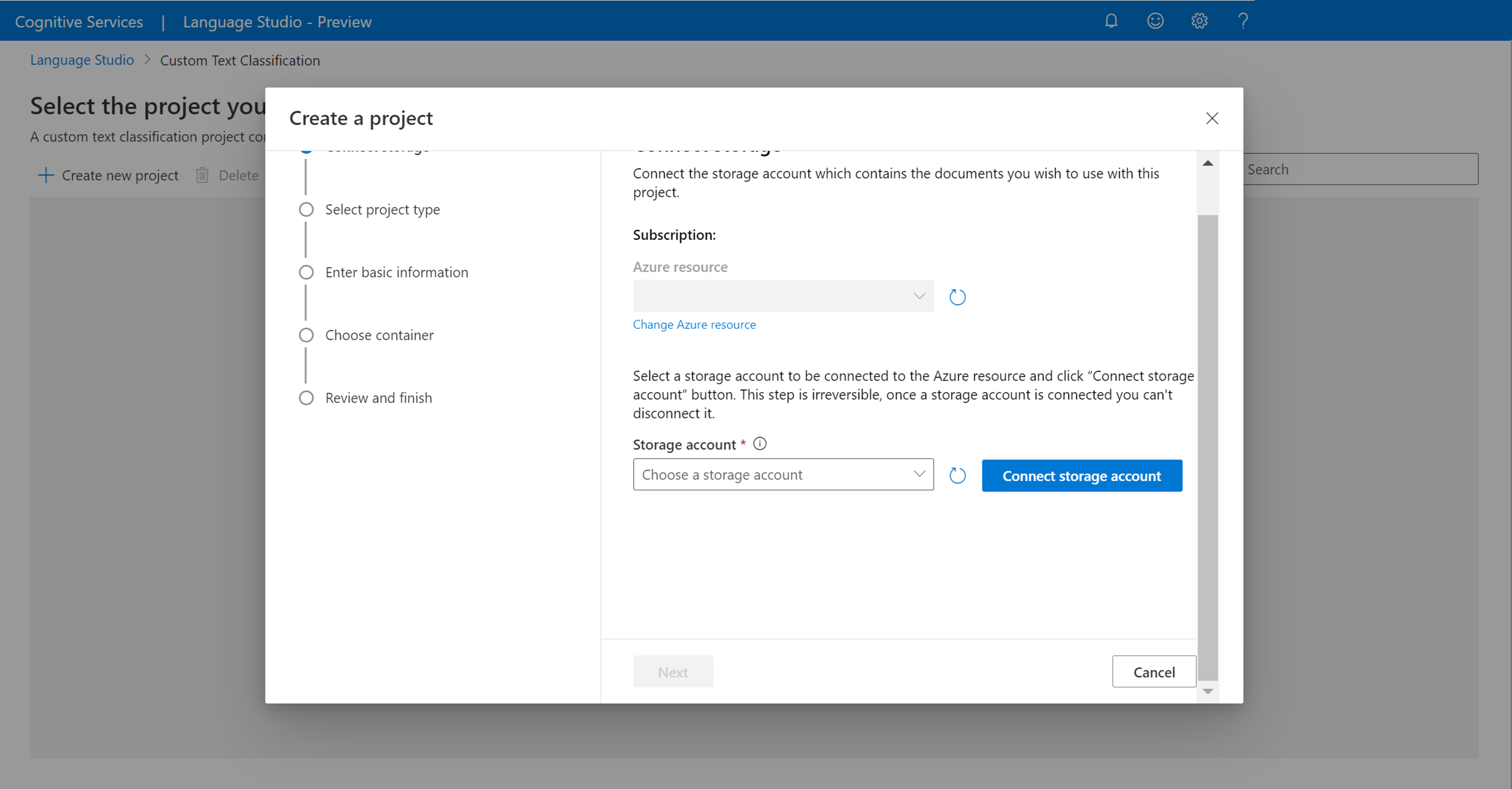
Miután rákattintott az Új projekt létrehozása elemre, megjelenik egy ablak, amely lehetővé teszi a tárfiók csatlakoztatását. Ha már csatlakoztatott egy tárfiókot, látni fogja, hogy a tárfiók csatlakoztatva van. Ha nem, válassza ki a tárfiókot a megjelenő legördülő listából, és válassza ki Csatlakozás tárfiókot. Ezzel beállítja a tárfiókhoz szükséges szerepköröket. Ez a lépés valószínűleg hibát ad vissza, ha nincs tulajdonosként hozzárendelve a tárfiókhoz.
Megjegyzés:
- Ezt a lépést csak egyszer kell elvégeznie minden egyes használt új nyelvi erőforrás esetében.
- Ez a folyamat visszafordíthatatlan, ha egy tárfiókot csatlakoztat a nyelvi erőforráshoz, később nem bonthatja le.
- A nyelvi erőforrást csak egy tárfiókhoz csatlakoztathatja.
