Dokumentumintelligencia egyéni modelljei
Fontos
- A Document Intelligence nyilvános előzetes verziójú kiadásai korai hozzáférést biztosítanak az aktív fejlesztés alatt lévő funkciókhoz.
- A funkciók, a megközelítések és a folyamatok az általános rendelkezésre állás (GA) előtt változhatnak a felhasználói visszajelzések alapján.
- A Document Intelligence ügyfélkódtárak nyilvános előzetes verziója alapértelmezés szerint a REST API 2024-02-29-preview verziója.
- A nyilvános előzetes verzió 2024-02-29 előzetes verziója jelenleg csak a következő Azure-régiókban érhető el:
- USA keleti régiója
- USA2 nyugati régiója
- Nyugat-Európa
Ez a tartalom a következőre vonatkozik::![]() v4.0 (előzetes verzió) | Korábbi verziók:
v4.0 (előzetes verzió) | Korábbi verziók:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Ez a tartalom a következőre vonatkozik::![]() v3.1 (GA) | Legújabb verzió:
v3.1 (GA) | Legújabb verzió:![]() v4.0 (előzetes verzió) | Korábbi verziók:
v4.0 (előzetes verzió) | Korábbi verziók:![]() v3.0
v3.0![]() v2.1
v2.1
Ez a tartalom a következőre vonatkozik::![]() v3.0 (GA) | Legújabb verziók:
v3.0 (GA) | Legújabb verziók:![]() v4.0 (előzetes verzió)
v4.0 (előzetes verzió)![]() v3.1 | Korábbi verzió:
v3.1 | Korábbi verzió:![]() v2.1
v2.1
Ez a tartalom a következőre vonatkozik::![]() v2.1 | Legújabb verzió:
v2.1 | Legújabb verzió:![]() v4.0 (előzetes verzió)
v4.0 (előzetes verzió)
A Dokumentumintelligencia fejlett gépi tanulási technológiát használ a dokumentumok azonosítására, az űrlapok és dokumentumok információinak észlelésére és kinyerésére, valamint a kinyert adatok strukturált JSON-kimenetben való visszaadására. A Dokumentumintelligencia segítségével dokumentumelemzési modelleket, előre összeállított/előre betanított vagy betanított önálló egyéni modelleket használhat.
Az egyéni modellek mostantól egyéni besorolási modelleket is tartalmaznak olyan forgatókönyvekhez, ahol a kinyerési modell meghívása előtt azonosítania kell a dokumentumtípust. Az osztályozó modellek az 2023-07-31 (GA) API-tól kezdve érhetők el. A besorolási modell egyéni extrakciós modellel párosítható a vállalatra jellemző űrlapok és dokumentumok mezőinek elemzéséhez és kinyeréséhez egy dokumentumfeldolgozó megoldás létrehozásához. Önálló egyéni extrakciós modellek kombinálhatók a komponált modellek létrehozásához.
Egyéni dokumentummodell-típusok
Az egyéni dokumentummodellek két típus, egyéni sablon vagy egyéni űrlap, valamint egyéni neurális vagy egyéni dokumentummodellek lehetnek. Mindkét modell címkézési és betanítási folyamata azonos, de a modellek a következőképpen különböznek:
Egyéni extrakciós modellek
Egyéni kinyerési modell létrehozásához címkézzen fel egy dokumentum adathalmazát a kinyerni kívánt értékekkel, és tanítsa be a modellt a címkézett adathalmazra. Az első lépésekhez csak öt, azonos űrlap- vagy dokumentumtípusú példára van szüksége.
Egyéni neurális modell
Fontos
A 4.0- és 2024-02-29-es verziójú API-tól kezdve az egyéni neurális modellek mostantól támogatják az átfedésben lévő mezőket és táblázat-, sor- és cellaszintű megbízhatóságot.
Az egyéni neurális (egyéni dokumentum) modell mélytanulási modelleket és nagy dokumentumgyűjteményeken betanított alapmodellt használ. Ezt a modellt ezután finomhangolja vagy az adatokhoz igazítja, amikor címkézett adatkészlettel tanítja be a modellt. Az egyéni neurális modellek támogatják a strukturált, félig strukturált és strukturálatlan dokumentumokat a mezők kinyeréséhez. Az egyéni neurális modellek jelenleg támogatják az angol nyelvű dokumentumokat. Amikor a két modelltípus közül választ, kezdje egy neurális modellel annak megállapításához, hogy megfelel-e a funkcionális igényeinek. Az egyéni dokumentummodellekkel kapcsolatos további információkért tekintse meg a neurális modelleket .
Egyéni sablonmodell
Az egyéni sablon vagy egyéni űrlapmodell egy konzisztens vizualizációs sablonra támaszkodik a címkézett adatok kinyeréséhez. A dokumentumok vizuális szerkezetének eltérései befolyásolják a modell pontosságát. A strukturált űrlapok, például a kérdőívek vagy az alkalmazások konzisztens vizualizációs sablonok.
A betanítási csoport strukturált dokumentumokból áll, amelyek formázása és elrendezése statikus és állandó az egyik dokumentumpéldánytól a következőig. Az egyéni sablonmodellek támogatják a kulcs-érték párokat, a kijelölési jeleket, a táblákat, az aláírásmezőket és a régiókat. Sablonmodellek, és bármely támogatott nyelven betanított dokumentumokon. További információ: egyéni sablonmodellek.
Ha a dokumentumok nyelve és a kinyerési forgatókönyvek támogatják az egyéni neurális modelleket, javasoljuk, hogy a nagyobb pontosság érdekében egyéni neurális modelleket használjon sablonmodellek fölé.
Tipp.
Annak ellenőrzéséhez, hogy a betanítási dokumentumok egységes vizualizációs sablont mutatnak-e, távolítsa el a felhasználó által megadott összes adatot a készlet minden űrlapjáról. Ha az üres űrlapok megjelenése megegyezik, akkor egységes vizualizációs sablont jelölnek.
További információ: Az egyéni modellek pontosságának és megbízhatóságának értelmezése és javítása.
Bemeneti követelmények
A legjobb eredmény érdekében dokumentumonként egy tiszta fényképet vagy kiváló minőségű vizsgálatot biztosít.
Támogatott fájlformátumok:
Modell PDF Kép:
jpeg/jpg, png, bmp, tiff, heifMicrosoft Office:
Word (docx), Excel (xlsx), PowerPoint (pptx)Olvasás ✔ ✔ ✔ Elrendezés ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview és újabb) Általános dokumentum ✔ ✔ Előre összeállított ✔ ✔ Egyéni kinyerés ✔ ✔ Egyéni besorolás ✔ ✔ ✔ ✱ A Microsoft Office-fájlok jelenleg nem támogatottak más modellekhez vagy verziókhoz.
PDF és TIFF esetén legfeljebb 2000 oldal dolgozható fel (ingyenes szintű előfizetéssel csak az első két oldal dolgozható fel).
A dokumentumok elemzéséhez használt fájlméret 500 MB a fizetős (S0) és 4 MB az ingyenes (F0) szint esetén.
A képméreteknek 50 x 50 képpont és 10 000 képpont x 10 000 képpont között kell lenniük.
Ha a PDF-eket jelszó védi, akkor beküldés előtt el kell távolítania a védelmet.
A kinyerni kívánt szöveg minimális magassága 12 képpont egy 1024 x 768 képpontos képhez. Ez a dimenzió körülbelül
8150 pont/hüvelyk méretű pont szövegnek felel meg.Egyéni modell betanítása esetén a betanítási adatok oldalainak maximális száma az egyéni sablonmodell esetében 500, az egyéni neurális modell esetében pedig 50 000.
Egyéni extrakciós modell betanítása esetén a betanítási adatok teljes mérete sablonmodell esetén 50 MB, a neurális modell esetében pedig 1G-MB.
Egyéni besorolási modell betanítása esetén a betanítási adatok
1GBteljes mérete legfeljebb 10 000 oldal lehet.
Összeállítási mód
Az egyéni modell összeállítása művelet támogatja a sablont és a neurális egyéni modelleket. A REST API és az ügyfélkódtárak korábbi verziói csak egyetlen buildelési módot támogattak, amelyet most sablon módnak neveznek.
A sablonmodellek csak olyan dokumentumokat fogadnak el, amelyek alapszintű lapszerkezettel – egységes vizualizációs megjelenéssel – vagy a dokumentum elemeinek relatív elhelyezkedésével rendelkeznek.
A neurális modellek olyan dokumentumokat támogatnak, amelyek ugyanazokat az információkat, de különböző lapstruktúrákat tartalmaznak. Ilyen dokumentumok például Egyesült Államok W2-űrlapok, amelyek ugyanazokat az információkat tartalmazzák, de megjelenésük vállalatonként eltérő. A neurális modellek jelenleg csak az angol szöveget támogatják.
Ez a táblázat a buildelési mód programozási nyelv SDK-hivatkozásaira és kódmintákra mutató hivatkozásokat tartalmaz a GitHubon:
| Programozási nyelv | SDK-referencia | Kódminta |
|---|---|---|
| C#/.NET | DocumentBuildMode Struct | Sample_BuildCustomModelAsync.cs |
| Java | DocumentBuildMode osztály | BuildModel.java |
| JavaScript | DocumentBuildMode típus | buildModel.js |
| Python | DocumentBuildMode Enum | sample_build_model.py |
Modellfunkciók összehasonlítása
Az alábbi táblázat az egyéni sablonokat és az egyéni neurális funkciókat hasonlítja össze:
| Szolgáltatás | Egyéni sablon (űrlap) | Egyéni neurális (dokumentum) |
|---|---|---|
| Dokumentumstruktúra | Sablon, űrlap és strukturált | Strukturált, részben strukturált és strukturálatlan |
| Betanítási idő | 1–5 perc | 20 perc és 1 óra között |
| Adatkinyerés | Kulcs-érték párok, táblák, kijelölési jelek, koordináták és aláírások | Kulcs-érték párok, kijelölési jelek és táblák |
| Átfedésben lévő mezők | Nem támogatott | Támogatott |
| Dokumentumvariációk | Minden változathoz modell szükséges | Egyetlen modellt használ az összes változathoz |
| Nyelvi támogatás | Több nyelvi támogatás | Angol, előzetes verziójú spanyol, francia, német, olasz és holland nyelvi támogatással |
Egyéni besorolási modell
A dokumentumbesorolás egy új forgatókönyv, amelyet a Dokumentumintelligencia a 2023-07-31 (v3.1 GA) API-val támogat. A dokumentumosztályozó API támogatja a besorolási és felosztási forgatókönyveket. Betanítsa a besorolási modellt az alkalmazás által támogatott különböző típusú dokumentumok azonosításához. A besorolási modell bemeneti fájlja több dokumentumot tartalmazhat, és osztályozza az egyes dokumentumokat egy társított oldaltartományon belül. További információkért tekintse megaz egyéni besorolási modelleket.
Feljegyzés
Az API-verziójú dokumentumbesorolás mostantól támogatja az 2024-02-29-preview Office-dokumentumtípusokat a besoroláshoz. Ez az API-verzió a besorolási modell növekményes betanítását is bevezeti.
Egyéni modelleszközök
A Document Intelligence 3.1-s és újabb verziói a következő eszközöket, alkalmazásokat és kódtárakat, programokat és kódtárakat támogatják:
| Szolgáltatás | Források | Modellazonosító |
|---|---|---|
| Egyéni modell | • Document Intelligence Studio • REST API • C# SDK • Python SDK |
custom-model-id |
A Document Intelligence v2.1 a következő eszközöket, alkalmazásokat és kódtárakat támogatja:
Feljegyzés
Az egyéni modelltípusok egyéni neurális és egyéni sablonok a Document Intelligence 3.1-es és 3.0-s verziójú API-ival érhetők el.
| Szolgáltatás | Források |
|---|---|
| Egyéni modell | • Dokumentumintelligencia-címkézési eszköz • REST API • Ügyfélkódtár SDK • Dokumentumintelligencia Docker-tároló |
Egyéni modell létrehozása
Adatok kinyerése adott vagy egyedi dokumentumokból egyéni modellek használatával. A következő erőforrásokra van szüksége:
Azure-előfizetés. Ingyenesen létrehozhat egyet.
Dokumentumintelligencia-példány az Azure Portalon. A szolgáltatás kipróbálásához használhatja az ingyenes tarifacsomagot (
F0). Az erőforrás üzembe helyezése után válassza az Ugrás az erőforráshoz lehetőséget a kulcs és a végpont lekéréséhez.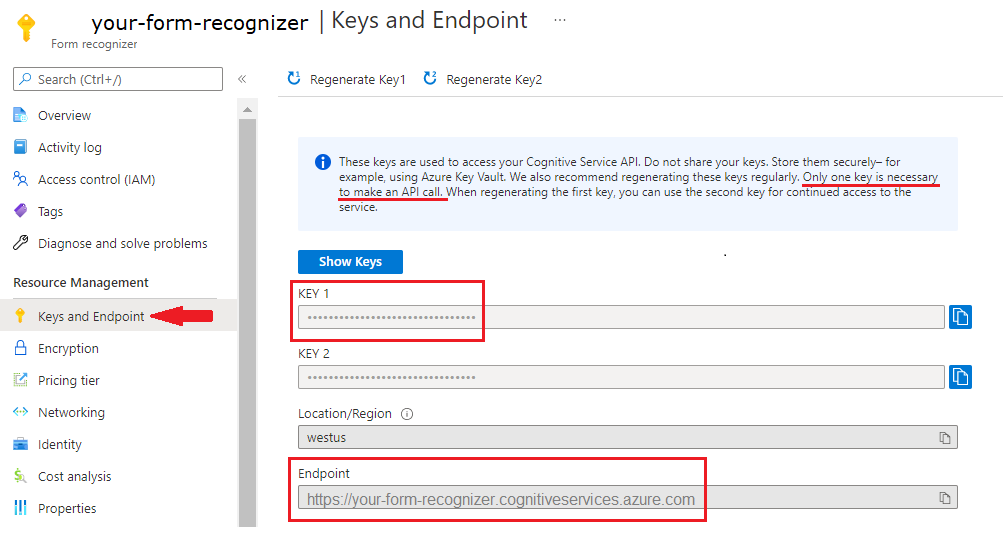
Mintacímkéző eszköz
Tipp.
- A továbbfejlesztett felhasználói élmény és a fejlett modellminőség érdekében próbálja ki a Document Intelligence v3.0 Studiót.
- A v3.0 Studio támogatja a v2.1 címkével ellátott adatokkal betanított modelleket.
- A 2.1-es verzióról a 3.0-s verzióra való migrálással kapcsolatos részletes információkért tekintse meg az API migrálási útmutatójában.
- A 3.0-s verzió használatának megkezdéséhez tekintse meg a REST API- vagy C#-, Java-, JavaScript- vagy Python SDK-gyorsútmutatókat.
A Dokumentumintelligencia-mintacímkéző eszköz egy nyílt forráskód eszköz, amellyel tesztelheti a dokumentumintelligencia és az optikai karakterfelismerés (OCR) funkcióinak legújabb funkcióit.
Az egyéni modellek létrehozásának és használatának megkezdéséhez próbálja ki a Mintacímkézés eszköz rövid útmutatót .
Document Intelligence Studio
Feljegyzés
A Document Intelligence Studio 3.1-s és 3.0-s verziójú API-kkal érhető el.
A Document Intelligence Studio kezdőlapján válassza az Egyéni kinyerési modellek lehetőséget.
A Saját projektek csoportban válassza a Projekt létrehozása lehetőséget.
Töltse ki a projekt részleteit tartalmazó mezőket.
Konfigurálja a szolgáltatáserőforrást úgy, hogy hozzáadja a Storage-fiókot és a Blob-tárolót a betanítási adatforrás Csatlakozás.
Tekintse át és hozza létre a projektet.
Adja hozzá a mintadokumentumokat az egyéni modell címkézéséhez, összeállításához és teszteléséhez.
Az első egyéni extrakciós modell létrehozásához részletes útmutatót aHogyan hozhat létre egyéni extrakciós modellt?
Egyéni modell kinyerésének összegzése
Ez a táblázat a támogatott adatkinyerési területeket hasonlítja össze:
| Modell | Űrlapmezők | Kijelölési jelek | Strukturált mezők (táblák) | Aláírás | Régiócímkézés | Átfedésben lévő mezők |
|---|---|---|---|---|---|---|
| Egyéni sablon | ✔ | ✔ | ✔ | ✔ | ✔ | N/a |
| Egyéni neurális | ✔ | ✔ | ✔ | N/a | * | ✔ (2024-02-29-preview) |
Táblázatszimbólumok:
✔ —Támogatott
**n/a – Jelenleg nem érhető el;
*-Modelltől függően eltérően viselkedik. Sablonmodellekkel a betanításkor szintetikus adatok jönnek létre. Neurális modellek esetén a régióban felismert szöveg ki lesz választva.
Tipp.
Ha a két modelltípus közül választ, először egy egyéni neurális modellel kezdje, ha megfelel a funkcionális igényeinek. Az egyéni neurális modellekről további információt az egyéni neurális modellekben talál.
Egyéni modell fejlesztési lehetőségei
Az alábbi táblázat a társított eszközökkel és ügyfélkódtárakkal elérhető funkciókat ismerteti. Ajánlott eljárásként győződjön meg arról, hogy az itt felsorolt kompatibilis eszközöket használja.
| Dokumentumtípusok | REST API | SDK | Címkék és tesztelési modellek |
|---|---|---|---|
| Egyéni sablon v 4.0 v3.1 v3.0 | Dokumentumintelligencia 3.1 | Dokumentumintelligencia SDK | Document Intelligence Studio |
| Egyéni neurális v4.0 v3.1 v3.0 | Dokumentumintelligencia 3.1 | Dokumentumintelligencia SDK | Document Intelligence Studio |
| Egyéni űrlap v2.1 | Document Intelligence 2.1 GA API | Dokumentumintelligencia SDK | Mintacímkéző eszköz |
Feljegyzés
A 3.0 API-val betanított egyéni sablonmodellek néhány fejlesztéssel rendelkeznek a 2.1 API-val szemben, amelyek az OCR-motor fejlesztéseiből erednek. Az egyéni sablonmodellek 2.1 API-val történő betanításakor használt adatkészletek továbbra is használhatók egy új modell betanítása a 3.0 API használatával.
A legjobb eredmény érdekében dokumentumonként egy tiszta fényképet vagy kiváló minőségű vizsgálatot biztosít.
A támogatott fájlformátumok: JPEG/JPG, PNG, BMP, TIFF és PDF (szövegbe ágyazva vagy beolvasva). A karakterkinyerési és -elhelyezési hibák lehetőségének kizárására a beágyazott szövegű PDF-ek a legalkalmasabbak.
PDF- és TIFF-fájlok esetén legfeljebb 2000 oldal dolgozható fel. Ingyenes szintű előfizetés esetén a rendszer csak az első két oldalt dolgozza fel.
A fájlméretnek 500 MB-nál kisebbnek kell lennie a fizetős (S0) és az ingyenes (F0) szint esetén 4 MB-nál.
A képméret 50 × 50 és 10 000 × 10 000 képpont között lehet.
A PDF-méretek legfeljebb 17 x 17 hüvelyk méretűek, amelyek jogi vagy A3 papírméretnek felelnek meg, vagy kisebbek.
A betanítási adatok teljes mérete legfeljebb 500 oldal.
Ha a PDF-eket jelszó védi, akkor beküldés előtt el kell távolítania a védelmet.
Tipp.
Betanítási adatok:
- Ha lehetséges, képes dokumentumok helyett használjon szöveges PDF-dokumentumokat. A beolvasott PDF-dokumentumokat képként kezeli a rendszer.
- Kérjük, hogy dokumentumonként csak az űrlap egyetlen példányát adja meg.
- Kitöltött űrlapok esetén olyan példákat használjon, amelyekben az összes mező ki van töltve.
- Minden mezőben más értékkel rendelkező űrlapot használjon.
- Ha az űrlapképek minősége alacsonyabb, használjon nagyobb adatkészletet. Használjon például 10–15 képet.
Támogatott nyelvek és területi beállítások
A támogatott nyelvek teljes listáját a Nyelvi támogatás – egyéni modellek oldalon találja.
Következő lépések
Próbálja meg feldolgozni saját űrlapjait és dokumentumait a Dokumentumintelligencia mintacímkéző eszközzel.
Végezze el a Dokumentumintelligencia rövid útmutatóját , és kezdje el létrehozni egy dokumentumfeldolgozó alkalmazást a választott fejlesztési nyelven.
Próbálja meg feldolgozni saját űrlapjait és dokumentumait a Document Intelligence Studióval.
Végezze el a Dokumentumintelligencia rövid útmutatóját , és kezdje el létrehozni egy dokumentumfeldolgozó alkalmazást a választott fejlesztési nyelven.