Az Azure Analysis Services horizontális felskálázása
A horizontális felskálázással az ügyfél-lekérdezések több lekérdezésreplika között is eloszthatók a lekérdezéskészletben, így csökkentve a válaszidőt a magas lekérdezési számítási feladatok során. A feldolgozást a lekérdezéskészlettől is elkülönítheti, így biztosítva, hogy az ügyfél-lekérdezéseket ne befolyásolja hátrányosan a feldolgozási műveletek. A vertikális felskálázás konfigurálható az Azure Portalon vagy az Analysis Services REST API-val.
A horizontális felskálázás a Standard tarifacsomagú kiszolgálók esetében érhető el. Az egyes lekérdezésreplikák díjszabása megegyezik a kiszolgálóéval. Minden lekérdezésreplikát a kiszolgálóval megegyező régióban kell létrehozni. A konfigurálható lekérdezésreplikák számát az a régió korlátozza, amelyben a kiszolgáló található. További információ: Rendelkezésre állás régiónként. A vertikális felskálázás nem növeli a kiszolgáló számára rendelkezésre álló memória mennyiségét. A memória növeléséhez magasabb szintű csomagra kell váltania.
Miért érdemes felskálázni?
Egy tipikus kiszolgálótelepítésben egy kiszolgáló feldolgozási kiszolgálóként és lekérdezéskiszolgálóként is szolgál. Ha a kiszolgáló modelljeire irányuló ügyfél-lekérdezések száma meghaladja a kiszolgáló tervéhez tartozó lekérdezésfeldolgozási egységeket (QPU), vagy a modellfeldolgozás a magas lekérdezési számítási feladatokkal egy időben történik, a teljesítmény csökkenhet.
A horizontális felskálázással akár hét további lekérdezésreplika-erőforrással is létrehozhat lekérdezéskészletet (összesen nyolcat, beleértve az elsődleges kiszolgálót is). A lekérdezéskészlet replikáinak számát a QPU-igényeknek megfelelően skálázhatja a kritikus időszakokban, és bármikor elkülönítheti a feldolgozó kiszolgálót a lekérdezéskészlettől.
A lekérdezéskészletben található lekérdezésreplikák számától függetlenül a számítási feladatok nem lesznek elosztva a lekérdezésreplikák között. Az elsődleges kiszolgáló szolgál a feldolgozó kiszolgálóként. A lekérdezésreplikák csak az elsődleges kiszolgáló és a lekérdezéskészlet minden replikája között szinkronizált modelladatbázisok lekérdezéseit szolgálják ki.
A horizontális felskálázás akár öt percet is igénybe vehet, amíg az új lekérdezésreplikák növekményesen hozzáadva lesznek a lekérdezéskészlethez. Ha az összes új lekérdezésreplika működik, az új ügyfélkapcsolatok terhelése ki van osztva a lekérdezéskészlet erőforrásai között. A meglévő ügyfélkapcsolatok nem változnak az aktuálisan csatlakoztatott erőforrástól. A skálázás során a lekérdezéskészletből eltávolított lekérdezéskészlet-erőforrás meglévő ügyfélkapcsolatai megszakadnak. Az ügyfelek újra csatlakozhatnak egy fennmaradó lekérdezéskészlet-erőforráshoz.
Hogyan működik?
Amikor először konfigurálja a horizontális felskálázást, a rendszer automatikusan szinkronizálja az elsődleges kiszolgálón lévő modelladatbázisokat egy új lekérdezéskészlet új replikáival. Az automatikus szinkronizálás csak egyszer történik. Az automatikus szinkronizálás során a rendszer az elsődleges kiszolgáló adatfájljait (a blobtárolóban inaktív állapotban titkosítva) egy második helyre másolja, a blobtárolóban pedig inaktív állapotban is titkosítja. A lekérdezéskészlet replikái ezután a második fájlkészletből származó adatokkal vannak hidratálva .
Bár az automatikus szinkronizálást csak akkor hajtja végre a rendszer, ha először skáláz fel egy kiszolgálót, manuális szinkronizálást is végrehajthat. A szinkronizálás biztosítja, hogy a lekérdezéskészlet replikáin lévő adatok megegyeznek az elsődleges kiszolgáló adataival. Amikor az elsődleges kiszolgálón feldolgoz (frissít) modelleket, szinkronizálást kell végrehajtani a feldolgozási műveletek befejezése után . Ez a szinkronizálás az elsődleges kiszolgáló blobtárolóban lévő fájljaiból a második fájlkészletbe másolja a frissített adatokat. A lekérdezéskészlet replikái ezután a Blob Storage második fájlkészletéből származó frissített adatokkal vannak hidratálva.
Ha egy későbbi horizontális felskálázási műveletet hajt végre, például a lekérdezéskészlet replikáinak számát 2-ről ötre növeli, az új replikákat a blobtároló második fájlkészletéből származó adatok hidratálják. Nincs szinkronizálás. Ha a horizontális felskálázás után szinkronizálást végez, a lekérdezéskészlet új replikái kétszer hidratálva lesznek – redundáns hidratálás. Egy későbbi vertikális felskálázási művelet végrehajtásakor fontos szem előtt tartani:
A felskálázási művelet előtt végezzen szinkronizálást a hozzáadott replikák redundáns hidratálásának elkerülése érdekében. Az egyidejűleg futó egyidejű szinkronizálási és vertikális felskálázási műveletek nem engedélyezettek.
A feldolgozási és a vertikális felskálázási műveletek automatizálása során fontos, hogy először az elsődleges kiszolgálón dolgozza fel az adatokat, majd hajtsa végre a szinkronizálást, majd hajtsa végre a vertikális felskálázási műveletet. Ez a sorozat minimális hatást biztosít a QPU-ra és a memóriaerőforrásokra.
A horizontális felskálázási műveletek során a lekérdezéskészlet összes kiszolgálója, beleértve az elsődleges kiszolgálót is, ideiglenesen offline állapotban van.
A szinkronizálás akkor is engedélyezett, ha nincsenek replikák a lekérdezéskészletben. Ha nulláról egy vagy több replikára skáláz fel új adatokat az elsődleges kiszolgálón végzett feldolgozási műveletből, először hajtsa végre a szinkronizálást replikák nélkül a lekérdezéskészletben, majd horizontális felskálázást. A horizontális felskálázás előtti szinkronizálás elkerüli az újonnan hozzáadott replikák redundáns hidratálását.
Amikor töröl egy modelladatbázist az elsődleges kiszolgálóról, az nem törlődik automatikusan a lekérdezéskészlet replikáiból. Végre kell hajtania egy szinkronizálási műveletet a Sync-AzAnalysisServicesInstance PowerShell-paranccsal, amely eltávolítja az adott adatbázis fájlját vagy fájljait a replika megosztott blobtárhelyéről, majd törli a modelladatbázist a lekérdezéskészlet replikáiról. Annak megállapításához, hogy létezik-e modelladatbázis a lekérdezéskészlet replikáin, de nem az elsődleges kiszolgálón, győződjön meg arról, hogy a feldolgozó kiszolgáló elkülönítése a lekérdezési készlet beállításától igen értékre van-e állítva. Ezután az SQL Server Management Studio (SSMS) használatával csatlakozzon az elsődleges kiszolgálóhoz a
:rwminősítő használatával, és ellenőrizze, hogy létezik-e az adatbázis. Ezután kapcsolódjon a lekérdezéskészlet replikáihoz úgy, hogy a:rwminősítő nélkül csatlakozik, hogy kiderüljön, ugyanaz az adatbázis is létezik-e. Ha az adatbázis a lekérdezéskészlet replikáin található, de nem az elsődleges kiszolgálón, futtasson szinkronizálási műveletet.Amikor átnevez egy adatbázist az elsődleges kiszolgálón, egy másik lépés szükséges annak biztosításához, hogy az adatbázis megfelelően szinkronizálva legyen a replikákkal. Az átnevezés után szinkronizálást hajt végre a Sync-AzAnalysisServicesInstance paranccsal, amely megadja a paramétert a
-Databaserégi adatbázisnévvel. Ez a szinkronizálás eltávolítja a régi nevű adatbázist és fájlokat a replikákból. Ezután végezzen egy másik szinkronizálást, amely megadja a-Databaseparamétert az új adatbázis nevével. A második szinkronizálás az újonnan elnevezett adatbázist a második fájlkészletbe másolja, és hidratálja a replikákat. Ezek a szinkronizálások nem hajthatóak végre a Modell szinkronizálása parancs használatával a portálon.
Szinkronizálási mód
Alapértelmezés szerint a lekérdezésreplikák teljes mértékben rehidratálódnak, nem növekményesen. A rehidratálás fázisokban történik. A rendszer leválasztja őket, és egyszerre kettőhöz csatolja őket (feltételezve, hogy legalább három replika van), hogy legalább egy replika bármikor online állapotban legyen a lekérdezésekhez. Bizonyos esetekben előfordulhat, hogy az ügyfeleknek újra csatlakozniuk kell az egyik online replikához a folyamat során. A ReplicaSyncMode beállítással mostantól megadhatja, hogy a lekérdezésreplika szinkronizálása párhuzamosan történjen. A párhuzamos szinkronizálás a következő előnyöket nyújtja:
- A szinkronizálási idő jelentős csökkentése.
- A replikák adatai nagyobb valószínűséggel konzisztensek a szinkronizálási folyamat során.
- Mivel az adatbázisok online állapotúak maradnak minden replikán a szinkronizálási folyamat során, így az ügyfeleknek nem kell újracsatlakozniuk.
- A memóriabeli gyorsítótár növekményesen frissül csak a módosított adatokkal, ami gyorsabb lehet, mint a modell teljes rehidratálása.
A ReplicaSyncMode beállítása
A ReplicaSyncMode speciális tulajdonságokban való beállításához használja az SSMS-t. A lehetséges értékek a következők:
1(alapértelmezett): Teljes replikaadatbázis rehidratációja szakaszokban (növekményes).2: Optimalizált szinkronizálás párhuzamosan.
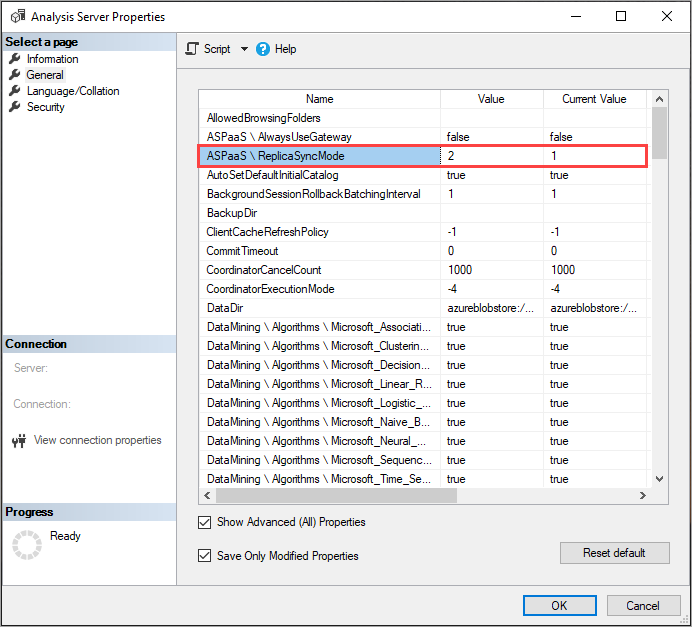
A ReplicaSyncMode=2 beállításakor a gyorsítótár frissítésének mennyiségétől függően a lekérdezésreplikák több memóriát használhatnak fel. Az adatbázis online állapotban tartásához és a lekérdezésekhez való rendelkezésre állásához – az adatok mennyiségétől függően – a művelet akár a replika memóriájának megduplázását is igényelheti, mivel a régi és az új szegmens is egyszerre marad a memóriában. A replikacsomópontok memóriakiosztása megegyezik az elsődleges csomópontéval, és általában extra memória van az elsődleges csomóponton a frissítési műveletekhez, ezért nem valószínű, hogy a replikák elfogynának a memóriájuk. Emellett a gyakori forgatókönyv az, hogy az adatbázis növekményesen frissül az elsődleges csomóponton, ezért a memória megduplázása nem kötelező. Ha a szinkronizálási művelet memóriakihasználtsági hibát tapasztal, újrapróbálkozás az alapértelmezett technikával (egyszerre kettő csatolása/leválasztása).
A feldolgozás elkülönítése a lekérdezéskészlettől
A feldolgozási és a lekérdezési műveletek maximális teljesítményéhez választhatja a feldolgozó kiszolgálót a lekérdezéskészlettől. Ha külön van választva, az új ügyfélkapcsolatok csak a lekérdezéskészlet lekérdezésreplikáihoz lesznek hozzárendelve. Ha a feldolgozási műveletek csak rövid időt vesznek igénybe, dönthet úgy, hogy a feldolgozási kiszolgálót csak annyi ideig választja el a lekérdezéskészlettől, amennyi a feldolgozási és szinkronizálási műveletek végrehajtásához szükséges, majd visszafoglalhatja a lekérdezéskészletbe. A feldolgozási kiszolgálónak a lekérdezéskészlettől való elkülönítése vagy a lekérdezéskészletbe való visszavétele akár öt percet is igénybe vehet a művelet befejezéséhez.
QPU-használat figyelése
Annak megállapításához, hogy szükséges-e a kiszolgáló vertikális felskálázása, figyelje a kiszolgálómetrikáit az Azure Portalon. Ha a QPU rendszeresen maximális, az azt jelenti, hogy a modelleken végzett lekérdezések száma meghaladja a csomag QPU-korlátját. A lekérdezéskészlet feladatsorhosszának metrikája akkor is nő, ha a lekérdezésszál-készlet várólistájában lévő lekérdezések száma meghaladja a rendelkezésre álló QPU-t.
Egy másik jó metrika az átlagos QPU a ServerResourceType szerint. Ez a metrika az elsődleges kiszolgáló átlagos QPU-értékét hasonlítja össze a lekérdezéskészlettel.
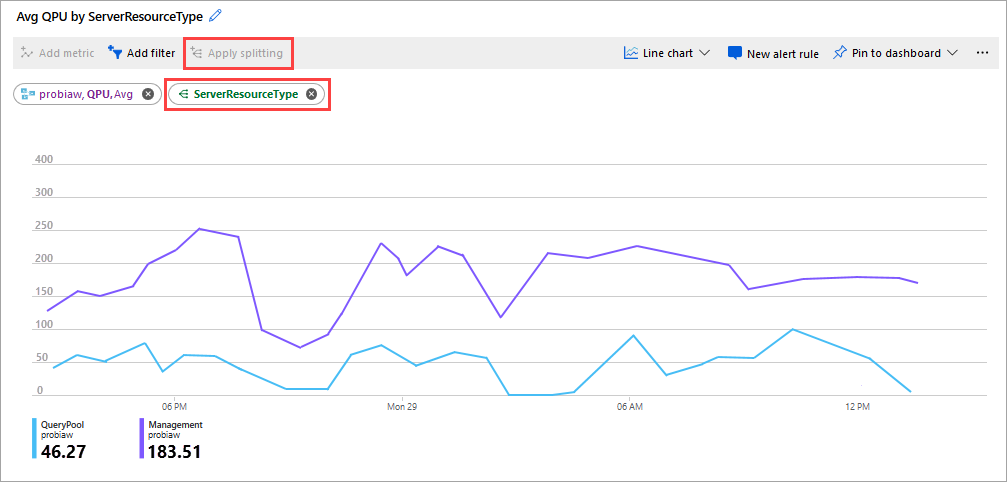
QPU konfigurálása ServerResourceType szerint
- A Metrikák vonaldiagramon kattintson a Metrikák hozzáadása elemre.
- Az ERŐFORRÁS területen válassza ki a kiszolgálót, majd a METRIC NAMESPACE-ben válassza az Analysis Services standard metrikáit, majd a METRIKában válassza a QPU, majd az AGGREGATION területen az Avg elemet.
- Kattintson a Felosztás alkalmazása gombra.
- Az ÉRTÉKEK területen válassza a ServerResourceType lehetőséget.
Részletes diagnosztikai naplózás
A kibővített kiszolgálói erőforrások részletesebb diagnosztikáihoz használja az Azure Monitor-naplókat. A naplókkal Log Analytics-lekérdezésekkel bonthatja ki a QPU-t és a memóriát kiszolgáló és replika szerint. További információ: Naplók elemzése a Log Analytics-munkaterületen. A lekérdezések például a Kusto-minta lekérdezések című témakörben olvashatók.
Horizontális felskálázás konfigurálása
Az Azure Portalon
A portálon kattintson a Felskálázás elemre. A csúszkával válassza ki a lekérdezésreplika-kiszolgálók számát. A kiválasztott replikák száma a meglévő kiszolgálón kívül van.
A feldolgozó kiszolgáló és a lekérdezési készlet elkülönítése esetén válassza az Igen lehetőséget a feldolgozó kiszolgáló lekérdezéskiszolgálókból való kizárásához. Az alapértelmezett kapcsolati sztring (anélkül
:rw) használó ügyfélkapcsolatokat a rendszer átirányítja a lekérdezéskészlet replikáira.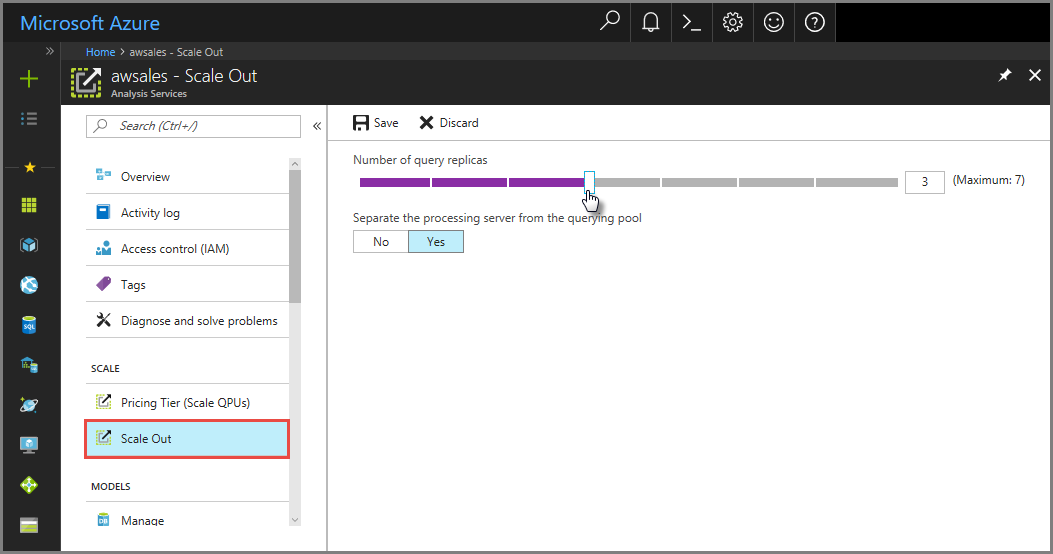
Kattintson a Mentés gombra az új lekérdezésreplika-kiszolgálók kiépítéséhez.
Amikor először konfigurálja a kiszolgáló horizontális felskálázását, a rendszer automatikusan szinkronizálja az elsődleges kiszolgálón lévő modelleket a lekérdezéskészlet replikáival. Az automatikus szinkronizálás csak egyszer történik, amikor először konfigurálja a vertikális felskálázást egy vagy több replikára. Az ugyanazon a kiszolgálón található replikák számának későbbi módosítása nem indít el újabb automatikus szinkronizálást. Az automatikus szinkronizálás akkor sem fordul elő újra, ha a kiszolgálót nulla replikára állítja be, majd ismét felskálázza tetszőleges számú replikára.
Szinkronizálás
A szinkronizálási műveleteket manuálisan vagy a REST API használatával kell végrehajtani.
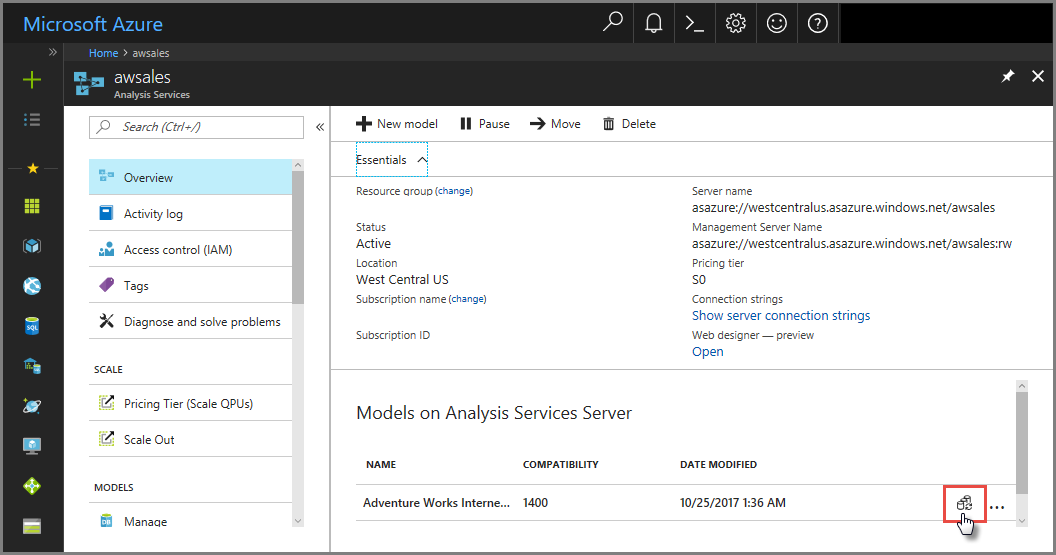
Az Azure Portalon
Az áttekintési> modell >szinkronizálási modelljében.
REST API
Használja a szinkronizálási műveletet.
Modell szinkronizálása
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
Szinkronizálás állapotának lekérése
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
Visszatérési állapotkódok:
| Kód | Leírás |
|---|---|
| 1- | Érvénytelen |
| 0 | Replikáló |
| 0 | Rehidratálás |
| 2 | Befejeződött |
| 3 | Sikertelen |
| 4 | Véglegesítése |
PowerShell
Feljegyzés
Javasoljuk, hogy az Azure Az PowerShell modult használja az Azure-ral való interakcióhoz. Első lépésként tekintse meg az Azure PowerShell telepítését ismertető témakört. Az Az PowerShell-modulra történő migrálás részleteiről lásd: Az Azure PowerShell migrálása az AzureRM modulból az Az modulba.
A PowerShell használata előtt telepítse vagy frissítse a legújabb Azure PowerShell-modult.
A szinkronizálás futtatásához használja a Sync-AzAnalysisServicesInstance parancsot.
A lekérdezésreplikák számának beállításához használja a Set-AzAnalysisServicesServer parancsot. Adja meg az opcionális -ReadonlyReplicaCount paramétert.
Ha el szeretné különíteni a feldolgozó kiszolgálót a lekérdezéskészlettől, használja a Set-AzAnalysisServicesServer parancsot. Adja meg a használni Readonlykívánt paramétert-DefaultConnectionMode.
További információ: Szolgáltatásnév használata az Az.AnalysisServices modullal.
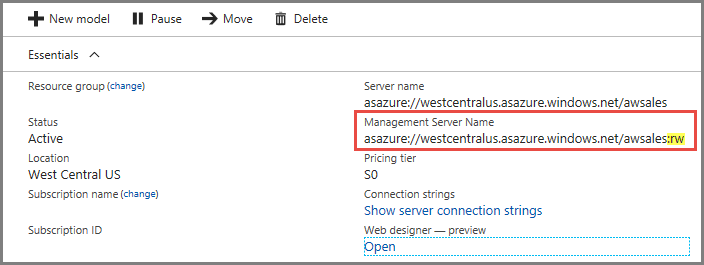
Kapcsolatok
A kiszolgáló Áttekintés lapján két kiszolgálónév található. Ha még nem konfigurálta a vertikális felskálázást egy kiszolgálóhoz, mindkét kiszolgálónév ugyanúgy működik. Miután konfigurálta a kiszolgáló vertikális felskálázását, meg kell adnia a megfelelő kiszolgálónevet a kapcsolat típusától függően.
A végfelhasználói ügyfélkapcsolatok, például a Power BI Desktop, az Excel és az egyéni alkalmazások esetében használja a Kiszolgáló nevét.
A PowerShellben, az Azure Functions-alkalmazásokban és az AMO-ban található SSMS-, Visual Studio- és kapcsolati sztring esetén használja a felügyeleti kiszolgáló nevét. A felügyeleti kiszolgáló neve egy speciális :rw (olvasási-írási) minősítőt tartalmaz. Minden feldolgozási művelet az (elsődleges) felügyeleti kiszolgálón történik.
Vertikális felskálázás, leskálázás és vertikális felskálázás
Több replikával rendelkező kiszolgálón módosíthatja a tarifacsomagot. Ugyanez a tarifacsomag az összes replikára vonatkozik. A skálázási művelet először egyszerre összes replikát lehoz, majd az új tarifacsomag összes replikáját megjeleníti.
Hibaelhárítás
Probléma: A felhasználók hibaüzenetet kapnak, és nem találják a kiszolgáló "<A kiszolgáló> neve" példányát a "ReadOnly" kapcsolati módban.
Megoldás: Amikor kiválasztja a feldolgozó kiszolgáló elkülönítése a lekérdezési készlet beállítástól, a rendszer átirányítja az alapértelmezett kapcsolati sztring (anélkül:rw) használó ügyfélkapcsolatokat a lekérdezéskészlet replikáira. Ha a lekérdezéskészlet replikái még nem online állapotban vannak, mert a szinkronizálás még nem fejeződött be, az átirányított ügyfélkapcsolatok meghiúsulhatnak. A sikertelen kapcsolatok elkerülése érdekében szinkronizáláskor legalább két kiszolgálónak kell lennie a lekérdezéskészletben. A rendszer minden kiszolgálót külön szinkronizál, míg mások online állapotban maradnak. Ha úgy dönt, hogy a feldolgozás során nem rendelkezik a feldolgozó kiszolgálóval a lekérdezéskészletben, akkor dönthet úgy, hogy eltávolítja a készletből feldolgozás céljából, majd a feldolgozás befejezése után, de a szinkronizálás előtt visszaveszi a készletbe. Memória- és QPU-metrikák használatával monitorozza a szinkronizálás állapotát.
Kapcsolódó információk
Az Azure Analysis Servicesfelügyeletének monitorozása Az Azure Analysis Services kezelése