Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az Azure Monitor riasztásai proaktívan azonosítják az Azure-erőforrások állapotával és teljesítményével kapcsolatos problémákat. Ez a cikk bemutatja, hogyan engedélyezheti és szerkesztheti a Kubernetes-fürtökhöz előre definiált ajánlott metrikariasztási szabályokat.
Ajánlott riasztási szabályok engedélyezése
A klaszterhez ajánlott riasztási szabályok engedélyezéséhez használja az alábbi módszerek valamelyikét. Engedélyezheti ugyanahhoz a fürthöz a Prometheus és a platformmetrika riasztási szabályait is.
Feljegyzés
Az Arc-kompatibilis Kubernetes-fürtökre vonatkozó ajánlott riasztások előzetes verzióban érhetők el, és nem támogatják a platformmetrika-riasztási szabályokat.
Az Azure portal használatával a Prometheus szabálycsoport azonos régióban jön létre, mint a fürt.
A fürt Riasztások menüjében válassza a Javaslatok beállítása lehetőséget.
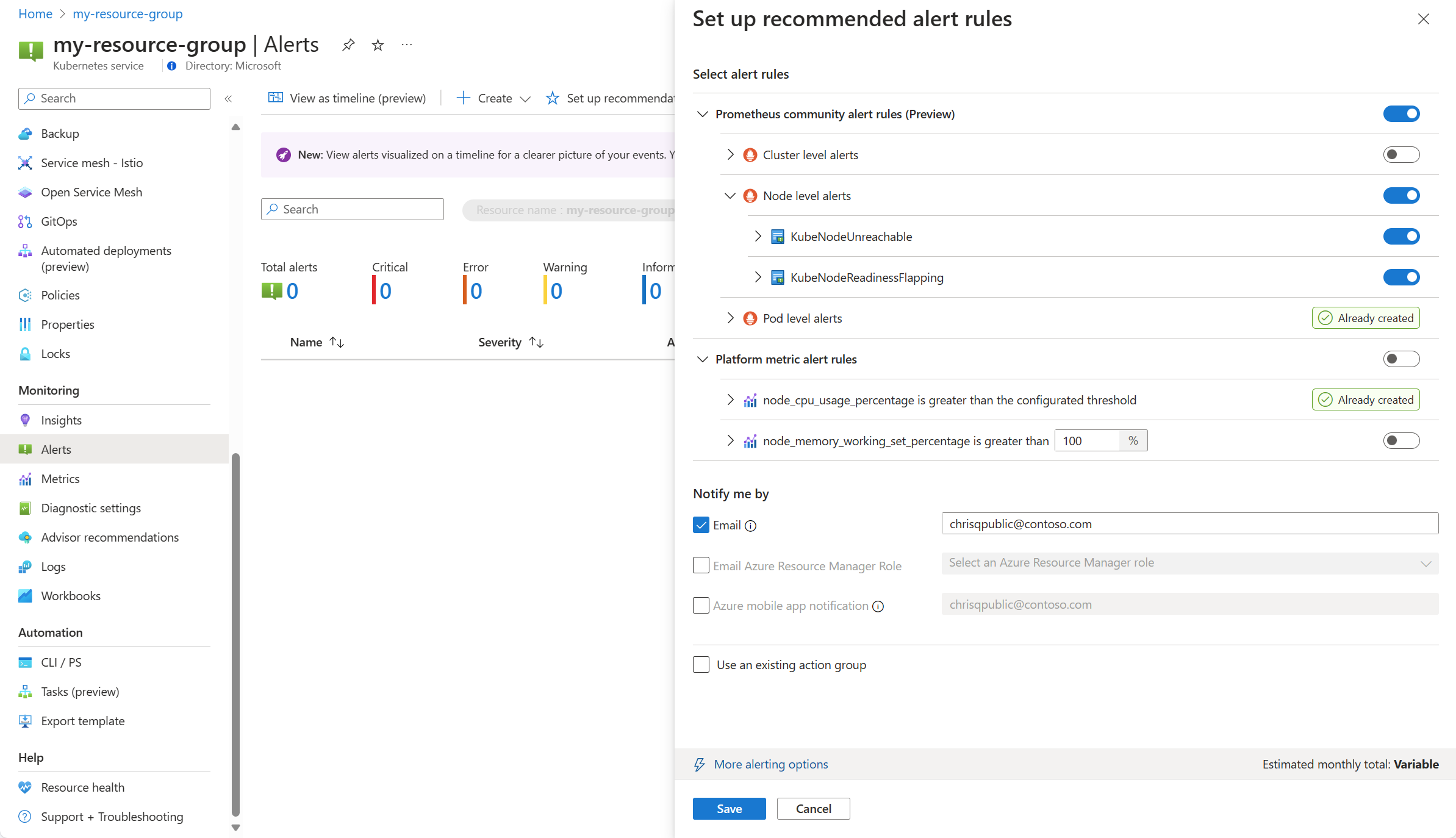
Az elérhető Prometheus- és platformriasztási szabályok pod-, fürt- és csomópontszint szerint rendezett Prometheus-szabályokkal jelennek meg. Állítsa be a Prometheus-szabályok egy csoportját az adott szabálykészlet engedélyezéséhez. Bontsa ki a csoportot az egyes szabályok megtekintéséhez. Meghagyhatja az alapértelmezett beállításokat, vagy letilthatja az egyes szabályokat, és szerkesztheti a nevüket és súlyosságukat.
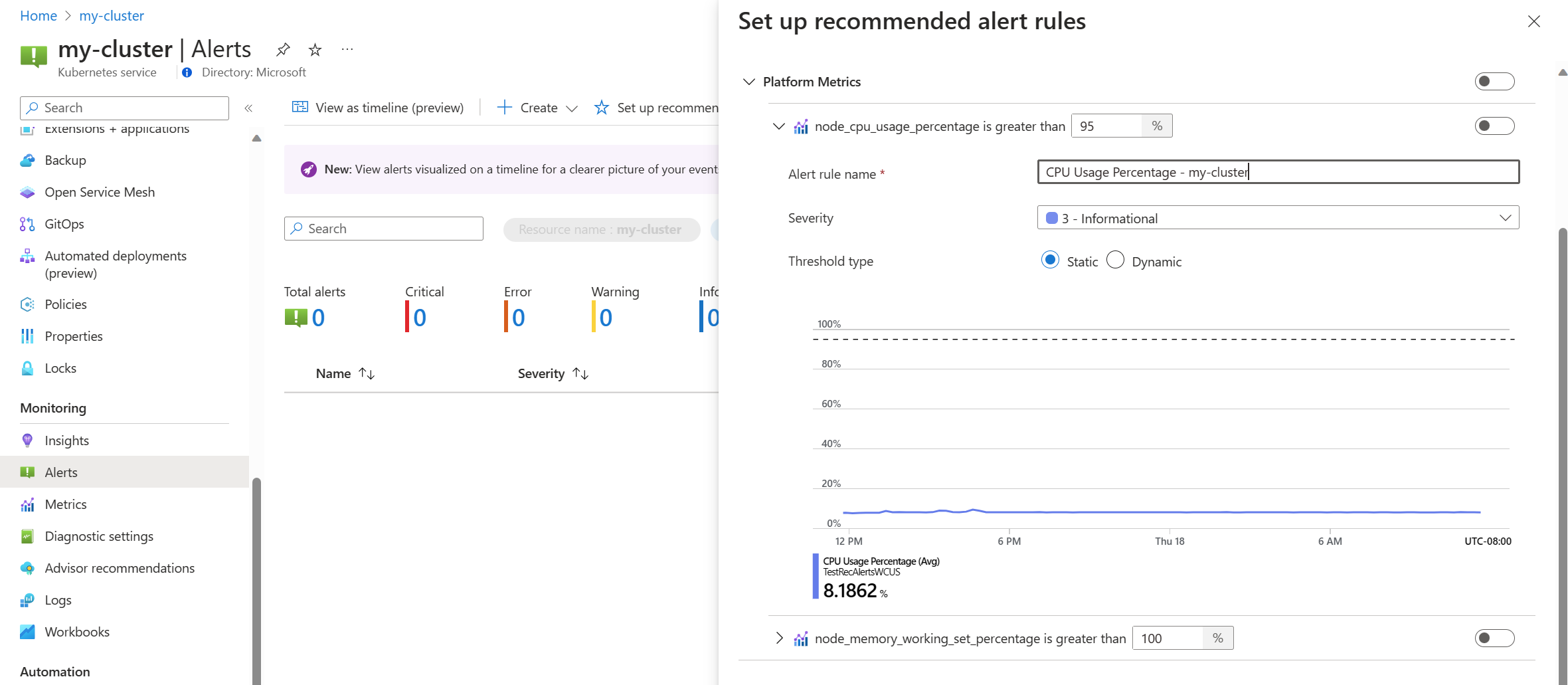
A platformmetrikaszabály engedélyezéséhez kapcsolja be azt a szabályt. A szabályt kibontva módosíthatja annak részleteit, például a nevet, a súlyosságot és a küszöbértéket.
Válasszon ki egy vagy több értesítési módszert egy új műveletcsoport létrehozásához, vagy válasszon ki egy meglévő műveletcsoportot a riasztási szabályok értesítési adataival.
Kattintson a Mentés gombra a szabálycsoport mentéséhez.



Ajánlott riasztási szabályok szerkesztése
A szabálycsoport létrehozása után nem szerkesztheti a szabályokat a portál ugyanazon lapján. A Prometheus-metrikák esetében a szabálycsoportot szerkesztenie kell a benne lévő szabályok módosításához, beleértve a még nem engedélyezett szabályok engedélyezését is. Platformmetrikák esetén szerkesztheti az egyes riasztási szabályokat.
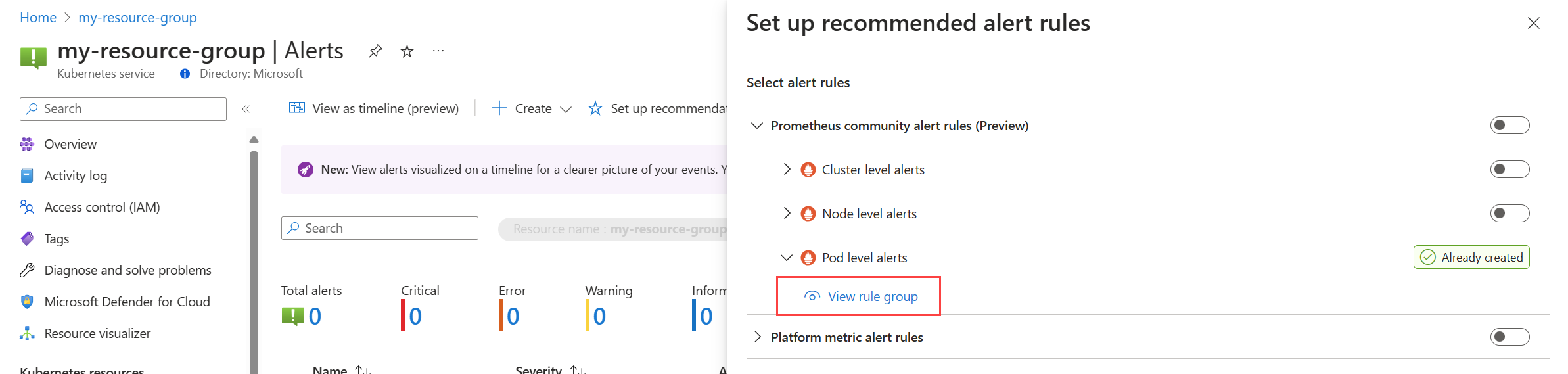
A fürt Riasztások menüjében válassza a Javaslatok beállítása lehetőséget. A már létrehozott szabályok és szabálycsoportok már létrehozottként lesznek megjelölve.
Bontsa ki a szabályt vagy szabálycsoportot. Kattintson a Prometheus szabálycsoportjának megtekintésére és a platformmetrikák riasztási szabályának megtekintésére.
Prometheus-szabálycsoportok esetén:
válassza a Szabályok lehetőséget a csoport riasztási szabályainak megtekintéséhez.
Kattintson a módosítani kívánt szabály melletti Szerkesztés ikonra. A szabály módosításához használja a riasztási szabály létrehozása című útmutatót.
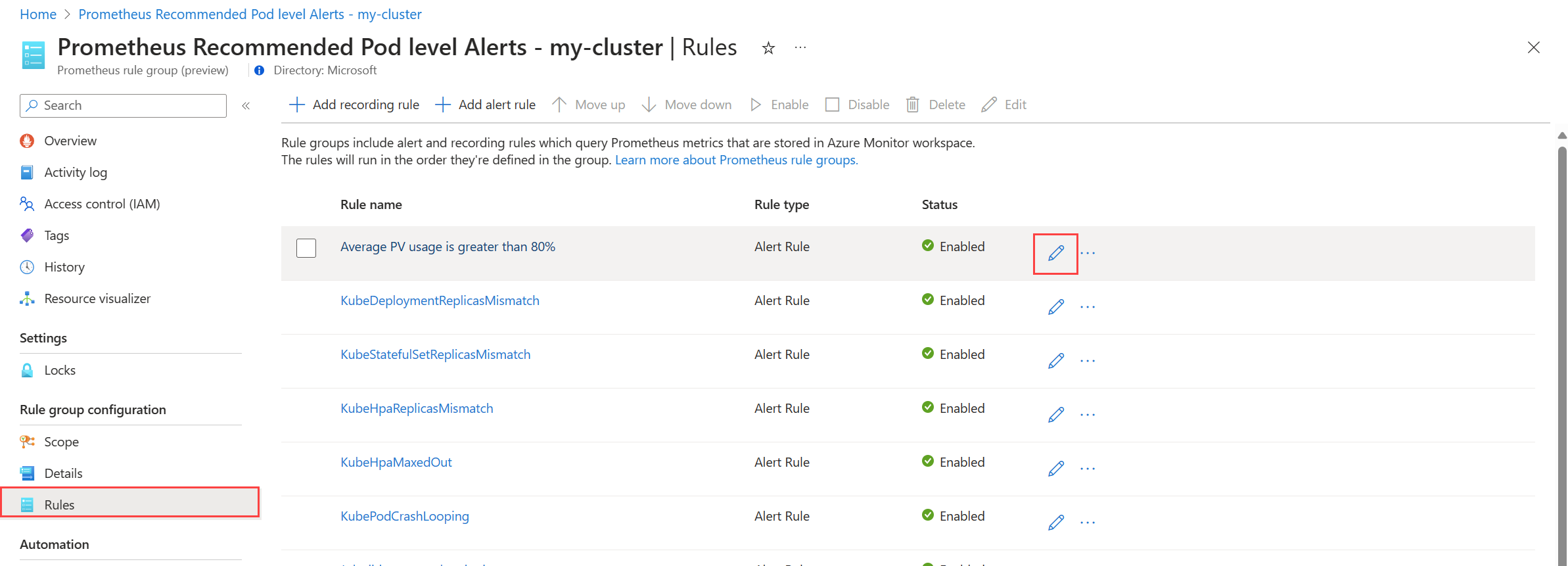
Ha befejezte a szabályok szerkesztését a csoportban, kattintson a Mentés gombra a szabálycsoport mentéséhez.
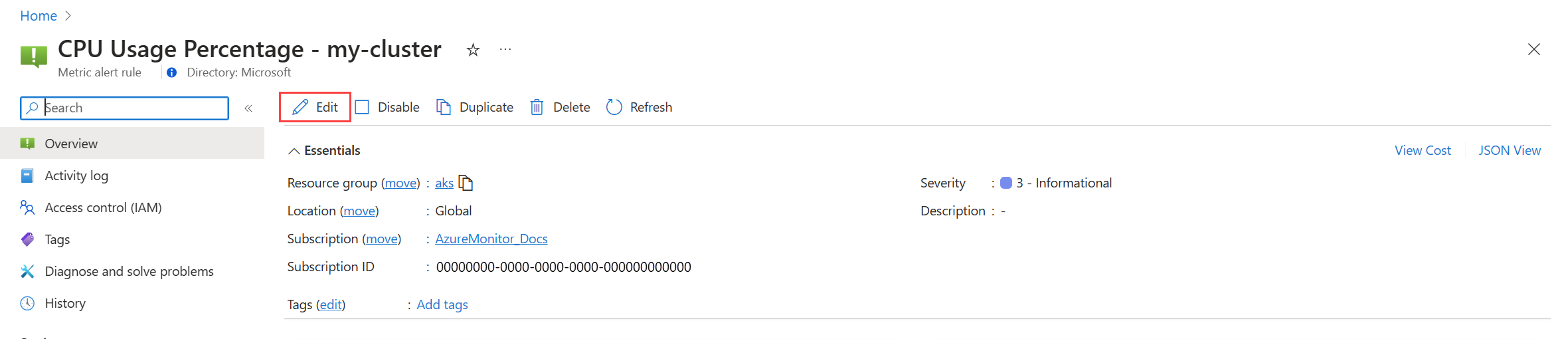
Platformmetrikák esetén:
Kattintson a Szerkesztés gombra a riasztási szabály részleteinek megnyitásához. A szabály módosításához használja a riasztási szabály létrehozása című útmutatót.



Riasztási szabálycsoport letiltása
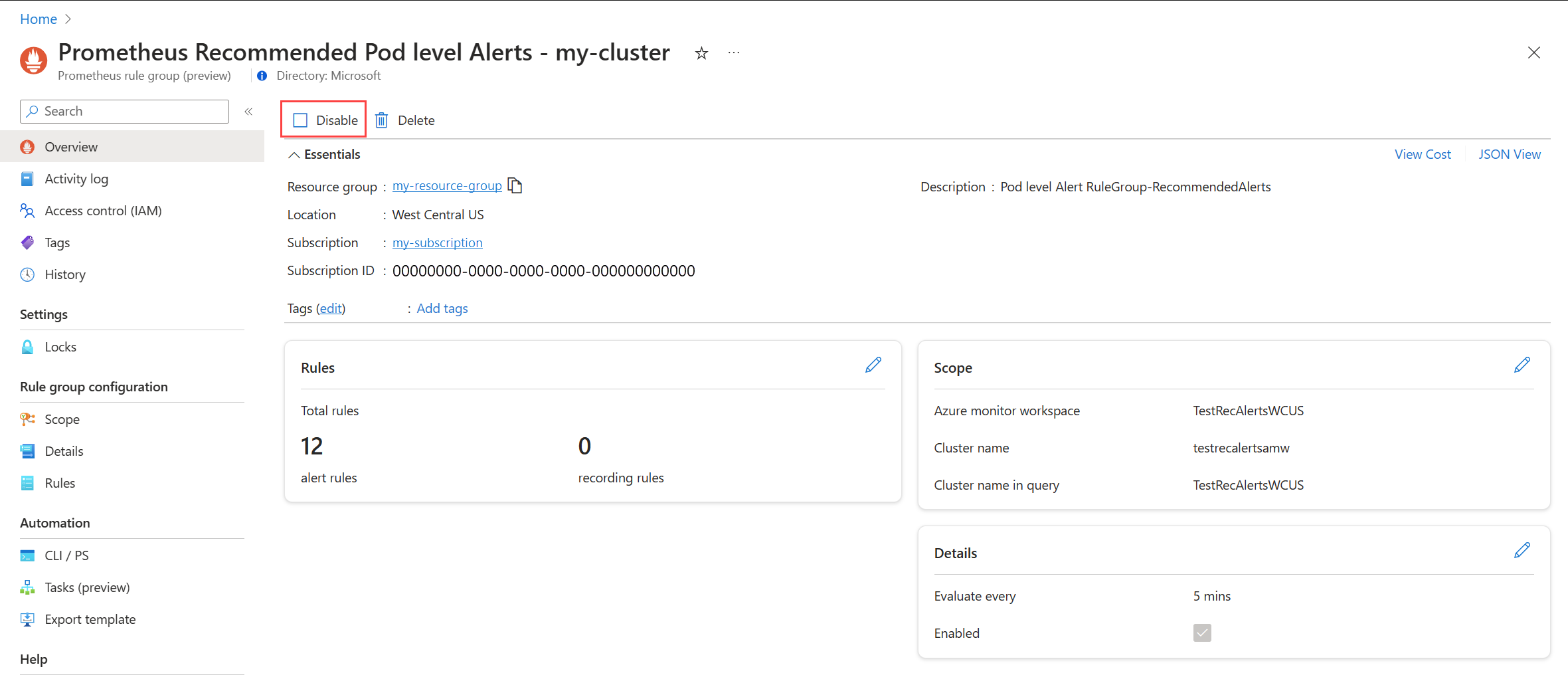
Tiltsa le a szabálycsoportot, hogy ne kapjon riasztásokat a benne lévő szabályoktól.
Tekintse meg a Prometheus riasztási szabálycsoportját vagy platformmetrikai riasztási szabályát az ajánlott riasztási szabályok szerkesztésében leírtak szerint.
Az Áttekintés menüben válassza a Letiltás lehetőséget.

Ajánlott riasztási szabály részletei
Az alábbi táblázatok az egyes ajánlott riasztási szabályok részleteit sorolják fel. Mindegyik forráskód elérhető a GitHubon a Prometheus-közösség hibaelhárítási útmutatóival együtt.
A Prometheus közösségi riasztási szabályai
Fürtszintű riasztások
| Riasztás neve | Leírás | Alapértelmezett küszöbérték | Időkeret (perc) |
|---|---|---|---|
| KubeCPU kvóta-túlterhelés | A névterekhez lefoglalt CPU-erőforráskvóta az elmúlt 5 percben több mint 50%-kal meghaladja a fürt csomópontjaikon elérhető CPU-erőforrásokat. | >1.5 | 5 |
| Kube memória kvóta túllépése | A névterekhez lefoglalt memóriaerőforrás-kvóta az elmúlt 5 percben több mint 50%-kal meghaladja a fürt csomópontjaiban rendelkezésre álló memóriaerőforrásokat. | >1.5 | 5 |
| KubeContainerOOMKilledCount | Az elmúlt 5 percben a podok belsejében lévő egy vagy több tároló memóriahiányos (OOM) események miatt leállt. | >0 | 5 |
| KubeClientErrors | A Kubernetes API-kérelmekben az ügyfélhibák (5xx-től kezdődő HTTP-állapotkódok) aránya meghaladja az elmúlt 15 percben az API-kérések teljes arányának 1%-át. | >0.01 | 15 |
| KubePersistentVolumeFillingUp | Az állandó kötet megtelik, és várhatóan elfogy a rendelkezésre álló terület aránya, a felhasznált terület és a rendelkezésre álló terület lineáris trendje az elmúlt 6 órában. Ezeket a feltételeket a rendszer az elmúlt 60 percben értékeli ki. | n/a | 60 |
| KubeÁllandóKötetInódusokBetöltése | Az állandó köteten belüli inódok kevesebb mint 3%-a érhető el az elmúlt 15 perc során. | <0.03 | 15 |
| KubePersistentVolume hibák | Egy vagy több állandó kötet az elmúlt 5 percben sikertelen vagy függőben lévő fázisban van. | >0 | 5 |
| KubeKonténerVárakozik | A Kubernetes podokban található egy vagy több tároló már 60 perce várakozási állapotban van. | >0 | 60 |
| KubeDaemonSetNotScheduled (KubeDaemonSet nem ütemezett) | Az elmúlt 15 percben egy vagy több pod nem lett ütemezve egyetlen csomópontra sem. | >0 | 15 |
| KubeDaemonSetMisScheduled | Egy vagy több pod helytelenül van ütemezve a fürtben az elmúlt 15 percben. | >0 | 15 |
| KubeQuotaAlmostFull | A Kubernetes-erőforráskvóták kihasználtsága az elmúlt 15 perc kemény korlátainak 90%-a és 100%-a között van. | >0,9 <1 | 15 |
Csomópontszintű riasztások
| Riasztás neve | Leírás | Alapértelmezett küszöbérték | Időkeret (perc) |
|---|---|---|---|
| KubeNodeNemElérhető | Egy csomópont az elmúlt 15 percben nem érhető el. | 1 | 15 |
| Kube csomópont készenléti ingadozás | A csomópontok készültségi állapota az elmúlt 15 percben több mint 2 alkalommal módosult. | 2 | 15 |
Podszintű riasztások
| Riasztás neve | Leírás | Alapértelmezett küszöbérték | Időkeret (perc) |
|---|---|---|---|
| KubePVUsageHigh | Az elmúlt 15 percben a Persistent Volumes (PV-k) átlagos kihasználtsága meghaladja a 80%-ot a podok esetében. | >0.8 | 15 |
| KubeTelepítésReplikákEltérése | A replikák kívánt száma és az elmúlt 10 percben elérhető replikák száma között eltérés van. | n/a | 10 |
| KubeStatefulSetReplicasMismatch | A StatefulSet kész replikáinak száma az elmúlt 15 percben nem egyezik meg a StatefulSet összes replikáinak számával. | n/a | 15 |
| KubeHpaReplicasMismatch | A fürt vízszintes pod-méretezője az elmúlt 15 percben nem érte el a kívánt replikaszámot. | n/a | 15 |
| KubeHpaMaxedOut | A fürt vízszintes podméretezője (HPA) az elmúlt 15 percben a maximális replikákon futott. | n/a | 15 |
| KubePodCrashLooping | Egy vagy több pod CrashLoopBackOff állapotban van, ahol a pod az indítás után folyamatosan összeomlik, és az elmúlt 15 percben sikertelenül helyreáll. | >=1 | 15 |
| KubeJobStale | Az elmúlt 6 órában legalább egy feladatpéldány nem fejeződött be sikeresen. | >0 | 360 |
| KubePódTartályÚjraindítás | Az elmúlt egy órában a Kubernetes-fürt podjain belül egy vagy több tároló már legalább egyszer újraindult. | >0 | 15 |
| KubePodReadyStateLow | Bármely üzembe helyezésnél vagy daemonset esetében a kész állapotú podok aránya a Kubernetes-fürtben az utolsó 5 percben 80% alá csökken. | <0.8 | 5 |
| KubePodHibaállapot | Az elmúlt 5 percben egy vagy több pod hibaállapotban van. | >0 | 5 |
| A KubePod nem indult el a vezérlő által | Egy vagy több pod nincs kész állapotban (azaz a "Függőben" vagy az "Ismeretlen" fázisban) az elmúlt 15 percben. | >0 | 15 |
| KubeStatefulSetGenerációEltérés | A Kubernetes StatefulSet megfigyelt generációja nem egyezik meg a metaadat-generációjával az elmúlt 15 percben. | n/a | 15 |
| KubeJobFailed | Egy vagy több Kubernetes-feladat meghiúsult az elmúlt 15 percben. | >0 | 15 |
| KubeContainerÁtlagosCPUMagas | Az átlagos processzorhasználat tárolónként meghaladja a 95%-ot az elmúlt 5 percben. | >0.95 | 5 |
| KubeTárolóÁtlagosMemóriaMagas | A tárolónkénti átlagos memóriahasználat az elmúlt 5 percben meghaladja a 95%-ot. | >0.95 | 10 |
| KubeletPodIndításiKésleltetésMagas | A pod indítási késésének 99. percentilise az elmúlt 10 percben meghaladja a 60 másodpercet. | >60 | 10 |
Platformmetrika riasztási szabályai
| Riasztás neve | Leírás | Alapértelmezett küszöbérték | Időkeret (perc) |
|---|---|---|---|
| A csomópont processzorhasználati aránya nagyobb, mint 95% | A csomópont processzorhasználati aránya nagyobb, mint 95% az elmúlt 5 percben. | 95 | 5 |
| A csomópont memória-munkakészletének százalékos aránya nagyobb, mint 100% | A csomópont memória-munkakészletének százalékos aránya nagyobb, mint 100% az elmúlt 5 percben. | 100 | 5 |
Korábbi Container Insights metrikariasztások (előzetes verzió)
A Container Insights metrikaszabályai 2024. május 31-én megszűntek. Ezek a szabályok nyilvános előzetes verzióban voltak, de az általános rendelkezésre állás elérése nélkül lettek kivonva, mivel a cikkben ismertetett új ajánlott metrikariasztások már elérhetők.
Ha már engedélyezte ezeket az örökölt riasztási szabályokat, tiltsa le őket, és engedélyezze az új felületet.
Metrikafigyelmeztetési szabályok letiltása
- A Insights menüben válassza ki a klaszterhez tartozó Ajánlott riasztások (előzetes verzió) lehetőséget.
- Módosítsa az egyes riasztási szabályok állapotát letiltottra.
Régi riasztások leképezése
Az alábbi táblázat az örökölt Container Insights-metrikariasztások mindegyikét megfelelteti a Prometheus által javasolt metrikariasztásoknak.
| Ajánlott egyéni metrika riasztás | Prometheus/Platform-metrika megfelelő ajánlott riasztás | Feltétel |
|---|---|---|
| Befejezett feladatok száma | KubeJobStale (Podszintű riasztások) | Az elmúlt 6 órában legalább egy feladatpéldány nem fejeződött be sikeresen. |
| Konténer CPU használat (%) | KubeContainerAverageCPUHigh (Podszintű riasztások) | Az átlagos processzorhasználat tárolónként meghaladja a 95%-ot az elmúlt 5 percben. |
| Konténer memóriahasználat %-a | KubeContainerAverageMemoryHigh (Pod-szintű riasztások) | A tárolónkénti átlagos memóriahasználat az elmúlt 5 percben meghaladja a 95%-ot. |
| Sikertelen podok száma | KubePodFailedState (Podszintű riasztások) | Az elmúlt 5 percben egy vagy több pod hibaállapotban van. |
| Csomópont CPU% | A csomópont processzorának százalékos aránya nagyobb, mint 95% (platformmetrika) | A csomópont processzorhasználati aránya nagyobb, mint 95% az elmúlt 5 percben. |
| Csomópont lemezhasználatának %-a | n/a | A csomópontok átlagos lemezhasználata nagyobb, mint 80%. |
| A csomópont állapota NotReady | KubeNodeUnreachable (csomópontszintű riasztások) | Egy csomópont az elmúlt 15 percben nem érhető el. |
| Csomópont munkakészletének memória %-a | A csomópont memória-munkakészletének százalékos aránya nagyobb, mint 100% | A csomópont memória-munkakészletének százalékos aránya nagyobb, mint 100% az elmúlt 5 percben. |
| OOM által megölt tárolók | KubeContainerOOMKilledCount (fürtszintű riasztások) | Az elmúlt 5 percben a podok belsejében lévő egy vagy több tároló memóriahiányos (OOM) események miatt leállt. |
| Állandó kötethasználat % | KubePVUsageHigh (Podszintű riasztások) | Az elmúlt 15 percben a Persistent Volumes (PV-k) átlagos kihasználtsága meghaladja a 80%-ot a podok esetében. |
| Podok készenléte (%) | KubePodReadyStateLow (Podszintű riasztások) | Bármely üzembe helyezésnél vagy daemonset esetében a kész állapotú podok aránya a Kubernetes-fürtben az utolsó 5 percben 80% alá csökken. |
| Újrainduló tárolók száma | KubePodContainerRestart (Podszintű riasztások) | Az elmúlt egy órában a Kubernetes-fürt podjain belül egy vagy több tároló már legalább egyszer újraindult. |
Örökölt metrikaleképezés
Az alábbi táblázat leképezi az örökölt Container Insights egyéni metrikákat a megfelelő Prometheus-metrikákra.
| Egyéni metrikák | Egyenértékű Prometheus-metrika |
|---|---|
| Cpu használat milli-magokban | rate(container_cpu_usage_seconds_total[5m]) * 1000 |
| CPU-használati arányszázalék | 100 * rate(container_cpu_usage_seconds_total{cluster="$cluster"}[5m]) |
| eloszthatóCPU-kihasználtságSzázaléka | 100 * ( összeg (fürt) (node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{cluster="$cluster"}) / sum by (cluster) (instance:node_num_cpu:sum{cluster="$cluster"}) ) |
| memoryRssByte | container_memory_rss{cluster="$cluster"} |
| memóriaRssSzázalék | 100 * (összeg (példány, fürt) (container_memory_rss{job="cadvisor", cluster="$cluster"}) / sum by (instance, cluster) (machine_memory_bytes{job="cadvisor", cluster="$cluster"})) |
| memóriaRssKioszthatóSzázalék | 100 * (összeg a (csomópont, fürt) szerint (container_memory_rss{cluster="$cluster"}) / összeg a (csomópont, fürt) szerint (node_memory_MemTotal_bytes{cluster="$cluster"})) |
| memória-aktívkészlet-byteok | konténer_memória_munkakészlet_bájt{cluster="$cluster"} |
| memória-munkakészlet százalék | 100 * (összeg (csomópont, fürt) (container_memory_working_set_bytes{cluster="$cluster"}) / összeg (csomópont, fürt) (node_memory_MemTotal_bytes{cluster="$cluster"})) |
| csomópontok száma | count(kube_node_status_condition{condition="Ready", status="true", cluster="$cluster"}) |
| lemezháznyegkihasználtság | 100 * (node_filesystem_size_bytes{cluster="$cluster"} – node_filesystem_free_bytes{cluster="$cluster"}) / node_filesystem_size_bytes{cluster="$cluster"} |
| podCount | count(count by (pod, namespace, cluster) (kube_pod_info{cluster="$cluster"})) |
| befejezett munka szám | count(kube_job_status_succeeded{status="true", cluster="$cluster"} és time() – kube_job_status_start_time > 6 * 3600) |
| újraindulóKonténerSzám | sum by(container, namespace, cluster) (rate(kube_pod_container_status_restarts_total{cluster="$cluster"}[5m])) |
| oomKilledContainerCount (hirtelen leállított konténerek száma) | sum by(container, névtér, klaszter) (kube_pod_container_status_terminated_reason{reason="OOMKilled", klaszter="$cluster"}) |
| podReadyPercentage | 100 * (sum(kube_pod_status_phase{phase="Running", cluster="$cluster"}) szerint (névtér, fürt) / sum(kube_pod_status_phase{phase!="Succeeded", cluster="$cluster"}) szerint (névtér, fürt)) |
Következő lépések
- Az Azure Monitor különböző riasztási szabálytípusairól olvashat.
- További információ a Szabálycsoportok riasztásáról a Prometheushoz készült Azure Monitor felügyelt szolgáltatásban.