Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Tipp.
Ez a tartalom egy részlet a .NET Docs-on elérhető, az Azure-hoz készült, natív felhőalapú .NET-alkalmazások tervezője című e-könyvből vagy egy ingyenesen letölthető PDF-ből, amely offline is olvasható.

A relációs (SQL) és a nem relációs (NoSQL) adatbázisrendszerek két típusa, amelyeket általában natív felhőbeli alkalmazásokban implementálnak. Másképpen vannak felépítve, másként tárolják az adatokat, és más módon férnek hozzá. Ebben a szakaszban mindkettőt megvizsgáljuk. A fejezet későbbi részében egy új, NewSQL nevű adatbázis-technológiát tekintünk át.
A relációs adatbázisok évtizedek óta elterjedt technológia. Érettek, bizonyítottak és széles körben implementálva vannak. Versengő adatbázis-termékek, eszközök és szakértelem bővelkedik. A relációs adatbázisok a kapcsolódó adattáblák tárolását biztosítják. Ezek a táblák rögzített sémával rendelkeznek, az SQL (strukturált lekérdezési nyelv) használatával kezelik az adatokat, és támogatják az ACID-garanciákat: atomitást, konzisztenciát, elkülönítést és tartósságot.
A NoSQL-adatbázisok nagy teljesítményű, nem relációs adattárakra vonatkoznak. Kiválóan használhatók, méretezhetőek, rugalmasak és rendelkezésre állási jellemzőkkel rendelkeznek. Normalizált adatok tábláinak összekapcsolása helyett a NoSQL strukturálatlan vagy félig strukturált adatokat tárol, gyakran kulcs-érték párokban vagy JSON-dokumentumokban. A NoSQL-adatbázisok általában nem biztosítanak ACID-garanciákat egyetlen adatbázispartíció hatókörén túl. A második válaszidőt igénylő nagy kötetű szolgáltatások előnyben részesítik a NoSQL-adattárakat.
A NoSQL-technológiák hatása az elosztott felhőbeli natív rendszerekre nem lehet túlbecsülni. Az új adattechnológiák térbeli elterjedése megzavarta azokat a megoldásokat, amelyek egykor kizárólag relációs adatbázisokra támaszkodtak.
A NoSQL-adatbázisok számos különböző modellt tartalmaznak az adatok elérésére és kezelésére, amelyek mindegyike megfelel az adott használati eseteknek. Az 5–9. ábra négy gyakori modellt mutat be.

5–9. ábra: Adatmodellek NoSQL-adatbázisokhoz
| Modell | Jellemzők |
|---|---|
| Dokumentumtár | Az adatok és metaadatok hierarchikusan vannak tárolva az adatbázisban található JSON-alapú dokumentumokban. |
| Kulcs értéktárolója | A NoSQL-adatbázisok közül a legegyszerűbb az adatok kulcs-érték párok gyűjteményeként jelenik meg. |
| Széles oszlopos tároló | A kapcsolódó adatok beágyazott kulcs/érték párok halmazaként lesznek tárolva egyetlen oszlopban. |
| Graph Store | Az adatok csomópont-, él- és adattulajdonságokként egy gráfstruktúrában vannak tárolva. |
CAP- és PACELC-tételek
Az ilyen típusú adatbázisok közötti különbségek megértéséhez vegye figyelembe a CAP-tételt, amely az állapotot tároló elosztott rendszerekre alkalmazott alapelvek halmaza. Az 5–10. ábra a CAP-tétel három tulajdonságát mutatja be.
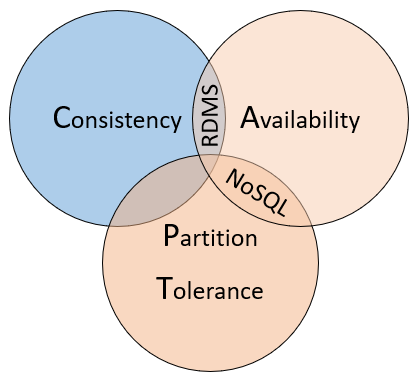
5–10. ábra. A CAP-tétel
A tétel azt állítja, hogy az elosztott adatrendszerek kompromisszumot kínálnak a konzisztencia, a rendelkezésre állás és a partíciótűrés között. És hogy bármelyik adatbázis csak a három tulajdonság közül kettőre képes garantálni:
Konzisztencia. A fürt minden csomópontja a legfrissebb adatokkal válaszol, még akkor is, ha a rendszernek blokkolnia kell a kérést, amíg az összes replika frissül. Ha egy jelenleg frissített elem "konzisztens rendszerét" kérdezi le, megvárja a választ, amíg az összes replika sikeresen frissül. Azonban a legfrissebb adatokat fogja megkapni. Meg kell érteni, hogy a CAP-tétel kontextusában használt "konzisztencia" kifejezésnek olyan technikai jelentése van, amely különbözik attól, ahogyan a "konzisztencia" az ACID-garanciák kontextusában van definiálva.
Rendelkezésre állás. A rendszer nem hibás csomópontja által fogadott minden kérésnek választ kell adnia. Egyszerűen fogalmazva, ha egy frissítendő elemhez lekérdez egy "elérhető rendszert", akkor a lehető legjobb választ kapja, amelyet a szolgáltatás ebben a pillanatban meg tud adni. Vegye figyelembe azonban, hogy a CAP-tétel által definiált "rendelkezésre állás" technikailag eltér a "magas rendelkezésre állástól", mivel hagyományosan az elosztott rendszerekről ismert.
Partíciótűrés. Garantálja, hogy a rendszer továbbra is működni fog, még akkor is, ha egy replikált adatcsomópont meghibásodik, vagy elveszíti a kapcsolatot más replikált adatcsomópontokkal.
A CAP-tétel ismerteti a hálózati partíciók konzisztenciájának és rendelkezésre állásának kezelésével kapcsolatos kompromisszumokat; azonban a konzisztenciával és a teljesítménnyel kapcsolatos kompromisszumok is léteznek hálózati partíció hiányában.
Feljegyzés
A rendelkezésre állás akkor is szenvedni fog, ha a konzisztencia helyett a rendelkezésre állást választja, a hálózati partíciók idején a rendelkezésre állás is romlik. A CAP elérhető rendszere több ügyfél számára érhető el, de nem feltétlenül "magas rendelkezésre állású" az összes ügyfél számára.
A CAP-tételt gyakran tovább bővítik a PACELC-vel , hogy átfogóbban ismertesse a kompromisszumokat. A KAP-tétel különösen fontos az időszakosan csatlakoztatott környezetekben, például az IoT-hez, a környezetfigyeléshez és a mobilalkalmazásokhoz kapcsolódó környezetekben. Ezekben a kontextusokban az eszközök particionálásra kerülhetnek a nehéz fizikai körülmények miatt, például áramkimaradások vagy zárt terekbe, például liftekbe való belépéskor. Az elosztott rendszerek, például a felhőalkalmazások esetében célszerűbb a PACELC-tételt használni, amely átfogóbb, és a hálózati partíciók hiányában is figyelembe veszi az olyan kompromisszumokat, mint a késés és a konzisztencia.
A relációs adatbázisok általában konzisztenciát és rendelkezésre állást biztosítanak, a partíciótűrést azonban nem. Ezek általában egyetlen kiszolgálóra vannak kiépítve, és vertikálisan skálázhatók, ha további erőforrásokat adnak hozzá a géphez.
Számos relációsadatbázis-rendszer támogatja a beépített replikációs funkciókat, amelyekben az elsődleges adatbázis másolatai más másodlagos kiszolgálópéldányokra is létrehozhatók. Az írási műveletek az elsődleges példányra kerülnek, és replikálódnak az egyes másodtárakba. Hiba esetén az elsődleges példány feladatátvételt végezhet egy másodlagos példányon a magas rendelkezésre állás biztosítása érdekében. A másodfokok olvasási műveletek terjesztésére is használhatók. Bár az írási műveletek mindig az elsődleges replikára kerülnek, az olvasási műveletek átirányíthatók bármelyik másodpéldányra a rendszerterhelés csökkentése érdekében.
Az adatok horizontálisan particionálhatók több csomóponton, például horizontálisan is. A horizontális skálázás azonban jelentősen növeli a működési többletterhelést azáltal, hogy adatokat köp le számos olyan adatra, amely nem tud könnyen kommunikálni. A kezelés költséges és időigényes lehet. A táblaillesztéseket, tranzakciókat és hivatkozási integritást tartalmazó relációs funkciók súlyos teljesítménybeli büntetést igényelnek a horizontálisan elosztott üzemelő példányokban.
A replikációs konzisztencia és a helyreállítási pont célkitűzései úgy hangolhatók, hogy a replikáció szinkron vagy aszinkron módon történik-e. Ha az adatreplikák elveszítik a hálózati kapcsolatot egy "nagy konzisztens" vagy szinkron relációs adatbázisfürtben, akkor nem tud írni az adatbázisba. A rendszer elutasítja az írási műveletet, mivel nem tudja replikálni a módosítást a másik adatreplikára. A tranzakció befejeződése előtt minden adatreplikának frissítenie kell.
A NoSQL-adatbázisok általában támogatják a magas rendelkezésre állást és a partíciótűrést. Horizontálisan skálázhatók, gyakran árucikk-kiszolgálókon. Ez a megközelítés óriási rendelkezésre állást biztosít mind a földrajzi régiókon belül, mind a különböző régiókban, csökkentett költséggel. Az adatok particionálása és replikálása ezeken a gépeken vagy csomópontokon redundanciát és hibatűrést biztosít. A konzisztencia általában konszenzusos protokollokkal vagy kvórummechanizmusokkal van hangolva. Nagyobb ellenőrzést biztosítanak a szinkron és az aszinkron replikáció relációs rendszerekben történő finomhangolása közötti kompromisszumok között.
Ha az adatreplikák elveszítik a kapcsolatot egy "magas rendelkezésre állású" NoSQL-adatbázisfürtben, akkor is végrehajthat egy írási műveletet az adatbázisba. Az adatbázisfürt lehetővé teszi az írási műveletet, és amint elérhetővé válik, frissíti az egyes adatreplikákat. A több írható replikát támogató NoSQL-adatbázisok tovább erősíthetik a magas rendelkezésre állást azáltal, hogy elkerülik a feladatátvétel szükségességét a helyreállítási idő célkitűzésének optimalizálása során.
A modern NoSQL-adatbázisok jellemzően particionálási képességeket implementálnak a rendszer kialakítása során. A partíciókezelés gyakran beépített az adatbázisba, az útválasztás pedig elhelyezési tippeken keresztül érhető el – ezt gyakran partíciókulcsoknak is nevezik. A rugalmas adatmodellekkel a NoSQL-adatbázisok csökkenthetik a sémakezelés terheit, és javíthatják a rendelkezésre állást az adatmodell-módosításokat igénylő alkalmazásfrissítések telepítésekor.
A magas rendelkezésre állás és a nagy méretezhetőség gyakran kritikusabb az üzlet szempontjából, mint a relációs táblák összekapcsolása és a hivatkozási integritás. A fejlesztők olyan technikákat és mintákat implementálhatnak, mint a Sagas, a CQRS és az aszinkron üzenetkezelés, hogy átfogják a végleges konzisztenciát.
Napjainkban ügyelni kell a KAP-tétel korlátainak mérlegelésére. Megjelent egy új típusú adatbázis, a NewSQL, amely kiterjeszti a relációs adatbázismotort a horizontális skálázhatóság és a NoSQL-rendszerek skálázható teljesítményének támogatására.
A relációs és a NoSQL-rendszerek szempontjai
Adott adatkövetelmények alapján a natív felhőbeli mikroszolgáltatások relációs, NoSQL-adattárat vagy mindkettőt implementálhatnak.
| Fontolja meg a NoSQL-adattárat, ha: | Fontolja meg a relációs adatbázist, ha: |
|---|---|
| Nagy mennyiségű számítási feladatokkal rendelkezik, amelyek nagy léptékben kiszámítható késést igényelnek (például ezredmásodpercben mért késést, miközben másodpercenként több millió tranzakciót hajt végre) | A számítási feladatok mennyisége általában másodpercenként több ezer tranzakción belül elfér |
| Az adatok dinamikusak és gyakran változnak | Az adatok rendkívül strukturáltak, és hivatkozási integritást igényelnek |
| A kapcsolatok lehetnek de normalizált adatmodellek | A kapcsolatok a normalizált adatmodelleken lévő táblázatos illesztéseken keresztül fejeződnek ki |
| Az adatlekérés egyszerű és táblaillesztés nélkül fejezhető ki | Összetett lekérdezésekkel és jelentésekkel dolgozik |
| Az adatok általában földrajzi helyeken replikálódnak, és a konzisztencia, a rendelkezésre állás és a teljesítmény finomabb szabályozását igénylik | Az adatok általában központosítottak, vagy aszinkron módon replikálhatók |
| Az alkalmazás üzembe lesz helyezve az árualapú hardvereken, például nyilvános felhőkben | Az alkalmazás nagy, csúcskategóriás hardverre lesz üzembe helyezve |
A következő szakaszokban bemutatjuk az Azure-felhőben elérhető lehetőségeket a natív felhőbeli adatok tárolására és kezelésére.
Adatbázis szolgáltatásként
Első lépésként kiépíthet egy Azure-beli virtuális gépet, és telepítheti az egyes szolgáltatásokhoz választott adatbázist. Bár teljes mértékben szabályozná a környezetet, lemondhat a felhőplatform számos beépített funkciójára. Az egyes szolgáltatások virtuális gépének és adatbázisának felügyeletéért is ön felel. Ez a megközelítés gyorsan időigényessé és költségessé válhat.
Ehelyett a natív felhőbeli alkalmazások előnyben részesítik az adatbázisként szolgáltatásként (DBaaS) közzétett adatszolgáltatásokat. A felhőszolgáltató által teljes mértékben felügyelt szolgáltatások beépített biztonságot, méretezhetőséget és monitorozást biztosítanak. A szolgáltatás birtoklása helyett egyszerűen háttérszolgáltatásként használja. A szolgáltató nagy léptékben üzemelteti az erőforrást, és a teljesítményért és a karbantartásért felelős.
Ezek a felhőbeli rendelkezésre állási zónákban és régiókban konfigurálhatók a magas rendelkezésre állás érdekében. Mindegyik támogatja az igény szerinti kapacitást és a használatalapú fizetéses modellt. Az Azure különböző típusú felügyelt adatszolgáltatási lehetőségeket kínál, amelyek mindegyike egyedi előnyökkel jár.
Először az Azure-ban elérhető relációs DBaaS-szolgáltatásokat fogjuk megvizsgálni. Látni fogja, hogy a Microsoft zászlóshajója, az SQL Server-adatbázis számos nyílt forráskódú lehetőséggel együtt érhető el. Ezután az Azure-beli NoSQL-adatszolgáltatásokról lesz szó.
Azure relációs adatbázisok
A relációs adatokat igénylő natív felhőbeli mikroszolgáltatások esetében az Azure négy felügyelt relációs adatbázist kínál szolgáltatásként (DBaaS) az 5–11. ábrán látható módon.

5–11. ábra. Az Azure-ban elérhető felügyelt relációs adatbázisok
Az előző ábrán figyelje meg, hogy mindegyik egy közös DBaaS-infrastruktúrára épül, amely további költségek nélkül tartalmazza a kulcsfontosságú képességeket.
Ezek a funkciók különösen fontosak azoknak a szervezeteknek, amelyek nagy számú adatbázist építenek ki, de korlátozott erőforrásokkal rendelkeznek a felügyeletükhöz. Az Azure-adatbázist percek alatt kiépítheti a processzormagok, a memória és az alapul szolgáló tároló mennyiségének kiválasztásával. Az adatbázist menet közben skálázhatja, és dinamikusan állíthatja be az erőforrásokat állásidő nélkül.
Azure SQL Database
A Microsoft SQL Serverben jártas fejlesztői csapatoknak érdemes megfontolni az Azure SQL Database használatát. Ez egy teljes körűen felügyelt, szolgáltatásként nyújtott relációs adatbázis (DBaaS) a Microsoft SQL Server adatbázismotorján alapul. A szolgáltatás számos olyan funkciót oszt meg, amelyek az SQL Server helyszíni verziójában találhatók, és az SQL Server adatbázismotor legújabb stabil verzióját futtatja.
A natív felhőbeli mikroszolgáltatásokkal való használathoz az Azure SQL Database három üzembe helyezési lehetőséggel érhető el:
Az önálló adatbázisok egy teljes mértékben felügyelt SQL Database-adatbázist jelölnek, amely az Azure-felhőben futó Azure SQL Database-kiszolgálón fut. Az adatbázis foglaltnak minősül, mivel nincs konfigurációs függősége a mögöttes adatbázis-kiszolgálón.
A felügyelt példány a Microsoft SQL Server adatbázismotor teljes körűen felügyelt példánya, amely közel 100%-os kompatibilitást biztosít egy helyszíni SQL Serverrel. Ez a beállítás támogatja a nagyobb, akár 35 TB-os adatbázisokat, és egy Azure-beli virtuális hálózatba kerül a jobb elkülönítés érdekében.
Az Azure SQL Database kiszolgáló nélküli számítási szint egyetlen adatbázishoz, amely automatikusan méretezhető a számítási feladatok igényei alapján. Csak a másodpercenként felhasznált számítási mennyiségért számlál. A szolgáltatás jól használható időszakos, kiszámíthatatlan használati mintákkal rendelkező, inaktivitási időszakokkal rendelkező számítási feladatokhoz. A kiszolgáló nélküli számítási szint automatikusan szünetelteti az adatbázisokat inaktív időszakokban, így csak a tárolási díjak számlázása történik. A tevékenység visszatérésekor automatikusan folytatódik.
A hagyományos Microsoft SQL Server-veremen túl az Azure három népszerű nyílt forráskódú adatbázis felügyelt verzióit is tartalmazza.
Nyílt forráskódú adatbázisok az Azure-ban
A nyílt forráskódú relációs adatbázisok népszerű választássá váltak a natív felhőbeli alkalmazások számára. Sok vállalat előnyben részesíti őket a kereskedelmi adatbázis-termékeknél, különösen a költségmegtakarítás érdekében. Számos fejlesztőcsapat élvezi a rugalmasságot, a közösség által támogatott fejlesztést, valamint az eszközök és bővítmények ökoszisztémáját. A nyílt forráskódú adatbázisok több felhőszolgáltatón is üzembe helyezhetők, így minimalizálható a "szállítói zárolás" miatti aggodalom.
A fejlesztők könnyedén önállóan üzemeltethetnek bármilyen nyílt forráskódú adatbázist egy Azure-beli virtuális gépen. Ez a megközelítés teljes körű vezérlés mellett az adatbázis és a virtuális gép felügyeletét, monitorozását és karbantartását is lehetővé teszi.
A Microsoft azonban továbbra is elkötelezett az Azure "nyílt platform" fenntartása mellett, mivel számos népszerű nyílt forráskódú adatbázist kínál teljes körűen felügyelt DBaaS-szolgáltatásként.
Azure adatbázis MySQL-hoz
A MySQL egy nyílt forráskódú relációs adatbázis, amely a LAMP szoftververemre épülő alkalmazások alappillére. Széles körben választott olvasási nagy számítási feladatok, ez által használt számos nagy szervezetek, beleértve a Facebook, Twitter, és a YouTube. A közösségi kiadás ingyenesen érhető el, míg a nagyvállalati kiadás licencvásárlást igényel. Az eredetileg 1995-ben létrehozott terméket a Sun Microsystems vásárolta meg 2008-ban. Az Oracle 2010-ben szerezte be a Sunt és a MySQL-t.
Az Azure Database for MySQL egy felügyelt relációsadatbázis-szolgáltatás, amely a nyílt forráskódú MySQL-kiszolgálómotoron alapul. A MySQL Community kiadást használja. Az Azure MySQL-kiszolgáló a szolgáltatás felügyeleti pontja. Ez ugyanaz a MySQL-kiszolgálómotor, amelyet a helyszíni üzemelő példányokhoz használnak. A motor kiszolgálónként vagy kiszolgálónként több adatbázist is létrehozhat, amelyek erőforrásokat osztanak meg. Továbbra is kezelheti az adatokat ugyanazokkal a nyílt forráskódú eszközökkel anélkül, hogy új készségeket kellene elsajátítania vagy virtuális gépeket kellene kezelnie.
Azure Database for MariaDB (Azure Adatbázis a MariaDB számára)
A MariaDB Server egy másik népszerű nyílt forráskódú adatbázis-kiszolgáló. A MySQL elágazásaként jött létre, amikor az Oracle megvásárolta a MySQL-t birtokba vevő Sun Microsystemst. A szándék az volt, hogy a MariaDB nyílt forráskódú maradjon. Mivel a MariaDB a MySQL elágazása, az adatok és a tábladefiníciók kompatibilisek, és az ügyfélprotokollok, struktúrák és API-k szorosan össze vannak állítva.
A MariaDB erős közösséggel rendelkezik, és sok nagyvállalat használja. Bár az Oracle továbbra is fenntartja, fejleszti és támogatja a MySQL-t, a MariaDB alapítvány kezeli a MariaDB-t, lehetővé téve a termékhez és a dokumentációhoz való nyilvános hozzájárulást.
Az Azure Database for MariaDB egy teljes mértékben felügyelt relációs adatbázis szolgáltatásként az Azure-felhőben. A szolgáltatás a MariaDB community edition kiszolgálómotoron alapul. Kiszámítható teljesítménnyel és dinamikus skálázhatósággal képes kezelni a kritikus fontosságú számítási feladatokat.
Azure Database for PostgreSQL
A PostgreSQL egy nyílt forráskódú relációs adatbázis több mint 30 éves aktív fejlesztéssel. A PostgreSQL a megbízhatóság és az adatintegritás szempontjából erős hírnévvel rendelkezik. Ez a funkció gazdag, SQL-kompatibilis, és a MySQL-nél nagyobb teljesítményűnek tekinthető – különösen összetett lekérdezésekkel és nehéz írásokkal rendelkező számítási feladatok esetén. Számos nagyvállalat, köztük az Apple, a Red Hat és a Fujitsu a PostgreSQL használatával készített termékeket.
Az Azure Database for PostgreSQL egy teljes mértékben felügyelt relációs adatbázis-szolgáltatás, amely a nyílt forráskódú Postgres-adatbázismotoron alapul. A szolgáltatás számos fejlesztési platformot támogat, többek között a C++, a Java, a Python, a Node, a C# és a PHP használatát. A PostgreSQL-adatbázisokat a parancssori felület eszközzel vagy az Azure Data Migration Service-vel migrálhatja.
Az Azure Database for PostgreSQL két üzembe helyezési lehetőséggel érhető el:
Az egykiszolgálós üzembe helyezési lehetőség egy központi felügyeleti pont több adatbázishoz, amelyeken számos adatbázis üzembe helyezhető. A díjszabás kiszolgálónként, magok és tárolók alapján van strukturálva.
A Rugalmas skálázás (Citus) lehetőséget a Citus Data technológia működteti. Lehetővé teszi a nagy teljesítményt azáltal , hogy horizontálisan skáláz egy adatbázist több száz csomóponton, hogy gyors teljesítményt és skálázást biztosítson. Ez a beállítás lehetővé teszi, hogy a motor több adatot elférjen a memóriában, több száz csomóponton párhuzamosítsa a lekérdezéseket, és gyorsabban indexelje az adatokat.
NoSQL-adatok az Azure-ban
A Cosmos DB egy teljes körűen felügyelt, globálisan elosztott NoSQL-adatbázis-szolgáltatás az Azure-felhőben. Számos nagyvállalat, köztük a Coca-Cola, a Skype, az ExxonMobil és a Liberty Mutual is elfogadta.
Ha a szolgáltatások gyors választ igényelnek a világ bármely pontjáról, magas rendelkezésre állással vagy rugalmas méretezhetőséggel, a Cosmos DB nagyszerű választás. Az 5–12. ábra a Cosmos DB-t mutatja.
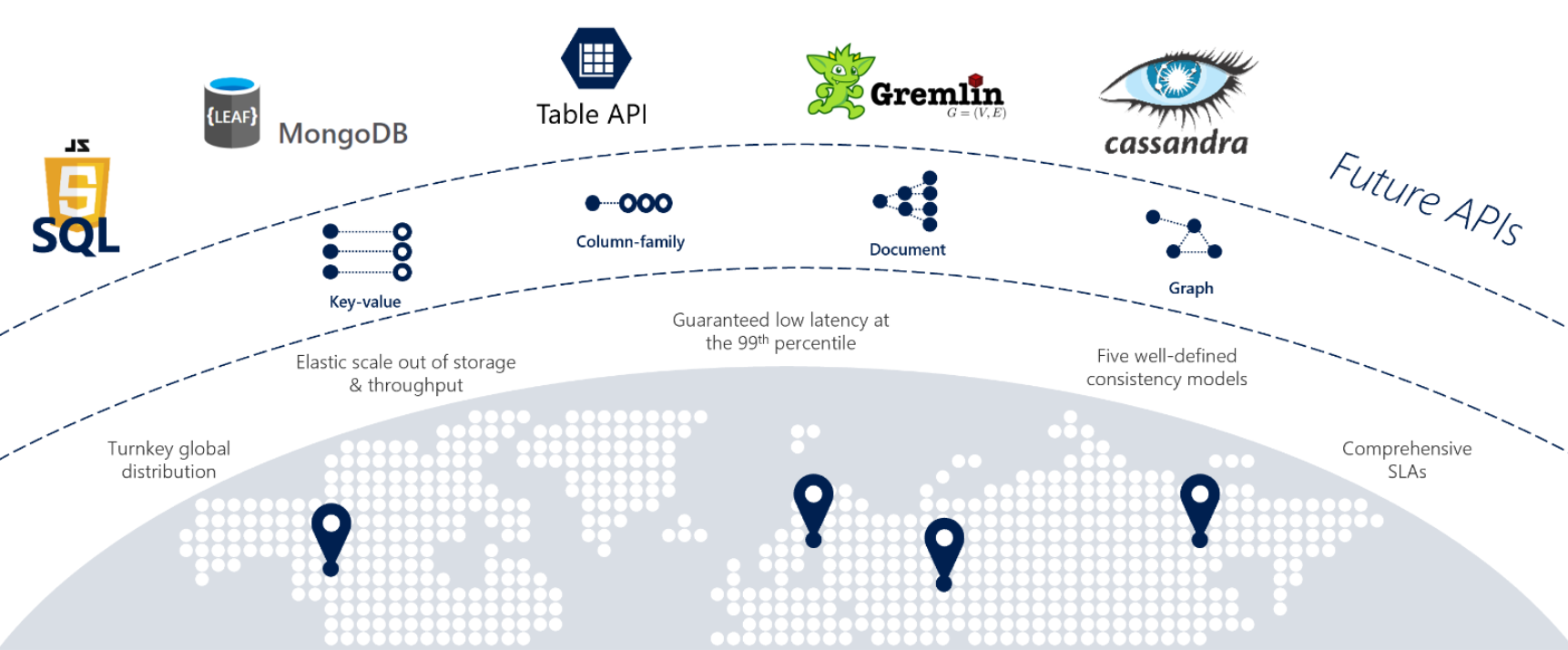
5–12. ábra: Az Azure Cosmos DB áttekintése
Az előző ábra a Cosmos DB-ben elérhető beépített natív felhőbeli képességeket mutatja be. Ebben a szakaszban közelebbről is megvizsgáljuk őket.
Globális támogatás
A natív felhőalkalmazások gyakran globális célközönséget igényelnek, és globális skálázást igényelnek.
A Cosmos-adatbázisokat régiók vagy világszerte terjesztheti, az adatokat a felhasználók közelében helyezheti el, javíthatja a válaszidőt és csökkentheti a késést. A szolgáltatások szüneteltetése vagy ismételt üzembe helyezése nélkül is hozzáadhat vagy eltávolíthat adatbázist egy régióból. A háttérben a Cosmos DB transzparens módon replikálja az adatokat az egyes konfigurált régiókba.
A Cosmos DB globális szinten támogatja az aktív/aktív fürtözést, így bármely adatbázis-régiót konfigurálhat írások és olvasások támogatására.
A Többrégiós írási protokoll a Cosmos DB egyik fontos funkciója, amely a következő funkciókat teszi lehetővé:
Korlátlan rugalmas írási és olvasási skálázhatóság.
99,999%-os olvasási és írási rendelkezésre állás az egész világon.
A garantált olvasási és írási műveletek kevesebb mint 10 ezredmásodpercben, a 99. percentilisben szolgálnak ki.
A Cosmos DB Multi-Homing API-kkal a mikroszolgáltatás automatikusan értesül a legközelebbi Azure-régióról, és kéréseket küld neki. A cosmos DB konfigurációmódosítások nélkül azonosítja a legközelebbi régiót. Ha egy régió elérhetetlenné válik, a Multi-Homing funkció automatikusan átirányítja a kéréseket a legközelebbi elérhető régióba.
Többmodelles támogatás
A monolitikus alkalmazások felhőbeli natív architektúrára való áttérésekor a fejlesztői csapatoknak néha nyílt forráskódú, NoSQL-adattárakat kell migrálniuk. A Cosmos DB többmodelles adatplatformjával segít megőrizni az ezekben a NoSQL-adattárakban lévő befektetéseit. Az alábbi táblázat a támogatott NoSQL kompatibilitási API-kat mutatja be.
| Szolgáltató | Leírás |
|---|---|
| NoSQL API | A NoSQL API dokumentumformátumban tárolja az adatokat |
| Mongo DB API | Mongo DB API-k és JSON-dokumentumok támogatása |
| Gremlin API | Támogatja a Gremlin API-t gráfalapú csomópontokkal és éladat-ábrázolásokkal |
| Cassandra API | Támogatja a Casandra API-t széles oszlopos adatmegjelenítésekhez |
| Táblázat API | Prémium szintű fejlesztésekkel támogatja az Azure Table Storage-t |
| PostgreSQL API | Felügyelt szolgáltatás a PostgreSQL bármilyen szintű futtatásához |
A fejlesztői csapatok minimális adat- vagy kódmódosítással áttelepíthetik a meglévő Mongo-, Gremlin- vagy Cassandra-adatbázisokat a Cosmos DB-be. Új alkalmazások esetén a fejlesztői csapatok választhatnak a nyílt forráskódú lehetőségek vagy a beépített SQL API-modell közül.
A Cosmos belsőleg egyszerű, primitív adattípusokból álló strukturált formátumban tárolja az adatokat. Az adatbázismotor minden egyes kéréshez lefordítja a primitív adatokat a kiválasztott modellábrázolásra.
Az előző táblázatban jegyezze fel a Table API lehetőséget. Ez az API az Azure Table Storage fejlődése. Mindkettő ugyanazzal az alapul szolgáló táblamodellel rendelkezik, de a Cosmos DB Table API prémium szintű fejlesztéseket ad hozzá, amelyek nem érhetők el az Azure Storage API-ban. Az alábbi táblázat a funkciókkal ellentétben áll.
| Szolgáltatás | Azure táblázat-tároló | Azure Cosmos DB (adatbázis) |
|---|---|---|
| Késés | Gyors | Egyjegyű ezredmásodperc késés olvasáshoz és íráshoz bárhol a világon |
| Átfutás | 20 000 művelet korlátja táblánként | Korlátlan műveletek táblánként |
| Globális terjesztés | Egyrégió opcionális egy másodlagos olvasási régióval | Kulcsrakész disztribúciók minden régióban automatikus feladatátvétellel |
| Indexelés | Csak partíció- és sorkulcs-tulajdonságokhoz érhető el | Az összes tulajdonság automatikus indexelése |
| Díjszabás | Hideg számítási feladatokhoz optimalizálva (alacsony átviteli sebesség : tárolási arány) | Gyors számítási feladatokhoz optimalizálva (magas átviteli sebesség : tárolási arány) |
Az Azure Table Storage-t használó mikroszolgáltatások egyszerűen migrálhatók a Cosmos DB Table API-ba. Nincs szükség kódmódosításra.
Beállítható konzisztencia
A Relációs vs. NoSQL szakasz korábbi részében az adatkonzisztencia témáját tárgyaltuk. Az adatkonzisztencia az adatok integritására utal. Az elosztott adatokkal rendelkező natív felhőszolgáltatások replikációra támaszkodnak, és alapvető kompromisszumot kell hozniuk az olvasási konzisztencia, a rendelkezésre állás és a késés között.
A legtöbb elosztott adatbázis lehetővé teszi a fejlesztők számára, hogy két konzisztenciamodell közül válasszanak: erős konzisztencia és végleges konzisztencia. Az erős konzisztencia az adatprogramozhatóság arany szabványa. Garantálja, hogy egy lekérdezés mindig a legfrissebb adatokat adja vissza , még akkor is, ha a rendszernek késéssel kell várnia, amíg egy frissítés replikálódik az összes adatbázis-másolatban. Bár a végleges konzisztenciára konfigurált adatbázisok azonnal visszaadják az adatokat, még akkor is, ha nem ez a legfrissebb másolat. Ez utóbbi lehetőség nagyobb rendelkezésre állást, nagyobb skálázást és nagyobb teljesítményt tesz lehetővé.
Az Azure Cosmos DB öt jól definiált konzisztenciamodellt kínál az 5–13. ábrán.

5–13. ábra: Cosmos DB konzisztenciaszintek
Ezek a lehetőségek lehetővé teszik, hogy pontos döntéseket és részletes kompromisszumokat hozzon az adatok konzisztenciájára, rendelkezésre állására és teljesítményére vonatkozóan. A szinteket az alábbi táblázat mutatja be.
| Konzisztenciaszint | Leírás |
|---|---|
| Végleges | Nincs megrendelési garancia az olvasásra. A replikák végül összefutnak. |
| Állandó előtag | Az olvasások továbbra is véglegesek, de a rendszer az adatokat abban a sorrendben adja vissza, amelyben meg van írva. |
| Munkamenet | Garantálja, hogy az aktuális munkamenet során írt adatokat elolvashatja. Ez az alapértelmezett konzisztenciaszint. |
| Korlátozott frissesség | Beolvassa a nyomvonal-írásokat a megadott időközök szerint. |
| Erős | Az olvasások garantáltan visszaadják az elem legújabb véglegesített verzióját. Az ügyfél soha nem lát nem véglegesített vagy részleges olvasást. |
A 9 golyós: Cosmos DB konzisztenciaszintek magyarázata című cikkben Jeremy Likness, a Microsoft programmenedzsere kiváló magyarázatot nyújt az öt modellre.
Particionálás
Az Azure Cosmos DB automatikus particionálást használ egy adatbázis skálázásához , hogy megfeleljen a natív felhőbeli szolgáltatások teljesítményigényének.
Adatbázisok, tárolók és elemek létrehozásával kezelheti az adatokat a Cosmos DB-adatokban.
A tárolók Cosmos DB-adatbázisban élnek, és az elemek séma-agnosztikus csoportosítását jelölik. Az elemek a tárolóhoz hozzáadott adatok. Dokumentumként, sorként, csomópontként vagy élként vannak ábrázolva. A rendszer automatikusan indexeli a tárolóhoz hozzáadott összes elemet.
A tároló particionálásához az elemek különböző részhalmazokra, úgynevezett logikai partíciókra vannak osztva. A logikai partíciók feltöltése a tároló minden eleméhez társított partíciókulcs értéke alapján történik. Az 5–14. ábra két tárolót jelenít meg egy partíciókulcs-érték alapján logikai partícióval.

5–14. ábra: Cosmos DB particionálási mechanika
Az előző ábrán látható, hogy az egyes elemek tartalmaznak egy "város" vagy "repülőtér" partíciókulcsot. A kulcs határozza meg az elem logikai partícióját. A városkóddal rendelkező elemek a bal oldali tárolóhoz, a repülőtéri kóddal ellátott elemekhez pedig a jobb oldali tárolóhoz vannak rendelve. A partíciókulcs értékének az azonosítóval való kombinálásával létrejön egy elem indexe, amely egyedileg azonosítja az elemet.
A Cosmos DB belsőleg automatikusan kezeli a logikai partíciók fizikai partíciókon való elhelyezését a tároló méretezhetőségének és teljesítményigényének kielégítése érdekében. Az alkalmazás átviteli sebességének és tárolási követelményeinek növekedésével az Azure Cosmos DB nagyobb számú kiszolgálón terjeszti újra a logikai partíciókat. Az újraterjesztési műveleteket a Cosmos DB felügyeli, és megszakítás vagy állásidő nélkül hívja meg.
NewSQL-adatbázisok
A NewSQL egy új adatbázis-technológia, amely egyesíti a NoSQL elosztott méretezhetőségét a relációs adatbázisok ACID-garanciáival. A NewSQL-adatbázisok olyan üzleti rendszerek számára fontosak, amelyeknek nagy mennyiségű adatot kell feldolgozni elosztott környezetekben, teljes tranzakciós támogatással és ACID-megfelelőségtel. Bár a NoSQL-adatbázisok nagy méretezhetőséget biztosítanak, nem garantálják az adatok konzisztenciáját. Az inkonzisztens adatok időszakos problémái terhet róhatnak a fejlesztői csapatra. A fejlesztőknek biztonsági intézkedéseket kell létrehozniuk a mikroszolgáltatási kódjukban a következetlen adatok által okozott problémák kezeléséhez.
A Cloud Native Computing Foundation (CNCF) számos NewSQL-adatbázisprojektet tartalmaz.
| Projekt | Jellemzők |
|---|---|
| Csótány DB | Acid-kompatibilis, globálisan skálázható relációs adatbázis. Adjon hozzá egy új csomópontot egy fürthöz, és a CsótányDB gondoskodik az adatok példányok és földrajzi területek közötti elosztásáról. Replikákat hoz létre, kezel és terjeszt a megbízhatóság biztosítása érdekében. Ez nyílt forráskód és szabadon elérhető. |
| TiDB | Nyílt forráskódú adatbázis, amely támogatja a hibrid tranzakciós és elemzési feldolgozási (HTAP) számítási feladatokat. Ez a MySQL-kompatibilis, és horizontális skálázhatóságot, erős konzisztenciát és magas rendelkezésre állást biztosít. A TiDB MySQL-kiszolgálóként működik. Továbbra is használhatja a meglévő MySQL-ügyfélkódtárakat anélkül, hogy az alkalmazás kódmódosításokat igényel. |
| YugabyteDB | Egy nyílt forráskód, nagy teljesítményű, elosztott SQL-adatbázis. Támogatja az alacsony lekérdezési késést, a hibákkal szembeni rugalmasságot és a globális adatterjesztést. A YugabyteDB PostgreSQL-kompatibilis, és kezeli a kibővített RDBMS-t és az internetes OLTP-számítási feladatokat. A termék a NoSQL-t is támogatja, és kompatibilis a Cassandrával. |
| Vitess | A Vitess adatbázismegoldás a MySQL-példányok nagy fürtjeinek üzembe helyezésére, skálázására és kezelésére. Nyilvános vagy magánfelhő-architektúrában is futtatható. A Vitess számos fontos MySQL-funkciót és funkciót egyesít és bővít, mind a vertikális, mind a horizontális horizontális skálázási támogatást. A YouTube-ról származó virtuális gépek 2011 óta minden YouTube-adatbázis-forgalmat kiszolgálnak. |
Az előző ábrán szereplő nyílt forráskódú projektek a Cloud Native Computing Foundationtől érhetők el. Az ajánlatok közül három teljes adatbázis-termék, amely tartalmazza a .NET-támogatást. A másik, vitess, egy adatbázis-fürtözési rendszer, amely horizontálisan skálázza a mySQL-példányok nagy fürtöit.
A NewSQL-adatbázisok egyik fő tervezési célja, hogy natív módon működjenek a Kubernetesben, kihasználva a platform rugalmasságát és méretezhetőségét.
A NewSQL-adatbázisok olyan rövid élettartamú felhőkörnyezetekben való boldogulásra lettek tervezve, ahol a mögöttes virtuális gépek egy pillanat alatt újraindíthatók vagy újraütemezhetők. Az adatbázisok úgy vannak kialakítva, hogy adatvesztés és állásidő nélkül túléljék a csomóponthibákat. A CsótányDB például képes túlélni egy gépvesztést úgy, hogy három konzisztens replikát tart fenn a fürt csomópontjai között.
A Kubernetes egy Services-szerkezettel teszi lehetővé, hogy az ügyfél egyetlen DNS-bejegyzésből kezelje az azonos NewSQL-adatbázis-folyamatok egy csoportját. Ha leválasztjuk az adatbázispéldányokat annak a szolgáltatásnak a címéről, amelyhez társítva van, a meglévő alkalmazáspéldányok megzavarása nélkül méretezhetjük a skálázást. Ha egy kérést egy adott időpontban küld egy szolgáltatásnak, az mindig ugyanazt az eredményt fogja eredményezni.
Ebben a forgatókönyvben az összes adatbázispéldány egyenlő. Nincsenek elsődleges vagy másodlagos kapcsolatok. A CsótányDB-ben található konszenzusreplikációs technikák lehetővé teszik, hogy bármely adatbázis-csomópont kezelje a kéréseket. Ha a terheléselosztásos kérelmet fogadó csomópont rendelkezik a helyileg szükséges adatokkal, azonnal válaszol. Ha nem, a csomópont átjáróvá válik, és továbbítja a kérést a megfelelő csomópontoknak a helyes válasz érdekében. Az ügyfél szempontjából minden adatbáziscsomópont ugyanaz: Egyetlen logikai adatbázisként jelennek meg egy egygépes rendszer konzisztenciájával, annak ellenére, hogy több tucat vagy akár több száz csomópont dolgozik a színfalak mögött.
A NewSQL-adatbázisok mögötti mechanikát a DASH: Four Properties of Kubernetes-Native Databases (A Kubernetes-Native Databases négy tulajdonsága) című cikkben tekintheti meg.
Adatmigrálás a felhőbe
Az egyik időigényesebb feladat az adatok áttelepítése egyik adatplatformról a másikra. Az Azure Data Migration Service segíthet az ilyen erőfeszítések felgyorsításában. Számos külső adatbázis-forrásból származó adatokat migrálhat az Azure Data platformjaira minimális állásidővel. A célplatformok a következő szolgáltatásokat tartalmazzák:
- Azure SQL Database
- Azure adatbázis MySQL-hoz
- Azure Database for MariaDB (Azure Adatbázis a MariaDB számára)
- Azure Database for PostgreSQL
- Azure Cosmos DB (adatbázis)
A szolgáltatás javaslatokat nyújt a migrálás végrehajtásához szükséges módosítások végigvezetésére kicsi vagy nagy méretben is.
Dolgozzon együtt velünk a GitHubon
A tartalom forrása a GitHubon található, ahol létrehozhat és áttekinthet problémákat és lekéréses kérelmeket is. További információért tekintse meg a közreműködői útmutatónkat.