Azure-beli virtuális gépeken futó Stromasys Charon-SSP Solaris emulátor
A Charon-SSP platformfüggetlen hipervizor az iparági szabványnak megfelelő x86-64 számítástechnikai rendszereken és virtuális gépeken emulálja az örökölt Sun SPARC-rendszereket.
Ezt a böngészőt már nem támogatjuk.
Frissítsen a Microsoft Edge-re, hogy kihasználhassa a legújabb funkciókat, a biztonsági frissítéseket és a technikai támogatást.
A nagyszámítógépek és a középkategóriás hardverek különböző gyártóktól származó rendszerekből állnak (mind a nagy teljesítmény, a magas átviteli sebesség és néha a magas rendelkezésre állás előzményeivel és céljával). Ezek a rendszerek gyakran vertikálisan felskálázhatók és monolitikusak voltak, ami azt jelenti, hogy egyetlen, nagy méretű, több feldolgozási egységből, megosztott memóriából és megosztott tárterületből álló keret voltak.
Az alkalmazás oldalán a programokat gyakran két ízben írták: tranzakciós vagy köteg. Mindkét esetben több programozási nyelvet is használtak, például COBOL, PL/I, Natural, Fortran, REXX stb. Ezeknek a rendszereknek az életkora és összetettsége ellenére számos migrálási útvonal létezik az Azure-ba.
Az adatoldalon az adatok tárolása általában fájlokban és adatbázisokban történik. A főszámítógépek és a középső adatbázisok gyakran különböző struktúrákban, például relációs, hierarchikus és hálózati struktúrákban is előfordulnak. A fájlkezelő rendszereknek különböző típusai vannak, amelyek némelyike indexelhető, és kulcs-érték tárolóként is működhet. Emellett a nagyszámítógépek adatkódolása eltérhet a nem nagyszámítógépes rendszerekben általában kezelt kódolástól. Ezért az adatmigrálásokat előzetes tervezéssel kell kezelni. Az Azure-adatplatformra való migrálásnak számos lehetősége van.

Sok esetben a nagyszámítógépek, a középső és más kiszolgálóalapú számítási feladatok replikálhatók az Azure-ban, és csak kevés a funkcióvesztés. Előfordulhat, hogy a felhasználók nem észlelik a mögöttes rendszerek változásait. Más helyzetekben lehetőség van az örökölt megoldás újrabontására és újratervezésére a felhővel összhangban lévő architektúrában. Ez úgy történik, hogy továbbra is fenntartja ugyanazt a vagy hasonló funkciót. A tartalomkészlet architektúrái (valamint a jelen cikk későbbi részében található tanulmány és egyéb források) segítenek végigvezetni a folyamaton.
A főszámítógép-architektúrákban a következő kifejezéseket használjuk.
A nagyszámítógépeket vertikálisan felskálázott kiszolgálókként tervezték, hogy nagy mennyiségű online tranzakciót és kötegelt feldolgozást futtasson az 1950-es évek végén. Így a nagyszámítógépek szoftverekkel rendelkeznek az online tranzakciós űrlapokhoz (más néven zöld képernyőkhöz) és nagy teljesítményű I/O-rendszerekhez a kötegelt futtatások feldolgozásához. A nagyszámítógépek megbízhatósága és rendelkezésre állása amellett, hogy képes online és kötegelt feladatok futtatására.
A nagyszámítógépek demystifyingjének része a különböző egymást átfedő kifejezések dekódolása. Például a központi tároló, a valós memória, a valós tároló és a fő tároló mind a közvetlenül a nagyszámítógép processzorához csatlakoztatott tárolóra vonatkozik. A nagyszámítógépes hardverek processzorokat és sok más eszközt tartalmaznak, például a közvetlen hozzáférésű tárolóeszközöket (DASD-ket), a mágneses szalagos meghajtókat és a felhasználói konzolok számos típusát. A szalagokat és a DASD-ket a rendszerfüggvényekhez és a felhasználói programokhoz használják.
A fizikai tárolás típusai:
A másodpercenkénti utasítások millióinak (MIPS) mérése állandó értéket ad a másodpercenkénti ciklusok számának egy adott géphez. A MIPS a nagyszámítógépek általános számítási teljesítményének mérésére szolgál. A nagyszámítógép-szállítók a MIPS-használat alapján díjat számítanak fel az ügyfeleknek. Az ügyfelek növelhetik a nagyszámítógépek kapacitását, hogy megfeleljenek bizonyos követelményeknek. Az IBM egy processzorkapacitás-indexet tart fenn, amely a különböző nagyszámítógépek relatív kapacitását mutatja.
Az alábbi táblázat a miPS-küszöbértékeket mutatja be a kis, közepes és nagyvállalati szervezetek (SORG-k, MORG-k és LORG-k) esetében.
| Ügyfél mérete | Tipikus MIPS-használat |
|---|---|
| SORG | Kevesebb mint 500 MIPS |
| MORG | 500 MIPS–5000 MIPS |
| LORG | Több mint 5000 MIPS |
A nagyszámítógép-adatok tárolása és rendszerezése különböző módokon történik, a relációs és hierarchikus adatbázisoktól a nagy átviteli sebességű fájlrendszerekig. Néhány gyakori adatrendszer a z/OS Db2 a relációs adatokhoz, az IMS DB hierarchikus adatokhoz. A nagy átviteli sebességű fájltárolás esetében a VSAM (IBM Virtual Storage Access Metódus) jelenhet meg. Az alábbi táblázat néhány általánosabb nagyszámítógépes adatrendszer és az Azure-ba történő lehetséges migrálási célok leképezését tartalmazza.
| Adatforrás | Célplatform az Azure-ban |
|---|---|
| z/OS Db2 & Db2 LUW | Azure SQL DB, SQL Server Azure-beli virtuális gépeken, Db2 LUW Azure-beli virtuális gépeken, Oracle azure-beli virtuális gépeken, Azure Database for PostgreSQL |
| IMS DB | Azure SQL DB, SQL Server Azure-beli virtuális gépeken, Db2 LUW Azure-beli virtuális gépeken, Oracle azure-beli virtuális gépeken, Azure Cosmos DB |
| Virtuális tárelérési módszer (VSAM), indexelt szekvenciális hozzáférési módszer (ISAM), egyéb egybesimított fájlok | Azure SQL DB, SQL Server Azure-beli virtuális gépeken, Db2 LUW Azure-beli virtuális gépeken, Oracle azure-beli virtuális gépeken, Azure Cosmos DB |
| Létrehozási dátumcsoportok (GDG-k) | Fájlok az Azure-ban az elnevezési konvenciók bővítményeit használva a GDG-khez hasonló funkciók biztosításához |
A midrange rendszerek és a középső számítógépek lazán definiált kifejezések egy olyan számítógéprendszerhez, amely nagyobb teljesítményű, mint egy általános célú személyi számítógép, de kevésbé hatékony, mint egy teljes méretű nagyszámítógép. A legtöbb esetben a középső számítógép hálózati kiszolgálóként van alkalmazva, ha kis-közepes számú ügyfélrendszer van. A számítógépek általában több processzorral, nagy mennyiségű véletlenszerű hozzáférési memóriával (RAM) és nagy merevlemezekkel rendelkeznek. Emellett általában olyan hardvereket is tartalmaznak, amelyek lehetővé teszik a fejlett hálózatkezelést, valamint portokat, amelyek az üzleti központú perifériákhoz (például nagy méretű adattároló eszközökhöz) csatlakoznak.
Ebben a kategóriában gyakori rendszerek közé tartozik az AS/400 és az IBM i és p sorozat. Az Unisys midrange rendszerek gyűjteményével is rendelkezik.
A Unix operációs rendszer az első nagyvállalati szintű operációs rendszerek egyike volt. A Unix az Ubuntu, a Solaris és a POSIX szabványt követő operációs rendszerek alap operációs rendszere. A Unixot ken Thompson, Dennis Ritchie és mások fejlesztették ki az AT&T Laboratóriumban. Eredetileg olyan programozók számára készült, akik nem programozók helyett szoftvereket fejlesztenek. Kormányzati szervezeteknek és felsőoktatási intézményeknek osztották ki, amelyek mindegyike arra késztette a Unixot, hogy a különböző speciális funkciókkal rendelkező változatok és villák szélesebb körére legyenek áthordva. A Unix és változatai (például az AIX, a HP-UX és a Tru64) gyakran régebbi rendszereken futnak, például IBM-nagyszámítógépeken, AS/400-rendszereken, Sun Sparc és DEC hardveralapú rendszereken.
Más örökölt rendszerek közé tartozik a Digital Equipment Corporation (DEC) rendszercsaládja, például a DEC VAX, a DEC Alpha és a DEC PDP. A DEC-rendszerek kezdetben a VAX VMS operációs rendszert futtatták, majd végül a Unix-változatokra, például a Tru64-be költöztek. Más rendszerek közé tartoznak a PA-RISC architektúrán alapuló rendszerek, például a HP-3000 és a HP-9000 rendszerek.
A midrange-adatok tárolása és rendszerezése különböző módokon történik, a relációs és hierarchikus adatbázisoktól a nagy átviteli sebességű fájlrendszerekig. A gyakori adatrendszerek egyike az i-hez készült Db2 (relációs adatok esetében), a hierarchikus adatokhoz pedig az IMS DB. Az alábbi táblázat néhány általánosabb nagyszámítógépes adatrendszer és az Azure-ba való lehetséges migrálási célok leképezését tartalmazza.
| Adatforrás | Célplatform az Azure-ban |
|---|---|
| Db2 for i | Azure SQL DB, SQL Server Azure-beli virtuális gépeken, Azure Database for PostgreSQL, Db2 LUW Azure-beli virtuális gépeken, Oracle azure-beli virtuális gépeken |
| IMS DB | Azure SQL DB, SQL Server Azure-beli virtuális gépeken, Db2 LUW Azure-beli virtuális gépeken, Oracle azure-beli virtuális gépeken, Azure Cosmos DB |
Vegye figyelembe a következő részleteket az endiannessről:
Az alábbi ábra vizuálisan bemutatja a big endian és a kis endian közötti különbséget.

Ezt a lehetőséget gyakran átemeléses migrálásnak is nevezik, ez a beállítás nem igényel kódmódosítást. Ezzel gyorsan migrálhatja meglévő alkalmazásait az Azure-ba. A rendszer minden alkalmazást migrál, hogy kihasználja a felhő előnyeit (a kódmódosításokkal járó kockázat és költség nélkül).
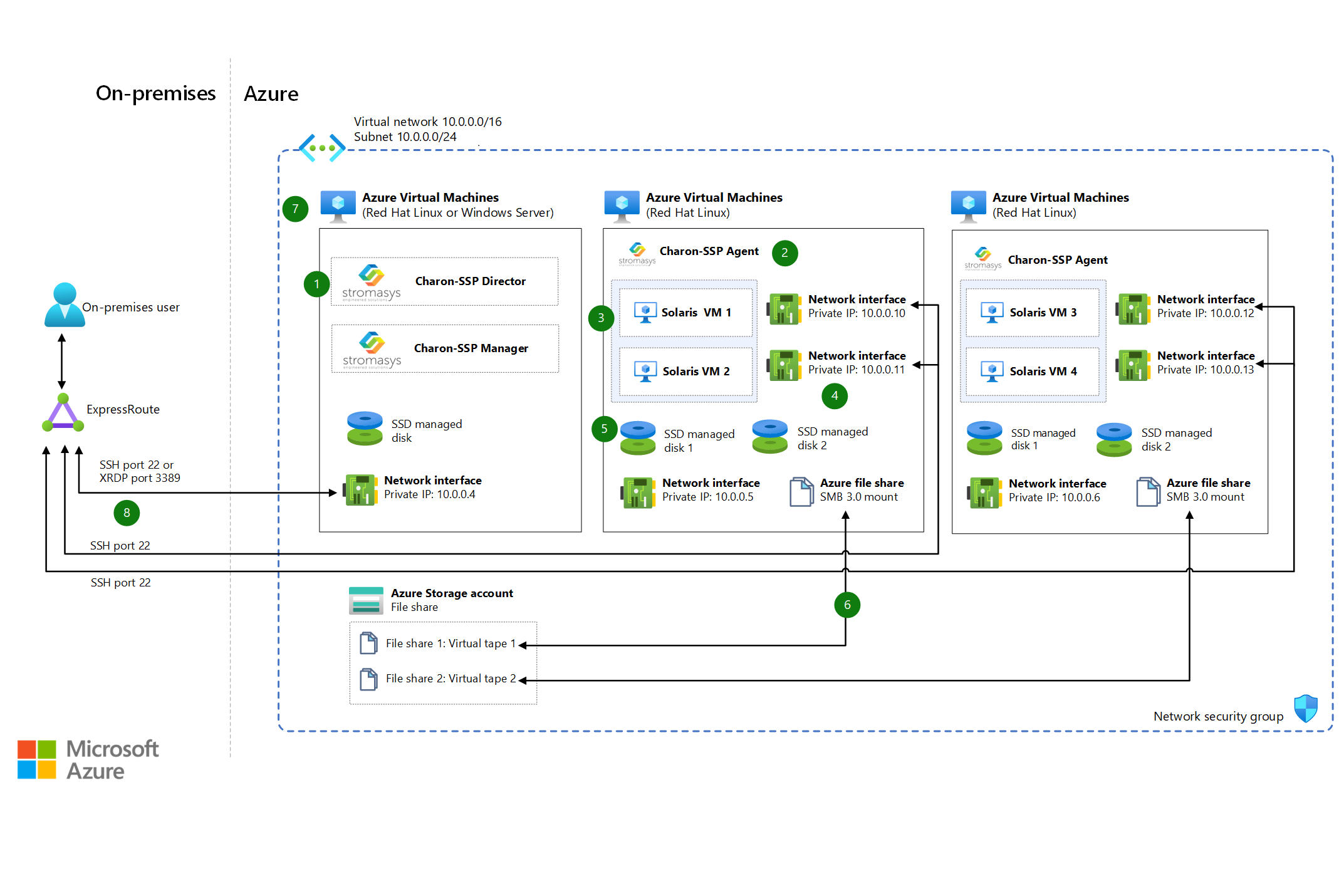
Azure-beli virtuális gépeken futó Stromasys Charon-SSP Solaris emulátor
A Charon-SSP platformfüggetlen hipervizor az iparági szabványnak megfelelő x86-64 számítástechnikai rendszereken és virtuális gépeken emulálja az örökölt Sun SPARC-rendszereket.
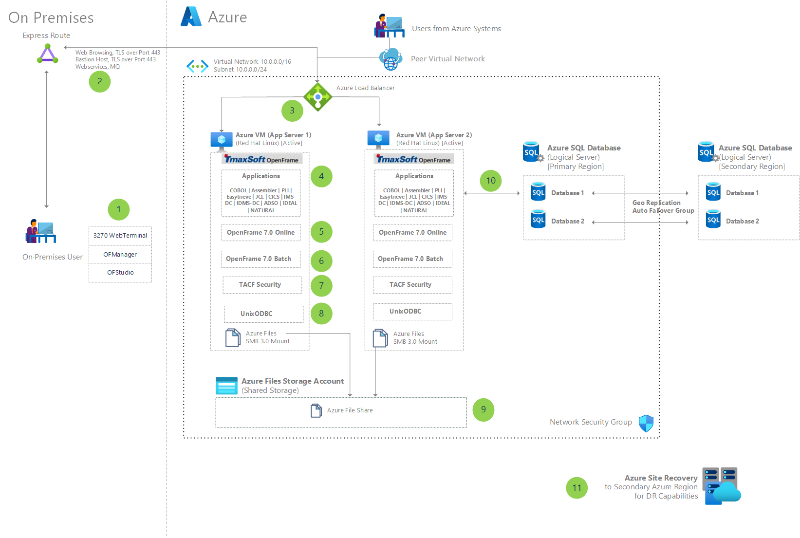
IBM-nagyszámítógép-alkalmazások migrálása az Azure-ba a TmaxSoft OpenFrame használatával
Ibm zSeries nagyszámítógépes alkalmazások migrálása az Azure-ba. Használjon kód nélküli megközelítést, amelyet a TmaxSoft OpenFrame kínál ehhez a lift- és műszakművelethez.
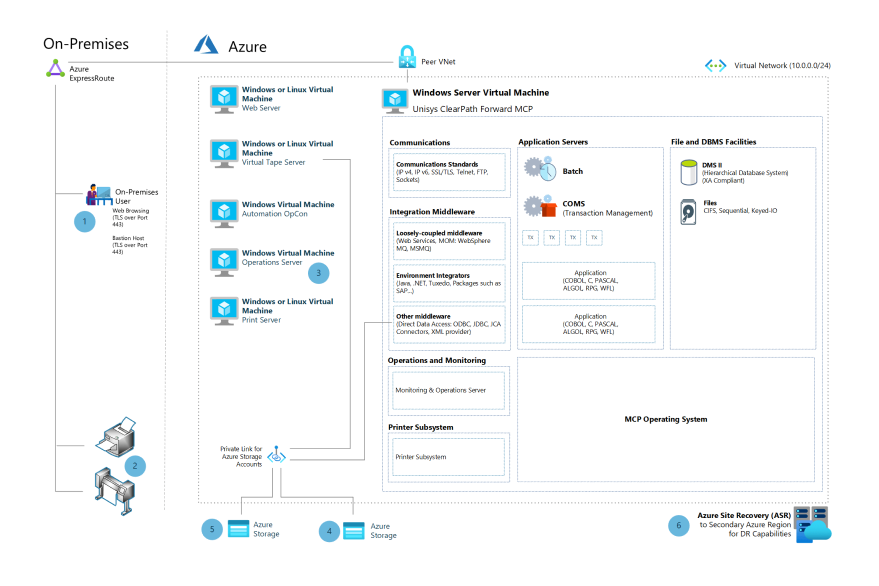
Az Unisys ClearPath Forward főszámítógépe az Azure-ba való áthelyezése Az Unisys virtualizálásával
A cikkben ismertetett architektúra bemutatja, hogyan használhatja a Microsoft-partner Unisys virtualizációs technológiáit egy örökölt Unisys CPF Libra-főszámítógéppel.
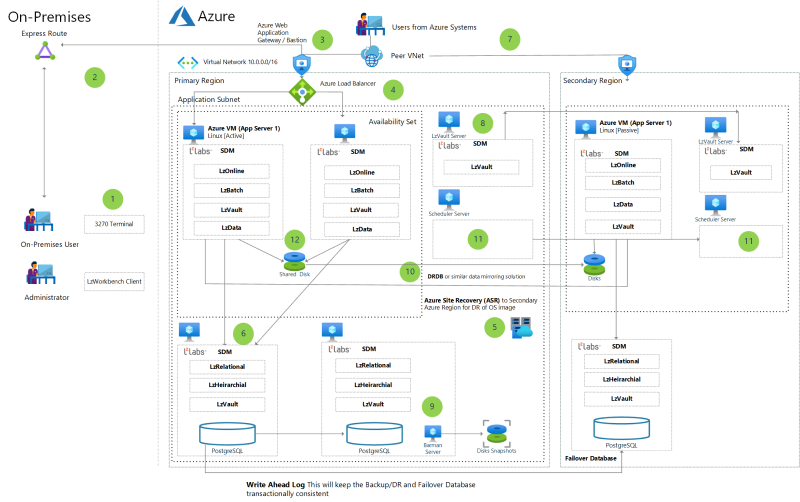
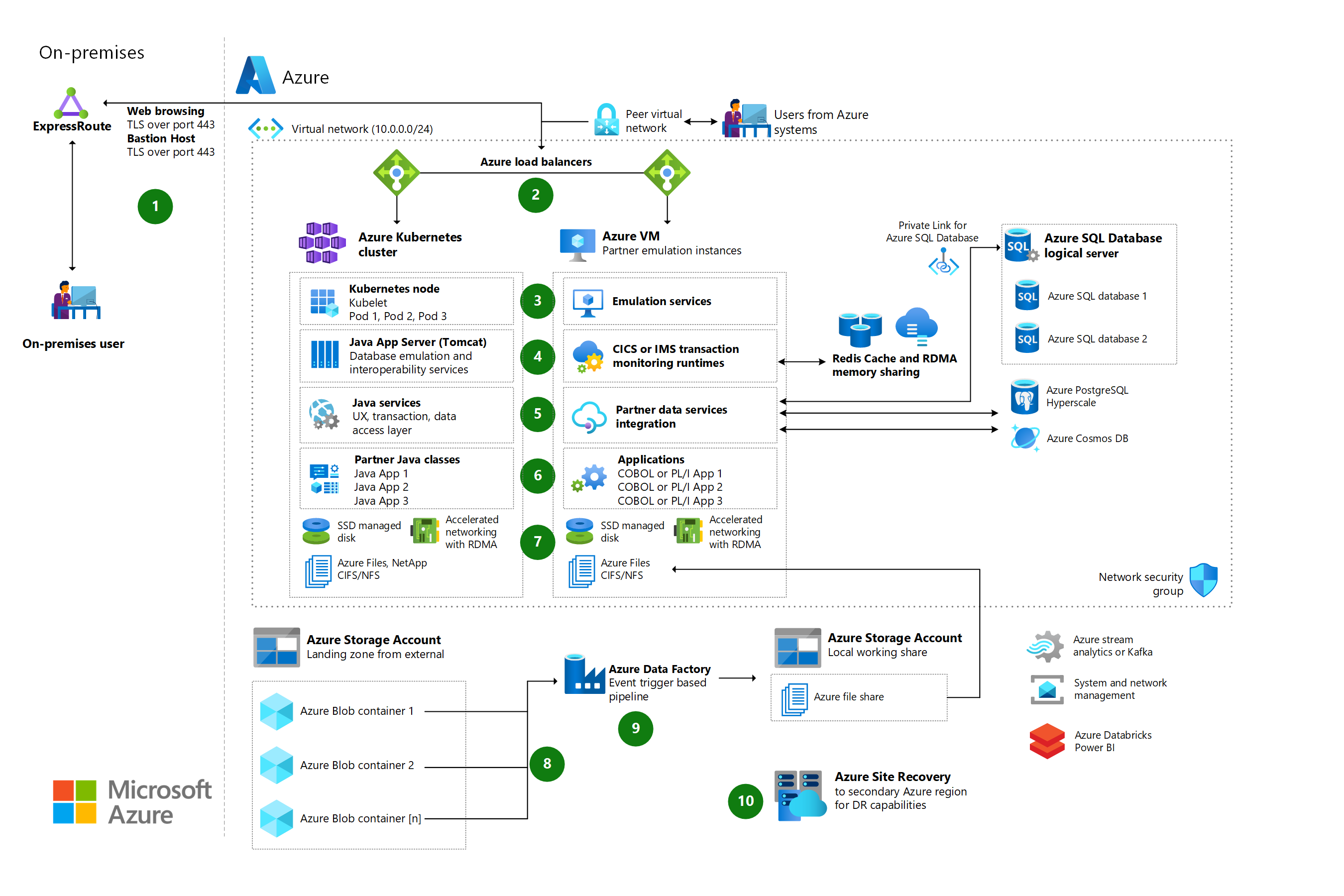
Az LzLabs szoftveralapú főszámítógép (SDM) használata Azure-beli virtuális gépek üzembe helyezésében
A nagyszámítógépes örökölt alkalmazások Azure-beli újrahelyezésének módszere az LzLabs szoftveralapú főszámítógép-platform használatával.
Az újrabontás minimális módosításokat igényel az alkalmazásokon. Ez gyakran lehetővé teszi, hogy az alkalmazásarchitektúra kihasználja az Azure-platformot szolgáltatásként (PaaS) és más felhőajánlatokat. Áttelepítheti például a meglévő alkalmazások számítási összetevőit Azure-alkalmazás Szolgáltatásba vagy az Azure Kubernetes Service-be (AKS). A relációs és nem kapcsolati adatbázisokat különböző beállításokba is átírhatja, például a felügyelt Azure SQL-példányokat, az Azure Database for MySQL-t, az Azure Database for PostgreSQL-t és az Azure Cosmos DB-t.
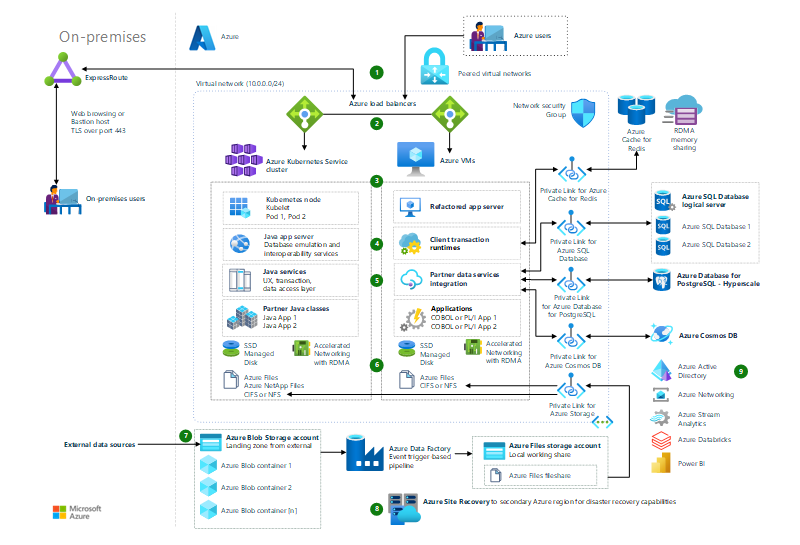
Általános nagyszámítógép-újrabontás az Azure-ba
Megtudhatja, hogyan lehet újrabontásra az általános nagyszámítógépes alkalmazásokat, hogy költséghatékonyabban és hatékonyabban fussanak az Azure-ban.
Micro Focus Enterprise Server Azure-beli virtuális gépeken
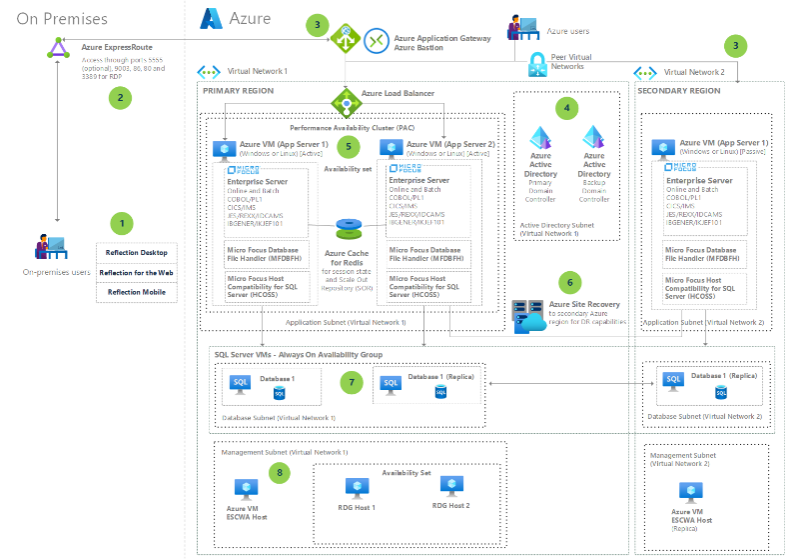
Optimalizálhatja, modernizálhatja és egyszerűsítheti az IBM z/OS nagyszámítógépes alkalmazásait a Micro Focus Enterprise Server 6.0 azure-beli virtuális gépeken való használatával.
IBM z/OS nagyszámítógépes csatolóeszközök (CF) újrabontása az Azure-ban
Ismerje meg, hogyan biztosíthatnak az Azure-szolgáltatások és -összetevők az IBM z/OS-főszámítógép CF- és párhuzamos Sysplex-képességeivel összehasonlítható vertikális felskálázási teljesítményt.
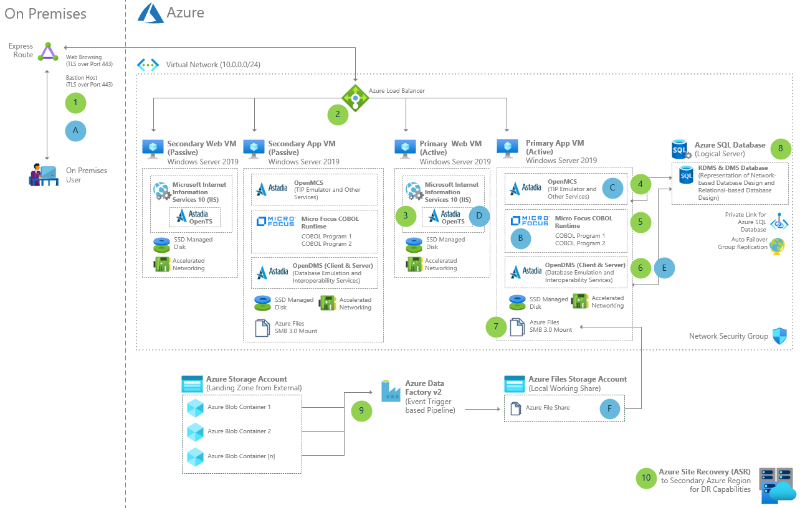
Unisys Dorado nagyszámítógépes migrálás az Azure-ba az Astadia > Micro Focus használatával
Unisys Dorado nagyszámítógépes rendszerek migrálása Astadia és Micro Focus termékekkel. Váltás az Azure-ba kód újraírása, adatmodellek váltása vagy képernyők frissítése nélkül.
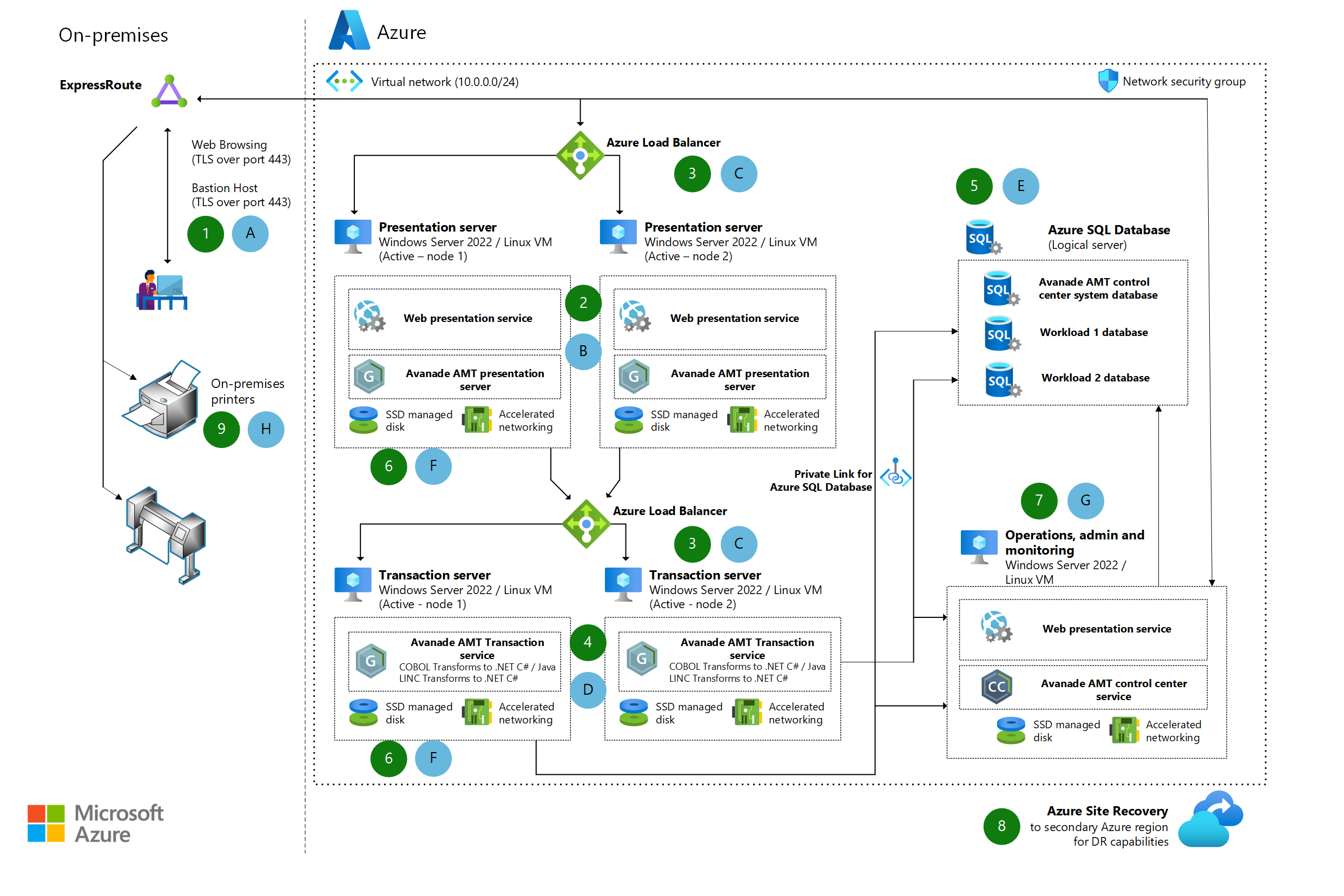
Unisys nagyszámítógépek migrálása
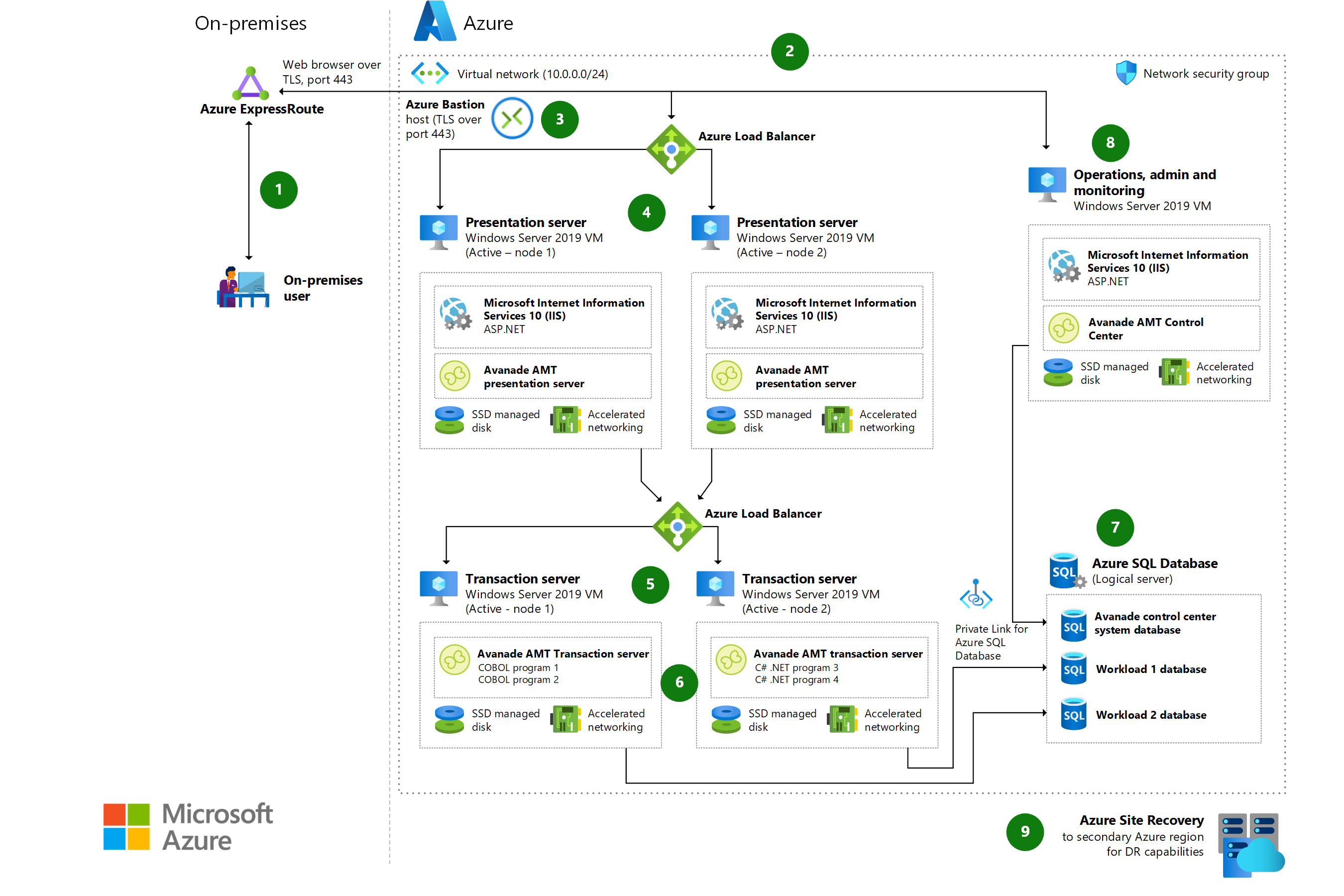
Ismerje meg az Avanade Automatizált migrálási technológia (AMT) keretrendszer használatával az Unisys nagyszámítógépes számítási feladatainak Azure-ba való migrálásának lehetőségeit.
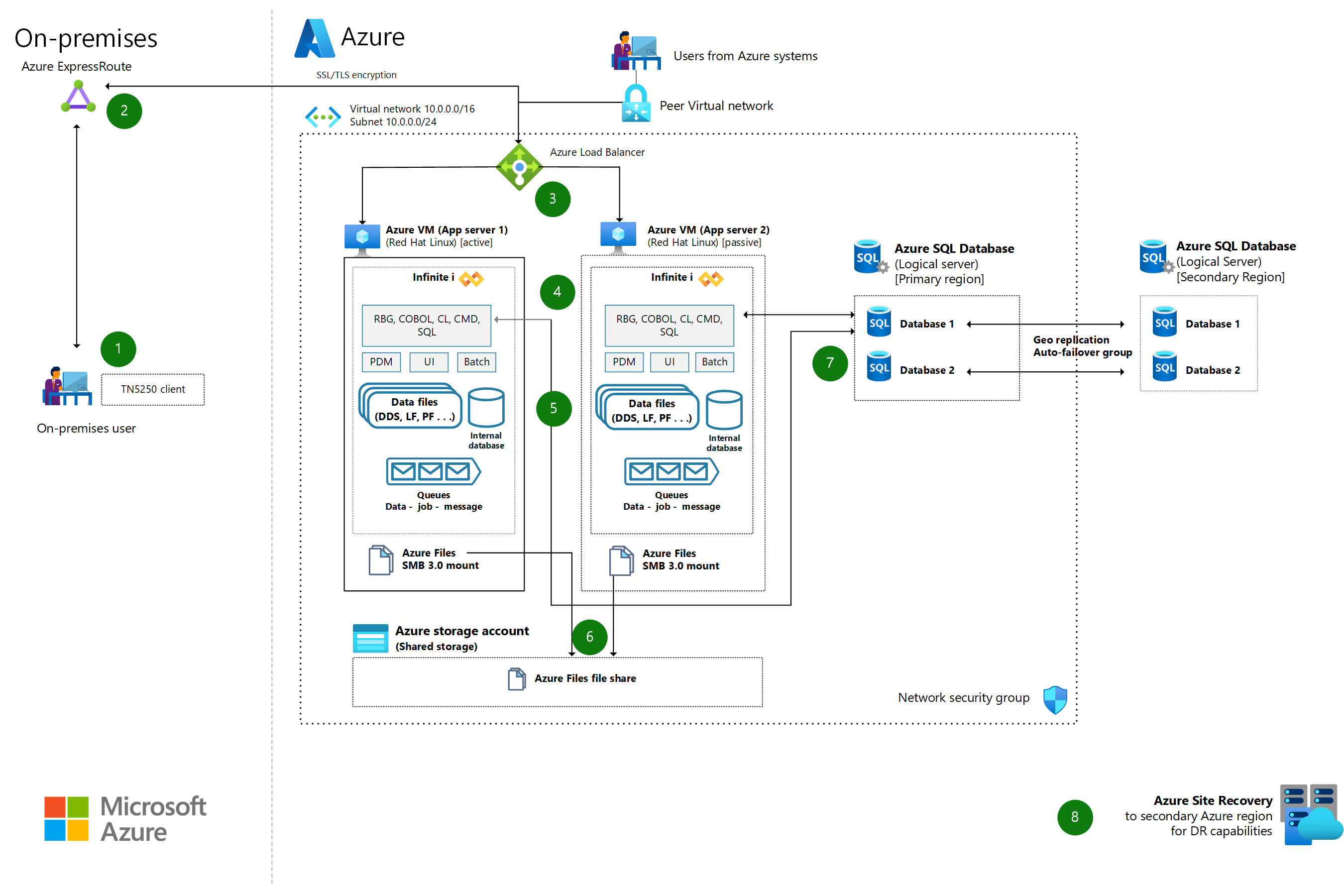
IBM System i (AS/400) az Azure-ba az Infinite i használatával
Az Infinite i használatával egyszerűen migrálhatja az IBM System i (AS/400) számítási feladatait az Azure-ba. Csökkentheti a költségeket, javíthatja a teljesítményt, javíthatja a rendelkezésre állást és modernizálhatja a költségeket.
IBM z/OS nagyszámítógép migrálása az Avanade AMT-vel
Megtudhatja, hogyan használhatja az Avanade Automated Migration Technology (AMT) keretrendszert az IBM z/OS nagyszámítógépes számítási feladatok Azure-ba való migrálásához.
Nagyszámítógépes alkalmazások áthelyezése az Azure-ba Raincode-fordítókkal
Ez az architektúra bemutatja, hogyan modernizálja a Raincode COBOL fordító a nagyszámítógépes örökölt alkalmazásokat.
IBM z/OS online tranzakciófeldolgozás az Azure-ban
Z/OS online tranzakciófeldolgozási (OLTP) számítási feladat áttelepítése költséghatékony, rugalmas, méretezhető és módosítható Azure-alkalmazásba.
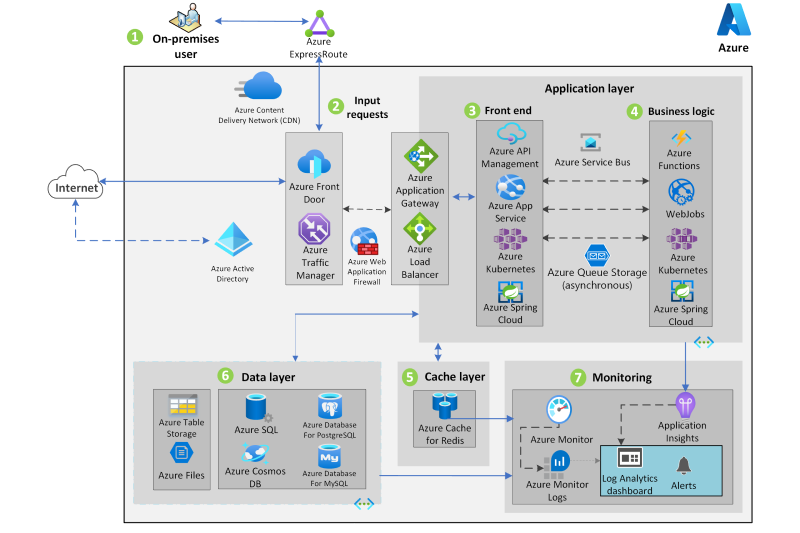
A migrálás újratervezése az alkalmazásfunkciók és a kódbázis módosítására és kiterjesztésére összpontosít, hogy optimalizálja az alkalmazásarchitektúrát a felhő méretezhetőségéhez. Például a monolitikus alkalmazásokat mikroszolgáltatások csoportjára bonthatja, amelyek együttműködnek és könnyen skálázhatóak. A relációs és nem kapcsolati adatbázisokat egy teljes körűen felügyelt adatbázis-megoldásra is át lehet tervezni, például felügyelt SQL-példányra, Az Azure Database for MySQL-re, az Azure Database for PostgreSQL-re és az Azure Cosmos DB-re.
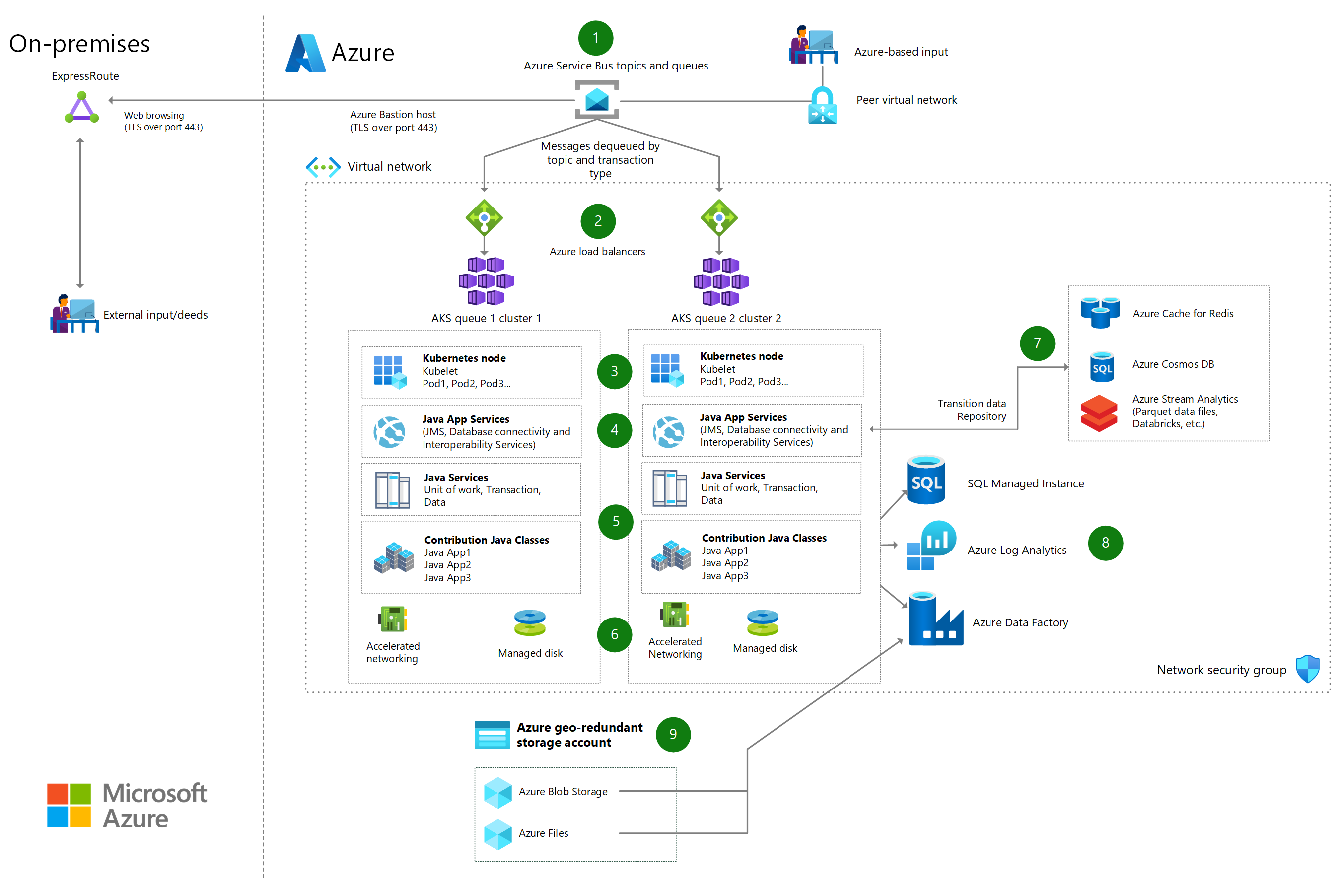
Nagy mennyiségű kötegtranzakció feldolgozása
Az Azure Kubernetes Service (AKS) és az Azure Service Bus használatával nagy mennyiségű kötegelt tranzakció feldolgozását valósíthatja meg.
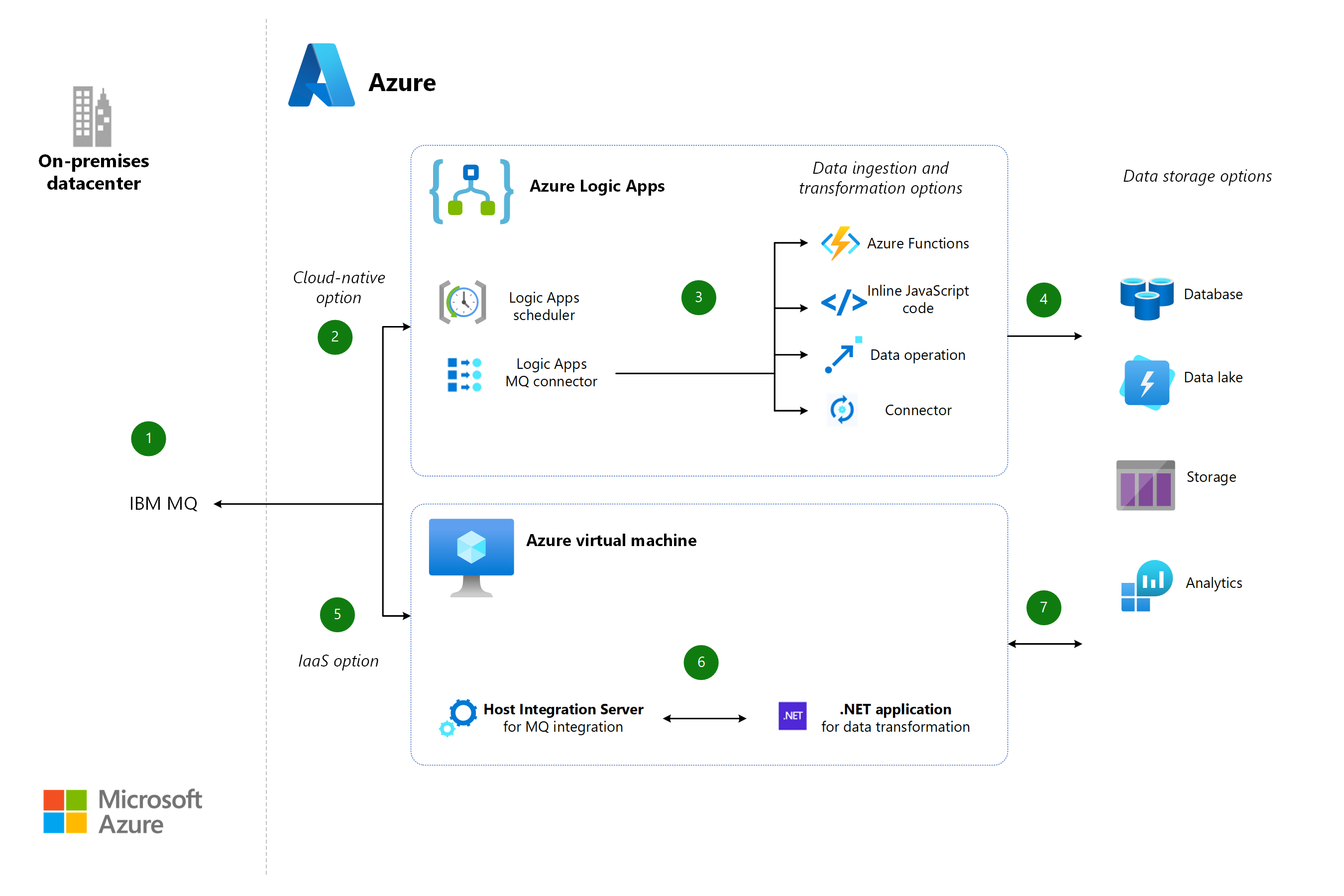
IBM-nagyszámítógépek és középső üzenetsorok integrálása az Azure-ral
Ez a példa a köztes szoftver integrációjának adatelső megközelítését ismerteti, amely lehetővé teszi az IBM-üzenetsorok (MQ-k) működését.
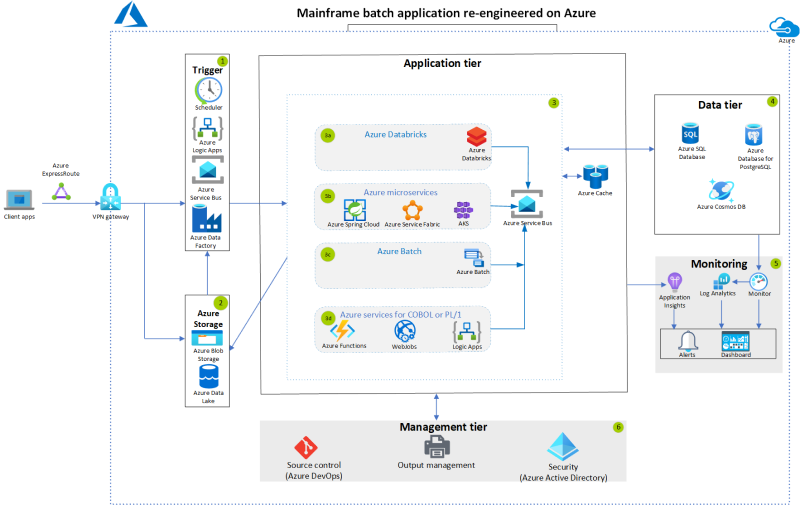
IBM z/OS batch-alkalmazások újratervezője az Azure-ban
Az Azure-szolgáltatások használatával újra megtervezhet nagyszámítógépes kötegelt alkalmazásokat. Ez az architektúraváltás csökkentheti a költségeket és javíthatja a méretezhetőséget.
Az Azure-ba (örökölt rendszerekhez) történő migrálás másik mintája a dedikált hardver. Ez a minta az, ahol az örökölt hardverek (például az IBM Power Systems) az Azure-adatközpontban futnak, és a hardver körül egy Felügyelt Azure-szolgáltatás fut, amely egyszerű felhőfelügyeletet és automatizálást tesz lehetővé. Emellett ez a hardver más Azure IaaS- és PaaS-szolgáltatásokkal való csatlakozáshoz és használathoz is elérhető.
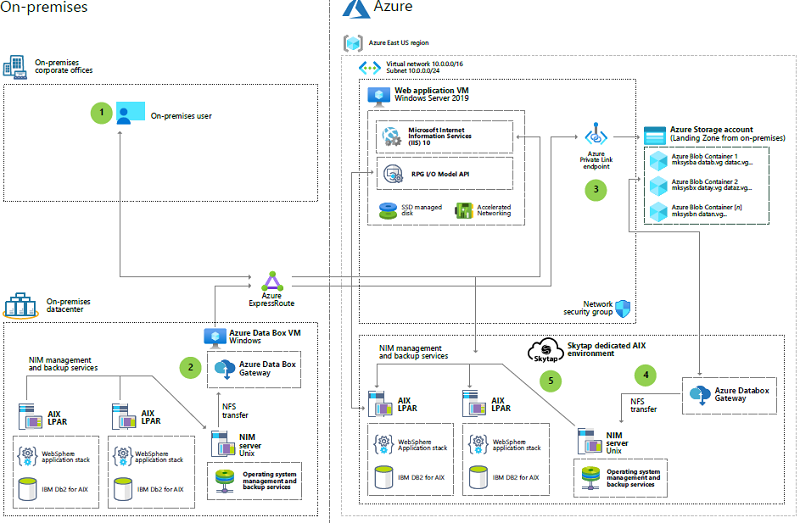
AIX-számítási feladatok migrálása az Azure Skytapba
Ez a példa az AIX logikai partíciók (LPAR-k) Azure-beli Skytapba való migrálását mutatja be.
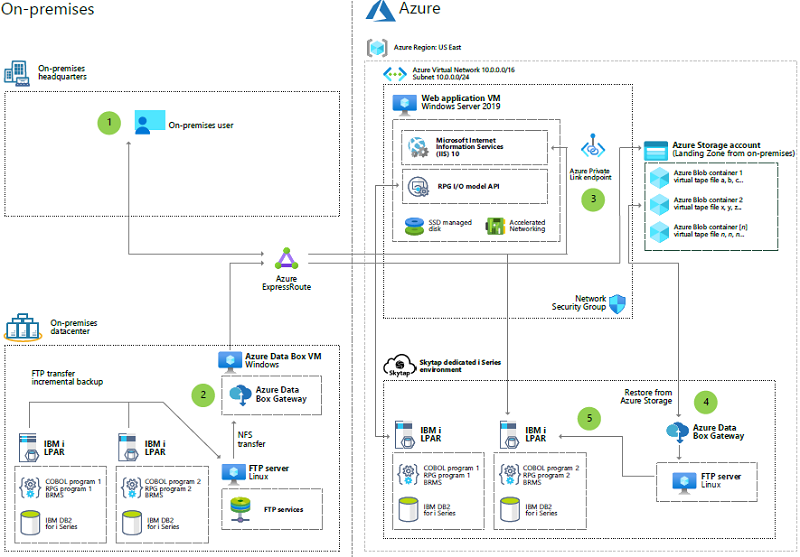
IBM i sorozatú alkalmazások migrálása a Skytapba az Azure-ban
Ez a példaarchitektúra bemutatja, hogyan használhatja a natív IBM i biztonsági mentési és helyreállítási szolgáltatásokat a Microsoft Azure-összetevőkkel.
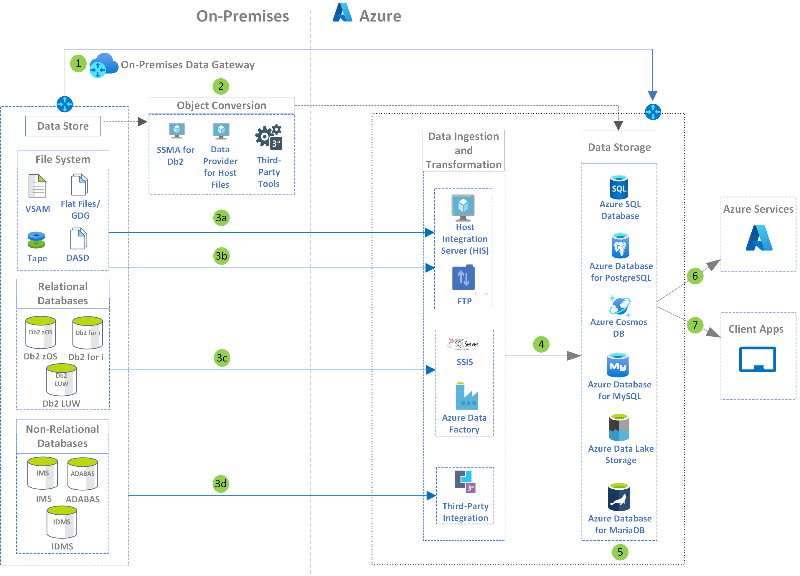
Az örökölt migrálások és az Azure-ba történő átalakítások kulcsfontosságú része az adatok szempontjából. Ez nem csak az adatáthelyezést, hanem az adatreplikálást és a szinkronizálást is magában foglalhatja.
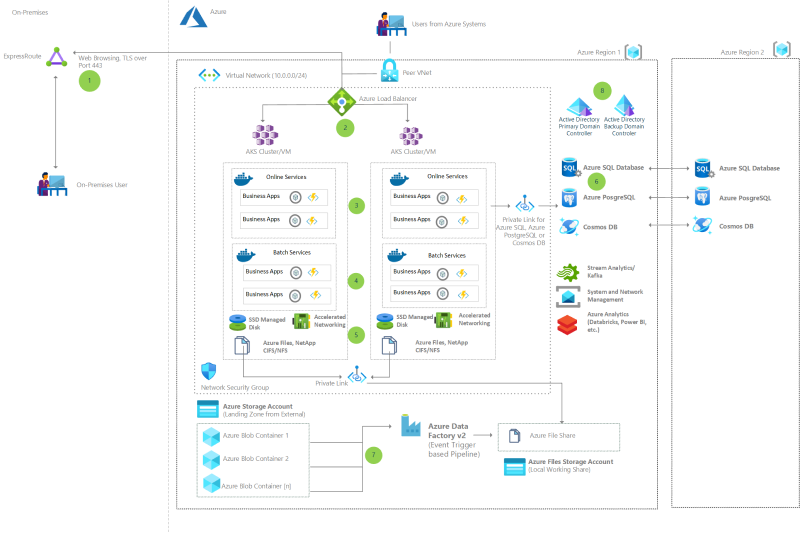
Nagy- vagy középszámítógépek adatainak modernizálása
Ismertető az IBM nagy- és középszámítógépei adatainak modernizálásáról. Egy adatközpontú megközelítést ismerhet meg ezen adatok az Azure-ba való migrálása kapcsán.
Nagyszámítógép-adatok replikálás és szinkronizálása az Azure-ban
Adatok replikálása a nagyszámítógép és a középső rendszerek modernizálása közben. A helyszíni adatok szinkronizálása az Azure-adatokkal a modernizáció során.
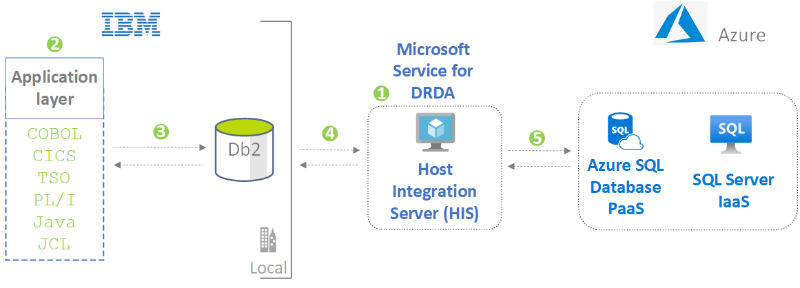
Nagyszámítógépes hozzáférés az Azure-adatbázisokhoz
Hozzáférés biztosítása a nagyszámítógép-alkalmazások számára az Azure-adatokhoz kód módosítása nélkül. A Microsoft Service for DRDA használatával db2 SQL-utasításokat futtathat egy SQL Server-adatbázisban.
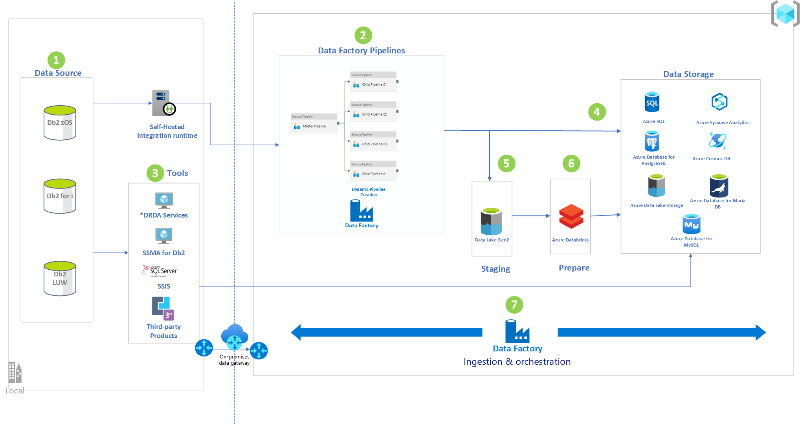
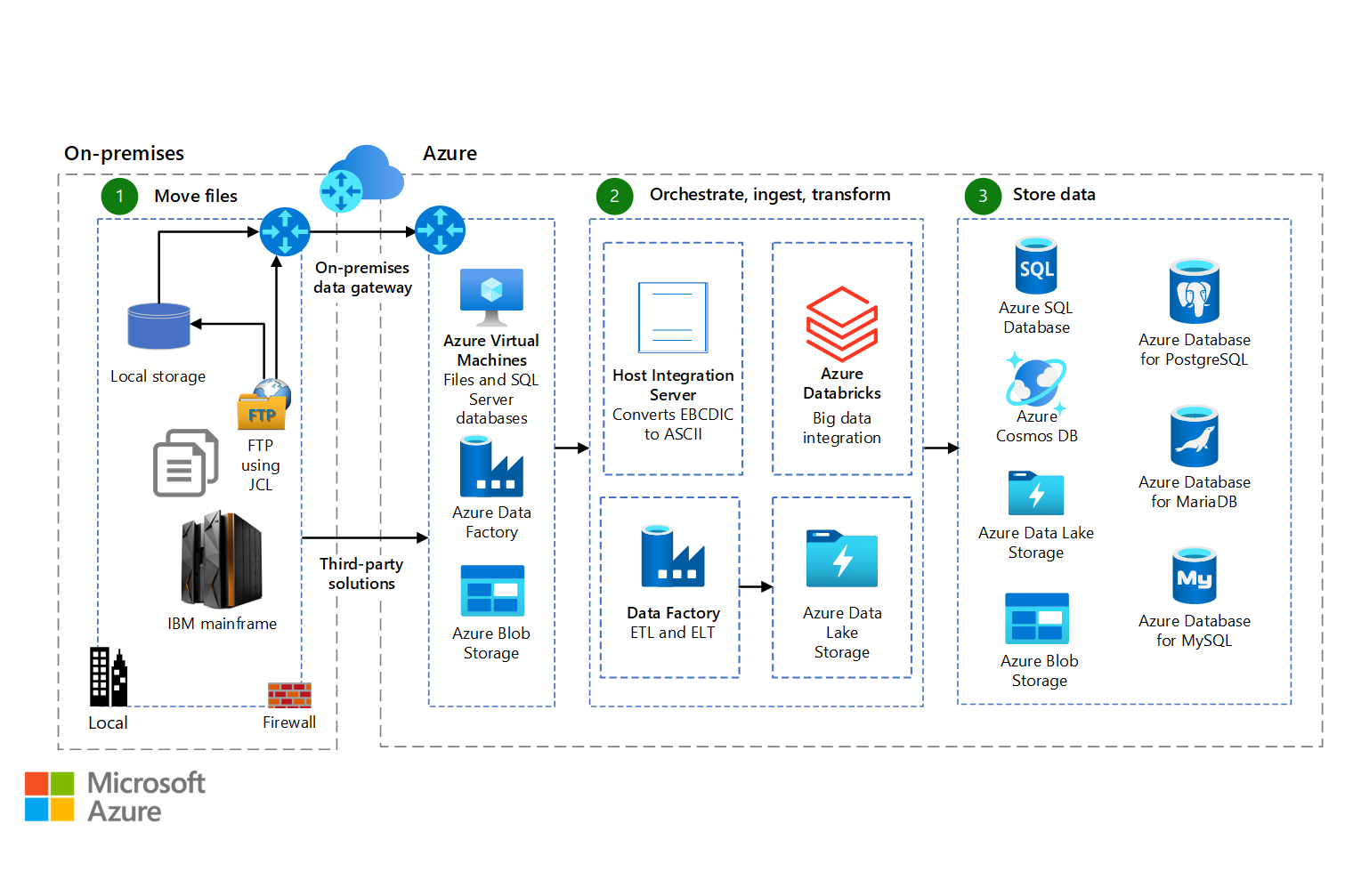
Nagyszámítógépes fájlreplikálás és szinkronizálás az Azure-ban
Ismerje meg a nagyszámítógépek és a központi fájlrendszer adatainak helyszíni és Azure-beli áthelyezésének, átalakításának, átalakításának és tárolásának számos lehetőségét.
A tanulmányokat, blogokat, webináriumokat és egyéb erőforrásokat az utazáshoz, az örökölt rendszerek Azure-ba való migrálásának módjaihoz használhatja:
A különböző iparágak innovatív és inspiráló módon migrálnak az örökölt nagyszámítógépekről és középkategóriás rendszerekről. Tekintse meg a következő ügyfél-esettanulmányokat és sikertörténeteket: