Alkalmazások és adatbázisok teljesítményhangolása az Azure SQL Database-ben
A következőre vonatkozik:![]() Azure SQL Database
Azure SQL Database
Miután azonosított egy teljesítményproblémát, amelyet az Azure SQL Database-zel kapcsolatban tapasztal, ez a cikk a következő segítségére van:
- Hangolja az alkalmazást, és alkalmazzon néhány ajánlott eljárást, amelyek javíthatják a teljesítményt.
- Az adatbázis finomhangolása az indexek és lekérdezések módosításával, hogy hatékonyabban működjön az adatokkal.
Ez a cikk feltételezi, hogy már dolgozott az Azure SQL Database adatbázis-tanácsadói javaslatain és az automatikus finomhangolási javaslatokon, ha vannak ilyenek. Azt is feltételezi, hogy áttekintette a figyelés és hangolás, a teljesítmény monitorozása a Lekérdezéstár használatával, valamint a teljesítményproblémák elhárításával kapcsolatos kapcsolódó cikkek áttekintését. Ez a cikk azt is feltételezi, hogy nincs a processzorerőforrás-kihasználtsággal kapcsolatos teljesítményproblémája, amely megoldható a számítási méret vagy a szolgáltatási szint növelésével, hogy több erőforrást biztosítson az adatbázisnak.
Feljegyzés
A felügyelt Azure SQL-példányhoz hasonló útmutatást az alkalmazások és adatbázisok finomhangolása a felügyelt Azure SQL-példány teljesítményéhez című témakörben talál.
Az alkalmazás finomhangolása
A hagyományos helyszíni SQL Serverben a kezdeti kapacitástervezés folyamatát gyakran elkülönítik az alkalmazás éles környezetben való futtatásától. Először hardver- és terméklicenceket vásárolnak, majd a teljesítmény finomhangolását. Az Azure SQL használatakor érdemes egy alkalmazás futtatásának és finomhangolásának folyamatát összekapcsolni. Az igény szerinti kapacitásért való fizetés modelljével úgy hangolhatja az alkalmazást, hogy a jelenleg szükséges minimális erőforrásokat használja, ahelyett, hogy a hardveren túlterjedne egy alkalmazás jövőbeli növekedési tervei alapján, amelyek gyakran helytelenek.
Egyes ügyfelek dönthetnek úgy, hogy nem hangolnak egy alkalmazást, és inkább a hardvererőforrások túlkiépítését választják. Ez a megközelítés akkor lehet jó ötlet, ha egy fontos alkalmazást nem szeretne módosítani egy forgalmas időszakban. Az alkalmazások finomhangolása azonban minimalizálhatja az erőforrásigényeket és csökkentheti a havi számlákat.
Az Azure SQL Database alkalmazástervezésének ajánlott eljárásai és antipatternjei
Bár az Azure SQL Database szolgáltatási szintjei az alkalmazások teljesítménystabilitásának és kiszámíthatóságának javítására lettek kialakítva, néhány ajánlott eljárás segíthet az alkalmazás finomhangolásában, hogy jobban kihasználhassa az erőforrásokat számítási méretben. Bár számos alkalmazás jelentős teljesítménynövekedést ér el egyszerűen egy magasabb számítási méretre vagy szolgáltatási szintre való váltással, egyes alkalmazásoknak további hangolásra van szükségük a magasabb szolgáltatási szint előnyeinek eléréséhez. A nagyobb teljesítmény érdekében fontolja meg az ilyen jellemzőkkel rendelkező alkalmazások további alkalmazáshangolását:
A "csevegő" viselkedés miatt lassú teljesítménnyel rendelkező alkalmazások
A csevegőalkalmazások túlzott adatelérési műveleteket végeznek, amelyek érzékenyek a hálózati késésre. Előfordulhat, hogy módosítania kell az ilyen típusú alkalmazásokat az adatbázishoz való adathozzáférési műveletek számának csökkentése érdekében. Például javíthatja az alkalmazások teljesítményét olyan technikák használatával, mint az alkalmi lekérdezések kötegelése vagy a lekérdezések tárolt eljárásokba való áthelyezése. További információ: Batch-lekérdezések.
Olyan intenzív számítási feladattal rendelkező adatbázisok, amelyeket egy teljes gép nem támogat
A legmagasabb prémium szintű számítási méret erőforrásait meghaladó adatbázisok kihasználhatják a számítási feladatok horizontális felskálázását. További információ: Adatbázisközi horizontális skálázás és funkcionális particionálás.
Az optimálisnál rosszabb lekérdezéseket tartalmazó alkalmazások
A rosszul hangolt lekérdezésekkel rendelkező alkalmazások nem biztos, hogy kihasználják a nagyobb számítási méretet. Ide tartoznak a WHERE záradékot nem tartalmazó, hiányzó indexekkel vagy elavult statisztikával rendelkező lekérdezések. Ezek az alkalmazások kihasználják a szabványos lekérdezési teljesítményhangolási technikákat. További információ: Hiányzó indexek és lekérdezéshangolás és -tippelés.
Az optimálisnál rosszabb adatelérési kialakítású alkalmazások
Előfordulhat, hogy az adathozzáférési egyidejűséggel kapcsolatos eredendő problémákkal (például holtpont) rendelkező alkalmazások nem élvezhetik a nagyobb számítási méret előnyeit. Fontolja meg az adatbázissal kapcsolatos adatátjárások csökkentését az adatok ügyféloldali gyorsítótárazásával az Azure Caching szolgáltatással vagy egy másik gyorsítótárazási technológiával. Lásd az alkalmazásréteg gyorsítótárazását.
Ha meg szeretné akadályozni, hogy holtpontok ismétlődjenek az Azure SQL Database-ben, olvassa el az Elemzés és a holtpontok megelőzése az Azure SQL Database-ben című témakört.
Az adatbázis finomhangolása
Ebben a szakaszban bemutatunk néhány technikát, amelyekkel az adatbázist finomhangolhatja, hogy a lehető legjobb teljesítményt nyújtsa az alkalmazás számára, és a lehető legkisebb számítási méretben futtassa. Ezen technikák némelyike megfelel a hagyományos SQL Server hangolási ajánlott eljárásainak, mások azonban az Azure SQL Database-hez tartoznak. Bizonyos esetekben megvizsgálhatja az adatbázisok felhasznált erőforrásait, hogy megtalálja azokat a területeket, ahol tovább finomíthatja és kibővítheti a hagyományos SQL Server-technikákat az Azure SQL Database-ben való működésre.
Hiányzó indexek azonosítása és hozzáadása
Az OLTP-adatbázis teljesítményével kapcsolatos gyakori probléma a fizikai adatbázis kialakításához kapcsolódik. Az adatbázissémákat gyakran nagy méretekben (betöltve vagy adatmennyiségben) végzett tesztelés nélkül tervezik és szállítják. Sajnos a lekérdezési terv teljesítménye kis méretekben elfogadható lehet, de az éles szintű adatmennyiségek alatt jelentősen csökken. A probléma leggyakoribb forrása az, hogy nincs megfelelő index, amely megfelel a szűrőknek vagy a lekérdezés egyéb korlátozásainak. A hiányzó indexek gyakran táblavizsgálatként nyilvánulnak meg, amikor egy indexkeresés elegendő lehet.
Ebben a példában a kiválasztott lekérdezési terv akkor használ vizsgálatot, ha egy keresés elegendő:
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
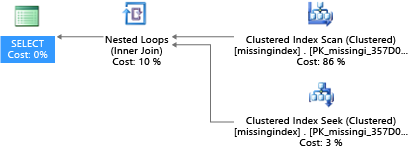
Az Azure SQL Database segíthet megtalálni és kijavítani a gyakori hiányzó indexfeltételeket. Az Azure SQL Database-be beépített DMV-k olyan lekérdezés-fordításokat vizsgálnak, amelyekben az index jelentősen csökkentené a lekérdezések futtatásának becsült költségét. A lekérdezés végrehajtása során az adatbázismotor nyomon követi az egyes lekérdezési tervek végrehajtásának gyakoriságát, és nyomon követi a végrehajtó lekérdezési terv és az indexet tartalmazó elképzelt terv közötti becsült szakadékot. Ezekkel a DMV-kkel gyorsan kitalálhatja, hogy a fizikai adatbázis kialakításának mely változásai javíthatják az adatbázis és annak tényleges számítási feladatainak általános számítási költségeit.
Ezzel a lekérdezésrel kiértékelheti a lehetséges hiányzó indexeket:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
Ebben a példában a lekérdezés a következő javaslatot eredményezte:
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
A létrehozása után ugyanez a Standard kiadás LECT utasítás kiválaszt egy másik tervet, amely kereséssel végzi a keresést a vizsgálat helyett, majd hatékonyabban hajtja végre a tervet:
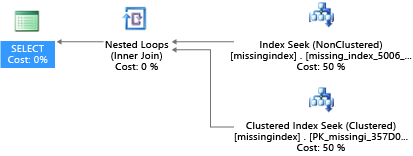
A legfontosabb megállapítás az, hogy egy megosztott, árucikk-rendszer I/O-kapacitása korlátozottabb, mint egy dedikált kiszolgálógépé. A szükségtelen I/O minimálisra csökkenthető, hogy a rendszer maximálisan kihasználhassa a szolgáltatásszintek egyes számítási méretének erőforrásait. A megfelelő fizikai adatbázis-kialakítási lehetőségek jelentősen javíthatják az egyes lekérdezések késését, javíthatják a skálázási egységenként kezelt egyidejű kérések átviteli sebességét, és minimalizálhatják a lekérdezés teljesítéséhez szükséges költségeket.
További információ az indexek hiányzó indexkérelmek használatával történő finomhangolásáról: Nemclustered indexek hangolása hiányzó indexjavaslatokkal.
Lekérdezés finomhangolása és tippelése
Az Azure SQL Database lekérdezésoptimalizálója hasonló a hagyományos SQL Server-lekérdezésoptimalizálóhoz. A lekérdezések finomhangolásához és a lekérdezésoptimalizáló érvelési modell korlátozásainak megértéséhez ajánlott eljárások többsége az Azure SQL Database-re is vonatkozik. Ha az Azure SQL Database-ben hangolja a lekérdezéseket, az összesítő erőforrásigény csökkentésének további előnye lehet. Előfordulhat, hogy az alkalmazás alacsonyabb költséggel futtatható, mint egy nemtuned egyenértékű, mert alacsonyabb számítási méretben is futtatható.
Az SQL Serverben gyakori és az Azure SQL Database-re is érvényes példa, hogy a lekérdezésoptimalizáló hogyan "szippantja" a paramétereket. A fordítás során a lekérdezésoptimalizáló kiértékeli egy paraméter aktuális értékét annak megállapításához, hogy képes-e optimálisabb lekérdezési tervet létrehozni. Bár ez a stratégia gyakran olyan lekérdezési tervhez vezethet, amely lényegesen gyorsabb, mint egy ismert paraméterértékek nélkül összeállított terv, jelenleg tökéletlenül működik mind az Azure SQL Database-ben. (Az SQL Server 2022 névvel ellátott új Intelligens lekérdezési teljesítmény funkcióA paraméterérzékenység-terv optimalizálása azt a forgatókönyvet kezeli, amikor egy paraméteres lekérdezés egyetlen gyorsítótárazott terve nem optimális az összes lehetséges bejövő paraméterértékhez. A paraméter bizalmassági tervének optimalizálása jelenleg nem érhető el az Azure SQL Database-ben.)
Az adatbázismotor támogatja a lekérdezési tippeket (direktívákat ), hogy szándékosan definiálhassa a szándékot, és felülbírálhassa a paraméterszenvedés alapértelmezett viselkedését. Dönthet úgy, hogy tippeket használ, ha az alapértelmezett viselkedés nem tökéletes egy adott számítási feladathoz.
A következő példa bemutatja, hogy a lekérdezésfeldolgozó hogyan hozhat létre olyan tervet, amely a teljesítmény és az erőforrás-követelmények szempontjából is optimális. Ez a példa azt is mutatja, hogy ha lekérdezési tippet használ, csökkentheti a lekérdezések futási idejét és az adatbázis erőforrás-követelményeit:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
A beállítási kód ferde (vagy szabálytalanul elosztott) adatokat hoz létre a t1 táblában. Az optimális lekérdezési terv attól függően változik, hogy melyik paraméter van kiválasztva. Sajnos a terv gyorsítótárazási viselkedése nem mindig felel meg újra a lekérdezésnek a leggyakoribb paraméterérték alapján. Így előfordulhat, hogy egy optimálisnál rosszabb terv gyorsítótárazva van, és számos értékhez használható, még akkor is, ha egy másik terv átlagosan jobb tervválasztást biztosít. Ezután a lekérdezési terv két azonos tárolt eljárást hoz létre, azzal a kivételrel, hogy egy speciális lekérdezési tippet használ.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Javasoljuk, hogy várjon legalább 10 percet a példa 2. részének megkezdése előtt, hogy az eredmények különbözhessenek az eredményben szereplő telemetriai adatoktól.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
A példa minden része 1000-szer kísérel meg paraméteres beszúrási utasítást futtatni (hogy elegendő terhelést generáljon a tesztadatkészletként való használathoz). A tárolt eljárások végrehajtásakor a lekérdezésfeldolgozó megvizsgálja az eljárásnak az első fordítása során átadott paraméterértéket (a "szippantás" paraméter). A processzor gyorsítótárazza az eredményül kapott tervet, és későbbi meghívásokhoz használja, még akkor is, ha a paraméter értéke eltér. Előfordulhat, hogy az optimális terv nem minden esetben használható. Előfordulhat, hogy az optimalizálónak olyan tervet kell választania, amely jobb az átlagos esethez, mint a lekérdezés első fordításakor használt konkrét esethez képest. Ebben a példában a kezdeti terv létrehoz egy "vizsgálat" tervet, amely beolvassa az összes sort, hogy megtalálja a paraméternek megfelelő értékeket:

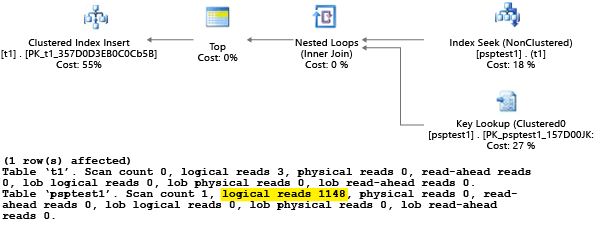
Mivel az eljárást az érték 1használatával hajtottuk végre, az eredményül kapott terv optimális volt az értékhez 1 , de a táblázat összes többi értékéhez képest nem volt optimális. Az eredmény valószínűleg nem az, amit szeretne, ha véletlenszerűen választaná ki az egyes terveket, mert a terv lassabban teljesít, és több erőforrást használ.
Ha a tesztet a beállított értékre SET STATISTICS IO ONállítja, az ebben a példában szereplő logikai vizsgálat a színfalak mögött történik. Láthatja, hogy a terv 1148 olvasást végez (ami nem hatékony, ha az átlagos eset csak egy sort ad vissza):

A példa második része egy lekérdezési tipp segítségével jelzi az optimalizálónak, hogy használjon egy adott értéket a fordítási folyamat során. Ebben az esetben arra kényszeríti a lekérdezésfeldolgozót, hogy hagyja figyelmen kívül a paraméterként átadott értéket, és ehelyett feltételezze UNKNOWN. Ez egy olyan értékre vonatkozik, amely a táblázatban az átlagos gyakorisággal rendelkezik (figyelmen kívül hagyva a ferdeséget). Az eredményül kapott terv egy olyan keresésalapú terv, amely gyorsabb, és átlagosan kevesebb erőforrást használ, mint a jelen példa 1. részében szereplő terv:
A hatást az Azure SQL Database-hez tartozó sys.resource_stats rendszernézetben láthatja. A teszt végrehajtásának időpontjától és a tábla feltöltésének időpontjától kezdve késés tapasztalható. Ebben a példában az 1. rész a 22:25:00 időablakban, a 2. rész pedig 22:35:00-kor lesz végrehajtva. A korábbi időablak több erőforrást használt ebben az időablakban, mint a későbbiben (a terv hatékonyságának javítása miatt).
SELECT TOP 1000 *
FROM sys.resource_stats
WHERE database_name = 'resource1'
ORDER BY start_time DESC

Feljegyzés
Bár a jelen példában szereplő kötet szándékosan kicsi, a nem optimális paraméterek hatása jelentős lehet, különösen a nagyobb adatbázisokra. A különbség szélsőséges esetekben másodpercek között lehet a gyors esetek és a lassú esetek órák között.
Megvizsgálhatja sys.resource_stats , hogy egy teszt erőforrása több vagy kevesebb erőforrást használ-e, mint egy másik teszt. Ha összehasonlítja az adatokat, különítse el a tesztek időzítését, hogy ne legyenek ugyanabban az 5 perces ablakban a sys.resource_stats nézetben. A gyakorlat célja a felhasznált erőforrások teljes mennyiségének minimalizálása, és nem a csúcserőforrások minimalizálása. A kódrészlet késésre való optimalizálása általában csökkenti az erőforrás-felhasználást is. Győződjön meg arról, hogy az alkalmazáson végzett módosításokra szükség van, és hogy a módosítások nem befolyásolják negatívan az ügyfélélményt olyan felhasználók számára, akik esetleg lekérdezési tippeket használnak az alkalmazásban.
Ha egy számítási feladat ismétlődő lekérdezésekkel rendelkezik, gyakran érdemes rögzíteni és ellenőrizni a tervválasztások optimálisságát, mert az az adatbázis üzemeltetéséhez szükséges minimális erőforrás-méretegységet vezérli. Az ellenőrzés után időnként újra meg kell fontolnia a terveket, hogy meggyőződjön arról, hogy nem csökkentek. További információ a lekérdezési tippekről (Transact-SQL).
Ajánlott eljárások az Azure SQL Database nagyon nagy adatbázisarchitektúráihoz
Az Azure SQL Database-ben az önálló adatbázisok rugalmas skálázási szolgáltatási szintjének kiadása előtt az ügyfelek kapacitáskorlátokba ütközhetnek az egyes adatbázisokra vonatkozóan. Míg a rugalmas rugalmas készletek (előzetes verzió) jelentősen magasabb tárolási korlátokat kínálnak, a rugalmas készleteket és a más szolgáltatási szinteken lévő készleteket továbbra is korlátozhatják a nem rugalmas skálázású szolgáltatási szintek tárolási kapacitáskorlátjai.
Az alábbi két szakasz két lehetőséget tárgyal az Azure SQL Database nagy méretű adatbázisaival kapcsolatos problémák megoldására, ha nem tudja használni a rugalmas skálázású szolgáltatási szintet.
Feljegyzés
A rugalmas rugalmas készletek előzetes verzióban érhetők el az Azure SQL Database-hez. A rugalmas készletek nem érhetők el a felügyelt Azure SQL-példányokhoz, a helyszíni SQL Server-példányokhoz, az Azure-beli virtuális gépeken futó SQL Serverhez vagy az Azure Synapse Analyticshez.
Adatbázisközi horizontális skálázás
Mivel az Azure SQL Database hagyományos hardveren fut, az egyes adatbázisok kapacitási korlátai alacsonyabbak, mint egy hagyományos helyszíni SQL Server-telepítés esetében. Egyes ügyfelek horizontális skálázási technikákkal terjesztik az adatbázis-műveleteket több adatbázisra, ha a műveletek nem férnek el az Azure SQL Database-ben lévő egyes adatbázisok korlátain belül. Az Azure SQL Database-ben horizontális skálázási technikákat használó ügyfelek többsége egyetlen dimenzióban osztotta fel az adatait több adatbázis között. Ehhez a megközelítéshez tisztában kell lenni azzal, hogy az OLTP-alkalmazások gyakran olyan tranzakciókat hajtanak végre, amelyek csak egy sorra vagy a séma egy kis sorcsoportjára vonatkoznak.
Feljegyzés
Az Azure SQL Database mostantól egy kódtárat biztosít a horizontális skálázáshoz. További információ: Elastic Database ügyfélkódtár áttekintése.
Ha például egy adatbázis ügyfélnévvel, megrendeléssel és rendelési adatokkal rendelkezik (például az AdventureWorks adatbázisban), ezeket az adatokat több adatbázisra oszthatja úgy, hogy csoportosítja az ügyfelet a kapcsolódó rendelési és rendelési adatokkal. Garantálhatja, hogy az ügyfél adatai egy adott adatbázisban maradnak. Az alkalmazás különböző ügyfeleket osztana szét az adatbázisok között, így hatékonyan terjesztené a terhelést több adatbázis között. A horizontális skálázással az ügyfelek nem csak a maximális adatbázisméretkorlátot kerülhetik el, hanem az Azure SQL Database a különböző számítási méretek korlátainál jelentősen nagyobb számítási feladatokat is feldolgozhat, feltéve, hogy az egyes adatbázisok beleférnek a szolgáltatási szint korlátaiba.
Bár az adatbázis-horizontális skálázás nem csökkenti egy megoldás összesített erőforrás-kapacitását, rendkívül hatékony a nagyon nagy, több adatbázisra kiterjedő megoldások támogatásában. Minden adatbázis más számítási méretben futtatható, így nagyon nagy, "hatékony" adatbázisokat támogat magas erőforrásigényekkel.
Funkcionális particionálás
A felhasználók gyakran kombinálják az egyes adatbázisok számos függvényét. Ha például egy alkalmazás rendelkezik egy áruház készletének kezelésére szolgáló logikával, akkor előfordulhat, hogy az adatbázis logikája a leltárhoz, a beszerzési rendelések nyomon követéséhez, a tárolt eljárásokhoz és a hónap végi jelentéskészítést kezelő indexelt vagy materializált nézetekhez van társítva. Ez a technika megkönnyíti az adatbázis felügyeletét olyan műveletekhez, mint a biztonsági mentés, de a hardvert is meg kell méreteznie az alkalmazás összes funkciójának maximális terhelésének kezeléséhez.
Ha kibővített architektúrát használ az Azure SQL Database-ben, érdemes az alkalmazás különböző funkcióit különböző adatbázisokra osztani. Ha ezt a technikát használja, az egyes alkalmazások egymástól függetlenül skálázhatók. Ahogy egy alkalmazás forgalmasabbá válik (és az adatbázis terhelése nő), a rendszergazda független számítási méreteket választhat az alkalmazás minden egyes függvényéhez. Az architektúra korlátja szerint az alkalmazások nagyobbak lehetnek, mint egy egyszerű gép, mert a terhelés több gép között oszlik el.
Kötegelt lekérdezések
Az adatokhoz nagy mennyiségű, gyakori, alkalmi lekérdezéssel hozzáférő alkalmazások esetében a válaszidő jelentős részét az alkalmazásszint és az adatbázisszint közötti hálózati kommunikációra fordítja. Még akkor is, ha az alkalmazás és az adatbázis is ugyanabban az adatközpontban van, a kettő közötti hálózati késést nagy számú adatelérési művelet megnagyosítja. Az adatelérési műveletek hálózati körútjának csökkentése érdekében fontolja meg az alkalmi lekérdezések kötegelésére vagy tárolt eljárásokként való fordítására szolgáló lehetőséget. Ha az alkalmi lekérdezéseket kötegeli, több lekérdezést is elküldhet egy nagy kötegként egyetlen út során az adatbázisba. Ha alkalmi lekérdezéseket állít össze egy tárolt eljárásban, ugyanazt az eredményt érheti el, mintha kötegelné őket. A tárolt eljárásokkal növelheti a lekérdezéstervek adatbázisbeli gyorsítótárazásának esélyét is, így ismét használhatja a tárolt eljárást.
Egyes alkalmazások írásigényesek. Néha csökkentheti az adatbázisok teljes I/O-terhelését, ha figyelembe veszi, hogyan kötegelheti össze az írásokat. Ez gyakran olyan egyszerű, mintha explicit tranzakciókat használunk a tárolt eljárásokban és alkalmi kötegekben végzett automatikus kiküldéses tranzakciók helyett. Az azure-beli adatbázis-alkalmazások kötegelési technikái a különböző technikák kiértékelésével kapcsolatosak. Kísérletezzen saját számítási feladatával, hogy megtalálja a megfelelő kötegelési modellt. Mindenképpen tisztában kell lennie azzal, hogy egy modell némileg eltérő tranzakciós konzisztenciagaranciával rendelkezhet. Az erőforrás-használatot minimalizáló megfelelő számítási feladat megkereséséhez meg kell találni a konzisztencia és a teljesítmény megfelelő kombinációját.
Alkalmazásszintű gyorsítótárazás
Egyes adatbázis-alkalmazások írásvédett számítási feladatokkal rendelkeznek. A gyorsítótárazási rétegek csökkenthetik az adatbázis terhelését, és az Azure SQL Database használatával csökkenthetik az adatbázisok támogatásához szükséges számítási méretet. Az Azure Cache for Redis esetében, ha olvasási nehéz számítási feladattal rendelkezik, az adatokat egyszer (vagy alkalmazásszintű gépenként, a konfigurálás módjától függően) egyszer is elolvashatja, majd ezeket az adatokat az adatbázison kívül tárolhatja. Ez az adatbázis-terhelés (CPU és olvasási IO) csökkentésének módja, de hatással van a tranzakciós konzisztenciára, mert a gyorsítótárból beolvasott adatok esetleg nem szinkronizálódnak az adatbázisban lévő adatokkal. Bár sok alkalmazásban elfogadható bizonyos fokú inkonzisztencia, ez nem minden számítási feladatra igaz. Az alkalmazásszintű gyorsítótárazási stratégia implementálása előtt teljes mértékben tisztában kell lennie az alkalmazáskövetelményekkel.
Konfigurációs és tervezési tippek
Ha Az Azure SQL Database-t használja, egy nyílt forráskódú T-SQL-szkriptet futtathat az azure SQL Database adatbázis-konfigurációjának és kialakításának javítására. A szkript igény szerint elemzi az adatbázist, és tippeket ad az adatbázis teljesítményének és állapotának javításához. Egyes tippek ajánlott eljárásokon alapuló konfigurációs és üzemeltetési módosításokat javasolnak, míg más tippek a számítási feladatokhoz megfelelő kialakítási módosításokat javasolnak, például a speciális adatbázismotor-funkciók engedélyezését.
A szkripttel kapcsolatos további információkért és az első lépésekért látogasson el az Azure SQL Tippek wikilapjára.
Kapcsolódó tartalom
- Tudnivalók a DTU-alapú vásárlási modellről
- További információ a virtuális magalapú vásárlási modellről
- Olvassa el , mi az az Azure rugalmas készlete?
- Fedezze fel , hogy mikor érdemes rugalmas készletet figyelembe venni
- További információ a teljesítmény dinamikus felügyeleti nézetek használatával történő monitorozásáról
- Ismerje meg, hogyan diagnosztizálhatja és háríthatja el a magas processzorhasználatot az Azure SQL Database-ben
- Nem klaszterezett indexek hangolása hiányzó indexjavaslatokkal
- Videó: Ajánlott adatbetöltési eljárások az Azure SQL Database-ben
- Az Azure SQL Database monitorozása az Azure Monitor segítségével