Oktatóanyag: Vektoros hasonlósági keresés végrehajtása Azure OpenAI-beágyazásokon az Azure Cache for Redis használatával
Ebben az oktatóanyagban egy alapvető vektor-hasonlósági keresési használati esetet fog végigvezetni. Az Azure OpenAI Service által létrehozott beágyazásokkal és az Azure Cache for Redis nagyvállalati rétegének beépített vektorkeresési képességeivel lekérdezheti a filmek adatkészletét, hogy megtalálja a leginkább releváns egyezést.
Az oktatóanyag a Wikipedia Movie Plots adatkészletét használja, amely több mint 35 000 film ábrázolását tartalmazza a Wikipédiából az 1901 és 2017 közötti évekre vonatkozóan. Az adatkészlet minden filmhez tartalmaz egy ábrázolás összegzését, valamint olyan metaadatokat, mint a film megjelenésének éve, a rendező(k), a fő szereplők és a műfaj. Az oktatóanyag lépéseit követve beágyazásokat hozhat létre a diagram összegzése alapján, és a többi metaadat használatával hibrid lekérdezéseket futtathat.
Ebben az oktatóanyagban az alábbiakkal fog megismerkedni:
- Vektorkereséshez konfigurált Azure Cache for Redis-példány létrehozása
- Telepítse az Azure OpenAI-t és más szükséges Python-kódtárakat.
- Töltse le a filmadatkészletet, és készítse elő elemzésre.
- Beágyazások létrehozásához használja a text-embedding-ada-002 (2. verzió) modellt.
- Vektorindex létrehozása az Azure Cache for Redisben
- A találatok rangsorolásához használjon koszin hasonlóságot.
- A RediSearch hibrid lekérdezési funkciójának használatával előszűrheti az adatokat, és még hatékonyabbá teheti a vektorkeresést.
Fontos
Ez az oktatóanyag végigvezeti a Jupyter Notebook létrehozásának lépésein. Ezt az oktatóanyagot egy Python-kódfájllal (.py) követheti, és hasonló eredményeket kaphat, de az oktatóanyag összes kódblokkját hozzá kell adnia a fájlhoz, és egyszer végre kell hajtania az .py eredményeket. Más szóval a Jupyter-jegyzetfüzetek köztes eredményeket biztosítanak a cellák végrehajtása során, de ez nem elvárható a Python-kódfájlok használatakor.
Fontos
Ha inkább egy befejezett Jupyter-jegyzetfüzetben szeretné követni a műveletet, töltse le a tutorial.ipynb nevű Jupyter-jegyzetfüzetfájlt, és mentse az új redis-vector mappába.
Előfeltételek
- Azure-előfizetés – Ingyenes létrehozás
- A kívánt Azure-előfizetésben az Azure OpenAI számára biztosított hozzáférés jelenleg az Azure OpenAI-hoz való hozzáférésre van szükség. Az Azure OpenAI-hoz való hozzáférésre a következő https://aka.ms/oai/accessűrlap kitöltésével jelentkezhet: .
- Python 3.7.1 vagy újabb verzió
- Jupyter notebookok (nem kötelező)
- Azure OpenAI-erőforrás a text-embedding-ada-002 (2. verzió) üzembe helyezett modellel. Ez a modell jelenleg csak bizonyos régiókban érhető el. A modell üzembe helyezésére vonatkozó útmutatásért tekintse meg az erőforrás-telepítési útmutatót .
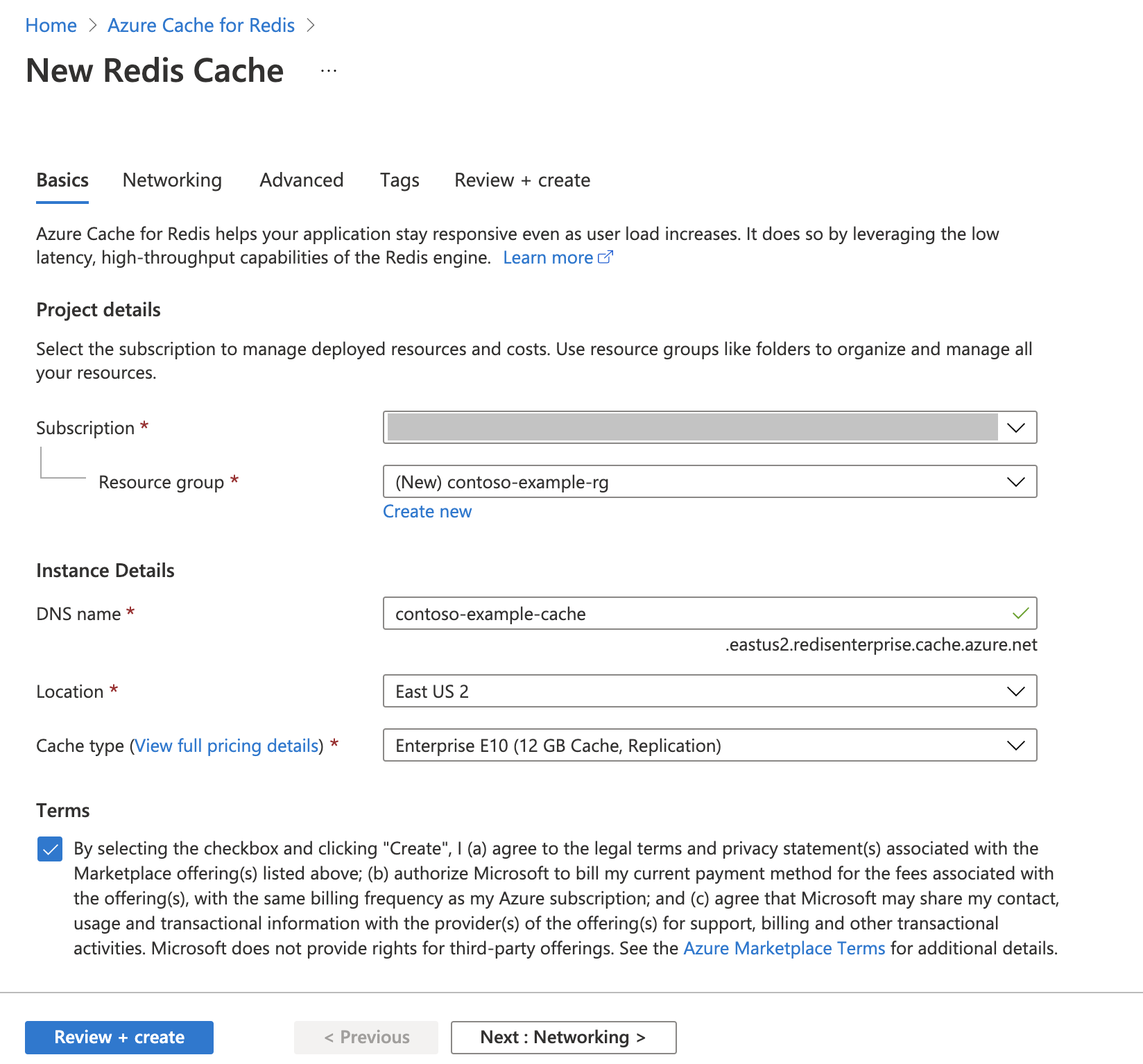
Azure Cache for Redis-példány létrehozása
Kövesse a rövid útmutatót: Redis Enterprise-gyorsítótár létrehozása útmutató. A Speciális lapon győződjön meg arról, hogy hozzáadta a RediSearch modult, és a vállalati fürtszabályzatot választotta. Minden más beállítás megfelelhet a rövid útmutatóban ismertetett alapértelmezett beállításnak.
A gyorsítótár létrehozása néhány percet vesz igénybe. Addig is továbbléphet a következő lépésre.
A fejlesztési környezet beállítása
Hozzon létre egy redis-vector nevű mappát a helyi számítógépen azon a helyen, ahol általában menti a projekteket.
Hozzon létre egy új Python-fájlt (tutorial.py) vagy Jupyter-jegyzetfüzetet (tutorial.ipynb) a mappában.
Telepítse a szükséges Python-csomagokat:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
Az adathalmaz letöltése
Egy webböngészőben keresse meg a következőt https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots: .
Jelentkezzen be vagy regisztráljon a Kaggle-ban. A fájl letöltéséhez regisztráció szükséges.
A archive.zip fájl letöltéséhez válassza a Kaggle letöltési hivatkozását.
Bontsa ki a archive.zip fájlt, és helyezze át a wiki_movie_plots_deduped.csv a redis-vector mappába.
Kódtárak importálása és kapcsolati adatok beállítása
Az Azure OpenAI-ra való sikeres híváshoz egy végpontra és egy kulcsra van szükség. Egy végpontra és egy kulcsra is szüksége van az Azure Cache for Redishez való csatlakozáshoz.
Nyissa meg az Azure OpenAI-erőforrást az Azure Portalon.
Keresse meg a végpontot és a kulcsokat az Erőforrás-kezelés szakaszban. Másolja ki a végpontot és a hozzáférési kulcsot, mivel mindkettőre szüksége lesz az API-hívások hitelesítéséhez. Példavégpont:
https://docs-test-001.openai.azure.com. A következők bármelyikét használhatja:KEY1vagyKEY2.Nyissa meg az Azure Cache for Redis-erőforrás áttekintési oldalát az Azure Portalon. Másolja ki a végpontot.
Keresse meg a hozzáférési kulcsokat a Beállítások szakaszban. Másolja ki a hozzáférési kulcsot. A következők bármelyikét használhatja:
PrimaryvagySecondary.Adja hozzá a következő kódot egy új kódcellához:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Frissítse az Azure OpenAI-üzemelő példány kulcs-
API_KEYRESOURCE_ENDPOINTés végpontértékeit.DEPLOYMENT_NAMEA beágyazási modell használatávaltext-embedding-ada-002 (Version 2)az üzembe helyezés nevére kell állítani, ésMODEL_NAMEa használt beágyazási modellnek kell lennie.Frissítse
REDIS_ENDPOINTazREDIS_PASSWORDAzure Cache for Redis-példány végpontját és kulcsértékét.Fontos
Határozottan javasoljuk, hogy környezeti változókat vagy egy titkos kulcskezelőt, például az Azure Key Vaultot használva adja át az API-kulcs, a végpont és az üzembehelyezési név adatait. Ezek a változók egyszerű szövegben vannak beállítva az egyszerűség kedvéért.
A 2. kódcella végrehajtása.
Adathalmaz importálása pandasba és adatok feldolgozása
Ezután beolvassa a csv-fájlt egy pandas DataFrame-be.
Adja hozzá a következő kódot egy új kódcellához:
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfHajtsa végre a 3. kódcellát. A következő kimenetnek kell megjelennie:
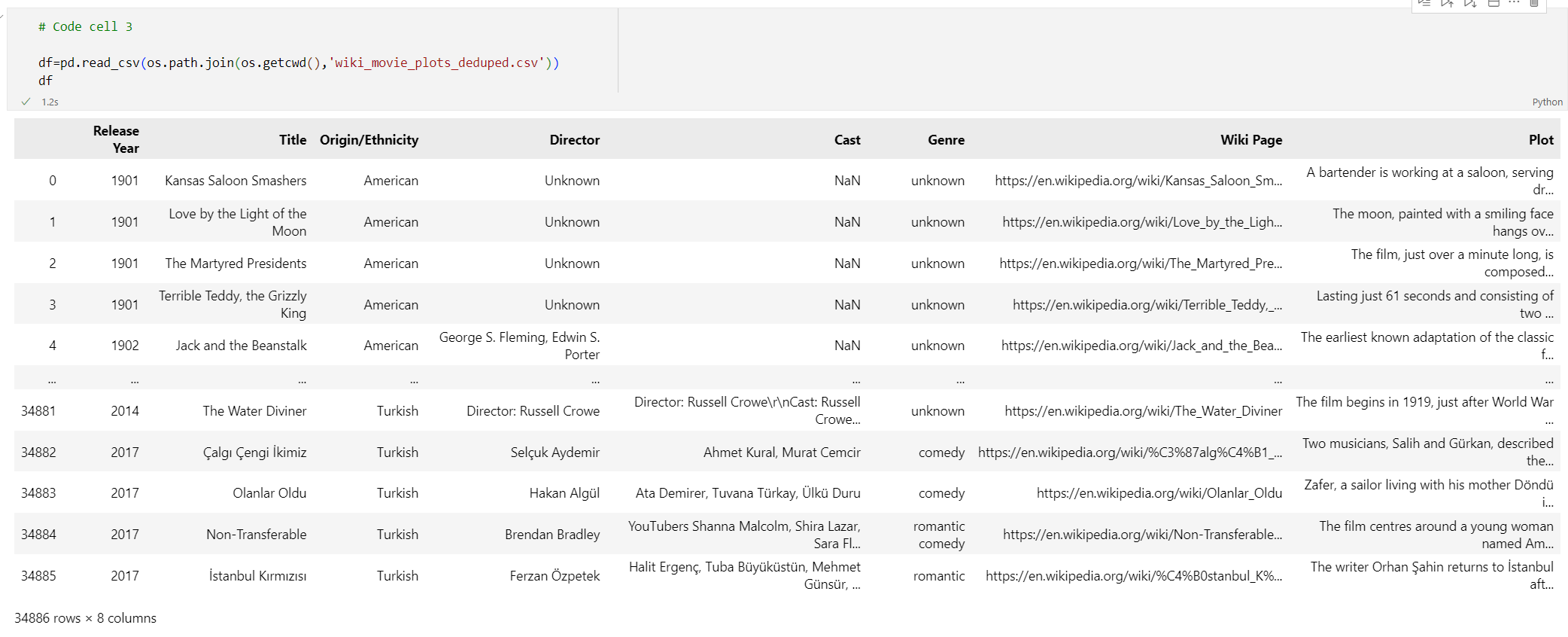
Ezután feldolgozhatja az adatokat egy
idindex hozzáadásával, szóközök eltávolításával az oszlopcímekből, és szűri a filmeket, hogy csak az 1970 után készült filmeket és az angolul beszélő országokból származó filmeket készítsenek. Ez a szűrési lépés csökkenti az adathalmazban lévő filmek számát, ami csökkenti a beágyazások létrehozásához szükséges költségeket és időt. A beállítások alapján szabadon módosíthatja vagy eltávolíthatja a szűrőparamétereket.Az adatok szűréséhez adja hozzá a következő kódot egy új kódcellához:
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfHajtsa végre a 4. kódcellát. A következő eredményeket kell látnia:
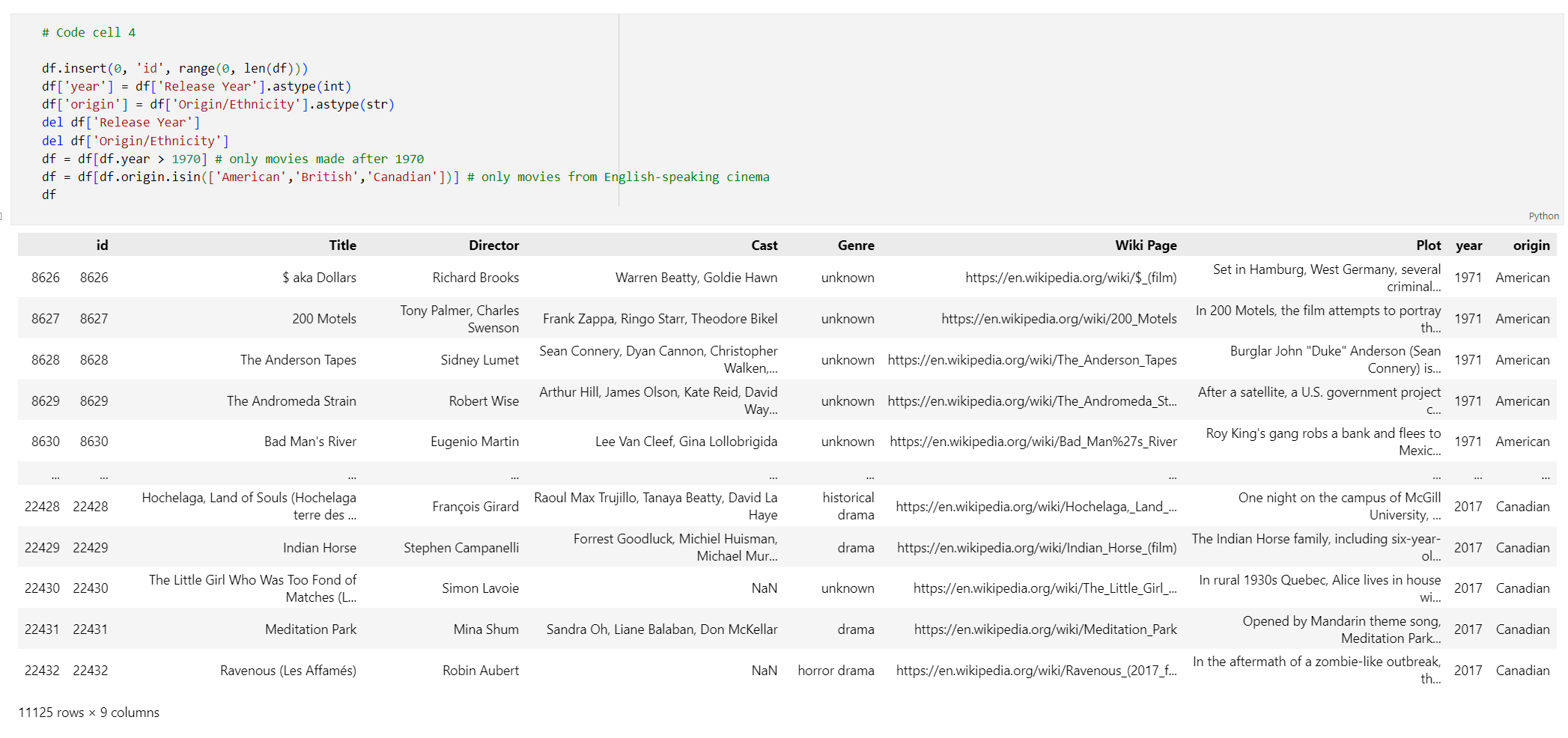
Hozzon létre egy függvényt az adatok megtisztításához a térköz és az írásjelek eltávolításával, majd használja a diagramot tartalmazó adatkereten.
Adja hozzá a következő kódot egy új kódcellához, és hajtsa végre:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Végül távolítsa el azokat a bejegyzéseket, amelyek túl hosszúak a beágyazási modellhez. (Más szóval a 8192-nél több jogkivonatra van szükség.) majd számítsa ki a beágyazások létrehozásához szükséges jogkivonatok számát. Ez hatással van a beágyazási generáció díjszabására is.
Adja hozzá a következő kódot egy új kódcellához:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))Hajtsa végre a 6. kódcellát. A következő kimenetnek kell megjelennie:
Number of movies: 11125 Number of tokens required:7044844Fontos
Tekintse meg az Azure OpenAI szolgáltatás díjszabását , amely a szükséges jogkivonatok száma alapján határozza meg a beágyazások létrehozásának költségeit.


DataFrame betöltése a LangChainbe
Töltse be a DataFrame-et a LangChainbe az DataFrameLoader osztály használatával. Ha az adatok a LangChain-dokumentumokban lesznek, sokkal egyszerűbb a LangChain-kódtárak használata beágyazások létrehozására és hasonlósági keresések elvégzésére. Állítsa be a page_content_column diagramot úgy, hogy a beágyazások létre legyenek hozva ezen az oszlopon.
Adja hozzá a következő kódot egy új kódcellához, és hajtsa végre:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Beágyazások létrehozása és betöltése a Redisbe
Most, hogy az adatokat szűrte és betöltötte a LangChainbe, beágyazásokat fog létrehozni, hogy lekérdezhesse az egyes filmek ábrázolását. Az alábbi kód konfigurálja az Azure OpenAI-t, beágyazásokat hoz létre, és betölti a beágyazási vektorokat az Azure Cache for Redisbe.
Adjon hozzá egy új kódcellát a következő kódhoz:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Hajtsa végre a 8. kódcellát. Ez több mint 30 percet vehet igénybe. A rendszer létrehoz egy
redis_schema.yamlfájlt is. Ez a fájl akkor hasznos, ha az Indexhez szeretne csatlakozni az Azure Cache for Redis-példányban anélkül, hogy újra létrehozna beágyazásokat.
Fontos
A beágyazások létrehozásának sebessége az Azure OpenAI-modell számára elérhető kvótától függ. A percenként 240 ezer jogkivonatot tartalmazó kvótával körülbelül 30 perc alatt feldolgozhatja az adathalmaz 7 M-jogkivonatait.
Vektorkeresési lekérdezések futtatása
Most, hogy beállította az adathalmazt, az Azure OpenAI szolgáltatás API-t és a Redis-példányt, vektorokkal kereshet. Ebben a példában egy adott lekérdezés első 10 találata lesz visszaadva.
Adja hozzá a következő kódot a Python-kódfájlhoz:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Hajtsa végre a 9. kódcellát. A következő kimenetnek kell megjelennie:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)A hasonlósági pontszámot a filmek sorrendi rangsorával együtt a hasonlóság adja vissza. Figyelje meg, hogy az adott lekérdezések hasonlósági pontszámai gyorsabban csökkennek a listában.
Hibrid keresések
Mivel a RediSearch a vektoros keresés mellett gazdag keresési funkciókat is kínál, az adathalmaz metaadatai, például a film műfaja, a szereposztás, a megjelenés éve vagy a rendező alapján is szűrheti az eredményeket. Ebben az esetben szűrjön a műfaj
comedyalapján.Adja hozzá a következő kódot egy új kódcellához:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Hajtsa végre a 10. kódcellát. A következő kimenetnek kell megjelennie:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Az Azure Cache for Redis és az Azure OpenAI service használatával beágyazásokkal és vektorkereséssel hatékony keresési képességeket adhat az alkalmazáshoz.
Az erőforrások eltávolítása
Ha továbbra is használni szeretné a cikkben létrehozott erőforrásokat, tartsa meg az erőforráscsoportot.
Ellenkező esetben az erőforrásokhoz kapcsolódó díjak elkerülése érdekében, ha befejezte az erőforrások használatát, törölheti a létrehozott Azure-erőforráscsoportot.
Figyelmeztetés
Az erőforráscsoport törlése nem vonható vissza. Erőforráscsoport törlésekor az erőforráscsoport összes erőforrása véglegesen törlődik. Figyeljen arra, hogy ne töröljön véletlenül erőforráscsoportot vagy erőforrásokat. Ha olyan meglévő erőforráscsoportban hozta létre az erőforrásokat, amelyekben meg szeretné tartani az erőforrásokat, az erőforráscsoport törlése helyett egyenként törölheti az egyes erőforrásokat.
Erőforráscsoport törlése
Jelentkezzen be az Azure Portalra, és válassza az Erőforráscsoportok elemet.
Jelölje ki a törölni kívánt erőforráscsoportot.
Ha sok erőforráscsoport van, a Szűrő bármely mezőhöz mezőbe írja be a cikk végrehajtásához létrehozott erőforráscsoport nevét. A keresési eredmények listájában válassza ki az erőforráscsoportot.
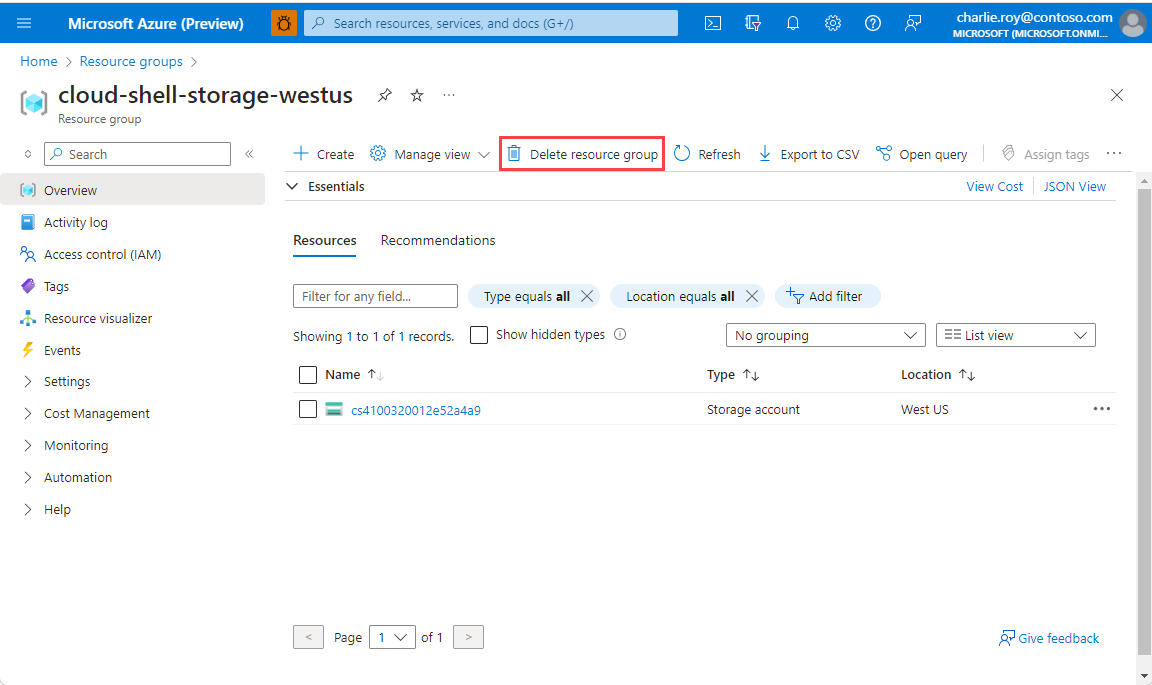
Válassza az Erőforráscsoport törlése elemet.
Az Erőforráscsoport törlése panelen adja meg az erőforráscsoport nevét a megerősítéshez, majd válassza a Törlés lehetőséget.
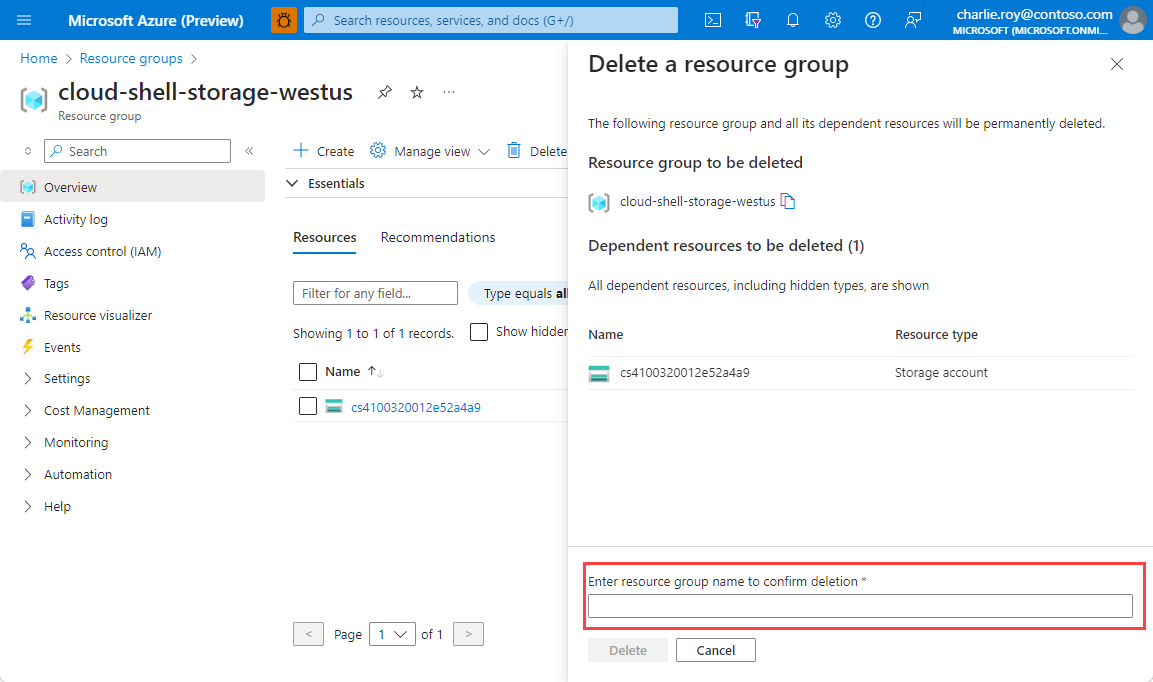
Néhány percen belül az erőforráscsoport és annak összes erőforrása törlődik.
Kapcsolódó tartalom
- További információ az Azure Cache for Redisről
- További információ az Azure Cache for Redis vektorkeresési képességeiről
- További információ az Azure OpenAI Szolgáltatás által létrehozott beágyazásokról
- További információ a koszinusz hasonlóságáról
- Megtudhatja, hogyan hozhat létre AI-alapú alkalmazást az OpenAI és a Redis használatával
- Q&A-alkalmazás létrehozása szemantikai válaszokkal