Forgalmas I/O kizárási minta
A nagy számban érkező I/O-kérések halmozott hatása jelentősen kihathat a teljesítményre és a válaszkészségre.
A probléma leírása
A hálózati hívások és az egyéb I/O-műveletek természetüknél fogva lassabbak, mint a számítási feladatok. Az I/O-kérések rendszerint jelentős terhelést okoznak, és a sok I/O-művelet halmozott hatása lelassíthatja a rendszert. Alább találhatók a forgalmas I/O gyakori okai.
Az egyes rekordok adatbázisba való írása és olvasása külön kérésekként
Az alábbi példa egy termékadatbázisból olvas. Három tábla van: Product, ProductSubcategory és ProductPriceListHistory. A kód egy lekérdezésekből álló sorozat végrehajtásával egy alkategória összes termékét lekéri az árakra vonatkozó információkkal együtt.
- Az alkategória lekérdezése a
ProductSubcategorytáblából. - Az alkategória összes termékének megkeresése a
Producttábla lekérdezésével. - Az árképzési adatok lekérdezése minden termékről a
ProductPriceListHistorytáblából.
Az alkalmazás az Entity Frameworköt használja az adatbázis lekérdezéséhez. A teljes kódmintát itt találja.
public async Task<IHttpActionResult> GetProductsInSubCategoryAsync(int subcategoryId)
{
using (var context = GetContext())
{
// Get product subcategory.
var productSubcategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subcategoryId)
.FirstOrDefaultAsync();
// Find products in that category.
productSubcategory.Product = await context.Products
.Where(p => subcategoryId == p.ProductSubcategoryId)
.ToListAsync();
// Find price history for each product.
foreach (var prod in productSubcategory.Product)
{
int productId = prod.ProductId;
var productListPriceHistory = await context.ProductListPriceHistory
.Where(pl => pl.ProductId == productId)
.ToListAsync();
prod.ProductListPriceHistory = productListPriceHistory;
}
return Ok(productSubcategory);
}
}
Ez a példa világosan bemutatja a problémát, viszont egy O/RM gyakran elfedheti, ha a gyermekrekordokat implicit módon egyenként olvassa be. Ez az úgynevezett „N+1 probléma”.
Egyetlen logikai művelet megvalósítása HTTP-kéréssorozatként
Ez gyakran előfordulhat, amikor a fejlesztők objektumorientált paradigmát követnek, a távoli objektumokat pedig úgy kezelik, mintha helyi objektumok lennének a memóriában. Ez túlzott hálózati forgalmat eredményezhet. A következő webes API például az egyéni HTTP GET metódusokkal felfedi a User objektumok egyéni tulajdonságait.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}/username")]
public HttpResponseMessage GetUserName(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/gender")]
public HttpResponseMessage GetGender(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/dateofbirth")]
public HttpResponseMessage GetDateOfBirth(int id)
{
...
}
}
Ez a módszer sem hibás, de a legtöbb ügyfélnek több tulajdonságra van szüksége minden User esetében, ez pedig a következőhöz hasonló ügyfélkódot eredményezi.
HttpResponseMessage response = await client.GetAsync("users/1/username");
response.EnsureSuccessStatusCode();
var userName = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/gender");
response.EnsureSuccessStatusCode();
var gender = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/dateofbirth");
response.EnsureSuccessStatusCode();
var dob = await response.Content.ReadAsStringAsync();
Olvasás és írás lemezen lévő fájlba
A fájl I/O egy fájl megnyitását és a megfelelő pontra való helyezését jelenti az adatok írása és olvasása előtt. A művelet befejezésekor a rendszer bezárhatja a fájlt az operációs rendszer erőforrásainak megtakarítása érdekében. Egy olyan alkalmazás, amely folyamatosan kis mennyiségű információt olvas és ír egy fájlba, jelentős mennyiségű I/O-terhelést okoz. A kis írási kérések töredezettséghez is vezethetnek, ami tovább lassíthatja a későbbi I/O-műveleteket.
A következő példa FileStreamet használ egy Customer objektum fájlba való írására. A FileStream létrehozása megnyitja, az eltávolítása pedig bezárja a fájlt. (Az using utasítás automatikusan megsemmisíti az FileStream objektumot.) Ha az alkalmazás új ügyfelek hozzáadásakor ismételten meghívja ezt a metódust, az I/O-többletterhelés gyorsan felhalmozódhat.
private async Task SaveCustomerToFileAsync(Customer customer)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
byte [] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
A probléma megoldása
Csökkentse az I/O-kérések számát úgy, hogy az adatokat kevesebb, de nagyobb méretű kérésekbe csomagolja.
Egy lekérdezéssel olvassa be az adatokat az adatbázisból több kisebb lekérdezés helyett. Itt található a termékinformációkat lekérő kód átdolgozott verziója.
public async Task<IHttpActionResult> GetProductCategoryDetailsAsync(int subCategoryId)
{
using (var context = GetContext())
{
var subCategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subCategoryId)
.Include("Product.ProductListPriceHistory")
.FirstOrDefaultAsync();
if (subCategory == null)
return NotFound();
return Ok(subCategory);
}
}
Kövesse a REST webes API-kra vonatkozó tervezési alapelveit. Itt található a korábbi példában használt webes API átdolgozott verziója. Ahelyett, hogy minden tulajdonsághoz külön GET metódust használna, elérhető egyetlen GET metódus, amely visszaadja a User értékét. Emiatt a kérésenkénti választörzsek mérete nagyobb lesz, de az ügyfelek valószínűleg kevesebb API-hívást hajtanak végre.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}")]
public HttpResponseMessage GetUser(int id)
{
...
}
}
// Client code
HttpResponseMessage response = await client.GetAsync("users/1");
response.EnsureSuccessStatusCode();
var user = await response.Content.ReadAsStringAsync();
A fájl I/O csökkentése érdekében fontolja meg az adatok memóriában történő pufferelését, majd a pufferelt adatok fájlba való írását egyetlen műveletben. Ez csökkenti a fájl ismételt megnyitása és bezárása által okozott terhelést, és a lemezen lévő fájl töredezettségének csökkentésében is segít.
// Save a list of customer objects to a file
private async Task SaveCustomerListToFileAsync(List<Customer> customers)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
foreach (var customer in customers)
{
byte[] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
}
// In-memory buffer for customers.
List<Customer> customers = new List<Customers>();
// Create a new customer and add it to the buffer
var customer = new Customer(...);
customers.Add(customer);
// Add more customers to the list as they are created
...
// Save the contents of the list, writing all customers in a single operation
await SaveCustomerListToFileAsync(customers);
Considerations
Az első két példa kevesebb I/O-hívást intéz, de mindegyik több információt kér le. Meg kell találnia az egyensúlyt a két tényező között. A legjobb megoldás a tényleges felhasználási mintáktól függ. A webes API példájában előfordulhat, hogy az ügyfeleknek csak a felhasználónévre van szükségük. Ebben az esetben célszerű lehet külön API-hívásként elérhetővé tenni a nevet. További információkért lásd a Felesleges beolvasásokat ismertető kizárási mintát.
Az adatok olvasásakor ne küldjön túl nagy méretű I/O-kéréseket. Az alkalmazásoknak csak azt az információt célszerű lehívniuk, amelyet valószínű, hogy fel is fog használni.
Néha hasznos egy objektumra vonatkozó információ két tömbre történő particionálása: gyakran lehívott adatokra, amelyekre a legtöbb kérés irányul, illetve kevésbé gyakran lehívott adatokra, amelyeket ritkán használnak. Sokszor a leggyakrabban lehívott adatok az objektum teljes adatainak viszonylag kis részét jelentik, ezért ha a rendszer csak ezt a részt hívja le, azzal jelentős mértékű I/O-terhelést takaríthat meg.
Az adatok írásakor kerülje az erőforrások szükségesnél tovább történő zárolását, így csökkentheti a versengés kialakulásának esélyét a hosszabb műveletek során. Ha az írási művelet több adattárolót, fájlt vagy szolgáltatást is érint, akkor használjon olyan módszert, amely végül konzisztens eredményekhez vezet. Lásd: Adatkonzisztencia-útmutató.
Ha puffereli az adatokat a memóriában az írása előtt, akkor az adatok a folyamatleállások esetén sebezhetővé válnak. Ha az adatátvitel viszonylag ritka, vagy adatlöketek jellemzik, akkor biztonságosabb az adatok tartósabb, külső üzenetsorban (például az Event Hubsban) történő pufferelése.
Fontolja meg a szolgáltatásból vagy adatbázisból lekért adatok gyorsítótárazását. Ezzel segíthet csökkenteni az I/O-műveletek mennyiségét, mert elkerüli az ugyanazon adatokra vonatkozó ismételt kéréseket. További információkért lásd a Gyorsítótárazás – Ajánlott eljárások című témakört.
A probléma észlelése
A forgalmas I/O tünetei a magas késleltetés és az alacsony átviteli sebesség. A végfelhasználók várhatóan magas válaszidőket vagy a szolgáltatások időtúllépéséből eredő hibákat fognak jelezni, mivel nagyobb a versengés az I/O-erőforrásokért.
A következő lépéseket végezheti el az esetlegesen felmerülő problémák okának meghatározásához:
- Végezzen folyamatfigyelést a termelési rendszeren a hosszú válaszidejű műveletek azonosításához.
- Az előző lépésben azonosított műveletek mindegyikénél végezzen terheléstesztelést.
- A terheléstesztek alatt gyűjtsön telemetriai adatokat a műveletek által eszközölt adathozzáférési kérésekről.
- Gyűjtsön részletes statisztikát minden adattárba küldött kérésről.
- Mérje fel az alkalmazást a tesztkörnyezetben, hogy meghatározza, hol fordulhatnak elő esetleg szűk I/O keresztmetszetek.
Az alábbi tüneteket figyelje:
- Nagy számú kis I/O kérés jön létre ugyanahhoz a fájlhoz.
- Egy alkalmazáspéldány nagy számú kis hálózati kérést hoz létre ugyanahhoz a szolgáltatáshoz.
- Egy alkalmazáspéldány nagy számú kis kérést hoz létre ugyanahhoz az adattárhoz.
- Az alkalmazások és szolgáltatások I/O korlátozottá válnak.
Diagnosztikai példa
Az alábbi szakaszok a korábban bemutatott adatbázis-lekérdezést végző példára alkalmazzák ezeket a lépéseket.
Az alkalmazás terheléstesztje
Ez a diagram bemutatja a terheléstesztelés eredményeit. A medián válaszidőt a rendszer kérésenként tíz másodpercekben méri. A diagram nagy késést mutat. 1000 felhasználós tesztelésnél előfordulhat, hogy egy felhasználónak akár egy percet is várnia kell, amíg megkapja a lekérdezés eredményét.
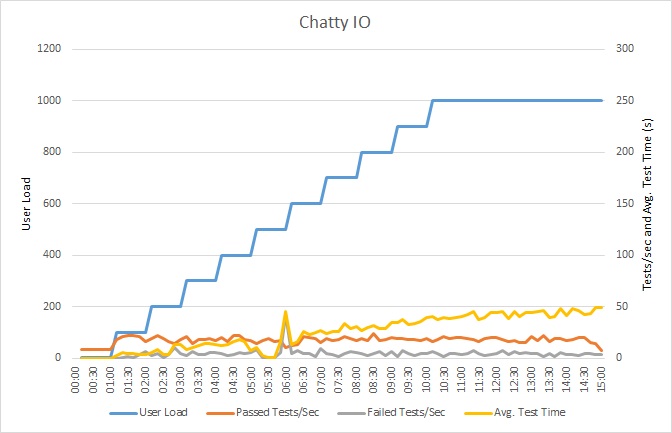
Megjegyzés:
Az alkalmazás egy Azure App Service webalkalmazásban lett üzembe helyezve az Azure SQL Database segítségével. A terhelésteszt egy szimulált lépéses munkaterhelést használt legfeljebb 1000 párhuzamos felhasználóval. Az adatbázis legfeljebb 1000 párhuzamos kapcsolatot támogató kapcsolatkészlettel van konfigurálva, hogy csökkenjen az esélye annak, hogy a kapcsolatokért aló versengés befolyásolja az eredményt.
Az alkalmazás figyelése
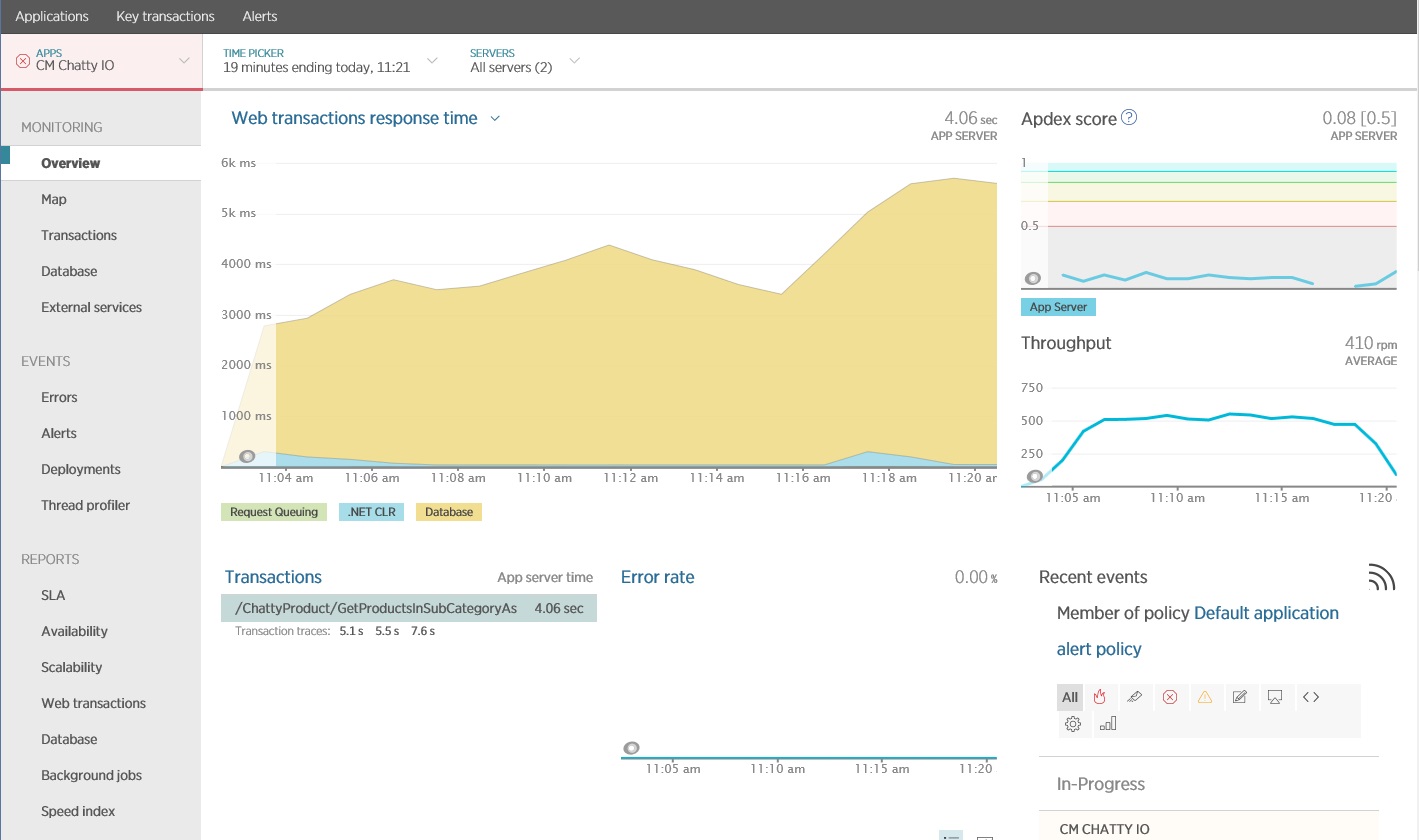
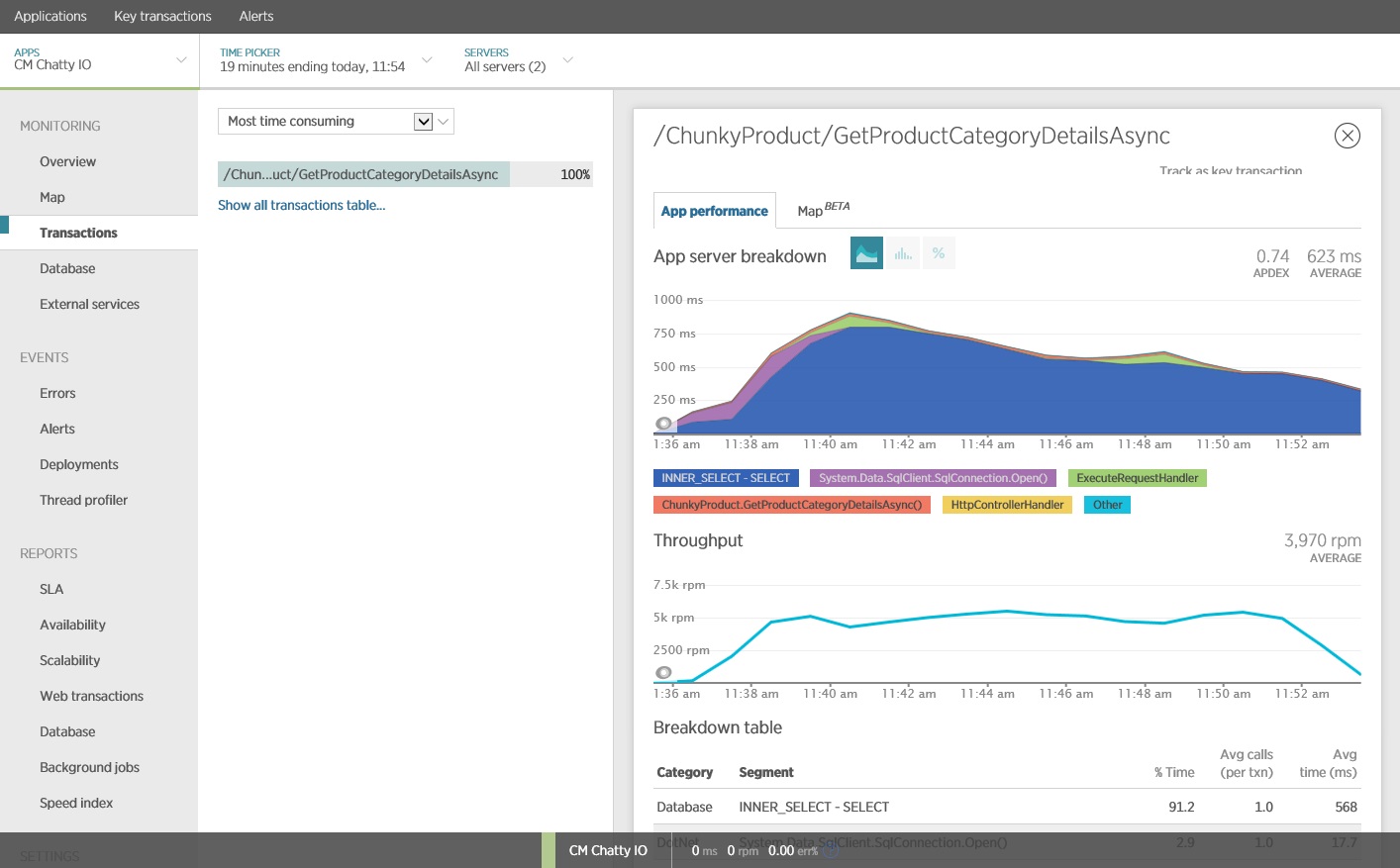
Az alkalmazásteljesítmény-figyelő (APM) csomaggal rögzítheti és elemezheti a forgalmas I/O azonosítására képes kulcs mérőszámokat. Az, hogy melyik mérőszám lesz fontos, az I/O munkaterheléstől függ. Ebben a példában az adatbázis-lekérdezések voltak az érdekes I/O kérések.
Az alábbi ábra a New Relic APM használatával létrehozott eredményeket mutatja. Az adatbázis átlagos válaszidejének csúcsa körülbelül 5,6 másodperc volt kérésenként a legnagyobb munkaterhelés közben. A rendszer a teszt során átlagosan 410 kérés támogatására volt képes percenként.
Részletes adathozzáférési információk gyűjtése
Ha figyelési adatok mélyebb vizsgálata megmutatja, hogy az alkalmazás három különböző SQL SELECT utasítást hajt végre. Ezek megfelelnek az Entity Framework által a ProductListPriceHistory, Product és ProductSubcategory táblákból való adatbeolvasásokra létrehozott kéréseknek. Ráadásul a ProductListPriceHistory táblából adatokat lekérő lekérdezés a messze leggyakoribban végrehajtott SELECT utasítás, nagyságrendekkel gyakoribb a többinél.
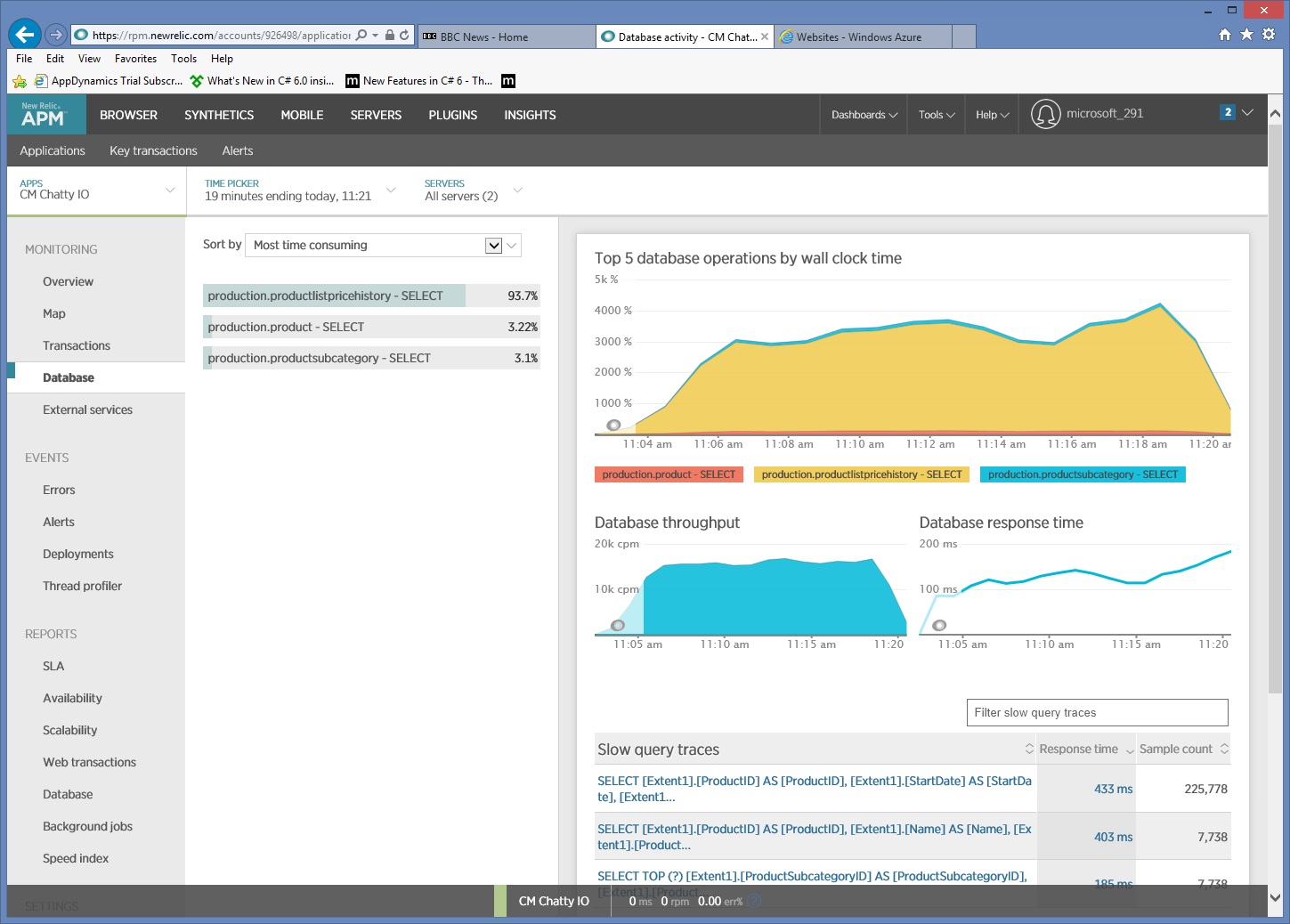
Kiderül, hogy a korábban bemutatott GetProductsInSubCategoryAsync metódus 45 SELECT lekérdezést végez el. Az alkalmazás minden lekérdezéshez megnyit egy új SQL-kapcsolatot.
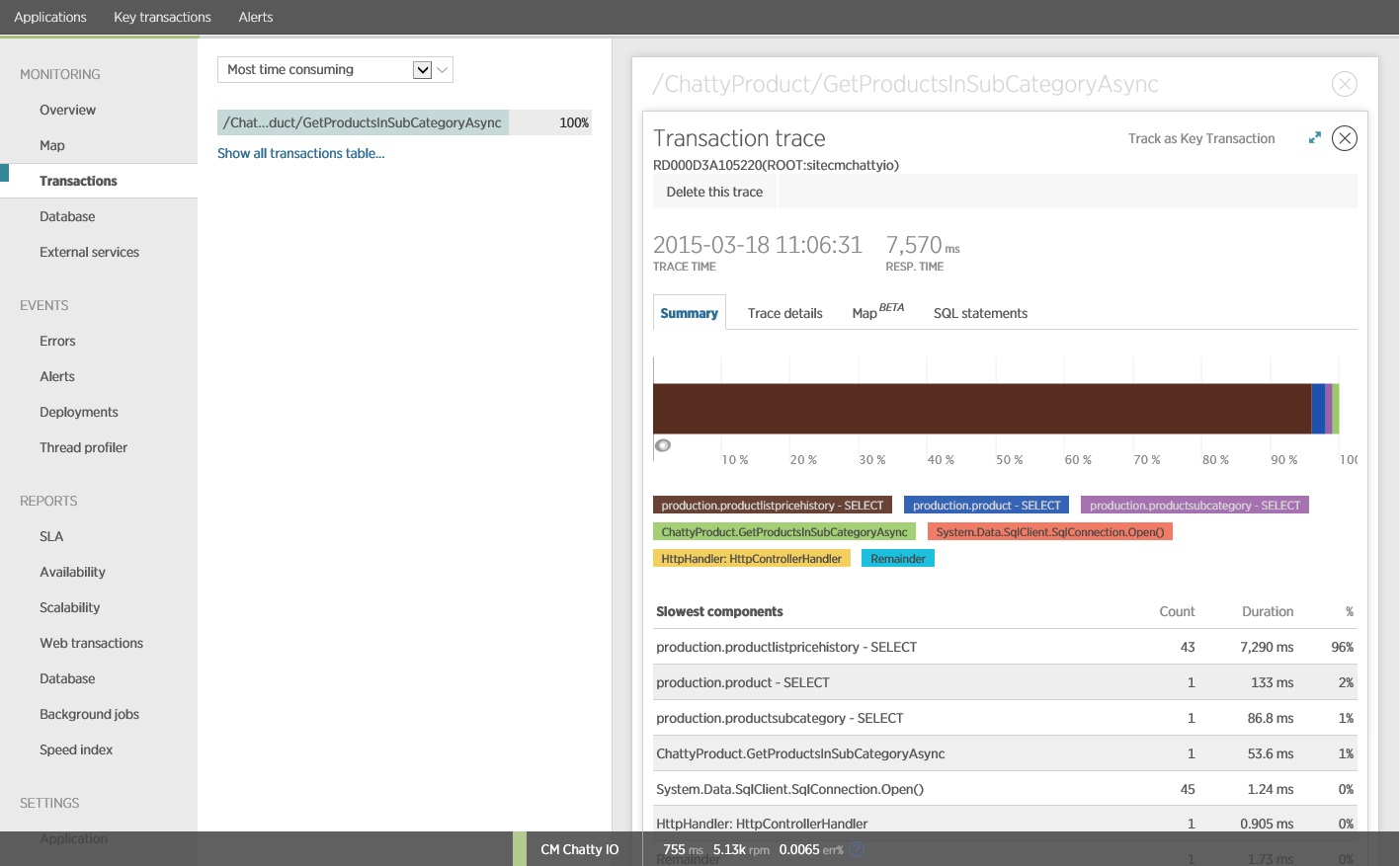
Megjegyzés:
Az ábra nyomkövetési adatokat tartalmaz a terhelésteszt GetProductsInSubCategoryAsync műveletének leglassabb példányához. Éles környezetben hasznos megvizsgálni a leglassabb példányok nyomkövetését, így látható, hogy van-e problémára utaló mintázat. Ha csak az átlagértékeket veszi figyelembe, előfordulhat, hogy elkerüli a figyelmét egy olyan probléma, amely terhelés alatt sokkal súlyosabbá válik.
A következő ábrán a ténylegesen kiadott SQL-utasítások láthatók. Az árinformációkat beolvasó lekérdezés a termék alkategória minden egyes termékéhez fut. Egy csatlakozással jelentősen csökkenthető lenne az adatbázishívások száma.
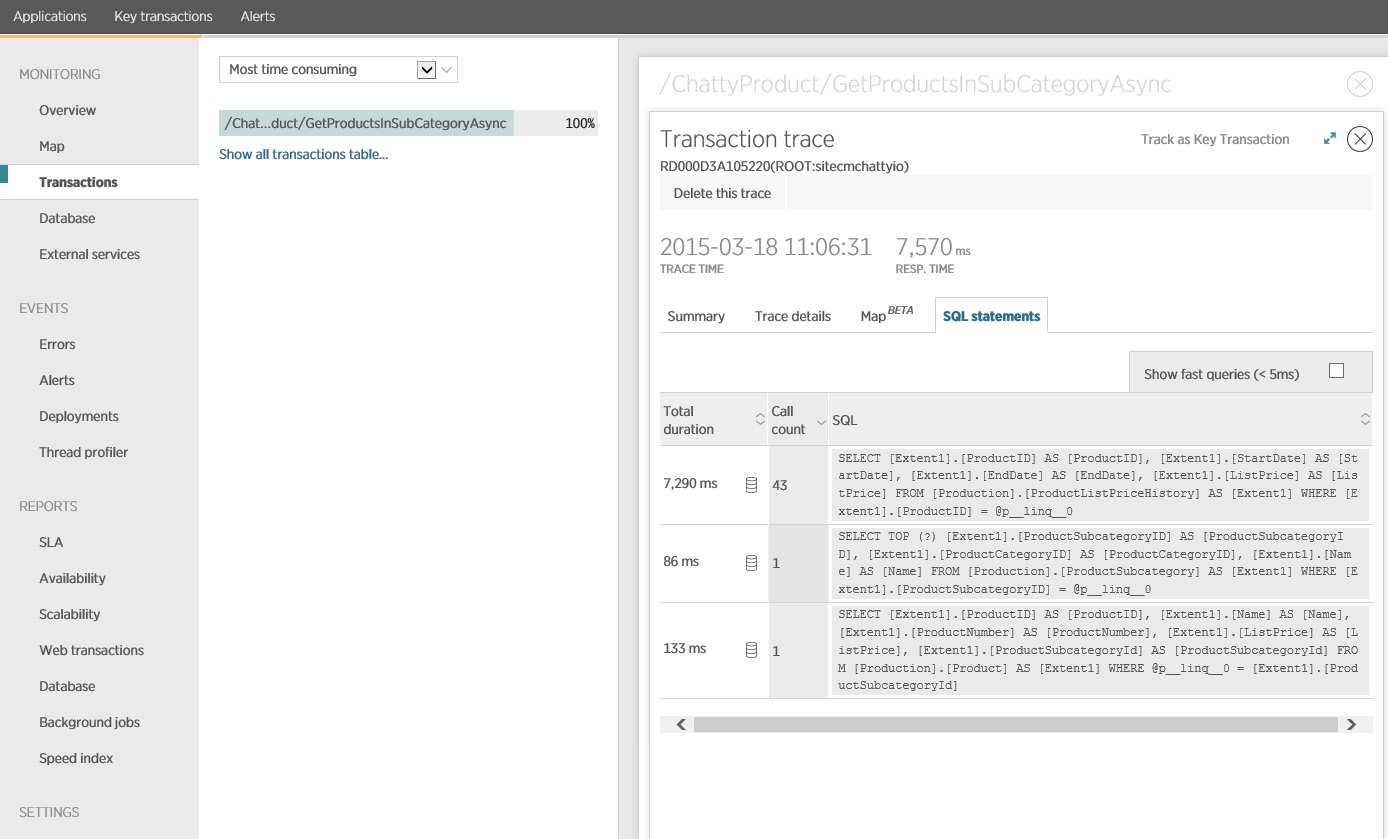
Ha O/RM-et (például Entity Framework) használ, az SQL-lekérdezések nyomon követésével bepillantást nyerhet abba, hogy hogyan fordítja az O/RM a programozott hívásokat SQL-utasításokká, és észlelhet területeket, ahol optimalizálható az adathozzáférés.
A megoldás megvalósítása és az eredmény ellenőrzése
A hívás Entity Frameworkbe való újraírása az alább eredményeket hozta.
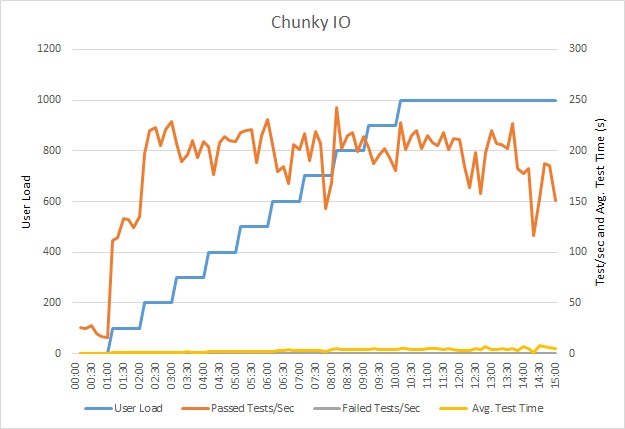
Ez a terhelésteszt ugyanazon az üzemelő példányon lett elvégezve, ugyanazzal a terhelési profillal. Ez alkalommal a diagram sokkal alacsonyabb késést mutat. A kérések átlagos ideje 1000 felhasználónál 5 és 6 másodperc között van, a legmagasabb érték majdnem egy perc volt.
Ez alkalommal a rendszer átlagosan 3970 kérést támogatott percenként (ez az érték a korábbi tesztben 410 volt).
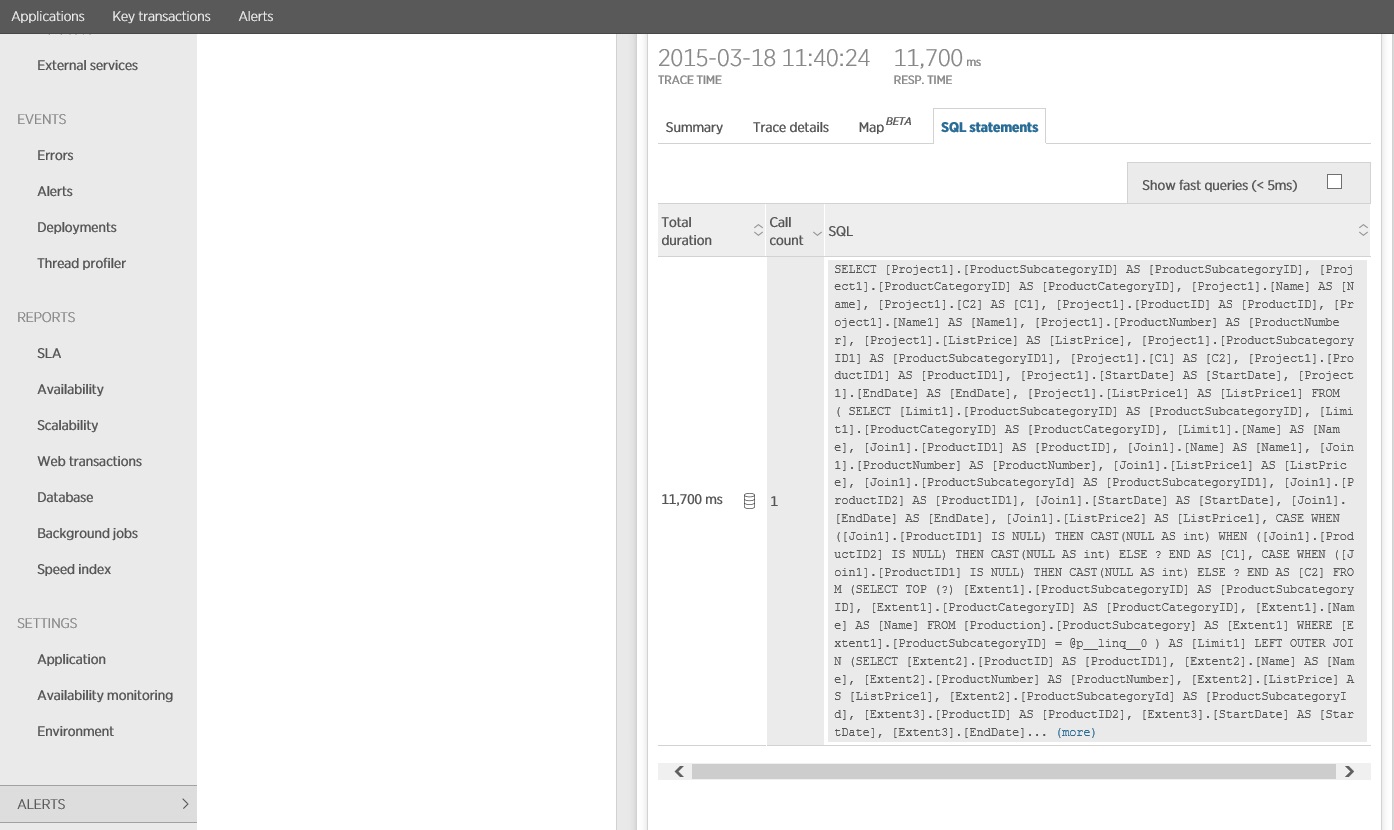
Az SQL-utasítás nyomon követéséből látható, hogy a rendszer az összes adatot egyetlen SELECT utasítással olvasta be. Noha ez a lekérdezés lényegesen összetettebb, műveletenként csak egyszer kell elvégezni. És noha az összetett illesztések költségessé válhatnak, a relációsadatbázis-rendszerek ilyen típusú lekérdezésekre vannak optimalizálva.
Kapcsolódó erőforrások
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: