Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőkre vonatkozik:![]() Azure SQL Database
Azure SQL Database
- Logikai Azure SQL Database-kiszolgáló
- önálló Azure SQL Database-adatbázis
- felügyelt Azure SQL-példány
Ez a cikk áttekintést nyújt az Azure SQL Database erőforrás-kezeléséről. Információt nyújt arról, hogy mi történik az erőforráskorlátok elérésekor, és ismerteti azokat az erőforrás-szabályozási mechanizmusokat, amelyek a korlátok kényszerítésére szolgálnak.
Az egyes adatbázisok tarifacsomagonkénti erőforráskorlátjaiért tekintse meg az alábbi hivatkozásokat:
- DTU-alapú önálló adatbázis erőforráskorlátai
- virtuális magalapú önálló adatbázis erőforráskorlátainak
A rugalmas készlet erőforráskorlátjaiért tekintse meg a következőt:
Dedikált Azure Synapse Analytics SQL-készletkorlátok esetén tekintse meg a következőt:
Előfizetés virtuális magjainak régiónkénti korlátozásai
2024 márciusától az előfizetések régiónként az alábbi virtuális magkorlátokkal rendelkeznek:
| Előfizetés típusa | Alapértelmezett virtuális magkorlátok |
|---|---|
| Nagyvállalati Szerződés (EA) | 2000. |
| Ingyenes próbaverziók | 10 |
| Microsoft startupok számára | 100 |
| MSDN / MPN / Imagine / AzurePass / Azure for Students | 40 |
| Használatalapú fizetés (PAYG) | 150 |
Vegye figyelembe a következőket:
- Ezek a korlátozások új és meglévő előfizetésekre vonatkoznak.
- A DTU vásárlási modellel kiépített adatbázisok és rugalmas készletek a virtuális mag kvótájával vannak számolva, és fordítva. Minden felhasznált virtuális mag egyenértékű a kiszolgálószintű kvótához felhasznált 100 DTU-val.
- Az alapértelmezett korlátok közé tartoznak a kiépített számítási adatbázisokhoz vagy rugalmas készletekhez konfigurált virtuális magok, valamint a kiszolgáló nélküli adatbázisokhoz konfigurált
maximális virtuális magok . - A Előfizetés-használatok – REST API-hívás lekérésével meghatározhatja az előfizetéséhez tartozó virtuális magok aktuális használatát.
- Ha az alapértelmezettnél magasabb virtuális magkvótát szeretne kérni, küldjön egy új támogatási kérelmet az Azure Portalon. További információ: Kérelemkvóta növelése az Azure SQL Database-hez és a felügyelt SQL-példányhoz.
Logikai kiszolgáló korlátai
| Erőforrás | Korlát |
|---|---|
| Adatbázisok logikai kiszolgálónkénti | 5 000 |
| Logikai kiszolgálók alapértelmezett száma előfizetésenként egy régióban | 250 |
| Logikai kiszolgálók maximális száma előfizetésenként egy régióban | 250 |
| Rugalmas készletek maximális száma logikai kiszolgálónként | A DTU-k vagy virtuális magok száma korlátozott. Ha például minden készlet 1000 DTU, akkor a kiszolgáló 54 készletet támogat. |
Fontos
Ahogy az adatbázisok száma megközelíti a logikai kiszolgálónkénti korlátot, a következők fordulhatnak elő:
- A lekérdezések
masteradatbázison való futtatása késésének növelése. Ide tartoznak az erőforrás-kihasználtsági statisztikák nézetei, például asys.resource_stats. - A felügyeleti műveletek késésének növelése és a portálnézetek renderelése, amelyek magukban foglalják a kiszolgálón lévő adatbázisok számbavételét.
Mi történik az erőforráskorlátok elérésekor?
Számítási PROCESSZOR
Amikor az adatbázis-számítási processzor kihasználtsága magasvá válik, a lekérdezések késése nő, és a lekérdezések akár időtúllépést is okozhatnak. Ilyen feltételek mellett előfordulhat, hogy a szolgáltatás várólistára állítja a lekérdezéseket, és erőforrásokat biztosít a végrehajtáshoz, amint az erőforrások ingyenessé válnak.
Ha magas számítási kihasználtságot észlel, a kockázatcsökkentési lehetőségek a következők:
- Az adatbázis vagy a rugalmas készlet számítási méretének növelése, hogy az adatbázis több számítási erőforrást biztosítson. Lásd: Önálló adatbázis-erőforrások skálázása és Rugalmas készlet erőforrásainak méretezése.
- Lekérdezések optimalizálása az egyes lekérdezések CPU-erőforrás-kihasználtságának csökkentése érdekében. További információ: Lekérdezés finomhangolása/tippelés.
Raktározás
Ha a felhasznált adatterület eléri a maximális adatméretkorlátot az adatbázis szintjén vagy a rugalmas készlet szintjén, az adatméretet növelő beszúrások és frissítések meghiúsulnak, és az ügyfelek hibaüzenetet kapnak. A SELECT és a DELETE utasítások változatlanok maradnak.
A prémium és az üzleti szempontból kritikus szolgáltatási szinteken az ügyfelek hibaüzenetet is kapnak, ha az adatok, tranzakciónaplók és tempdb összesített tárolási felhasználása egyetlen adatbázis vagy rugalmas készlet esetében meghaladja a maximális helyi tárterület-méretet. További információ: Tárhelyszabályozási.
Ha magas tárterület-kihasználtságot észlel, a kockázatcsökkentési lehetőségek a következők:
- Növelje az adatbázis vagy a rugalmas készlet maximális adatméretét, vagy vertikálisan felskálázható egy szolgáltatási célkitűzésre magasabb maximális adatméretkorláttal. Lásd: Önálló adatbázis-erőforrások skálázása és Rugalmas készlet erőforrásainak méretezése.
- Ha az adatbázis rugalmas készletben található, akkor másik lehetőségként az adatbázis áthelyezhető a készleten kívülre, hogy a tárterülete ne legyen megosztva más adatbázisokkal.
- Az adatbázis zsugorítása a nem használt terület visszaszerzéséhez. További információ: Adatbázisok fájlterületének kezelése.
- Rugalmas készletekben az adatbázisok zsugorítása több tárhelyet biztosít a készlet más adatbázisai számára.
- Ellenőrizze, hogy a magas helykihasználtság az állandó verziótár (PVS) méretének megugrása miatt van-e. A PVS minden adatbázis része, és gyorsított adatbázis-helyreállításmegvalósításához használatos. Az aktuális PVS-méret meghatározásához tekintse meg Gyorsított adatbázis-helyreállításcímű témakört. A nagy PVS-méret gyakori oka egy olyan tranzakció, amely hosszú ideig (órákig) nyitva van, megakadályozva a sor régebbi verzióinak törlését a PVS-ben.
- A nagy mennyiségű tárterületet használó prémium és üzleti szempontból kritikus szolgáltatási szinteken lévő adatbázisok és rugalmas készletek esetében előfordulhat, hogy a tárhelyen kívüli hiba akkor is előfordulhat, ha az adatbázisban vagy a rugalmas készletben a felhasznált terület nem éri el a maximális adatméretkorlátot. Ez akkor fordulhat elő, ha
tempdbvagy tranzakciónapló-fájlok nagy mennyiségű tárterületet használnak fel a maximális helyi tárterület-korlát felé. Feladatátvétel az adatbázist vagy a rugalmas készletet, hogy visszaállítsa atempdbkezdeti kisebb méretére, vagy csökkentse tranzakciónaplót a helyi tárolási felhasználás csökkentése érdekében.
Munkamenetek, feldolgozók és kérések
A munkamenetek, a feldolgozók és a kérések a következőképpen vannak definiálva:
- A munkamenet az adatbázismotorhoz csatlakoztatott folyamatot jelöli.
- A kérés egy lekérdezés vagy köteg logikai ábrázolása. A kérést egy munkamenethez csatlakoztatott ügyfél küldi el. Idővel több kérés is kibocsátható ugyanazon a munkameneten.
- A feldolgozói szál, más néven feldolgozó vagy szál az operációs rendszer szálának logikai ábrázolása. A kérések több feldolgozóval is rendelkezhetnek, ha párhuzamos lekérdezés-végrehajtási tervvel hajtják végre, vagy egyetlen feldolgozóval, ha soros (egyszálas) végrehajtási tervvel hajtják végre. A feldolgozóknak a kéréseken kívül is támogatniuk kell a tevékenységeket: például egy feldolgozónak fel kell dolgoznia egy bejelentkezési kérést, amikor egy munkamenet csatlakozik.
Ezekről a fogalmakról további információt a szál- és feladatarchitektúra útmutatójában talál.
A feldolgozók maximális számát a szolgáltatási szint és a számítási méret határozza meg. Az új kéréseket a rendszer elutasítja a munkamenet- vagy feldolgozói korlátok elérésekor, és az ügyfelek hibaüzenetet kapnak. Bár a kapcsolatok számát az alkalmazás szabályozhatja, az egyidejű feldolgozók számát gyakran nehezebb megbecsülni és szabályozni. Ez különösen igaz a csúcsterhelési időszakokban, amikor az adatbázis erőforráskorlátai elérik, és a feldolgozók halmozódnak fel a hosszabb ideig futó lekérdezések, a nagy blokkoló láncok vagy a lekérdezések túlzott párhuzamossága miatt.
Jegyzet
Az Azure SQL Database kezdeti ajánlata csak egyszálas lekérdezéseket támogatott. Abban az időben a kérelmek száma mindig megegyezett a munkavállalók számával. Az Azure SQL Database 10928-ban megjelenő hibaüzenete csak a visszamenőleges kompatibilitás érdekében tartalmazza a The request limit for the database is *N* and has been reached szövegét. Az elért korlát valójában a munkavállalók száma.
Ha a maximális párhuzamossági fok (MAXDOP) értéke nulla vagy egynél nagyobb, a feldolgozók száma sokkal magasabb lehet a kérelmek számánál, és a korlát sokkal hamarabb érhető el, mint amikor a MAXDOP értéke egy.
- További információ az Erőforrás-szabályozási hibák10928-ás hibájáról.
- További információ az 10928-10936-os és 10936-os.
A munkavégzők vagy munkamenetek korlátainak megközelítését vagy túllépését az alábbiakkal csökkentheti:
- Az adatbázis vagy a rugalmas készlet szolgáltatási szintjének vagy számítási méretének növelése. Lásd: Önálló adatbázis-erőforrások skálázása és Rugalmas készlet erőforrásainak méretezése.
- Lekérdezések optimalizálása az erőforrás-kihasználtság csökkentése érdekében, ha a megnövekedett feldolgozók oka a számítási erőforrásokért való versengés. További információ: Lekérdezés finomhangolása/tippelés.
- A lekérdezési számítási feladat optimalizálása az előfordulások számának és a lekérdezésblokkolás időtartamának csökkentése érdekében. További információ: A blokkolási problémákismertetése és megoldása.
- Szükség esetén csökkentse a MAXDOP beállítást.
Az Azure SQL Database munkavégző és munkamenetkorlátainak megkeresése szolgáltatási szint és számítási méret szerint:
- virtuálismag-vásárlási modellt használó önálló adatbázisok erőforráskorlátai
- rugalmas készletek erőforráskorlátai a virtuális mag vásárlási modellel
- DTU vásárlási modellt használó önálló adatbázisok erőforráskorlátai
- rugalmas készletek erőforráskorlátai a DTU vásárlási modellel
További információ a munkamenet- vagy feldolgozókorlátok bizonyos hibáinak elhárításáról Erőforrás-szabályozási hibák.
Külső kapcsolatok
A külső végpontokhoz sp_invoke_external_rest_endpoint keresztül létesített egyidejű kapcsolatok száma 10% feldolgozószálra van leképezve, legfeljebb 150 feldolgozó kemény korlátjával.
Emlékezet
Más erőforrásoktól (PROCESSZOR, feldolgozók, tárterület) eltérően a memóriakorlát elérése nem befolyásolja negatívan a lekérdezés teljesítményét, és nem okoz hibákat és hibákat. Ahogy az memóriakezelési architektúra útmutatójában részletesen ismertetjük, az adatbázismotor gyakran az összes rendelkezésre álló memóriát használja kialakítás szerint. A memória elsősorban az adatok gyorsítótárazására szolgál, így elkerülhető a lassabb tárterület-hozzáférés. Így a nagyobb memóriakihasználtság általában a memória gyorsabb olvasása miatt javítja a lekérdezési teljesítményt, ahelyett, hogy lassabban olvas a tárolóból.
Az adatbázismotor indítása után, amikor a számítási feladat elkezd adatokat olvasni a tárolóból, az adatbázismotor agresszíven gyorsítótárazza az adatokat a memóriában. A kezdeti felfutási időszak után gyakori és várható, hogy a avg_memory_usage_percentavg_instance_memory_percent és oszlopai, valamint az sql_instance_memory_percent Azure Monitor metrika közel 100%lesz, különösen az olyan adatbázisok esetében, amelyek nem tétlenek, és nem férnek el teljesen a memóriában.
Jegyzet
A sql_instance_memory_percent metrika az adatbázismotor teljes memóriahasználatát tükrözi. Ez a metrika akkor sem éri el a 100%, ha nagy intenzitású számítási feladatok futnak. Ennek az az oka, hogy a rendelkezésre álló memória egy kis része az adatgyorsítótártól eltérő kritikus memóriafoglalásokhoz van fenntartva, például szálvermekhez és végrehajtható modulokhoz.
Az adatgyorsítótár mellett az adatbázismotor más összetevői is használnak memóriát. Ha a memóriaigény és az adatgyorsítótár az összes rendelkezésre álló memóriát felhasználta, az adatbázismotor csökkenti az adatgyorsítótár méretét, hogy a memória más összetevők számára is elérhetővé legyen, és dinamikusan növeli az adatgyorsítótárat, amikor más összetevők felszabadítják a memóriát.
Ritkán előfordulhat, hogy egy megfelelően igényes számítási feladat nem megfelelő memóriafeltételt okoz, ami memóriahiányhoz vezethet. Memóriakihasználtsági hibák 0% és 100%közötti memóriakihasználtság bármelyik szintjén előfordulhatnak. A memóriakimaradási hibák nagyobb valószínűséggel fordulnak elő kisebb számítási méretekben, amelyek arányosan kisebb memóriakorlátokkal rendelkeznek, és /vagy olyan számítási feladatok esetén, amelyek több memóriát használnak a lekérdezések feldolgozásához, például sűrű rugalmas készletek.
Ha memóriahiba lépett fel, a kockázatcsökkentési lehetőségek a következők:
- Tekintse át a sys.dm_os_out_of_memory_eventsOOM-feltételének részleteit.
- Az adatbázis vagy a rugalmas készlet szolgáltatási szintjének vagy számítási méretének növelése. Lásd: Önálló adatbázis-erőforrások skálázása és Rugalmas készlet erőforrásainak méretezése.
- Lekérdezések és konfiguráció optimalizálása a memória kihasználtságának csökkentése érdekében. A gyakori megoldásokat az alábbi táblázat ismerteti.
| Megoldás | Leírás |
|---|---|
| A memóriahasználati támogatás méretének csökkentése | A memóriahasználati támogatásokkal kapcsolatos további információkért lásd az Az SQL Server memóriahasználati támogatásainak ismertetése blogbejegyzést. A túlzottan nagy memóriahasználat elkerülése érdekében gyakori megoldás a statisztikák naprakészen tartása. Ez pontosabb becslést eredményez a lekérdezési motor memóriahasználatáról, elkerülve a nagy memóriakihasználtságokat. Alapértelmezés szerint a 140-es vagy újabb kompatibilitási szintet használó adatbázisokban az adatbázismotor automatikusan módosíthatja a memóriakiadás méretét Batch módú memóriavisszajelzésihasználatával. Hasonlóképpen, a 150-es vagy újabb kompatibilitási szintet használó adatbázisokban az adatbázismotor sor módú memóriavisszajelzéstis használ a gyakoribb sormódú lekérdezésekhez. Ez a beépített funkció segít elkerülni a memóriakihasználtság miatti memóriakihasználtságokat. |
| A lekérdezésterv gyorsítótárának méretének csökkentése | Az adatbázismotor gyorsítótárazza a lekérdezési terveket a memóriában, hogy elkerülje a lekérdezéstervek összeállítását minden lekérdezés-végrehajtáshoz. A csak egyszer használt gyorsítótárazási tervek által okozott lekérdezésterv-gyorsítótár-blob elkerülése érdekében ügyeljen a paraméteres lekérdezésekre, és fontolja meg OPTIMIZE_FOR_AD_HOC_WORKLOADS adatbázis-hatókörű konfigurációsengedélyezését. |
| A zárolási memória méretének csökkentése | Az adatbázismotor memóriát használ zárolásokhoz. Ha lehetséges, kerülje a nagy méretű tranzakciókat, amelyek nagy számú zárolást szerezhetnek be, és magas zárolási memóriahasználatot okozhatnak. |
Erőforrás-felhasználás felhasználói számítási feladatok és belső folyamatok szerint
Az Azure SQL Database olyan alapvető szolgáltatásfunkciók implementálásához igényel számítási erőforrásokat, mint a magas rendelkezésre állás és vészhelyreállítás, az adatbázis biztonsági mentése és visszaállítása, a monitorozás, a lekérdezéstár, az automatikus hangolás stb. A rendszer a belső folyamatok teljes erőforrásainak egy korlátozott részét erőforrás-szabályozási mechanizmusokkal teszi elérhetővé, így a többi erőforrás elérhetővé válik a felhasználói számítási feladatok számára. Amikor a belső folyamatok nem használnak számítási erőforrásokat, a rendszer elérhetővé teszi őket a felhasználói számítási feladatok számára.
A felhasználói számítási feladatok és a belső folyamatok teljes processzor- és memóriahasználatát a rendszer a sys.dm_db_resource_stats és sys.resource_stats nézetekben, avg_instance_cpu_percent és avg_instance_memory_percent oszlopokban jelenti. Ezeket az adatokat az Azure Monitor-metrikák sql_instance_cpu_percent és sql_instance_memory_percent is jelenti, önálló adatbázisok és rugalmas készletek a készlet szintjén.
Jegyzet
Az Azure Monitor-metrikák sql_instance_cpu_percent és sql_instance_memory_percent 2023 júliusa óta érhetők el. Ezek teljes mértékben egyenértékűek a korábban elérhető sqlserver_process_core_percent és sqlserver_process_memory_percent metrikákkal. Az utóbbi két metrika továbbra is elérhető marad, de a jövőben el lesz távolítva. Az adatbázis-figyelés megszakításának elkerülése érdekében ne használja a régebbi metrikákat.
Ezek a metrikák nem érhetők el az alapszintű, S1 és S2 szolgáltatási célkitűzéseket használó adatbázisokhoz. Ugyanezek az adatok a következő dinamikus felügyeleti nézetekben érhetők el.
A felhasználói számítási feladatok processzor- és memóriahasználata az egyes adatbázisokban a sys.dm_db_resource_stats és sys.resource_stats nézetekben, avg_cpu_percent és avg_memory_usage_percent oszlopokban történik. Rugalmas készletek esetén a készletszintű erőforrás-felhasználást a rendszer sys.elastic_pool_resource_stats nézetben (korábbi jelentéskészítési forgatókönyvek esetén) és sys.dm_elastic_pool_resource_stats valós idejű monitorozás céljából jelenti. A felhasználói számítási feladatok processzorhasználatát az cpu_percent Azure Monitor metrikáján keresztül is jelenti a rendszer, önálló adatbázisok és rugalmas készletek a készlet szintjén.
A felhasználói számítási feladatok és belső folyamatok legutóbbi erőforrás-felhasználásának részletesebb lebontása a sys.dm_resource_governor_resource_pools_history_ex és sys.dm_resource_governor_workload_groups_history_ex nézetekben történik. Az ezekben a nézetekben hivatkozott erőforráskészletekkel és számítási feladatcsoportokkal kapcsolatos részletekért lásd erőforrás-szabályozási. Ezek a nézetek a felhasználói számítási feladatok, valamint a kapcsolódó erőforráskészletek és számítási feladatok csoportjaiban lévő konkrét belső folyamatok erőforrás-kihasználtságáról nyújtanak jelentést.
Borravaló
A számítási feladatok teljesítményének monitorozása vagy hibaelhárítása során fontos figyelembe venni felhasználói processzorhasználati (avg_cpu_percent, cpu_percent), valamint teljes processzorhasználatot. A teljesítmény jelentősen befolyásolhatja, ha ezen metrikák bármelyik a 70–100% tartományban van.
felhasználói processzorhasználati az egyes szolgáltatási célokban a felhasználói számítási feladatok cpu-korlátja felé mutató százalékos értékként van meghatározva. Hasonlóképpen, teljes processzorhasználat az összes számítási feladat cpu-korlátja felé irányuló százalékos értékként van meghatározva. Mivel a két korlát eltérő, a felhasználó és a teljes processzorhasználat különböző skálákon van mérve, és nem hasonlíthatók össze közvetlenül egymással.
Ha felhasználói processzorhasználat eléri a 100%, az azt jelenti, hogy a felhasználói számítási feladat teljes mértékben használja a kiválasztott szolgáltatási célkitűzésben elérhető processzorkapacitást, még akkor is, ha teljes processzorhasználati 100%alatt marad.
Amikor teljes processzorhasználati eléri a 70–100% tartományt, a felhasználói számítási feladatok átviteli sebességének és a lekérdezések késésének növekedése akkor is látható, ha felhasználói processzorhasználat jelentősen 100%alatt marad. Ez nagyobb valószínűséggel fordul elő, ha kisebb szolgáltatási célkitűzéseket használ a számítási erőforrások mérsékelt lefoglalásával, de viszonylag intenzív felhasználói számítási feladatok, például sűrű rugalmas készletek. Ez kisebb szolgáltatási célkitűzések esetén is előfordulhat, ha a belső folyamatok átmenetileg több erőforrást igényelnek, például az adatbázis új replikája létrehozásakor vagy az adatbázis biztonsági mentésekor.
Hasonlóképpen, ha felhasználói processzorhasználat eléri a 70–100% tartományt, a felhasználói számítási feladatok átviteli sebessége és a lekérdezési késés nő, még akkor is, ha teljes processzorhasználati jóval a korlátja alatt van.
Ha felhasználói processzorhasználat vagy teljes processzorhasználati magas, a kockázatcsökkentési lehetőségek megegyeznek a Számítási processzor szakaszban leírtakkal, és tartalmazzák a szolgáltatás célkitűzésének növelését és/vagy a felhasználói számítási feladatok optimalizálását.
Jegyzet
Még egy teljesen tétlen adatbázison vagy rugalmas készleten is teljes processzorhasználati soha nem nulla a háttéradatbázis-motor tevékenységei miatt. Az adott háttértevékenységtől, a számítási mérettől és a korábbi felhasználói számítási feladatoktól függően széles körben ingadozhat.
Erőforrás-szabályozás
Az erőforráskorlátok érvényre juttatásához az Azure SQL Database olyan erőforrás-szabályozási implementációt használ, amely az SQL Server Resource Governoralapul, amelyet módosítottak és kiterjesztettek a felhőben való futtatásra. Az SQL Database-ben több erőforráskészlet és számítási feladatcsoport, amelyek erőforráskorlátai a készlet és a csoport szintjén is meg vannak adva, kiegyensúlyozott adatbázis-szolgáltatásként. A felhasználói számítási feladatok és a belső számítási feladatok külön erőforráskészletek és számítási feladatok csoportjaiba vannak besorolva. Az elsődleges és olvasható másodlagos replikák felhasználói számítási feladatai, beleértve a georeplikákat is, az SloSharedPool1 erőforráskészletbe és UserPrimaryGroup.DBId[N] számítási feladatok csoportjaiba vannak besorolva, ahol [N] az adatbázis-azonosító értékét jelenti. Emellett több erőforráskészlet és számítási feladatcsoport is létezik a különböző belső számítási feladatokhoz.
Az Azure SQL Database aMellett, hogy a Resource Governor használatával szabályozza az erőforrásokat az adatbázismotoron belül, windowsos feladatobjektumokat is használ a folyamatszintű erőforrás-szabályozáshoz, a Windows File Server Resource Manager (FSRM) a tárkvóta-kezeléshez.
Az Azure SQL Database erőforrás-szabályozása hierarchikus jellegű. A korlátokat felülről lefelé az operációs rendszer szintjén és a tárterület szintjén kényszeríti ki az operációs rendszer erőforrás-szabályozási mechanizmusai és erőforrás-kormányzója, majd az erőforráskészlet szintjén a Resource Governor, majd a számítási feladatcsoport szintjén a Resource Governor használatával. Az aktuális adatbázisra vagy rugalmas készletre vonatkozó erőforrás-szabályozási korlátok sys.dm_user_db_resource_governance nézetben jelennek meg.
Adatok I/O-szabályozása
Az adat-I/O-szabályozás az Azure SQL Database-ben a fizikai I/O olvasásának és írásának az adatbázis adatfájljaira való korlátozására szolgál. Az IOPS-korlátok az egyes szolgáltatási szintekre vannak beállítva a "zajos szomszéd" hatás minimalizálása érdekében, az erőforrás-kiosztás méltányosságának biztosítása a több-bérlős szolgáltatásokban, valamint a mögöttes hardver és tároló képességeinek megőrzése érdekében.
Az önálló adatbázisok esetében a számítási feladatok csoportkorlátjai az összes tároló I/O-ra vonatkoznak az adatbázison. Rugalmas készletek esetén a számítási feladatok csoportkorlátjai a készlet minden adatbázisára vonatkoznak. Emellett az erőforráskészlet korlátja a rugalmas készlet halmozott I/O-jára is vonatkozik. Az tempdbaz I/O-ra a számítási feladatok csoportkorlátjai vonatkoznak, kivéve az alapszintű, a standard és az általános célú szolgáltatási szintet, ahol magasabb tempdb I/O-korlátok érvényesek. Előfordulhat, hogy az erőforráskészlet korlátait a számítási feladatok nem érik el egy adatbázison (akár önállóan, akár készletben), mivel a számítási feladatcsoport korlátai alacsonyabbak az erőforráskészlet korlátainál, és hamarabb korlátozzák az IOPS/átviteli sebességet. A készletkorlátokat azonban az egyesített számítási feladatok elérhetik több, ugyanabban a készletben lévő adatbázisra vonatkozóan.
Ha például egy lekérdezés 1000 IOPS-t hoz létre I/O-erőforrás-szabályozás nélkül, de a számítási feladatcsoport maximális IOPS-korlátja 900 IOPS-ra van állítva, a lekérdezés nem tud 900-nál több IOPS-t létrehozni. Ha azonban az erőforráskészlet maximális IOPS-korlátja 1500 IOPS, és az erőforráskészlethez társított összes számítási feladatcsoport teljes I/O-értéke meghaladja az 1500 IOPS-t, akkor ugyanannak a lekérdezésnek az I/O-értéke a munkacsoport 900 IOPS-korlátja alá csökkenhet.
A sys.dm_user_db_resource_governance nézet által visszaadott IOPS- és átviteli sebesség maximális értékei korlátokként/korlátként működnek, nem pedig garanciaként. Továbbá az erőforrás-szabályozás nem garantálja a tárolási késést. Egy adott felhasználói számítási feladat számára elérhető legjobb késés, IOPS és átviteli sebesség nem csak az I/O erőforrás-szabályozási korlátoktól, hanem a használt I/O-méretek kombinációjától és a mögöttes tároló képességeitől is függ. Az SQL Database olyan I/O-műveleteket használ, amelyek mérete 512 bájt és 4 MB között változik. Az IOPS-korlátok érvényre juttatása érdekében minden I/O-t számba kell venni a méretétől függetlenül, kivéve az Azure Storage-beli adatfájlokat tartalmazó adatbázisokat. Ebben az esetben a 256 KB-nál nagyobb I/O-k több 256 KB-os I/O-ként vannak elszámolva, hogy igazodjanak az Azure Storage I/O könyveléséhez.
Az Azure Storage-ban adatfájlokat használó alapszintű, standard és általános célú adatbázisok esetében előfordulhat, hogy a primary_group_max_io érték nem érhető el, ha egy adatbázis nem rendelkezik elegendő adatfájllal az IOPS összegző megadásához, vagy ha az adatok nem egyenletesen vannak elosztva a fájlok között, vagy ha a mögöttes blobok teljesítményszintje az erőforrás-szabályozási korlátok alatt korlátozza az IOPS/átviteli sebességet. Hasonlóképpen, a tranzakciók gyakori véglegesítése által generált kis napló I/O-műveletek esetén előfordulhat, hogy a primary_max_log_rate érték nem érhető el egy számítási feladat számára a mögöttes Azure Storage-blob IOPS-korlátja miatt. Az Azure Premium Storage-t használó adatbázisok esetében az Azure SQL Database elegendően nagy tárolóblobokat használ a szükséges IOPS/átviteli sebesség beszerzéséhez, az adatbázis méretétől függetlenül. Nagyobb adatbázisok esetén több adatfájl jön létre a teljes IOPS/átviteli sebesség növeléséhez.
Az olyan erőforrás-kihasználtsági értékek, mint a avg_data_io_percent és a avg_log_write_percent, amelyek a sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_statsés sys.elastic_pool_resource_stats nézetekben vannak kiszámítva, a maximális erőforrás-szabályozási korlátok százalékában vannak kiszámítva. Ezért ha az erőforrás-szabályozási korláttól eltérő tényezők korlátozzák az IOPS-t/átviteli sebességet, az IOPS/átviteli sebesség elsimul, és a terhelés növekedésével nő a késések száma, annak ellenére, hogy a jelentett erőforrás-kihasználtság 100%alatt marad.
Az adatbázisfájlonkénti olvasási és írási IOPS- és átviteli sebesség, valamint késés figyeléséhez használja a sys.dm_io_virtual_file_stats() függvényt. Ez a függvény az összes I/O-t az adatbázison keresztül jeleníti meg, beleértve a háttérbeli I/O-t is, amely nem avg_data_io_percent, hanem IOPS-t és az alapul szolgáló tároló átviteli sebességét használja, és hatással lehet a megfigyelt tárolási késésre. A függvény további késéseket jelez, amelyeket az I/O-erőforrás-szabályozás az olvasások és írások esetében a io_stall_queued_read_ms és io_stall_queued_write_ms oszlopokban is bevezethet.
Tranzakciónaplók sebességszabályozása
A tranzakciónaplók sebességének szabályozása az Azure SQL Database-ben a számítási feladatok, például a tömeges beszúrás, a SELECT INTO és az index buildjei magas betöltési arányának korlátozására szolgál. Ezeket a korlátokat a rendszer az alszekundum szintjén követi és érvényesíti a naplórekord-létrehozás sebességére, és korlátozza az átviteli sebességet attól függetlenül, hogy hány I/O adható ki az adatfájlokhoz. A tranzakciónapló-létrehozási arányok jelenleg lineárisan skálázhatók egy olyan pontra, amely hardverfüggő és szolgáltatásszint-függő.
A naplózási arányok úgy vannak beállítva, hogy különböző forgatókönyvekben elérhetőek és fenntarthatók legyenek, míg az általános rendszer minimális hatással lehet a felhasználói terhelésre. A naplók sebességszabályozása biztosítja, hogy a tranzakciónapló biztonsági mentései a közzétett helyreállíthatósági SLA-kon belül maradjanak. Ez a szabályozás megakadályozza a másodlagos replikák túlzott leállását is, amely egyébként a vártnál hosszabb állásidőt eredményezhet a feladatátvétel során.
A tranzakciós naplófájlok tényleges fizikai I/O-jai nincsenek szabályozva vagy korlátozva. A naplórekordok létrehozásakor a rendszer minden műveletet kiértékel és kiértékel, hogy késleltetni kell-e a maximálisan kívánt naplósebességet (MB/s másodpercenként). A késések nem lesznek hozzáadva, amikor a naplórekordok ki vannak ürítve a tárolóba, hanem a naplósebesség szabályozása lesz alkalmazva a naplósebesség létrehozásakor.
A futtatáskor érvényes naplólétrehozási arányokat a visszajelzési mechanizmusok is befolyásolják, ideiglenesen csökkentve az engedélyezett naplók sebességét, hogy a rendszer stabilizálódhasson. A naplófájlterület kezelése, a naplótér kifogyott állapotainak és az adatreplikációs mechanizmusoknak a elkerülése ideiglenesen csökkentheti a teljes rendszerkorlátot.
A naplósebesség-vezérlő forgalomalakítását a következő várakozási típusok (a sys.dm_exec_requests és sys.dm_os_wait_stats nézetekben teszik közzé):
| Várakozás típusa | Jegyzetek |
|---|---|
LOG_RATE_GOVERNOR |
Adatbázis-korlátozás |
POOL_LOG_RATE_GOVERNOR |
Készletkorlátozás |
INSTANCE_LOG_RATE_GOVERNOR |
Példányszint-korlátozás |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Visszajelzés-vezérlés, rendelkezésre állási csoport fizikai replikációja a Prémium/Üzleti szempontból kritikus szinten nem tartható fenn |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Visszajelzés-vezérlés, sebességkorlátozás a naplóterület kiesésének elkerülése érdekében |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Georeplikációs visszajelzések szabályozása, a naplók sebességének korlátozása a magas adatkésés és a georeplikációk elérhetetlenségének elkerülése érdekében |
Ha olyan naplósebesség-korlátot tapasztal, amely akadályozza a kívánt méretezhetőséget, vegye figyelembe a következő lehetőségeket:
- Vertikális felskálázás magasabb szolgáltatási szintre egy szolgáltatási szint maximális naplózási sebességének lekéréséhez, vagy váltás másik szolgáltatási szintre.
- A prémium sorozatú és prémium sorozatú memóriaoptimalizált hardverek esetében a rugalmas skálázású kiépített szolgáltatási szint adatbázisonként 150 MiB/s naplózási arányt és rugalmas készletenként 150 MiB/s-t biztosít.
- Más hardversorozatok esetén a rugalmas skálázási szolgáltatási szint adatbázisonként 100 MiB/s naplósebességet és rugalmas készletenként 125 MiB/s-t biztosít.
- Ha a betöltött adatok átmenetiek, például átmeneti adatok egy ETL-folyamatban, akkor betölthetők
tempdb(amely minimálisan naplózva van). - Elemzési forgatókönyvek esetén töltse be a fürtözött oszlopcentrikus táblába, vagy egy olyan táblába, amely adattömörítésihasznál. Ez csökkenti a szükséges naplók számát. Ez a technika növeli a processzorhasználatot, és csak a fürtözött oszlopcentrikus indexek vagy adattömörítés előnyeit élvező adathalmazokra alkalmazható.
Tárolóhely szabályozása
A prémium és az üzleti szempontból kritikus szolgáltatási szinteken az ügyféladatokat, köztük az adatfájlokat, a tranzakciónapló-fájlokat és a tempdb fájlokat az adatbázist vagy rugalmas készletet üzemeltető gép helyi SSD-tárolójában tárolja a rendszer. A helyi SSD-tároló magas IOPS- és átviteli sebességet, valamint alacsony I/O-késést biztosít. Az ügyféladatok mellett az operációs rendszer, a felügyeleti szoftverek, a monitorozási adatok és naplók, valamint a rendszer működéséhez szükséges egyéb fájlok helyi tárolót is használnak.
A helyi tároló mérete véges, és a hardver képességeitől függ, amely meghatározza a maximális helyi tárolási korlátot, vagy a helyi tárolót az ügyféladatokhoz. Ez a korlát úgy van beállítva, hogy maximalizálja az ügyfelek adattárolását, miközben biztonságos és megbízható rendszerműveletet biztosít. Az egyes szolgáltatási célok maximális helyi tárolási értékének megkereséséhez tekintse meg önálló adatbázisok és rugalmas készletekerőforráskorlátokkal kapcsolatos dokumentációját.
Ezt az értéket és az adott adatbázis vagy rugalmas készlet által jelenleg használt helyi tároló mennyiségét is megtalálhatja az alábbi lekérdezéssel:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Oszlop | Leírás |
|---|---|
server_name |
Logikai kiszolgáló neve |
database_name |
Adatbázis neve |
slo_name |
Szolgáltatás célkitűzésének neve, beleértve a hardvergenerálást is |
user_data_directory_space_quota_mb |
Maximális helyi tárolásiMB-ban |
user_data_directory_space_usage_mb |
Az adatfájlok, tranzakciós naplófájlok és tempdb fájlok aktuális helyi tárolási felhasználása MB-ban. Öt percenként frissítve. |
Ezt a lekérdezést a felhasználói adatbázisban kell végrehajtani, nem a master adatbázisban. Rugalmas készletek esetén a lekérdezés a készlet bármely adatbázisában végrehajtható. A jelentett értékek a teljes készletre vonatkoznak.
Fontos
Prémium és üzleti szempontból kritikus szolgáltatási szinteken, ha a számítási feladat adatfájlok, tranzakciónapló-fájlok és tempdb fájlok együttes helyi tárolási felhasználását próbálja növelni a maximális helyi tárterület- korláton túl, a rendszer helyen kívüli hibát fog tapasztalni. Ez akkor is megtörténik, ha az adatbázisfájlban használt terület nem éri el a fájl maximális méretét.
A helyi SSD-tárolót a prémium és üzleti szempontból kritikus szolgáltatási szinteken lévő adatbázisok is használják az tempdb adatbázishoz és a rugalmas skálázású RBPEX-gyorsítótárhoz. Az adatbázisok létrehozása, törlése és méretének növelése vagy csökkentése során a gépeken a teljes helyi tárterület-használat idővel ingadozik. Ha a rendszer azt észleli, hogy a számítógépen rendelkezésre álló helyi tároló alacsony, és egy adatbázis vagy egy rugalmas készlet ki van téve a szabad terület kifutásának, áthelyezi az adatbázist vagy a rugalmas készletet egy másik gépre, amelyen elegendő helyi tároló áll rendelkezésre.
Ez az áthelyezés online módon történik, hasonlóan az adatbázis-skálázási művelethez, és hasonló hatással van, beleértve a művelet végén egy rövid (másodperces) feladatátvételt is. Ez a feladatátvétel megszakítja a nyitott kapcsolatokat, és visszaállítja a tranzakciókat, ami potenciálisan hatással lehet az adatbázist használó alkalmazásokra.
Mivel a rendszer minden adatot átmásol a különböző gépek helyi tárolóköteteibe, a prémium és üzleti szempontból kritikus szolgáltatási szinteken lévő nagyobb adatbázisok áthelyezése jelentős időt igényelhet. Ezalatt az idő alatt, ha egy adatbázis vagy egy rugalmas készlet vagy a tempdb adatbázis által történő helyi térhasználat gyorsan növekszik, nő a szabad terület elfogyásának kockázata. A rendszer kiegyensúlyozott módon kezdeményezi az adatbázisok áthelyezését, hogy minimalizálja a felesleges feladatátvételeket.
tempdb méretek
Az Azure SQL Database-ben tempdb méretkorlátjai a vásárlási és üzembehelyezési modelltől függenek.
További információért tekintse át tempdb méretkorlátokat a következőhöz:
- virtuálismag-vásárlási modell: önálló adatbázisok, készletezett adatbázisok
- DTU vásárlási modell: önálló adatbázisok, készletezett adatbázisok.
Korábban elérhető hardver
Ez a szakasz részletesen ismerteti a korábban elérhető hardvereket.
- A Gen4-hardver ki lett állítva, és nem érhető el kiépítéshez, felskálázáshoz vagy leskálázáshoz. Az adatbázist egy támogatott hardvergenerációra migrálhatja a virtuális magok és a tárterület skálázhatóságának, a gyorsított hálózatkezelésnek, a legjobb IO-teljesítménynek és a minimális késésnek a biztosítása érdekében. További információ: Gen 4-hardver támogatása véget ért az Azure SQL Database.
Az Azure Resource Graph Explorer segítségével azonosíthatja az összes Olyan Azure SQL Database-erőforrást, amely jelenleg Gen4-hardvert használ, vagy ellenőrizheti, hogy az erőforrások milyen hardvert használnak egy adott logikai kiszolgáló az Azure Portalon.
Az Azure Resource Graph Explorerben az eredmények megtekintéséhez legalább read engedélyekkel kell rendelkeznie az Azure-objektumhoz vagy objektumcsoporthoz.
Ha Resource Graph Explorer szeretné azonosítani a Gen4-hardvert továbbra is használó Azure SQL-erőforrásokat, kövesse az alábbi lépéseket:
Lépjen a Azure Portal.
Keresse meg a
Resource grapha keresőmezőben, és válassza ki a Resource Graph Explorer szolgáltatást a keresési eredmények közül.A lekérdezési ablakban írja be a következő lekérdezést, majd válassza a Lekérdezés futtatása:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"A Eredmények panel megjeleníti az Azure-ban jelenleg üzembe helyezett összes, Gen4-hardvert használó erőforrást.
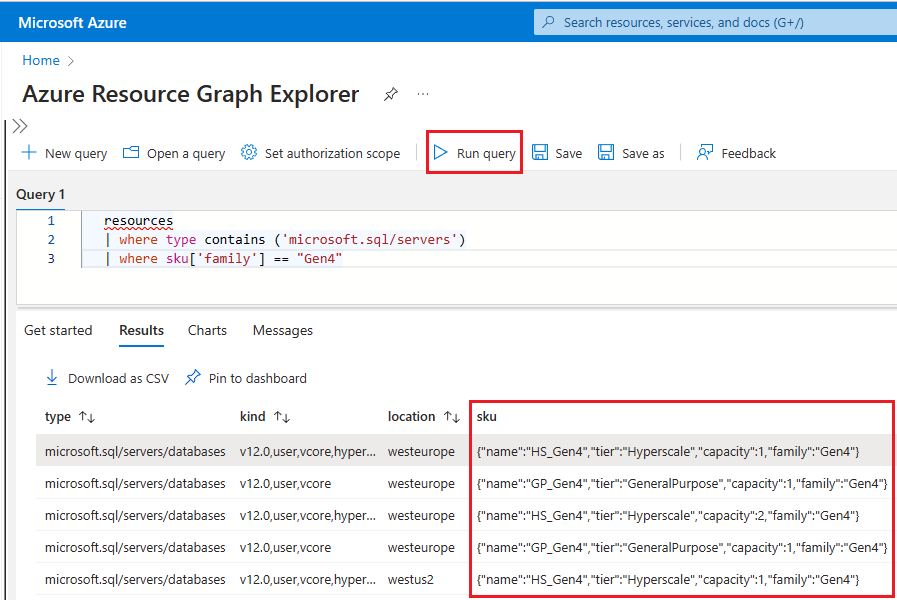
Ha ellenőrizni szeretné, hogy az erőforrások milyen hardvert használnak egy adott logikai kiszolgálóhoz az Azure-ban, kövesse az alábbi lépéseket:
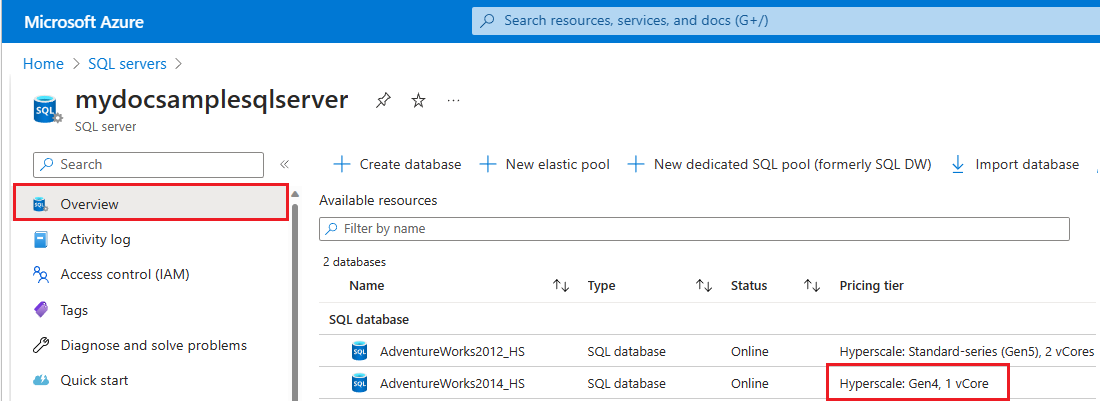
- Lépjen a Azure Portal.
- Keresse meg a
SQL serversa keresőmezőben, és válassza SQL-kiszolgálók a keresési eredmények közül a SQL-kiszolgálók lap megnyitásához és a kiválasztott előfizetés(ek) összes kiszolgálójának megtekintéséhez. - Válassza ki a megfelelő kiszolgálót a kiszolgáló Áttekintés lapjának megnyitásához.
- Görgessen le a rendelkezésre álló erőforrásokhoz, és ellenőrizze a Tarifacsomag oszlopot a gen4 hardvert használó erőforrásokhoz.
Ha az erőforrásokat standard sorozatú hardverre szeretné migrálni, tekintse át Hardvermódosítása című cikket.
Kapcsolódó tartalom
- Az Általános Azure-korlátokról további információt Azure-előfizetések és -szolgáltatások korlátait, kvótáit és korlátozásait.
- További információ a DTU-kkal és az eDTU-kkal kapcsolatban: DTU-k és eDTU-k.
- A
tempdbméretkorlátokról további információt egyetlen virtuálismag-adatbázis, készletezett virtuálismag-adatbázisok, önálló DTU-adatbázisokés készletezett DTU-adatbázisokcímű témakörben talál.