Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Vonatkozik a következőkre:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analitikai Platform System (PDW)
Analitikai Platform System (PDW)![]() SQL adatbázis a Microsoft Fabric-ben
SQL adatbázis a Microsoft Fabric-ben
Az oszlopcentrikus indexek a nagy adatraktározási ténytáblák tárolásának és lekérdezésének szabványai. Ez az index oszlopalapú adattárolást és lekérdezésfeldolgozást használ annak érdekében, hogy az adattárházban a lekérdezési teljesítmény akár tízszerese is legyen a hagyományos sororientált tárolásnak. Az adattömörítéssel akár tízszeresére is csökkenthető a tömörítetlen adatméret. Az SQL Server 2016 (13.x) SP1-től kezdődően az oszlopcentrikus indexek működési elemzést tesznek lehetővé: a tranzakciós számítási feladatokon végzett, valós idejű teljesítményt nyújtó elemzések futtatását.
További információ egy kapcsolódó forgatókönyvről:
- Oszlopalapú indexek az adattárházakban
- Kezdje el a columnstore használatát valós idejű üzemeltetési elemzésekhez
Mi az oszlopalapú index?
Az oszlopalapú index egy olyan technológia, amely az adatok oszlopos adatformátummal történő tárolására, beolvasására és kezelésére szolgál, és amelyet oszlopalapú tárolónakhívnak.
Főbb kifejezések és fogalmak
A következő fő kifejezések és fogalmak oszlopcentrikus indexekhez vannak társítva.
Columnstore
Az oszloptárak olyan adatok, amelyek logikailag táblázatként rendezve, sorokkal és oszlopokkal, és fizikailag oszlopalapú adatformátumban tárolódnak.
Rowstore
A sortár egy adatstruktúra, amely logikailag táblázatként van rendezve sorokkal és oszlopokkal, és fizikailag sorok szerinti adatformátumban van tárolva. Ez a formátum a relációs táblaadatok hagyományos tárolásának módja. Az SQL Serverben a rowstore olyan táblára hivatkozik, amelyben a mögöttes adattárolási formátum halom, fürtözött index vagy memóriaoptimalizált tábla.
Note
Az oszlopcentrikus indexekről szóló vitákban a rowstore és a columnstore kifejezésekkel hangsúlyozzuk az adattárolás formátumát.
Rowgroup
A sorcsoport olyan sorok csoportja, amelyek egyszerre vannak oszlopcentrikus formátumban tömörítve. A sorcsoportok általában a sorcsoportonkénti sorok maximális számát tartalmazzák, ami 1 048 576 sor.
A nagy teljesítmény és a nagy tömörítési sebesség érdekében az oszlopcentrikus index sorcsoportokra szeleteli a táblát, majd oszlopszerűen tömöríti az egyes sorcsoportokat. A sorok számának a sorcsoportban elég nagynak kell lennie a tömörítési sebesség javításához, és elég kicsinek kell lennie ahhoz, hogy kihasználhassa a memórián belüli műveleteket.
Egy sorcsoport, amelyről az összes adat törölve lett, átkerül a TÖMÖRÍTETT állapotból a TOMBSTONE állapotba, és később egy háttérfolyamat, amelyet tuple-movernek neveznek, eltávolítja. További információ a sorcsoportok állapotairól, lásd: sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Tip
Ha túl sok kis sorcsoport van, az csökkenti az oszlopcentrikus index minőségét. Az SQL Server 2017 -ig (14.x) a kisebb TÖMÖRÍTETT sorcsoportok egyesítéséhez újraszervezési művelet szükséges, amely egy belső küszöbérték-szabályzatot követ, amely meghatározza a törölt sorok eltávolítását és a tömörített sorcsoportok egyesítését.
Az SQL Server 2019 -től (15.x) kezdődően egy háttéregyesítési feladat is működik a TÖMÖRÍTETT sorcsoportok egyesítésére, ahonnan nagy számú sort töröltek.
A kisebb sorcsoportok egyesítése után javítani kell az index minőségét.
Note
Az SQL Server 2019 (15.x), az Azure SQL Database, az Azure SQL kezelt példánya és az Azure Synapse Analytics dedikált SQL-készletei esetében az ún. tuple-mover tevékenységét egy háttér-egyesítési feladat segíti, amely automatikusan tömöríti a kisebb OPEN delta sorcsoportokat, amelyek a belső küszöbérték által meghatározott ideje léteznek, vagy egyesíti azokat a COMPRESSED sorcsoportokat, ahonnan nagy számú sor került törlésre. Ez idővel javítja az oszlopcentrikus index minőségét.
Oszlopszegmens
Az oszlopszegmens a sorcsoporton belülről származó adatok oszlopa.
- Minden sorcsoport egy oszlopszegmenst tartalmaz a tábla minden oszlopához.
- Minden oszlopszegmens össze van tömörítve, és fizikai adathordozón van tárolva.
- Az egyes szegmensek metaadatai lehetővé teszik a szegmensek gyors eltávolítását olvasás nélkül.
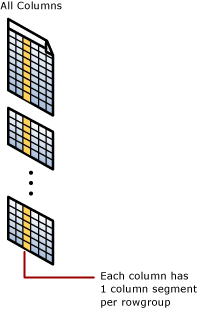
Fürtözött oszlopalapú tárolású index
A fürtözött oszlop-alapú index szolgál a teljes tábla fizikai tárolására.
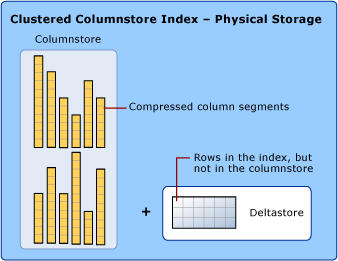
Az oszlopszegmensek töredezettségének csökkentése és a teljesítmény javítása érdekében az oszlopcentrikus index ideiglenesen tárolhat bizonyos adatokat egy deltastore nevű fürtözött indexbe, valamint a törölt sorok azonosítóinak B-fa listájába. A deltastore-műveleteket a színfalak mögött kezelik. A megfelelő lekérdezési eredmények visszaadásához a fürtözött oszlopcentrikus index az oszloptárból és a deltastore-ból származó lekérdezési eredményeket is egyesíti.
Note
A dokumentáció általában a B-fa kifejezést használja az indexekre hivatkozva. A sorkataszterekben az adatbázismotor egy B+ fát implementál. Ez nem vonatkozik az oszlopcentrikus indexekre vagy a memóriaoptimalizált táblák indexére. További információ: SQL Server és Azure SQL index architektúrája és tervezési útmutatója.
Delta sorcsoport
A delta sorcsoport egy fürtözött B-fa index, amely csak oszlopalapú indexekkel használható. Javítja az oszlopcentrikus tömörítést és a teljesítményt azáltal, hogy sorokat tárol, amíg a sorok száma eléri a küszöbértéket (1 048 576 sor), majd áthelyezi őket az oszloptárba.
Amikor egy delta sorcsoport eléri a sorok maximális számát, az OPEN-ről ZÁRT állapotra vált. Egy tuple-mover nevű háttérfolyamat ellenőrzi a zárt sorcsoportokat. Ha a folyamat egy zárt sorcsoportot talál, tömöríti a delta sorcsoportot, és tömörített sorcsoportként tárolja az oszloptárban.
Ha egy delta sorcsoport tömörítése megtörtént, a meglévő delta sorcsoport "TOMBSTONE" állapotba vált, amelyet a tuple-mover később eltávolít, ha nincs rá hivatkozás.
További információ a sorcsoportok állapotairól, lásd: sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Note
Az SQL Server 2019 (15.x) verziójától kezdve a háttérben futó egyesítési feladat segíti a tuple-mover munkáját. Ez a feladat automatikusan tömöríti a belső küszöbérték szerint már egy ideje létező kisebb OPEN delta sorcsoportokat, vagy egyesíti a TÖMÖRÍTETT sorcsoportokat, amelyekből nagyszámú sor lett törölve. Ez idővel javítja az oszlopcentrikus index minőségét.
Deltastore
Az oszlopcentrikus indexek több deltasorcsoporttal is rendelkezhetnek. Az összes deltasorcsoportot együttesen deltastore-nak nevezzük.
Nagy mennyiségű betöltés esetén a sorok többsége közvetlenül az oszlopáruházba kerül anélkül, hogy áthaladna a deltastore-on. Előfordulhat, hogy a tömeges terhelés végén néhány sor túl kevés ahhoz, hogy megfeleljen a 102 400 sorból álló sorcsoport minimális méretének. Ennek eredményeképpen az utolsó sorok az oszloptár helyett a deltastore-ba kerülnek. Kisebb, 102 400 sornál kisebb tömeges terhelések esetén az összes sor közvetlenül a deltastore-ba kerül.
Nem klaszteres oszlop adattár index
A nem fürtözött oszlopindextár és a fürtözött oszlopindextár ugyanúgy működnek. A különbség az, hogy a nem klaszterezett indexet egy sortáblázaton hozzák létre másodlagos indexként, míg a klaszteres oszlopos tárolási index az egész tábla elsődleges tárolását szolgálja.
A nem klaszteres index a mögöttes tábla sorainak és oszlopainak egy részét vagy egészét tartalmazza másolatként. Az index a tábla egy vagy több oszlopaként van definiálva, és egy választható feltétellel rendelkezik, amely szűri a sorokat.
A neminclusterált oszloptárolós index lehetővé teszi a valós idejű operatív elemzéseket, ahol az OLTP munkafolyamat a mögöttes fürtözött indexet használja, miközben az elemzések párhuzamosan futnak az oszloptárolós indexen. További információért lásd: A columnstore használatának első lépései valós idejű üzemeltetési elemzésekhez.
Kötegelt üzemmód végrehajtása
A batch módú végrehajtás egy lekérdezésfeldolgozási módszer, amely több sor együttes feldolgozására szolgál. A Batch mód végrehajtása szorosan integrálva van az oszloptár tárolási formátumával, és optimalizálva van. Néha a kötegelt módú végrehajtást vektoralapú vagy vektoros végrehajtásnak is nevezik. Az oszlopcentrikus indexeken lévő lekérdezések kötegelt módú végrehajtást használnak, amely általában két-négyszeresére növeli a lekérdezés teljesítményét. További információ: Lekérdezésfeldolgozási architektúra útmutatója.
Miért érdemes oszlopcentrikus indexet használni?
Az oszlopcentrikus indexek rendkívül magas szintű adattömörítést biztosíthatnak, általában 10-szeresére, így jelentősen csökkenthetik az adattárház tárolási költségeit. Az elemzésekhez az oszlopcentrikus index nagyságrendekkel jobb teljesítményt nyújt, mint a B-fa index. Az oszlopcentrikus indexek az adattárház- és elemzési számítási feladatok előnyben részesített adattárolási formátumai. Az SQL Server 2016 (13.x) verziójától kezdve oszlopalapú indexeket használhat valós idejű elemzésekhez az operatív munkaterhelésén.
Az okai annak, hogy az oszlopalapú indexek olyan gyorsak:
Az oszlopok ugyanabból a tartományból származó értékeket tárolnak, és gyakran hasonló értékekkel rendelkeznek, ami nagy tömörítési arányt eredményez. A rendszer I/O szűk keresztmetszetei minimálisra csökkennek vagy megszűnnek, és a memóriaigény jelentősen csökken.
A nagy tömörítési sebesség kisebb memóriaigény használatával javítja a lekérdezési teljesítményt. A lekérdezési teljesítmény viszont javulhat, mert az SQL Server több lekérdezési és adatműveletet hajthat végre a memóriában.
A kötegelt végrehajtás több sor együttes feldolgozásával javítja a lekérdezési teljesítményt, általában kétszer-négyszeresére.
A lekérdezések gyakran csak néhány oszlopot választanak ki egy táblából, ami csökkenti a fizikai adathordozó teljes I/O-jának számát.
Mikor érdemes oszlopcentrikus indexet használni?
Ajánlott használati esetek:
Fürtözött oszlopcentrikus index használatával ténytáblákat és nagyméretű dimenziótáblákat tárolhat adattárház-számítási feladatokhoz. Ez a módszer akár 10-szer is javítja a lekérdezési teljesítményt és az adattömörítést. További információért lásd: Oszlopáruház indexek az adattárházakhoz.
A nem klaszterizált oszlopalapú index használatával elemzést végezhet valós időben egy OLTP-terhelésen. További információért lásd: A columnstore használatának első lépései valós idejű üzemeltetési elemzésekhez.
További használati forgatókönyvek az oszlopcentrikus indexekhez: Válassza ki az igényeinek leginkább megfelelő oszlopcentrikus indexet.
Hogyan választhatok a sor- és oszlopcentrikus indexek között?
A rowstore-indexek a legjobban az adatokat kereső lekérdezéseken, egy adott érték keresésekor vagy egy kis értéktartományon végzett lekérdezések esetén teljesítenek a legjobban. Használjon sortárindexeket tranzakciós számítási feladatokhoz, mert általában táblakeresésre van szükségük a táblavizsgálatok helyett.
Az oszlopcentrikus indexek nagy teljesítménynövekedést biztosítanak a nagy mennyiségű adatot beolvasó elemzési lekérdezésekhez, különösen a nagy táblákon. Oszlopcentrikus indexeket használjon adattárház- és elemzési számítási feladatokhoz, különösen ténytáblákon, mivel a táblakeresések helyett általában teljes táblavizsgálatot igényelnek.
Az rendezett klaszteres oszlopraktár indexek az oszloppredikátumok alapján javítják a lekérdezések teljesítményét. A rendezett oszloptárolós indexek javíthatják a sorcsoportok kizárását, ami a sorcsoportok teljes kihagyásával javíthatja a teljesítményt. További információ: A teljesítmény finomhangolása rendezett oszlopcentrikus indexekkel. A rendezett oszlopalapú index rendelkezésre állásával kapcsolatos információkat a Rendezett oszlopindex rendelkezésre állásicímű témakörben találja.
Kombinálhatom a sor- és oszloptárat ugyanazon a táblán?
Yes. Az SQL Server 2016-tól kezdve (13.x) létrehozhat egy frissíthető, nem klaszteres oszlopalapú indexet egy soros táblán. Az oszlopcentrikus index a kijelölt oszlopok egy példányát tárolja, ezért további hely szükséges az adatokhoz, de a kijelölt adatok átlagosan 10 alkalommal lesznek tömörítve. Egyszerre futtathat elemzéseket az oszlopkészlet indexen és tranzakciókat a sorkészlet indexen. Az oszloptár akkor frissül, amikor az adatok megváltoznak a sortártáblában, így mindkét index ugyanazon adatokon dolgozik.
Az SQL Server 2016-tól (13.x) kezdődően egy vagy több nem klaszterezett soros index is lehet egy oszloptárolós indexen, és hatékony táblakereséseket hajthat végre az alapul szolgáló oszlopos adattárban. Más lehetőségek is elérhetővé válnak. Például, elsődleges kulcskényszert alkalmazhat egy EGYEDI kényszerrel a soros tároló táblán. Mivel egy nemunikus érték nem illeszthető be a sortártáblába, az SQL Server nem tudja beszúrni az értéket az oszloptárba.
Rendezett oszloptárolós indexek
A hatékony szegmenseltörlés engedélyezésével a rendezett oszlopcentrikus indexek gyorsabb teljesítményt nyújtanak a lekérdezési predikátumnak nem megfelelő nagy mennyiségű rendezett adat kihagyásával. Az adatok rendezett oszlopcentrikus indexbe való betöltése hosszabb időt vehet igénybe, mint a nem rendezett indexekben az adatrendezési művelet miatt, de a rendezett oszlopcentrikus indexek esetén a lekérdezések később gyorsabban futhatnak.
- Az SQL Database Engine-ben rendezett oszlopcentrikus indexekkel rendelkező adatraktározási terhelések teljesítményhangolásáról további információért lásd: A teljesítmény finomhangolása rendezett oszlopcentrikus indexekkel.
- Az oszlopcentrikus index típusának használatáról további információt Az igényeinek leginkább megfelelő oszlopcentrikus index kiválasztásacímű témakörben talál.
Rendezett oszlopalapú index elérhetősége
A rendezett oszlopcentrikus indexek a következő platformokon érhetők el:
| Platform | Rendezett fürtözött oszlopalapú indexek | Rendezett nem klaszterezett oszlopcentrikus indexek |
|---|---|---|
| Azure SQL Database | Yes | Yes |
| Azure SQL Kezelt PéldányAUTD | Yes | Yes |
| Azure SQL Felügyelt Példány2025 | Yes | Yes |
| Azure SQL Felügyelt Példány2022 | Yes | No |
| SQL-adatbázis a Microsoft Fabricben | Yes1 | Yes |
| SQL Server 2025 (17.x) | Yes | Yes |
| SQL Server 2022 (16.x) | Yes | No |
| Dedikált SQL-készlet az Azure Synapse Analyticsben | Yes | No |
AUTD az Always-up-to-date frissítési szabályzattal konfigurált felügyelt Azure SQL-példányra vonatkozik.
A 2025 az SQL Server 2025 frissítési szabályzattal konfigurált felügyelt Azure SQL-példányra vonatkozik.
2022 Azokra a Felügyelt Azure SQL-példányokra vonatkozik, amelyeket a SQL Server 2022 frissítési szabályzatával konfiguráltak.
1A Fabric SQL-adatbázisban a fürtözött oszlopcentrikus indexekkel rendelkező táblák nincsenek tükrözve a Fabric OneLake.
Metadata
Az oszlopcentrikus index összes oszlopa a metaadatokban lesz tárolva, a benne foglalt oszlopokként. Az oszlopalapú index nem rendelkezik kulcsoszlopokkal.
Kapcsolódó tevékenységek
| Task | Referenciacikkek | Notes |
|---|---|---|
| Táblázat létrehozása oszloptárként. | CREATE TABLE (Transact-SQL) | A tábla létrehozásakor alapértelmezés szerint a sortárolót használja alapul szolgáló adatformátumként. Az SQL Server 2016 (13.x) verziótól kezdve a INDEX ... CLUSTERED COLUMNSTORE beállítás megadásával létrehozhatja a fürtözött oszlop adattárház indexet tartalmazó táblát. Nem kell először létrehoznia egy soros adattáblát, majd átalakítania oszlopos adattáblává. |
| Sortártáblát oszloptárká alakíthat. | OSZLOP ADATTÁRHÁZ INDEX LÉTREHOZÁSA (Transact-SQL) | Meglévő halom vagy B-fa átalakítása oszlopalapú adattárrá. Példák a meglévő indexek kezelésére, valamint az index nevére az átalakítás végrehajtásakor. |
| Hozzon létre egy nem klaszteres oszlop-tároló indexet egy sor alapú táblán. | OSZLOP ADATTÁRHÁZ INDEX LÉTREHOZÁSA (Transact-SQL) | A soros táblának lehet egy nem klaszterezett oszlopalapú indexe. Az SQL Server 2016 (13.x) verziótól kezdődően a nem klaszterezett oszlopalapú index rendelkezhet szűrt feltétellel. A példák az alapszintű szintaxist mutatják be. |
| Oszlopalapú tábla átalakítása soralapúvá. | CSOPORTOSÍTOTT INDEX LÉTREHOZÁSA (Transact-SQL) vagy oszloptár-tábla visszaalakítása sor-tár halommá | Ez az átalakítás általában nem szükséges, de előfordulhat, hogy konvertálni kell. Példák mutatják, hogyan alakítható egy oszloptár halom- vagy klaszterindexé. |
| Oszlopcentrikus indexek létrehozása adattárházakhoz. | Oszlopalapú indexek az adattárházakhoz | Az oszlopcentrikus indexek gyors adattárház-lekérdezésekhez való használatát ismerteti. |
| Indexek létrehozása operatív elemzésekhez. | Kezdje el a columnstore használatát valós idejű üzemeltetési elemzésekhez | Azt ismerteti, hogyan hozhat létre kiegészítő oszloptár- és B-faindexeket, hogy az OLTP-lekérdezések B-fa indexeket használnak, az elemzési lekérdezések pedig oszlopcentrikus indexeket használnak. |
| Használjon B-fa indexet, hogy érvényesítse az elsődleges kulcs megszorítást egy oszlop-adattároló indexen. | Oszlopalapú indexek az adattárházakhoz | Bemutatja, hogyan kombinálhatja a B-fa- és oszlopcentrikus indexeket az oszlopcentrikus táblák elsődleges kulcskorlátjának kikényszerítéséhez. |
| Hozzon létre egy memóriaoptimalizált táblát oszlopcentrikus indexkel. | CREATE TABLE (Transact-SQL) | Az SQL Server 2016 -tól kezdve (13.x) létrehozhat egy memóriaoptimalizált táblát egy oszlopcentrikus indexkel. Az oszlopcentrikus index a tábla létrehozása után is hozzáadható a ALTER TABLE ADD INDEX szintaxissal. |
| Adatok betöltése oszlopcentrikus indexbe. | Oszloptárolós indexek adatbetöltése | |
| Oszlopcentrikus index törlése. | DROP INDEX (Transact-SQL) | Az oszlopalapú index elvetése ugyanazt a szabványos DROP INDEX szintaxist használja, mint amit a B-fa indexek használnak. A klaszteres oszloptárolós index elvetése az oszloptárolós táblát halmazzá alakítja. |
| Töröljön egy sort egy oszlopcentrikus indexből. | DELETE (Transact-SQL) | Sor törléséhez használja DELETE (Transact-SQL). oszlopcentrikus sor: Az SQL Server logikailag töröltként jelöli meg a sort, de az index újraépítéséig nem veszi vissza a sor fizikai tárterületét. deltastore sor: Az SQL Server logikailag és fizikailag törli a sort. |
| Frissítsen egy sort az oszlopalapú indexben. | UPDATE (Transact-SQL) | A sor frissítéséhez használja UPDATE (Transact-SQL). oszlopcentrikus sor: Az SQL Server logikailag töröltként jelöli meg a sort, majd beszúrja a frissített sort a deltastore-ba. deltastore sor: Az SQL Server frissíti a deltastore sorát. |
| Oszloptárolós index karbantartása. |
ALTER INDEX ... ÚJRAÉPÍT Oszlopcentrikus index ÁTRENDEZÉSE Indexkarbantartási módszerek: átrendezés és újraépítés |
A legtöbb esetben a ALTER INDEX ... REORGANIZE hasonló eredményeket ad, mint a ALTER INDEX ... REBUILD, de alacsonyabb erőforrás-felhasználás mellett.
ALTER INDEX ... REORGANIZE mindig online fut. Mindkét beállítás töredezettségmentesítést nyújt egy oszloptároló indexhez, és kényszeríti a deltastore sorait az oszloptárba való átkerülésre.Az SQL Server 2019 -től kezdve (15.x) az Azure SQL Database-ben és a felügyelt Azure SQL-példányban az oszlopcentrikus index minősége automatikusan megmarad, így a legtöbb esetben nincs szükség időszakos indexkarbantartásra. |
Kapcsolódó tartalom
- Az oszlopcentrikus indexek újdonságai
- Oszlopalapú indexek – Adatbetöltési útmutató
- oszlopalapú indexek – Lekérdezési teljesítmény
- Kezdje el a Columnstore használatát a valós idejű üzemeltetési elemzésekhez
- Oszlopalapú indexek az adattárházakban
- Oszlopalapú indexek töredezettségmentesítése
- SQL Server és Az Azure SQL index architektúrája és tervezési útmutatója
- oszlopcentrikus indexarchitektúra
- OSZLOP ADATTÁRHÁZ INDEX LÉTREHOZÁSA (Transact-SQL)