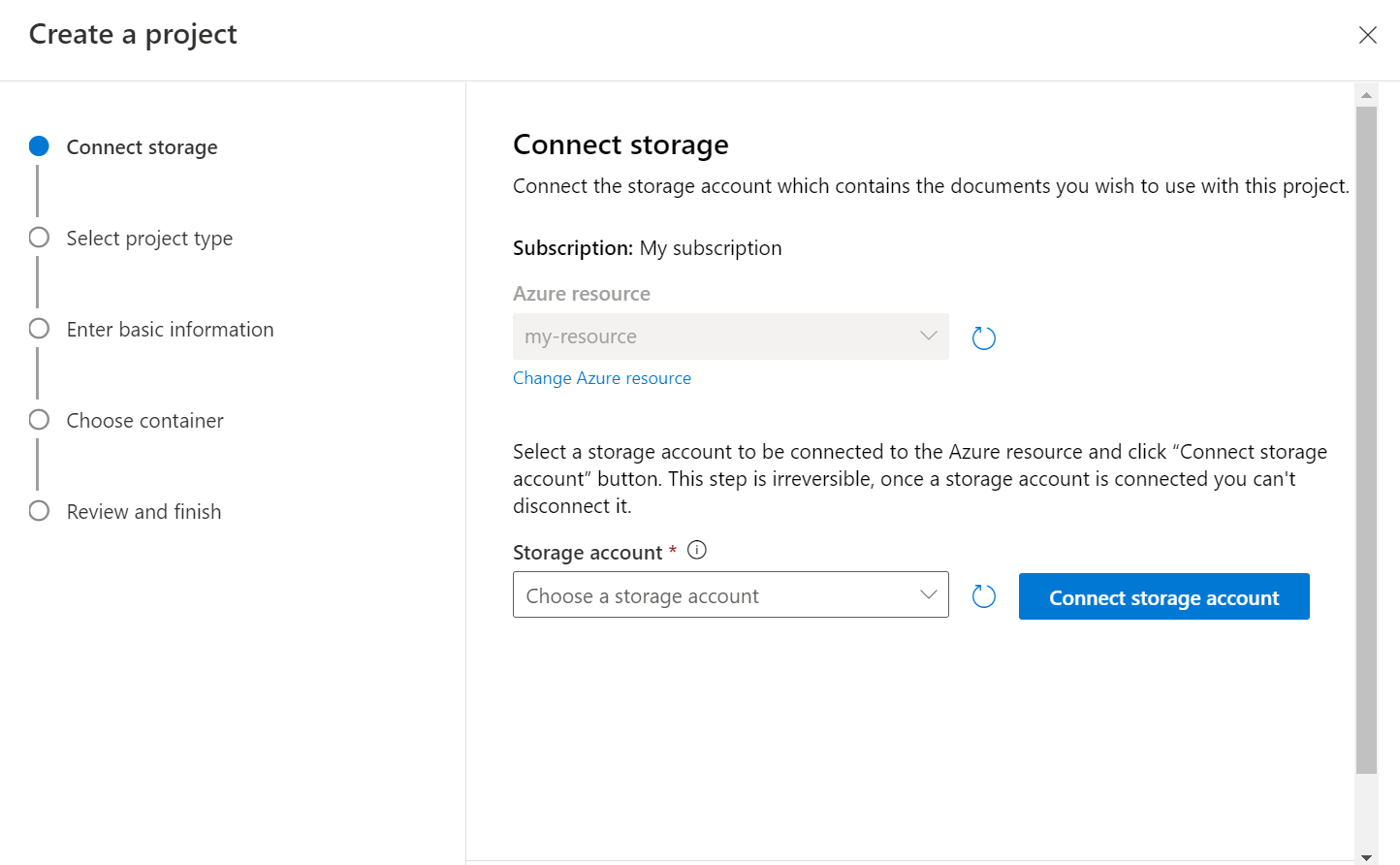
Válassza ki a projekt típusát. Létrehozhat egy többcímkés besorolási projektet, amelyben minden dokumentum egy vagy több osztályhoz vagy egycímkés besorolási projekthez tartozhat, ahol minden dokumentum csak egy osztályhoz tartozhat. A kijelölt típus később nem módosítható. További információ a projekttípusokról
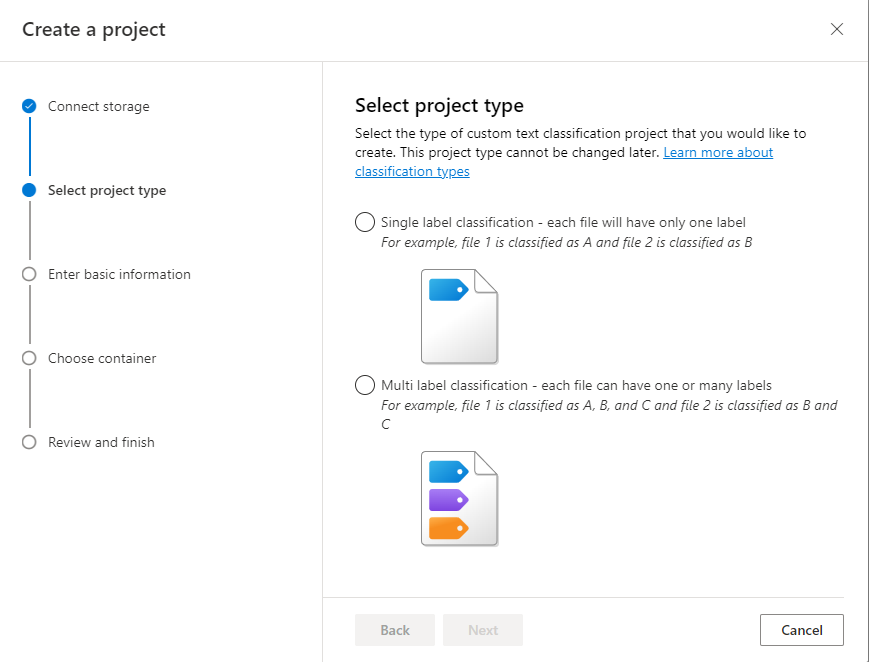
Adja meg a projekt adatait, beleértve a projekt dokumentumainak nevét, leírását és nyelvét. Ha a példaadatkészletet használja, válassza az Angol lehetőséget. Később nem módosíthatja a projekt nevét. Válassza a Következő lehetőséget.
Tipp.
Az adatkészletnek nem kell teljesen azonos nyelven lennie. Több dokumentumot is használhat, amelyek mindegyike különböző támogatott nyelvekkel rendelkezik. Ha az adathalmaz különböző nyelvű dokumentumokat tartalmaz, vagy ha futásidőben különböző nyelvektől vár szöveget, akkor a projekt alapadatainak megadásakor válassza a többnyelvű adatkészlet engedélyezése lehetőséget. Ez a beállítás később engedélyezhető a Projekt beállításai lapon.
Válassza ki azt a tárolót, ahová feltöltötte az adathalmazt.
Megjegyzés:
Ha már címkézte az adatokat, győződjön meg arról, hogy az a támogatott formátumot követi, és válassza az Igen lehetőséget, a dokumentumaim már fel vannak címkézve, és formáztam a JSON-címkéket tartalmazó fájlt, és az alábbi legördülő menüben válassza ki a címkék fájlját.
Ha az egyik példaadatkészletet használja, használja a mellékelt
webOfScience_labelsFilevagymovieLabelsjson fájlt. Ezután válassza a Tovább gombra.Tekintse át a megadott adatokat, és válassza a Projekt létrehozása lehetőséget.




Saját modell betanítása
Általában a projekt létrehozása után elkezdi címkézni a projekthez csatlakoztatott tárolóban lévő dokumentumokat . Ebben a rövid útmutatóban importált egy címkével ellátott mintaadatkészletet, és inicializálta a projektet a JSON-címkék mintafájljával.
A modell betanításának megkezdése a Language Studióban:
A bal oldali menüben válassza a Betanítási feladatok lehetőséget.
Válassza a Betanítási feladat indítása lehetőséget a felső menüben.
