A csapat Adattudomány folyamat életciklusának modellezési szakasza
Ez a cikk a Team Adattudomány Process (TDSP) modellezési szakaszához kapcsolódó célokat, feladatokat és termékeket ismerteti. Ez a folyamat egy ajánlott életciklust biztosít, amellyel csapata strukturálhatja adatelemzési projektjeit. Az életciklus a csapat által végrehajtott fő fázisokat vázolja fel, gyakran iteratív módon:
- Üzleti ismeretek
- Adatgyűjtés és -megértés
- Mintázás
- Üzembe helyezés
- Ügyfélfogadás
Íme a TDSP életciklusának vizuális ábrázolása:
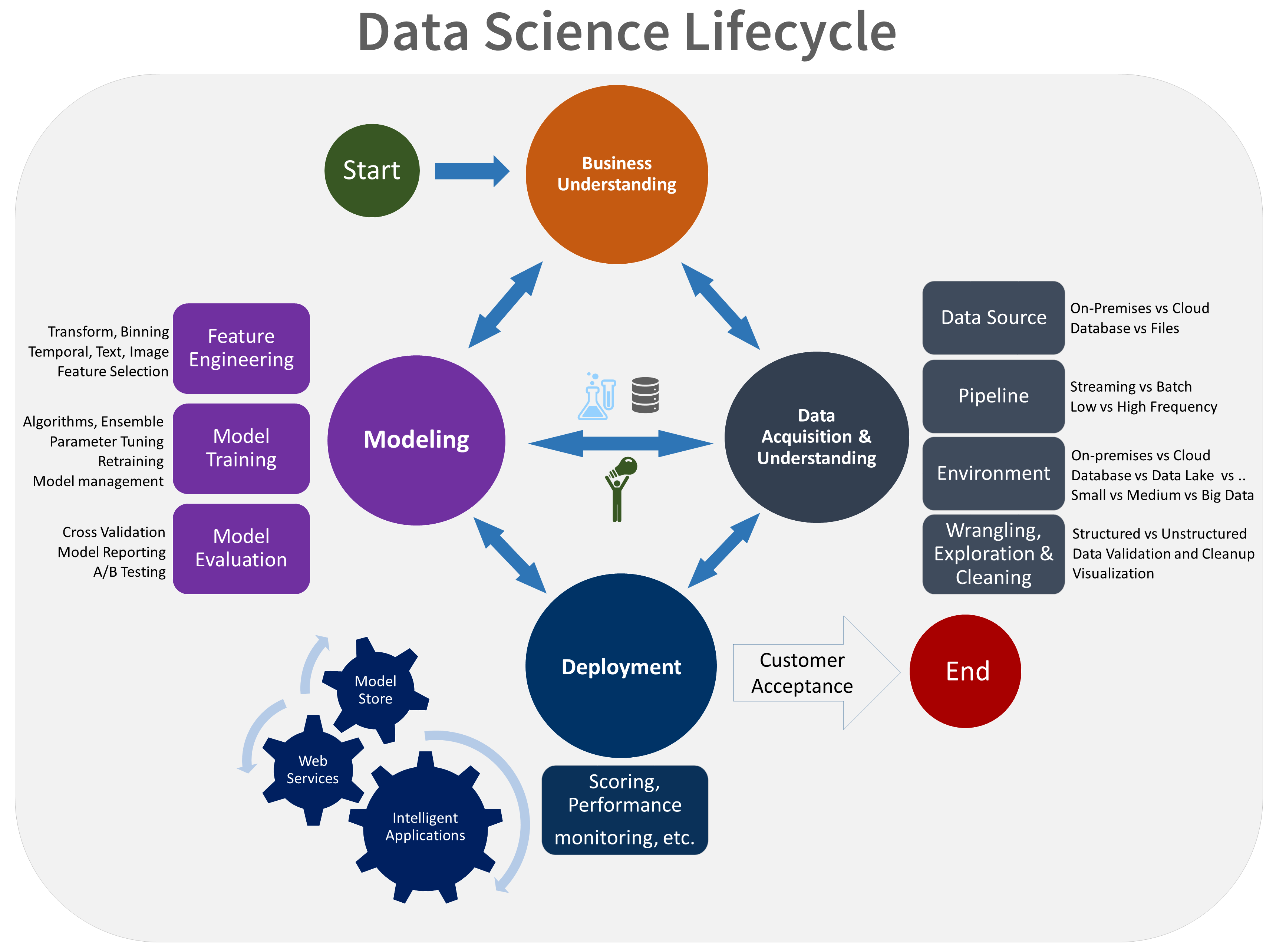
Célok
A modellezési szakasz célja:
Határozza meg a gépi tanulási modell optimális adatfunkcióit.
Hozzon létre egy informatív gépi tanulási modellt, amely a legpontosabban előrejelzi a célt.
Éles környezethez megfelelő gépi tanulási modell létrehozása.
A feladatok végrehajtása
A modellezési fázis három fő feladatból áll:
Szolgáltatásfejlesztés: A modell betanításának megkönnyítése érdekében hozzon létre adatszolgáltatásokat a nyers adatokból.
Modellbetanítás: A modellek sikerességi metrikáinak összehasonlításával keresse meg azt a modellt, amely a legpontosabban válaszol a kérdésre.
Modellértékelés: Határozza meg, hogy a modell alkalmas-e az éles környezetben való használatra.
Jellemzőkiemelés
A funkciófejlesztés magában foglalja a nyers változók felvételét, összesítését és átalakítását az elemzésben használt funkciók létrehozásához. Ha betekintést szeretne a modell felépítésébe, akkor meg kell vizsgálnia a modell mögöttes funkcióit.
Ehhez a lépéshez a tartományi szakértelem és az adatfeltárási lépésből származó megállapítások kreatív kombinációja szükséges. A funkciófejlesztés kiegyensúlyozza az informatív változók keresését és beépítését, ugyanakkor megpróbálja elkerülni a túl sok egymástól független változót. Az informatív változók javítják az eredményt. A nem kapcsolódó változók szükségtelen zajt vezetnek be a modellbe. Ezeket a funkciókat a pontozás során beszerzett új adatokhoz is létre kell hoznia. Ennek eredményeképpen ezeknek a funkcióknak a létrehozása csak a pontozáskor elérhető adatoktól függhet.
A modell betanítása
A megválaszolni kívánt kérdés típusától függően számos modellezési algoritmus használható. Az előre összeállított algoritmusok kiválasztásával kapcsolatos útmutatásért tekintse meg az Azure Machine Learning Designer Machine Learning-algoritmusokkal kapcsolatos csalási lapját. Más algoritmusok nyílt forráskódú csomagokon keresztül érhetők el R-ben vagy Pythonban. Bár ez a cikk az Azure Machine Learningre összpontosít, az általa nyújtott útmutató számos gépi tanulási projekt esetében hasznos.
A modell betanításának folyamata a következő lépéseket tartalmazza:
A bemeneti adatok véletlenszerű felosztása betanítási adatkészletre és tesztadatkészletre való modellezéshez.
A modellek létrehozása a betanítási adatkészlet használatával.
Értékelje ki a betanítást és a tesztadatkészletet. Konkurens gépi tanulási algoritmusok sorozatának használata. Használjon különböző kapcsolódó hangolási paramétereket (más néven paraméteres takarításokat), amelyek az aktuális adatokkal kapcsolatos érdeklődési kérdés megválaszolására irányulnak.
A sikeres metrikák alternatív módszerek közötti összehasonlításával határozza meg a legjobb megoldást a kérdés megválaszolásához.
További információ: Modellek betanítása a Machine Learning használatával.
Feljegyzés
A szivárgás elkerülése: Adatszivárgást okozhat, ha a betanítási adatkészleten kívülről származó adatokat is tartalmaz, amelyek lehetővé teszik, hogy egy modell vagy gépi tanulási algoritmus irreálisan jó előrejelzéseket készítsen. A szivárgás gyakori oka annak, hogy az adattudósok idegesek lesznek, ha olyan prediktív eredményeket kapnak, amelyek túl jónak tűnnek ahhoz, hogy igaznak tűnjenek. Ezek a függőségek nehezen észlelhetők. A szivárgás elkerülése gyakran megköveteli az elemzési adatkészletek létrehozása, a modell létrehozása és az eredmények pontosságának kiértékelése közötti iterálást.
A modell kiértékelése
A modell betanítása után a csapat egyik adatelemzője a modellértékelésre összpontosít.
Döntse el, hogy a modell megfelelően teljesít-e az éles környezethez. Néhány fontos kérdés, amit fel kell tenni:
A modell megfelelő megbízhatósággal válaszol a kérdésre a tesztadatok alapján?
Érdemes alternatív módszereket kipróbálnia?
Több adatot kell gyűjtenie, több funkciófejlesztést kell végeznie, vagy kísérleteznie kell más algoritmusokkal?
A modell értelmezése: A Machine Learning Python SDK-val hajtsa végre a következő feladatokat:
Ismertesse a modell teljes viselkedését vagy egyéni előrejelzéseit helyileg a személyes gépen.
Értelmezhetőségi technikák engedélyezése a megtervezett funkciókhoz.
Az Azure-beli teljes modell és egyéni előrejelzések viselkedésének ismertetése.
Magyarázatok feltöltése a Machine Learning futtatási előzményeibe.
Egy vizualizációs irányítópult használatával kezelheti a modell magyarázatait egy Jupyter-jegyzetfüzetben és a Machine Learning-munkaterületen.
Helyezzen üzembe egy pontozó magyarázót a modell mellett, hogy megfigyelje a magyarázatokat a következtetés során.
Méltányosság felmérése: A fairlearn nyílt forráskódú Python-csomag és a Machine Learning segítségével hajtsa végre a következő feladatokat:
Értékelje a modell előrejelzéseinek méltányosságát. Ez a folyamat segít a csapatnak többet megtudni a gépi tanulás méltányosságáról.
Méltányossági felmérési megállapítások feltöltése, listázása és letöltése a Machine Learning Studióba és onnan.
A modelljei méltányossági megállapításaival kapcsolatban tekintse meg a Machine Learning Studió méltányossági felmérési irányítópultját.
Integrálás az MLflow-jal
A Machine Learning integrálható az MLflow-jal a modellezési életciklus támogatása érdekében. Az MLflow nyomon követését használja kísérletekhez, projekttelepítéshez, modellkezeléshez és modellregisztrációs adatbázishoz. Ez az integráció zökkenőmentes és hatékony gépi tanulási munkafolyamatot biztosít. A Machine Learning alábbi funkciói támogatják ezt a modellezési életciklus-elemet:
Kísérletek nyomon követése: Az MLflow alapvető funkcióit széles körben használják a modellezési szakaszban a különböző kísérletek, paraméterek, metrikák és összetevők nyomon követésére.
Projektek üzembe helyezése: A kód MLflow-projektekkel való csomagolása egységes futtatásokat és egyszerű megosztást biztosít a csapattagok között, ami elengedhetetlen az iteratív modell fejlesztése során.
Modellek kezelése: A modellek kezelése és verziószámozása ebben a fázisban kritikus fontosságú, mivel a különböző modellek létrehozása, kiértékelése és finomítása folyamatban van.
Modellek regisztrálása: A modellregisztrációs adatbázis a modellek teljes életciklusa során történő verziószámozására és kezelésére szolgál.
Lektorált szakirodalom
A kutatók tanulmányokat tesznek közzé a TDSP-ről a lektorált szakirodalomban. Az idézetek lehetőséget nyújtanak a TDSP-hez hasonló alkalmazások vagy hasonló ötletek vizsgálatára, beleértve a modellezési életciklus fázisát is.
Közreműködők
Ezt a cikket a Microsoft tartja karban. Eredetileg a következő közreműködők írták.
Fő szerző:
- Mark Tabladillo | Vezető felhőmegoldás-tervező
A nem nyilvános LinkedIn-profilok megtekintéséhez jelentkezzen be a LinkedInbe.
Kapcsolódó erőforrások
Ezek a cikkek a TDSP életciklusának további szakaszait ismertetik: