A nem relációs adatbázisok olyan adatbázisok, amelyek nem használják a legtöbb hagyományos adatbázisrendszerben található sorok és oszlopok táblázatos sémáját. A nem relációs adatbázisok ehelyett olyan tárolási modellt használnak, amely a tárolt adatok típusának konkrét követelményeire van optimalizálva. Az adatok tárolhatók például egyszerű kulcs-érték párként, JSON-dokumentumként vagy élekből és csúcsokból álló gráfként.
Az adattárak közös tulajdonsága, hogy nem használnak relációs modellt. Emellett jellemzőbbek az általuk támogatott adatok típusában és az adatok lekérdezésének módjában. Az idősoros adattárak például időalapú adatsorok lekérdezéseire vannak optimalizálva. A gráfadattárak azonban az entitások közötti súlyozott kapcsolatok feltárására vannak optimalizálva. Egyik formátum sem általánosítaná jól a tranzakciós adatok kezelésének feladatát.
A NoSQL kifejezés olyan adattárakra vonatkozik, amelyek nem használnak SQL-t lekérdezésekhez. Ehelyett az adattárak más programozási nyelveket és szerkezeteket használnak az adatok lekérdezéséhez. A gyakorlatban a "NoSQL" a "nem relációs adatbázist" jelenti, annak ellenére, hogy sok ilyen adatbázis támogatja az SQL-kompatibilis lekérdezéseket. A mögöttes lekérdezés-végrehajtási stratégia azonban általában nagyon eltér attól, ahogyan egy hagyományos RDBMS ugyanazt az SQL-lekérdezést hajtaná végre.
A következő szakaszok a nem relációs vagy NoSQL-adatbázis fő kategóriáit ismertetik.
Adattárak dokumentálása
A dokumentumadattárak nevesített sztringmezők és objektumadat-értékek készletét kezelik egy dokumentumnak nevezett entitásban. Ezek az adattárak általában JSON-dokumentumok formájában tárolják az adatokat. Minden mezőérték lehet skaláris elem, például szám vagy összetett elem, például lista vagy szülő-gyermek gyűjtemény. A dokumentum mezőiben lévő adatok különböző módon kódolhatók, például XML, YAML, JSON, BSON, vagy akár egyszerű szövegként is tárolhatók. A dokumentumok mezői elérhetővé válnak a tárfelügyeleti rendszer számára, így az alkalmazások az ezekben a mezőkben szereplő értékekkel kérdezik le és szűrik az adatokat.
A dokumentumok általában egy entitás összes adatát tartalmazzák. Az, hogy mely elemek alkotnak entitást, az alkalmazástól függ. Egy entitás például tartalmazhatja egy ügyfél, egy rendelés vagy mindkettő egyvelegének adatait. Egyetlen dokumentum tartalmazhat olyan információkat, amelyek egy relációs adatbázis-kezelő rendszer (RDBMS) több relációs táblájában is elférnek. A dokumentumtár nem igényli, hogy minden dokumentum ugyanazzal a struktúrával rendelkezzen. Ez a szabad formátumú megközelítés nagyfokú rugalmasságot biztosít. Az alkalmazások például különböző adatokat tárolhatnak a dokumentumokban az üzleti követelmények változására válaszul.
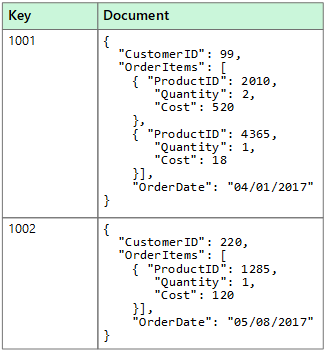
Az alkalmazás a dokumentumkulcs segítségével kérhet le dokumentumokat. A kulcs a dokumentum egyedi azonosítója, amely gyakran kivonatolt, az adatok egyenletes elosztásának elősegítése érdekében. Bizonyos dokumentum-adatbázisok automatikusan létrehozzák a kulcsot. Másokban megadhat egy dokumentumattribútumot, amelyet kulcsként használhat. Az alkalmazás emellett egy vagy több mező értéke alapján és lekérdezhet dokumentumokat. Bizonyos dokumentum-adatbázisok támogatják az indexelést, ami elősegíti az egy vagy több indexelt mező alapján történő gyors dokumentumkeresést.
Számos dokumentum-adatbázis támogatja a helyi frissítést, amely révén az alkalmazások a teljes dokumentum átírása nélkül módosíthatják az adott mezők értékeit egy dokumentumban. Az egyetlen dokumentum több mezőjén végzett olvasási és írási műveletek általában atomiak.
Kapcsolódó Azure-szolgáltatás:
Oszlopos adattárak
Az oszlopos vagy oszlopcsaládos adattár oszlopokba és sorokba rendezi az adatokat. Legegyszerűbb formájában az oszlopcsalád-adattárak nagyon hasonlóak lehetnek egy relációs adatbázishoz, legalábbis elméletileg. Az oszlopcsalád-adatbázisok valódi ereje a ritka adatok strukturálásának denormalizált megközelítésében rejlik, amely az adatok tárolásának oszloporientált megközelítéséből ered.
Az oszlopcsalád-adattárak úgy is felfoghatók, hogy táblázatos adatokat tárolnak sorokkal és oszlopokkal, de az oszlopok oszlopcsaládok néven ismert csoportokra vannak osztva. Minden oszlopcsalád logikailag összefüggő oszlopokat tartalmaz, amelyek általában egységként vannak lekérve vagy módosítva. Az egyéb, külön elérhető adatok külön oszlopcsaládokban tárolhatók. Egy oszlopcsaládon belül az új oszlopok dinamikusan hozzáadhatók, a sorok pedig ritkák is lehetnek (ez azt jelenti, hogy a soroknak nem kell minden oszlophoz értéket tartalmazniuk).
Az alábbi ábrán látható példában két oszlopcsalád szerepel: Identity és Contact Info. Az egyetlen entitás adatai minden oszlopcsaládban ugyanazt a sorkulcsot tartalmazzák. Ez a struktúra, ahol az oszlopcsalád bármely objektumának sorai dinamikusan változhatnak, az oszlopcsalád megközelítésének fontos előnye, hogy az adattár ezen formája kiválóan alkalmas különböző sémákkal rendelkező adatok tárolására.

A kulcs-/értéktárakkal vagy a dokumentum-adatbázisokkal ellentétben a legtöbb oszlopcsalád-adatbázis fizikailag kulcs sorrendben tárolja az adatokat a kivonatok kiszámítása helyett. A sorkulcs az elsődleges index, és lehetővé teszi a kulcsalapú hozzáférést egy adott kulcson vagy kulcstartományon keresztül. Egyes implementációk lehetővé teszik másodlagos indexek létrehozását egy oszlopcsalád adott oszlopaihoz. A másodlagos indexek lehetővé teszik az adatok lekérését oszlopértékek szerint a sorkulcs helyett.
A lemezen az oszlopcsalád összes oszlopa ugyanabban a fájlban van tárolva, és az egyes fájlokban meghatározott számú sor található. Nagy adathalmazok esetén ez a megközelítés teljesítménybeli előnyt hoz létre azáltal, hogy csökkenti a lemezről beolvasandó adatok mennyiségét, ha egyszerre csak néhány oszlopot kérdez le.
A sorok olvasási és írási műveletei általában egyetlen oszlopcsaládon belül atomiak, bár egyes implementációk az egész sor atomiságát biztosítják, több oszlopcsaládra kiterjedően.
Kapcsolódó Azure-szolgáltatás:
Kulcs/érték adattárak
A kulcs/érték tároló lényegében egy nagy kivonattábla. Minden egyes adatértékhez egy egyedi kulcs társul, a kulcs/érték tároló pedig ezt a kulcsot használja az adatok egy megfelelő kivonatoló függvénnyel való tárolásához. A kivonatoló algoritmus a kivonatolt kulcsok az adattárban való egyenletes elosztására van kiválasztva.
A legtöbb kulcs/érték tároló csak az egyszerű lekérdezési, beszúrási és törlési műveleteket támogatja. Egy érték (akár részleges, akár teljes) módosításához az alkalmazásnak a teljes értékre vonatkozóan felül kell írnia a meglévő adatokat. A legtöbb megvalósításban egyetlen érték olvasása vagy írása atomi műveletnek számít. Ha az érték túl nagy, az írás hosszabb időt is igénybe vehet.
Az alkalmazás tetszőleges adatokat tárolhat egy értékekből álló készletként, bár egyes kulcs/érték tárolók korlátozzák az értékek maximális méretét. A tárolt értékek a tárolórendszer szoftvere számára nem átlátszók. A sémaadatok biztosítása és értelmezése az alkalmazás feladata. Az értékek alapvetően blobok, a kulcs/érték tároló pedig egyszerűen kulcsonként olvassa be vagy tárolja az értéket.
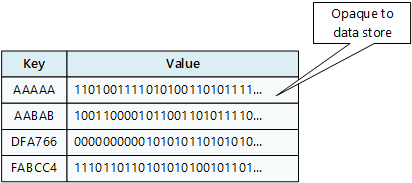
A kulcs/érték tárolók nagy mértékben optimalizálva vannak olyan alkalmazásokhoz, amelyek egyszerű kereséseket végeznek a kulcs értékével vagy egy kulcstartománysal, de kevésbé alkalmasak olyan rendszerekre, amelyek különböző kulcsok/értékek különböző tábláiban kell adatokat lekérdezni, például több táblán keresztüli adatok összekapcsolásához.
A kulcs-/értéktárolók szintén nem olyan helyzetekre vannak optimalizálva, ahol fontos a nem kulcsértékek lekérdezése vagy szűrése ahelyett, hogy csak kulcsokon alapuló kereséseket hajtanak végre. Egy relációs adatbázis esetében például egy WHERE záradékkal megkeresheti a rekordokat a nem kulcsoszlopok szűréséhez, de a kulcs/értékek tárolói általában nem rendelkeznek ilyen típusú keresési képességgel az értékekhez, vagy ha igen, az összes érték lassú vizsgálatát igényli.
Egyetlen kulcs/érték tároló lehet rendkívüli mértékben skálázható, mivel az adattár könnyedén feloszthatja az adatokat több, külön gépeken található csomópont között.
Kapcsolódó Azure-szolgáltatások:
Gráfadattárak
A gráfadattár kétféle információt, csomópontot és élet kezel. A csomópontok entitásokat jelölnek, az élek pedig az entitások közötti kapcsolatokat határozzák meg. Mind a csomópontok, mind az élek rendelkezhetnek olyan tulajdonságokkal, amelyek a táblák oszlopaihoz hasonlóan információt nyújtanak az adott csomópontról vagy élről. A szegélyeknek is lehet iránya, amely a kapcsolat természetét jelöli.
A gráfadattár célja, hogy lehetővé tegye az alkalmazások számára a csomópontok és élek hálózatán áthaladó lekérdezések hatékony végrehajtását, valamint az entitások közötti kapcsolatok elemzését. Az alábbi ábrán egy szervezet személyzeti adatai láthatók gráfként strukturálva. Az entitások az alkalmazottak és a részlegek, az élek pedig a jelentéskészítési kapcsolatokat jelzik, valamint azt, hogy melyik alkalmazott melyik részlegen dolgozik. Ebben a gráfban az élek nyilai a kapcsolatok irányát jelzik.
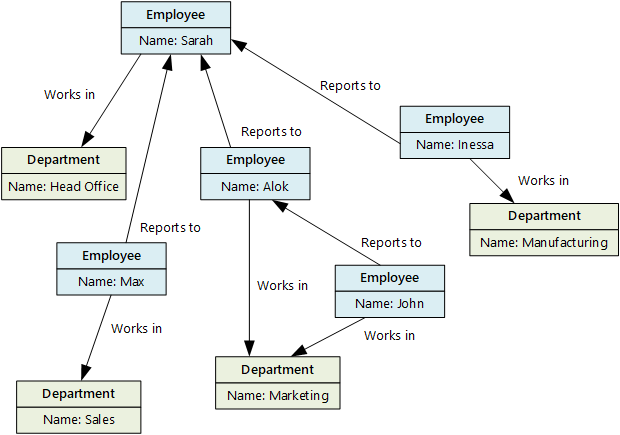
Ez a struktúra megkönnyíti az olyan lekérdezések elvégzését, mint a "Minden olyan alkalmazott megkeresése, aki közvetlenül vagy közvetve jelent Sarah-nak" vagy "Ki dolgozik ugyanabban a részlegben, mint John?" A sok entitást és kapcsolatot tartalmazó nagyméretű gráfok esetében gyorsan végezhet összetett elemzéseket. Sok gráfadatbázis használ olyan lekérdezési nyelvet, amellyel egy kapcsolatokból álló hálózat hatékonyan bejárható.
Kapcsolódó Azure-szolgáltatás:
Idősorozat-adattárak
Az idősoradatok idő szerint rendszerezett értékek, és az idősorok adattára az ilyen típusú adatokhoz van optimalizálva. Az idősorozat-adattáraknak nagyon sok írást kell támogatniuk, mivel általában nagy mennyiségű adatot gyűjtenek valós időben nagy számú forrásból. Az idősorozat-adattárak telemetriai adatok tárolására vannak optimalizálva. A forgatókönyvek IoT-érzékelőket vagy alkalmazás-/rendszerszámlálókat is tartalmaznak. A frissítések ritkák, a törlések pedig a legtöbbször tömeges műveletként történnek.
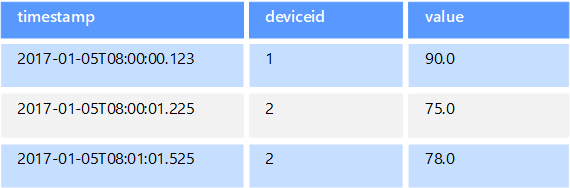
Bár az idősor-adatbázisba írt rekordok általában kicsik, gyakran nagy számú rekord van, és a teljes adatméret gyorsan nőhet. Az idősoros adattárak emellett a rendelésen kívüli és késői adatokat, az adatpontok automatikus indexelését és az időkeretekben leírt lekérdezések optimalizálását is kezelik. Ez az utolsó funkció lehetővé teszi, hogy a lekérdezések több millió adatponton és több adatfolyamon futhassanak gyorsan az idősoros vizualizációk támogatása érdekében, ami az idősoradatok felhasználásának gyakori módja.
Kapcsolódó Azure-szolgáltatások:
Objektum-adattárak
Az objektumadattárak nagy bináris objektumok vagy blobok, például képek, szövegfájlok, video- és hangstreamek, nagy alkalmazásadat-objektumok és -dokumentumok, valamint virtuálisgép-lemezképek tárolására és lekérésére vannak optimalizálva. Az objektumok a tárolt adatokból, néhány metaadatból és az objektum eléréséhez szükséges egyedi azonosítóból állnak. Az objektumtárolók úgy vannak kialakítva, hogy támogassák az egyenként nagyon nagy méretű fájlokat, valamint nagy mennyiségű teljes tárterületet biztosítanak az összes fájl kezeléséhez.
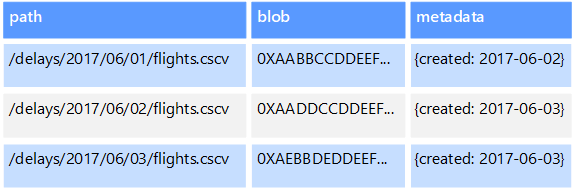
Egyes objektumadattárak több kiszolgálócsomópontra replikálnak egy adott blobot, ami gyors párhuzamos olvasást tesz lehetővé. Ez a folyamat viszont lehetővé teszi a nagyméretű fájlokban lévő adatok horizontális lekérdezését, mivel több folyamat, amelyek általában különböző kiszolgálókon futnak, egyszerre kérdezhetik le a nagy méretű adatfájlokat.
Az objektumadattárak egyik különleges esete a hálózati fájlmegosztás. A fájlmegosztások használatával a fájlok a hálózaton keresztül, szabványos hálózati protokollok, például kiszolgálói üzenetblokk (SMB) használatával érhetők el. A megfelelő biztonsági és egyidejű hozzáférés-vezérlési mechanizmusoknak köszönhetően az adatok ilyen módon való megosztása lehetővé teszi az elosztott szolgáltatások számára, hogy nagy mértékben skálázható adathozzáférést biztosítsanak az alapszintű, alacsony szintű műveletekhez, például az egyszerű olvasási és írási kérelmekhez.
Kapcsolódó Azure-szolgáltatások:
Külső indexadattárak
A külső indexadattárak lehetővé teszik a más adattárakban és szolgáltatásokban tárolt információk keresését. A külső indexek bármely adattár másodlagos indexeként szolgálnak, és nagy mennyiségű adat indexelésére használhatók, és közel valós idejű hozzáférést biztosítanak ezekhez az indexekhez.
Előfordulhat például, hogy a szövegfájlok egy fájlrendszerben vannak tárolva. Egy fájl megkeresése a fájl elérési útja alapján gyors, de a fájl tartalma alapján történő kereséshez az összes fájl vizsgálata szükséges, ami lassú. A külső indexek segítségével másodlagos keresési indexeket hozhat létre, majd gyorsan megtalálhatja a feltételeknek megfelelő fájlok elérési útját. Egy külső index egy másik példaalkalmazása az olyan kulcs-/értéktárolók, amelyek csak a kulcs alapján indexelnek. Létrehozhat egy másodlagos indexet az adatok értékei alapján, és gyorsan megkeresheti azt a kulcsot, amely egyedileg azonosítja az egyes egyező elemeket.
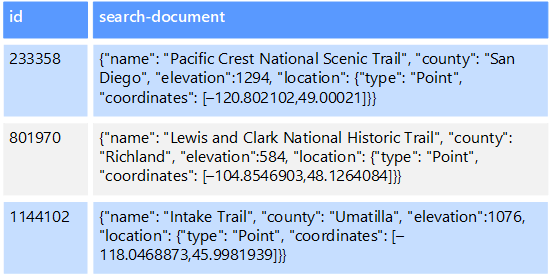
Az indexek egy indexelési folyamat futtatásával jönnek létre. Ez egy lekéréses modellel végezhető el, amelyet az adattár aktivál, vagy egy leküldéses modell használatával, amelyet alkalmazáskód indít el. Az indexek többdimenziósak lehetnek, és nagy mennyiségű szöveges adat szabadszöveges keresését támogathatják.
A külső indexadattárakat gyakran használják teljes szöveges és webes keresések támogatására. Ezekben az esetekben a keresés pontos vagy homályos lehet. Az intelligens keresés olyan dokumentumokat keres, amelyek megfelelnek egy adott feltételkészletnek, és az egyezés mértékét is kiszámítja. Egyes külső indexek támogatják a nyelvi elemzést is, amelyek szinonimák, műfajbővítések (például a "kutyák" és a "háziállatok" egyezése) és az eredet (például a "futtatás" keresése a "futtatás" és a "futtatás" kifejezésre is vonatkozik).
Kapcsolódó Azure-szolgáltatás:
Jellemző követelmények
A nem relációs adattárak gyakran más tárolási architektúrát használnak, mint a relációs adatbázisok. Pontosabban, inkább nem rendelkeznek rögzített sémával. Emellett általában nem támogatják a tranzakciókat, vagy más módon korlátozzák a tranzakciók hatókörét, és skálázhatósági okokból általában nem tartalmaznak másodlagos indexeket.
Az alábbiak az egyes nem relációs adattárakra vonatkozó követelményeket hasonlítják össze:
| Követelmény | Dokumentumadatok | Oszlopcsalád adatai | Kulcs-/értékadatok | Gráfadatok |
|---|---|---|---|---|
| Normalizálás | Denormalizált | Denormalizált | Denormalizált | Normalizált |
| Schema | Séma olvasásra | Írásra definiált oszlopcsaládok, olvasási oszlopséma | Séma olvasásra | Séma olvasásra |
| Konzisztencia (egyidejű tranzakciók között) | Állandósítható konzisztencia, dokumentumszintű garanciák | Oszlopcsaládszintű garanciák | Kulcsszintű garanciák | Gráfszintű garanciák |
| Atomitás (tranzakció hatóköre) | Gyűjtemény | Tábla | Tábla | Grafikon |
| Zárolási stratégia | Optimista (zárolásmentes) | Pesszimista (sorzárak) | Optimista (ETag) | |
| Hozzáférési minta | Véletlenszerű hozzáférés | Aggregátumok magas/széles adatokon | Véletlenszerű hozzáférés | Véletlenszerű hozzáférés |
| Indexelés | Elsődleges és másodlagos indexek | Elsődleges és másodlagos indexek | Csak elsődleges index | Elsődleges és másodlagos indexek |
| Adatalakzat | Bizonylat | Táblázatos oszlopcsaládok oszlopokkal | Kulcs és érték | Éleket és csúcsokat tartalmazó gráf |
| Ritka | Igen | Yes | Igen | Nem |
| Széles (sok oszlop/attribútum) | Igen | Igen | Nem | Nem |
| Datum mérete | Kicsi (KBs) és közepes (alacsony MBs) | Közepes (MB)-ről nagyra (alacsony GB-k) | Kicsi (KBs) | Kicsi (KBs) |
| Teljes maximális skálázás | Nagyon nagy (PC-k) | Nagyon nagy (PC-k) | Nagyon nagy (PC-k) | Nagy (TBs) |
| Követelmény | Idősorozat-adatok | Objektumadatok | Külső indexadatok |
|---|---|---|---|
| Normalizálás | Normalizált | Denormalizált | Denormalizált |
| Schema | Séma olvasásra | Séma olvasásra | Séma írásra |
| Konzisztencia (egyidejű tranzakciók között) | N.A. | N/A | N.A. |
| Atomitás (tranzakció hatóköre) | N/A | Object | N/A |
| Zárolási stratégia | N/A | Pesszimista (blobzárok) | N/A |
| Hozzáférési minta | Véletlenszerű hozzáférés és összesítés | Szekvenciális hozzáférés | Véletlenszerű hozzáférés |
| Indexelés | Elsődleges és másodlagos indexek | Csak elsődleges index | N/A |
| Adatalakzat | Táblázatos | Blobok és metaadatok | Bizonylat |
| Ritka | Nem | N.A. | Nem |
| Széles (sok oszlop/attribútum) | Nem | Yes | Igen |
| Datum mérete | Kicsi (KBs) | Nagy (GBs) a nagyon nagy (TBs) | Kicsi (KBs) |
| Teljes maximális skálázás | Nagy (alacsony TB-k) | Nagyon nagy (PC-k) | Nagy (alacsony TB-k) |
Közreműködők
Ezt a cikket a Microsoft tartja karban. Eredetileg a következő közreműködők írták.
Fő szerző:
- Zoiner Tejada | vezérigazgató és tervező
További lépések
- Relációs és NoSQL-adatok
- Elosztott NoSQL-adatbázisok ismertetése
- A Microsoft Azure-adatok alapjai: A nem relációs adatok megismerése az Azure-ban
- Nem relációs adatmodell implementálása