Válassza az Új modell betanítása lehetőséget, és írja be a modell nevét a szövegmezőbe. A meglévő modell felülírásához válassza ezt a lehetőséget, és válassza ki azt a modellt, amelyet felül szeretne írni a legördülő menüből. A betanított modellek felülírása visszavonhatatlan, de az az új modell üzembe helyezéséig nem érinti az üzembe helyezett modelleket.

Válassza ki az adatfelosztási módszert. Választhatja a tesztelési csoport automatikus felosztását a betanítási adatokból , ahol a rendszer a megadott százalékok szerint felosztja a címkézett adatokat a betanítási és tesztelési csoportok között. Vagy használhatja a betanítási és tesztelési adatok manuális felosztását is, ez a beállítás csak akkor engedélyezett, ha dokumentumokat adott hozzá a tesztelési csoporthoz az adatfeliratozás során. Az adatfelosztással kapcsolatos további információkért tekintse meg a modell betanítását ismertető témakört.
Válassza a Betanítása gombot.
Ha kiválasztja a betanítási feladat azonosítóját a listából, megjelenik egy oldalpanel, ahol ellenőrizheti a betanítás állapotát, a feladat állapotát és a feladat egyéb adatait.
Megjegyzés:
- Csak a sikeresen befejezett betanítási feladatok hoznak létre modelleket.
- A modell betanítása néhány perc és több óra közötti időt vehet igénybe a címkézett adatok méretétől függően.
- Egyszerre csak egy betanítási feladat futtatható. Amíg a futó feladat be nem fejeződik, nem lehet másik betanítási feladatot elindítani ugyanabban a projektben.

A modell üzembe helyezése
A modell betanítása után általában áttekintheti az értékelés részleteit , és szükség esetén fejleszthet . Ebben a rövid útmutatóban egyszerűen üzembe helyezi a modellt, és elérhetővé teszi a Language Studióban való kipróbáláshoz, vagy meghívhatja az előrejelzési API-t.
A modell üzembe helyezése a Language Studióban:
Válassza a Modell üzembe helyezése lehetőséget a bal oldali menüben.
Új üzembehelyezési feladat elindításához válassza az Üzembe helyezés hozzáadása lehetőséget.
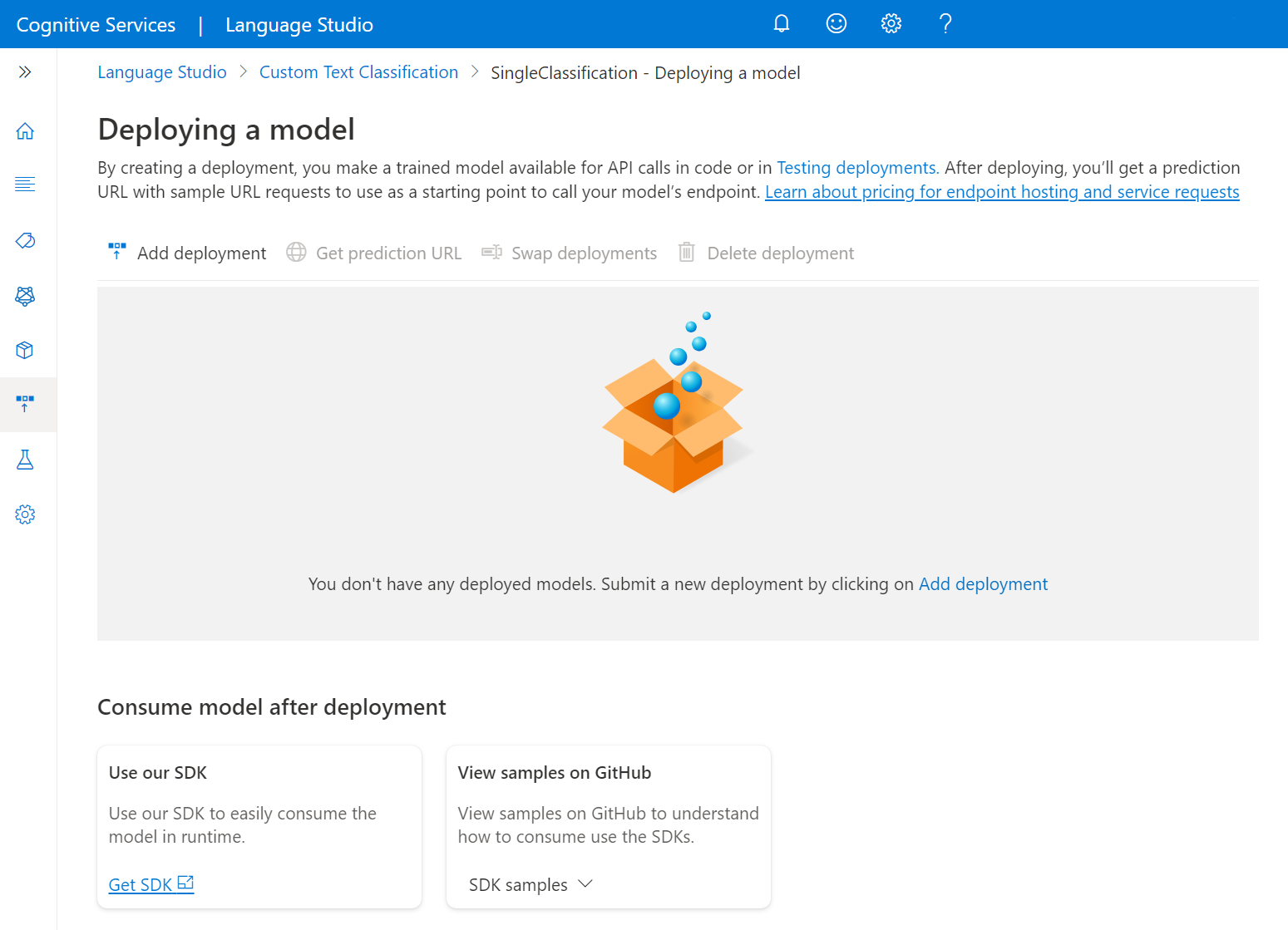
Új üzembe helyezés létrehozásához válassza az Új üzembe helyezés létrehozása lehetőséget, és rendeljen hozzá egy betanított modellt az alábbi legördülő listából. A meglévő üzembe helyezés felülírásához válassza ezt a lehetőséget, és válassza ki azt a betanított modellt, amelyet hozzá szeretne rendelni az alábbi legördülő menüből.
Megjegyzés:
A meglévő üzembe helyezés felülírásához nincs szükség a Prediction API-hívás módosítására, de a kapott eredmények az újonnan hozzárendelt modellen alapulnak.
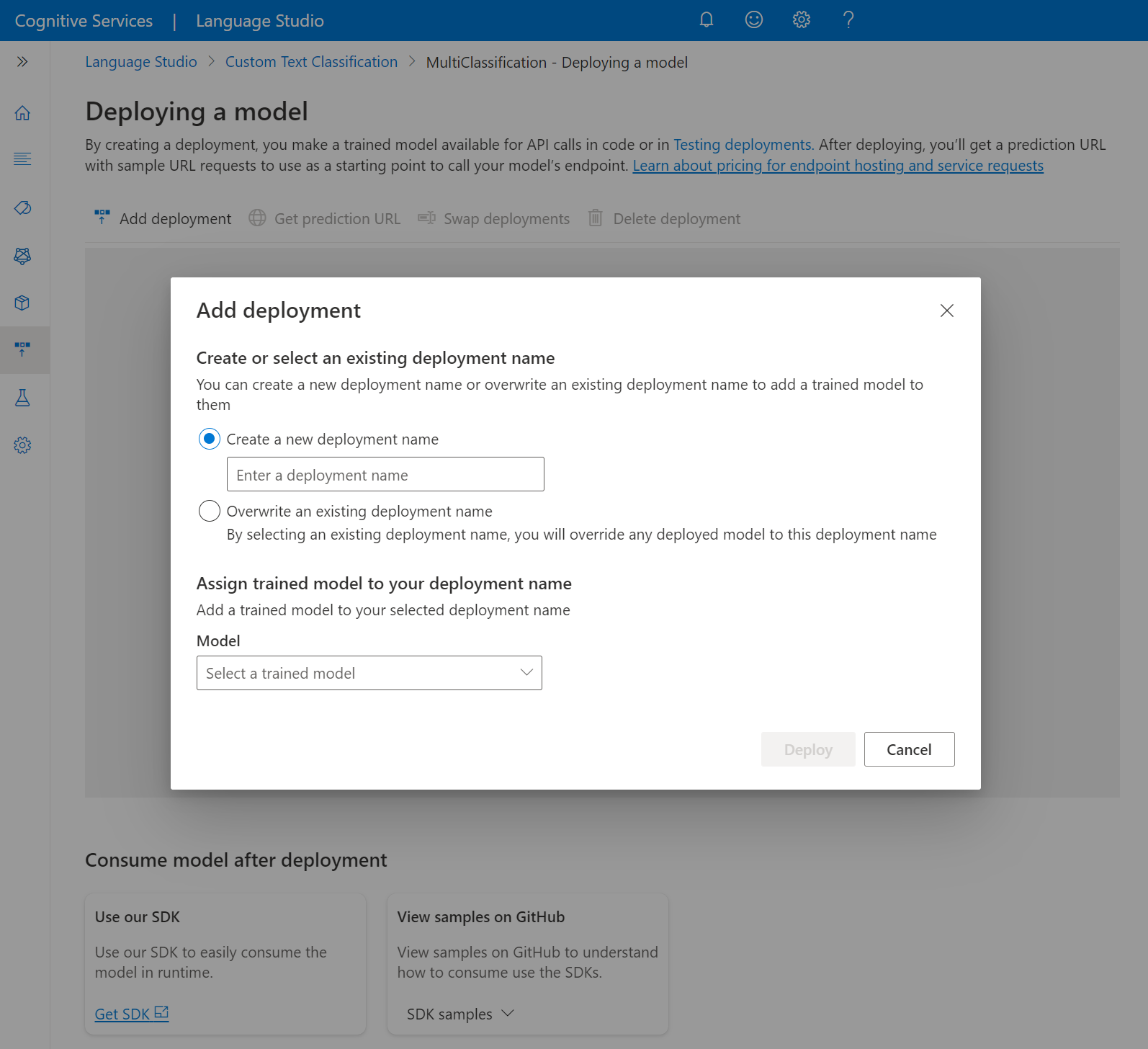
Válassza az Üzembe helyezés lehetőséget az üzembe helyezési feladat elindításához.
A sikeres üzembe helyezés után mellette megjelenik egy lejárati dátum. Az üzembe helyezés lejárata az, amikor az üzembe helyezett modell nem lesz használható előrejelzéshez, ami általában tizenkét hónappal a betanítási konfiguráció lejárta után következik be.


Modell tesztelése
A modell üzembe helyezése után megkezdheti a szöveg besorolását a Prediction API-val. Ebben a rövid útmutatóban a Language Studióval küldi el az egyéni szövegbesorolási feladatot, és megjeleníti az eredményeket. A korábban letöltött mintaadatkészletben megtalálhatja az ebben a lépésben használható tesztdokumentumokat.
Az üzembe helyezett modellek tesztelése a Language Studióban:
A képernyő bal oldalán található menüben válassza a Tesztelési üzemelő példányok lehetőséget.
Válassza ki a tesztelni kívánt üzembe helyezést. Csak az üzemelő példányokhoz rendelt modelleket tesztelheti.
Többnyelvű projektek esetén válassza ki a tesztelni kívánt szöveg nyelvét a nyelvi legördülő menüben.
Válassza ki a lekérdezni/tesztelni kívánt üzembe helyezést a legördülő listában.
Írja be a kérelemben elküldeni kívánt szöveget, vagy töltsön fel egy
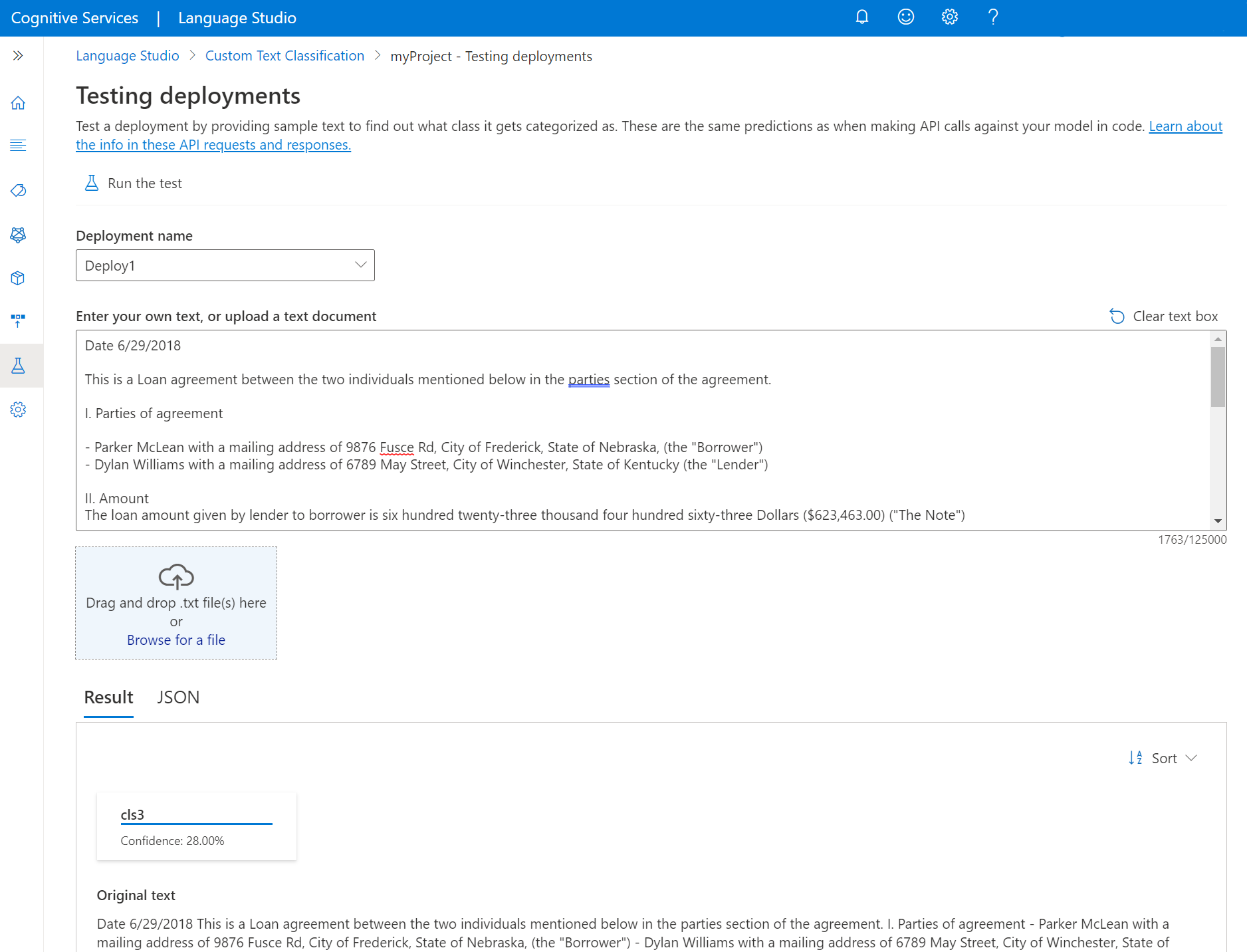
.txtdokumentumot, amelyet használni szeretne. Ha a példaadatkészletek egyikét használja, használhatja a mellékelt .txt fájlok egyikét.Válassza a teszt futtatása lehetőséget a felső menüben.
Az Eredmény lapon láthatja a szöveg előrejelzett osztályait. A JSON-választ a JSON lapon is megtekintheti. Az alábbi példa egy címkebesorolási projektre mutat. A többcímke-besorolási projekt több osztályt is visszaadhat az eredményben.

Projektek törlése
Ha már nincs szüksége a projektre, törölheti a projektet a Language Studióval. Válassza ki az egyéni szövegbesorolást a tetején, majd válassza ki a törölni kívánt projektet. A projekt törléséhez válassza a Törlés lehetőséget a felső menüből.
Előfeltételek
- Azure-előfizetés – Hozzon létre egyet ingyenesen.
Új Azure AI-nyelvi erőforrás és Azure Storage-fiók létrehozása
Az egyéni szövegbesorolás használatához létre kell hoznia egy Azure AI Language-erőforrást, amely megadja a projekt létrehozásához és a modell betanításához szükséges hitelesítő adatokat. Szüksége lesz egy Azure Storage-fiókra is, ahol feltöltheti a modell létrehozásához használt adatkészletet.
Fontos
A gyors kezdéshez javasoljuk, hogy hozzon létre egy új Azure AI Language-erőforrást a jelen cikkben ismertetett lépésekkel, amely lehetővé teszi a nyelvi erőforrás létrehozását, valamint egy tárfiók egyidejű létrehozását és/vagy csatlakoztatását, ami egyszerűbb, mint később.
Ha rendelkezik egy már meglévő erőforrással , amelyet használni szeretne, azt a tárfiókhoz kell csatlakoztatnia.
Új erőforrás létrehozása az Azure Portalról
Lépjen az Azure Portalra egy új Azure AI-nyelvi erőforrás létrehozásához.
A megjelenő ablakban válassza az Egyéni szövegbesorolás > egyéni elnevezett entitásfelismerés lehetőséget az egyéni funkciók közül. A Folytatás gombra kattintva hozza létre az erőforrást a képernyő alján.
Hozzon létre egy nyelvi erőforrást a következő részletekkel.
Név Kötelező érték Előfizetés Az Azure-előfizetése. Erőforráscsoport Az erőforrást tartalmazó erőforráscsoport. Használhat egy meglévőt, vagy létrehozhat egy újat. Region Az egyik támogatott régió. Például: "USA 2. nyugati régiója". Név Az erőforrás neve. Tarifacsomag Az egyik támogatott tarifacsomag. Az ingyenes (F0) szinttel kipróbálhatja a szolgáltatást. Ha "a bejelentkezési fiókja nem a kiválasztott tárfiók erőforráscsoportjának tulajdonosa", akkor a nyelvi erőforrás létrehozása előtt a fióknak hozzá kell rendelnie egy tulajdonosi szerepkört az erőforráscsoporthoz. Segítségért forduljon az Azure-előfizetés tulajdonosához.
Az Azure-előfizetés tulajdonosának meghatározásához keresse meg az erőforráscsoportot , és kövesse a társított előfizetésre mutató hivatkozást. Ekkor:
- A Hozzáférés-vezérlés (IAM) lap kiválasztása
- Szerepkör-hozzárendelések kiválasztása
- Szűrés szerepkör:tulajdonos szerint.
Az Egyéni szöveg besorolása & egyéni elnevezett entitásfelismerés szakaszban válasszon ki egy meglévő tárfiókot, vagy válassza az Új tárfiók lehetőséget. Vegye figyelembe, hogy ezek az értékek segítenek az első lépésekben, és nem feltétlenül azok a tárfiókértékek , amelyeket éles környezetben szeretne használni. A projekt létrehozása során felmerülő késés elkerülése érdekében csatlakozzon a nyelvi erőforrással azonos régióban lévő tárfiókokhoz.
Tárfiók értéke Javasolt érték Storage account name Bármely név Tárfiók típusa Standard LRS Győződjön meg arról, hogy a Felelős AI-értesítés be van jelölve. Válassza a Véleményezés + létrehozás lehetőséget a lap alján.
Mintaadatok feltöltése blobtárolóba
Miután létrehozott egy Azure Storage-fiókot, és csatlakoztatta a nyelvi erőforráshoz, fel kell töltenie a dokumentumokat a mintaadatkészletből a tároló gyökérkönyvtárába. Ezek a dokumentumok később a modell betanítása gombra lesznek használva.
Töltse le a mintaadatkészletet többcímke-besorolási projektekhez.
Nyissa meg a .zip fájlt, és bontsa ki a dokumentumokat tartalmazó mappát.
A megadott mintaadatkészlet körülbelül 200 dokumentumot tartalmaz, amelyek mindegyike egy film összegzése. Minden dokumentum az alábbi osztályok egy vagy több osztályához tartozik:
- "Rejtély"
- "Dráma"
- "Thriller"
- "Komédia"
- "Művelet"
Az Azure Portalon keresse meg a létrehozott tárfiókot, és válassza ki. Ezt úgy teheti meg, hogy a Tárfiókok elemre kattint, és beírja a tárfiók nevét bármely mező szűrőjébe.
ha az erőforráscsoport nem jelenik meg, győződjön meg arról, hogy az Előfizetés egyenlő szűrő az Összes értékre van állítva.
A tárfiókban válassza a Tárolók lehetőséget a bal oldali menüBen, az Adattárolás alatt. A megjelenő képernyőn válassza a + Tároló lehetőséget. Adja meg a tárolónak a példaadatokat, és hagyja meg az alapértelmezett nyilvános hozzáférési szintet.
A tároló létrehozása után válassza ki. Ezután válassza a Feltöltés gombot a
.txtkorábban letöltött fájlok és.jsonfájlok kiválasztásához.
Erőforráskulcsok és végpont lekérése
Lépjen az erőforrás áttekintési oldalára az Azure Portalon
A bal oldali menüben válassza a Kulcsok és végpont lehetőséget. A végpontot és a kulcsot fogja használni az API-kérésekhez

Egyéni szövegbesorolási projekt létrehozása
Miután konfigurálta az erőforrás- és tárolótárolót, hozzon létre egy új egyéni szövegbesorolási projektet. A projekt az adatokon alapuló egyéni ml-modellek készítésének munkaterülete. A projektet csak Ön és mások érhetik el, akik hozzáférnek a használt nyelvi erőforráshoz.
Projektfeladat importálásának aktiválása
Küldjön post kérést a következő URL-cím, fejlécek és JSON-törzs használatával a címkék fájljának importálásához. Győződjön meg arról, hogy a címkék fájlja az elfogadott formátumot követi.
Ha már létezik ilyen nevű projekt, a program lecseréli a projekt adatait.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Helyőrző | Érték | Példa |
|---|---|---|
{ENDPOINT} |
Az API-kérés hitelesítésének végpontja. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
A projekt neve. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | myProject |
{API-VERSION} |
A hívott API verziója. Az itt hivatkozott érték a legújabb kiadott verzióhoz tartozik. További információ a többi elérhető API-verzióról | 2022-05-01 |
Fejlécek
A kérés hitelesítéséhez használja az alábbi fejlécet.
| Kulcs | Érték |
|---|---|
Ocp-Apim-Subscription-Key |
Az erőforrás kulcsa. Az API-kérések hitelesítésére szolgál. |
Törzs
Használja a következő JSON-t a kérésben. Cserélje le az alábbi helyőrző értékeket a saját értékeire.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Kulcs | Helyőrző | Érték | Példa |
|---|---|---|---|
| api-verzió | {API-VERSION} |
A hívott API verziója. Az itt használt verziónak meg kell egyeznie az URL-cím API-verziójával. További információ a többi elérhető API-verzióról | 2022-05-01 |
| projectName | {PROJECT-NAME} |
A projekt neve. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | myProject |
| projectKind | customMultiLabelClassification |
A projekt típusa. | customMultiLabelClassification |
| language | {LANGUAGE-CODE} |
A projektben használt dokumentumok nyelvi kódját meghatározó sztring. Ha a projekt többnyelvű projekt, válassza ki a dokumentumok többségének nyelvi kódját. A többnyelvű támogatással kapcsolatos további információkért tekintse meg a nyelvi támogatást . | en-us |
| Többnyelvű | true |
Logikai érték, amely lehetővé teszi, hogy a dokumentumok több nyelven is szerepeljenek az adathalmazban, és a modell üzembe helyezésekor bármilyen támogatott nyelven lekérdezheti a modellt (ez nem feltétlenül szerepel a betanítási dokumentumokban). A többnyelvű támogatással kapcsolatos további információkért tekintse meg a nyelvi támogatást . | true |
| storageInputContainerName | {CONTAINER-NAME} |
Annak az Azure Storage-tárolónak a neve, ahová feltöltötte a dokumentumait. | myContainer |
| osztályok | [] | A projektben szereplő összes osztályt tartalmazó tömb. Ezekbe az osztályokba szeretné besorolni a dokumentumokat. | [] |
| documents | [] | A projekt összes dokumentumát és a dokumentumhoz címkézett osztályokat tartalmazó tömb. | [] |
| hely | {DOCUMENT-NAME} |
A dokumentumok helye a tárolóban. Mivel az összes dokumentum a tároló gyökerében található, ennek kell lennie a dokumentum nevének. | doc1.txt |
| adathalmaz | {DATASET} |
Az a tesztkészlet, amelyre a dokumentum a betanítás előtt felosztáskor kerül. Az adatfelosztással kapcsolatos további információkért tekintse meg a modell betanítását ismertető témakört. A mező lehetséges értékei a következők Train : és Test. |
Train |
Miután elküldte az API-kérést, kapni fog egy 202 választ, amely jelzi, hogy a feladat helyesen lett elküldve. A válaszfejlécekben bontsa ki az operation-location értéket. A következő módon lesz formázva:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} a kérés azonosítására szolgál, mivel ez a művelet aszinkron. Ezt az URL-címet fogja használni az importálási feladat állapotának lekéréséhez.
A kérés lehetséges hibaforgatókönyvei:
- A kijelölt erőforrás nem rendelkezik megfelelő engedélyekkel a tárfiókhoz.
- A
storageInputContainerNamemegadott nem létezik. - Érvénytelen nyelvi kód van használatban, vagy ha a nyelvi kód típusa nem sztring.
multilingualaz érték egy sztring, és nem logikai érték.
Importálási feladat állapotának lekérése
Az alábbi GET kéréssel kérheti le a projekt importálásának állapotát. Cserélje le az alábbi helyőrző értékeket a saját értékeire.
Kérelem URL-címe
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Helyőrző | Érték | Példa |
|---|---|---|
{ENDPOINT} |
Az API-kérés hitelesítésének végpontja. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
A projekt neve. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | myProject |
{JOB-ID} |
A modell betanítási állapotának helyének azonosítója. Ez az érték az location előző lépésben kapott fejlécértékben van. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
A hívott API verziója. Az itt hivatkozott érték a legújabb kiadott verzióhoz tartozik. További információ a többi elérhető API-verzióról | 2022-05-01 |
Fejlécek
A kérés hitelesítéséhez használja az alábbi fejlécet.
| Kulcs | Érték |
|---|---|
Ocp-Apim-Subscription-Key |
Az erőforrás kulcsa. Az API-kérések hitelesítésére szolgál. |
Saját modell betanítása
Általában a projekt létrehozása után megkezdheti a projekthez csatlakoztatott tárolóban lévő dokumentumok címkézését. Ebben a rövid útmutatóban importált egy címkézett mintaadatkészletet, és inicializálta a projektet a JSON-címkék mintafájljával.
A modell betanításának megkezdése
A projekt importálása után megkezdheti a modell betanítását.
Post-kérés elküldése a következő URL-cím, fejlécek és JSON-törzs használatával egy betanítási feladat elküldéséhez. Cserélje le az alábbi helyőrző értékeket a saját értékeire.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Helyőrző | Érték | Példa |
|---|---|---|
{ENDPOINT} |
Az API-kérés hitelesítésének végpontja. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
A projekt neve. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | myProject |
{API-VERSION} |
A hívott API verziója. Az itt hivatkozott érték a legújabb kiadott verzióhoz tartozik. További információ a többi elérhető API-verzióról | 2022-05-01 |
Fejlécek
A kérés hitelesítéséhez használja az alábbi fejlécet.
| Kulcs | Érték |
|---|---|
Ocp-Apim-Subscription-Key |
Az erőforrás kulcsa. Az API-kérések hitelesítésére szolgál. |
Kérés törzse
Használja a következő JSON-t a kérelem törzsében. A modell megkapja a {MODEL-NAME} betanítás befejezését. Csak a sikeres betanítási feladatok hoznak létre modelleket.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Kulcs | Helyőrző | Érték | Példa |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
A modell neve, amely a sikeres betanítása után lesz hozzárendelve a modellhez. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Ez a modellverzió lesz a modell betanítása. | 2022-05-01 |
| evaluationOptions | Lehetőség az adatok betanítási és tesztelési csoportok közötti felosztására. | {} |
|
| kind | percentage |
Felosztási módszerek. A lehetséges értékek: percentage és manual. További információkért tekintse meg a modell betanítása című témakört. |
percentage |
| trainingSplitPercentage | 80 |
A betanítási csoportban szerepeltetni kívánt címkézett adatok százalékos aránya. A javasolt érték a .80 |
80 |
| testingSplitPercentage | 20 |
A tesztkészletbe felvenni kívánt címkézett adatok százalékos aránya. A javasolt érték a .20 |
20 |
Megjegyzés:
Az trainingSplitPercentage és testingSplitPercentage csak akkor szükséges, ha Kind be van állítva percentage , és mindkét százalék összege 100-nak kell lennie.
Miután elküldte az API-kérést, kapni fog egy 202 választ, amely jelzi, hogy a feladat helyesen lett elküldve. A válaszfejlécekben bontsa ki az location értéket. A következő módon lesz formázva:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
A(z) {JOB-ID} a kérés azonosítására szolgál, mivel ez a művelet aszinkron. Ezzel az URL-címel lekérheti a betanítás állapotát.
Betanítási feladat állapotának lekérése
A betanítás 10 és 30 perc közötti időt vehet igénybe. A következő kéréssel továbbra is lekérdezheti a betanítási feladat állapotát, amíg az sikeresen be nem fejeződik.
A modell betanítási folyamatának állapotának lekéréséhez használja az alábbi GET-kérést . Cserélje le az alábbi helyőrző értékeket a saját értékeire.
Kérelem URL-címe
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Helyőrző | Érték | Példa |
|---|---|---|
{ENDPOINT} |
Az API-kérés hitelesítésének végpontja. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
A projekt neve. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | myProject |
{JOB-ID} |
A modell betanítási állapotának helyének azonosítója. Ez az érték az location előző lépésben kapott fejlécértékben van. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
A hívott API verziója. Az itt hivatkozott érték a legújabb kiadott verzióhoz tartozik. A modell életciklusában további információt talál a többi elérhető API-verzióról. | 2022-05-01 |
Fejlécek
A kérés hitelesítéséhez használja az alábbi fejlécet.
| Kulcs | Érték |
|---|---|
Ocp-Apim-Subscription-Key |
Az erőforrás kulcsa. Az API-kérések hitelesítésére szolgál. |
Válasz törzse
A kérés elküldése után a következő választ kapja.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
A modell üzembe helyezése
A modell betanítása után általában áttekintheti az értékelés részleteit , és szükség esetén fejleszthet . Ebben a rövid útmutatóban egyszerűen üzembe helyezi a modellt, és elérhetővé teszi a Language Studióban való kipróbáláshoz, vagy meghívhatja az előrejelzési API-t.
Üzembehelyezési feladat elküldése
PUT-kérés elküldése az alábbi URL-cím, fejlécek és JSON-törzs használatával üzembehelyezési feladat elküldéséhez. Cserélje le az alábbi helyőrző értékeket a saját értékeire.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Helyőrző | Érték | Példa |
|---|---|---|
{ENDPOINT} |
Az API-kérés hitelesítésének végpontja. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
A projekt neve. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | myProject |
{DEPLOYMENT-NAME} |
Az üzembe helyezés neve. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | staging |
{API-VERSION} |
A hívott API verziója. Az itt hivatkozott érték a legújabb kiadott verzióhoz tartozik. További információ a többi elérhető API-verzióról | 2022-05-01 |
Fejlécek
A kérés hitelesítéséhez használja az alábbi fejlécet.
| Kulcs | Érték |
|---|---|
Ocp-Apim-Subscription-Key |
Az erőforrás kulcsa. Az API-kérések hitelesítésére szolgál. |
Kérés törzse
Használja a következő JSON-t a kérés törzsében. Használja az üzembe helyezéshez hozzárendelni kívánt modell nevét.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Kulcs | Helyőrző | Érték | Példa |
|---|---|---|---|
| betanítottModelLabel | {MODEL-NAME} |
Az üzembe helyezéshez hozzárendelendő modellnév. Csak sikeresen betanított modelleket rendelhet hozzá. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | myModel |
Miután elküldte az API-kérést, kapni fog egy 202 választ, amely jelzi, hogy a feladat helyesen lett elküldve. A válaszfejlécekben bontsa ki az operation-location értéket. A következő módon lesz formázva:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
A(z) {JOB-ID} a kérés azonosítására szolgál, mivel ez a művelet aszinkron. Ezzel az URL-címel lekérheti az üzembe helyezés állapotát.
Üzembehelyezési feladat állapotának lekérése
Az üzembehelyezési feladat állapotának lekérdezéséhez használja a következő GET kérést. Használhatja az előző lépéstől kapott URL-címet, vagy lecserélheti az alábbi helyőrző értékeket a saját értékeire.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Helyőrző | Érték | Példa |
|---|---|---|
{ENDPOINT} |
Az API-kérés hitelesítésének végpontja. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
A projekt neve. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | myProject |
{DEPLOYMENT-NAME} |
Az üzembe helyezés neve. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | staging |
{JOB-ID} |
A modell betanítási állapotának helyének azonosítója. Ez az location előző lépésben kapott fejlécértékben található. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
A hívott API verziója. Az itt hivatkozott érték a legújabb kiadott verzióhoz tartozik. További információ a többi elérhető API-verzióról | 2022-05-01 |
Fejlécek
A kérés hitelesítéséhez használja az alábbi fejlécet.
| Kulcs | Érték |
|---|---|
Ocp-Apim-Subscription-Key |
Az erőforrás kulcsa. Az API-kérések hitelesítésére szolgál. |
Válasz törzse
A kérés elküldése után a következő választ kapja. Tartsa le a végpont lekérdezését, amíg az állapotparaméter "sikeres" értékre nem változik. A kérés sikerességét jelző kódot kell kapnia 200 .
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Szöveg osztályozása
A modell sikeres üzembe helyezése után megkezdheti a szöveg besorolását a Prediction API-val. A korábban letöltött mintaadatkészletben megtalálhatja az ebben a lépésben használható tesztdokumentumokat.
Egyéni szövegbesorolási feladat elküldése
Ezzel a POST-kéréssel elindíthat egy szövegbesorolási feladatot.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Helyőrző | Érték | Példa |
|---|---|---|
{ENDPOINT} |
Az API-kérés hitelesítésének végpontja. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
A hívott API verziója. Az itt hivatkozott érték a legújabb kiadott verzióhoz tartozik. A modell életciklusában további információt talál a többi elérhető API-verzióról. | 2022-05-01 |
Fejlécek
| Kulcs | Érték |
|---|---|
| Ocp-Apim-Subscription-Key | Az API-hoz hozzáférést biztosító kulcs. |
Törzs
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Kulcs | Helyőrző | Érték | Példa |
|---|---|---|---|
displayName |
{JOB-NAME} |
A feladat neve. | MyJobName |
documents |
[{},{}] | A feladatokat futtatni kívánt dokumentumok listája. | [{},{}] |
id |
{DOC-ID} |
Dokumentum neve vagy azonosítója. | doc1 |
language |
{LANGUAGE-CODE} |
A dokumentum nyelvi kódját meghatározó sztring. Ha ez a kulcs nincs megadva, a szolgáltatás feltételezi a projekt alapértelmezett nyelvét, amely a projekt létrehozásakor lett kiválasztva. A támogatott nyelvkódok listáját a nyelvi támogatásban találja. | en-us |
text |
{DOC-TEXT} |
Dokumentumfeladat a tevékenységek futtatásához. | Lorem ipsum dolor sit amet |
tasks |
A végrehajtani kívánt feladatok listája. | [] |
|
taskName |
CustomMultiLabelClassification | A tevékenység neve | CustomMultiLabelClassification |
parameters |
A feladatnak átadni kívánt paraméterek listája. | ||
project-name |
{PROJECT-NAME} |
A projekt neve. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Az üzembe helyezés neve. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | prod |
Response
A sikerességről 202-ben kap választ. A válaszfejlécekben bontsa ki operation-locationa .
operation-location formátuma a következő:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Ezzel az URL-címvel lekérdezheti a tevékenység befejezési állapotát, és lekérheti az eredményeket a tevékenység befejezésekor.
Tevékenység eredményeinek lekérése
A szövegbesorolási feladat állapotának/eredményeinek lekérdezéséhez használja a következő GET kérést.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Helyőrző | Érték | Példa |
|---|---|---|
{ENDPOINT} |
Az API-kérés hitelesítésének végpontja. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
A meghívni kívánt API verziója. Az itt hivatkozott érték a legújabb kiadású modellverzióhoz tartozik. | 2022-05-01 |
Fejlécek
| Kulcs | Érték |
|---|---|
| Ocp-Apim-Subscription-Key | Az API-hoz hozzáférést biztosító kulcs. |
Választörzs
A válasz egy JSON-dokumentum lesz, amely a következő paraméterekkel rendelkezik.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Clean up resources
Ha már nincs szüksége a projektre, az alábbi DELETE kéréssel törölheti azt. Cserélje le a helyőrző értékeket a saját értékeire.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Helyőrző | Érték | Példa |
|---|---|---|
{ENDPOINT} |
Az API-kérés hitelesítésének végpontja. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
A projekt neve. Ez az érték megkülönbözteti a kis- és nagybetűk értékét. | myProject |
{API-VERSION} |
A hívott API verziója. Az itt hivatkozott érték a legújabb kiadott verzióhoz tartozik. További információ a többi elérhető API-verzióról | 2022-05-01 |
Fejlécek
A kérés hitelesítéséhez használja az alábbi fejlécet.
| Kulcs | Érték |
|---|---|
| Ocp-Apim-Subscription-Key | Az erőforrás kulcsa. Az API-kérések hitelesítésére szolgál. |
Az API-kérés elküldése után egy 202 sikeres választ kap, ami azt jelenti, hogy a projekt törölve lett. A sikeres hívás eredménye a Operation-Location feladat állapotának ellenőrzésére szolgáló fejléccel.
További lépések
Miután létrehozott egy egyéni szövegbesorolási modellt, a következőt teheti:
Amikor elkezd saját egyéni szövegbesorolási projekteket létrehozni, az útmutató cikkek segítségével részletesebben megismerheti a modell fejlesztését:
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: