Költségvetések, költségek és kvóták kezelése a szervezeti szintű Azure Machine Learning esetében
Az Azure Machine Learningben felmerülő számítási költségek kezelésekor egy szervezeti szinten, sok számítási feladattal, sok csapattal és felhasználóval, számos felügyeleti és optimalizálási feladattal kell foglalkoznia.
Ebben a cikkben bemutatjuk a költségek optimalizálására, a költségvetések kezelésére és a kvóták megosztására vonatkozó ajánlott eljárásokat az Azure Machine Learning használatával. A cikk tükrözi a Microsofton belüli, valamint az ügyfelekkel való partneri viszony során felügyelt Machine Learning-csapatok tapasztalatait és következtetéseit. A következőket fogja megtanulni:
- Számítási erőforrások optimalizálása a számítási feladatok követelményeinek megfelelően.
- A csapat költségvetésének legjobb kihasználása.
- Tervezze meg, kezelje és ossza meg a költségvetéseket, a költségeket és a kvótákat nagyvállalati szinten.
Számítás optimalizálása a számítási feladatokra vonatkozó követelményeknek való megfelelés érdekében
Új gépi tanulási projekt indításakor feltáró munkára lehet szükség a számítási követelmények megfelelő képének megtekintéséhez. Ez a szakasz javaslatokat nyújt arra vonatkozóan, hogyan határozhatja meg a megfelelő virtuálisgép-termékváltozatot a betanításhoz, a következtetéshez vagy a munkaállomáshoz, amelyből dolgozhat.
A betanítás számítási méretének meghatározása
A betanítási számítási feladat hardverkövetelményei projektenként eltérőek lehetnek. Ezeknek a követelményeknek való megfelelés érdekében az Azure Machine Learning Compute különböző típusú virtuális gépeket kínál:
- Általános célú: Kiegyensúlyozott processzor-memória arány.
- Memóriaoptimalizált: Magas memória-PROCESSZOR arány.
- Számításoptimalizált: Magas processzor-memória arány.
- Nagy teljesítményű számítás: Vezető szintű teljesítményt, méretezhetőséget és költséghatékonyságot biztosít a különböző valós HPC számítási feladatokhoz.
- GPU-kkal rendelkező példányok: Speciális virtuális gépek, amelyekre nagy teljesítményű grafikus renderelés és videószerkesztés, valamint mély tanulással történő modellbetanítás és következtetés (ND) irányul.
Lehet, hogy még nem tudja, mik a számítási követelmények. Ebben a forgatókönyvben azt javasoljuk, hogy kezdje az alábbi költséghatékony alapértelmezett beállításokkal. Ezek a lehetőségek az egyszerűsített teszteléshez és a betanítási számítási feladatokhoz használhatók.
| Típus | Virtuális gép mérete | Jellemzők |
|---|---|---|
| CPU | Standard_DS3_v2 | 4 mag, 14 gigabájt (GB) RAM, 28 GB tárterület |
| GPU | Standard_NC6 | 6 mag, 56 gigabájt (GB) RAM, 380 GB tárterület, NVIDIA Tesla K80 GPU |
Ha a lehető legjobb virtuálisgép-méretet szeretné elérni a forgatókönyvhöz, az próbaverzióból és hibából állhat. Az alábbiakban több szempontot is figyelembe kell venni.
- Ha processzorra van szüksége:
- Használjon memóriaoptimalizált virtuális gépet, ha nagy adathalmazokon szeretne betanítást végezni.
- Használjon számításra optimalizált virtuális gépet, ha valós idejű következtetést vagy más késésre érzékeny feladatokat végez.
- A betanítási idő felgyorsítása érdekében használjon több maggal és RAM-mal rendelkező virtuális gépet.
- Ha GPU-ra van szüksége, a virtuális gép kiválasztásával kapcsolatos információkért tekintse meg a GPU-optimalizált virtuálisgép-méreteket .
- Ha elosztott betanítást végez, használjon több GPU-val rendelkező virtuálisgép-méreteket.
- Ha több csomóponton végez elosztott betanítást, használjon NVLink-kapcsolattal rendelkező GPU-kat.
Miközben kiválasztja a számítási feladatnak leginkább megfelelő virtuálisgép-típust és termékváltozatot, értékelje ki az összehasonlítható virtuálisgép-termékváltozatokat a CPU és a GPU teljesítménye és díjszabása közötti kompromisszumként. Költségkezelési szempontból a feladatok több termékváltozatban is jól futhatnak.
Bizonyos GPU-k, mint például az NC-család, különösen NC_Promo termékváltozatok, hasonló képességekkel rendelkeznek a többi GPU-hoz, például az alacsony késéshez és a több számítási feladat párhuzamos kezeléséhez. A többi GPU-hoz képest kedvezményes áron érhetők el. A virtuálisgép-termékváltozatok számítási feladathoz való kiválasztása jelentős költségmegtakarítást eredményezhet.
A kihasználtság szempontjából fontos, hogy nagyobb számú GPU-ra regisztráljon, nem feltétlenül gyorsabb eredményekkel. Ehelyett győződjön meg arról, hogy a GPU-k teljes mértékben kihasználva vannak. Ellenőrizze például, hogy szükség van-e nvidia CUDA-ra. Bár a nagy teljesítményű GPU-végrehajtáshoz szükség lehet rá, előfordulhat, hogy a feladat nem függ attól.
A következtetés számítási méretének meghatározása
A következtetési forgatókönyvek számítási követelményei eltérnek a betanítási forgatókönyvektől. Az elérhető lehetőségek attól függően különböznek, hogy a forgatókönyv offline következtetést igényel-e kötegben, vagy valós időben online következtetést igényel.
Valós idejű következtetési forgatókönyvek esetén fontolja meg a következő javaslatokat:
- Profilkészítési képességek használata a modellen az Azure Machine Learning használatával annak meghatározásához, hogy mennyi processzort és memóriát kell lefoglalnia a modellhez webszolgáltatásként való üzembe helyezéskor.
- Ha valós idejű következtetést végez, de nincs szüksége magas rendelkezésre állásra, helyezze üzembe a Azure Container Instances (nincs termékváltozat kiválasztása).
- Ha valós idejű következtetést végez, de magas rendelkezésre állásra van szüksége, helyezze üzembe a Azure Kubernetes Service.
- Ha hagyományos gépi tanulási modelleket használ, és 10 lekérdezést kap < másodpercenként, kezdje egy CPU-termékváltozattal. Az F sorozatú termékváltozatok gyakran jól működnek.
- Ha mélytanulási modelleket használ, és 10 lekérdezést kap > másodpercenként, próbáljon ki egy NVIDIA GPU-termékváltozatot (NCasT4_v3 gyakran jól működik) a Tritonnal.
Kötegelt következtetési forgatókönyvek esetén fontolja meg a következő javaslatokat:
- Ha Azure Machine Learning-folyamatokat használ kötegelt következtetéshez, a kezdeti virtuális gép méretének kiválasztásához kövesse a betanítás számítási méretének meghatározása című témakör útmutatását.
- Költség és teljesítmény optimalizálása horizontális skálázással. A költségek és a teljesítmény optimalizálásának egyik fő módszere a számítási feladat párhuzamosítása az Azure Machine Learning párhuzamos futtatási lépésének segítségével. Ezzel a folyamatlépéssel számos kisebb csomópontot használhat a feladat párhuzamos végrehajtásához, ami lehetővé teszi a horizontális skálázást. A párhuzamosításnak azonban van egy többlettere. A számítási feladattól és az elérhető párhuzamosság mértékétől függően előfordulhat, hogy a párhuzamos futtatási lépés lehetőség vagy sem.
Számítási példány méretének meghatározása
Interaktív fejlesztéshez ajánlott az Azure Machine Learning számítási példánya. A számítási példány (CI) ajánlat egyetlen csomópontos számítást hoz létre, amely egyetlen felhasználóhoz van kötve, és felhőalapú munkaállomásként használható.
Egyes szervezetek nem engedélyezik az éles adatok használatát a helyi munkaállomásokon, korlátozásokat léptetnek életbe a munkaállomás-környezetben, vagy korlátozzák a csomagok és függőségek telepítését a vállalati informatikai környezetben. A számítási példányok munkaállomásként használhatók a korlátozás leküzdéséhez. Biztonságos környezetet kínál éles adatokhoz való hozzáféréssel, és olyan képeken fut, amelyek népszerű csomagokkal és eszközökkel rendelkeznek az előre telepített adatelemzéshez.
A számítási példány futtatásakor a rendszer a virtuálisgép-számításért, a standard Load Balancer (beleértve a lb/kimenő szabályokat és a feldolgozott adatokat), az operációsrendszer-lemezért (Prémium SSD által felügyelt P10-lemez), az ideiglenes lemezért (az ideiglenes lemez típusa a kiválasztott virtuális gép méretétől függ) és a nyilvános IP-címért kell fizetnie. A költségek megtakarítása érdekében javasoljuk, hogy a felhasználók fontolja meg a következőket:
- Indítsa el és állítsa le a számítási példányt, ha nincs használatban.
- A számítási példányon tárolt adatok mintájának használata és a számítási fürtökre való felskálázás a teljes adatkészlettel való együttműködéshez
- Kísérletezési feladatok elküldése helyi számítási cél módban a számítási példányon a fejlesztés vagy tesztelés során, vagy amikor a feladatok teljes körű elküldésekor megosztott számítási kapacitásra vált. Például számos korszak, teljes adatkészlet és hiperparaméteres keresés.
Ha leállítja a számítási példányt, az leállítja a virtuális gép számítási óráinak, ideiglenes lemezeinek és standard Load Balancer feldolgozott adatok költségeinek számlázását. Vegye figyelembe, hogy a felhasználó továbbra is fizet az operációsrendszer-lemezért, és standard Load Balancer a számítási példány leállítása esetén is tartalmaz lb/outbound szabályokat. Az operációsrendszer-lemezen mentett adatok a leállások és újraindítások során megmaradnak.
A kiválasztott virtuális gép méretének finomhangolása a számítási kihasználtság monitorozásával
Az Azure Machine Learning számítási használatára és kihasználtságára vonatkozó információkat az Azure Monitoron keresztül tekintheti meg. Megtekintheti a modell üzembe helyezésének és regisztrációjának részleteit, a kvóta részleteit, például az aktív és tétlen csomópontokat, a futtatási adatokat, például a megszakított és befejezett futtatásokat, valamint a GPU- és CPU-kihasználtság számítási kihasználtságát.
A figyelési adatokból származó megállapítások alapján jobban megtervezheti vagy módosíthatja az erőforrás-használatot a csapatban. Ha például az elmúlt héten sok tétlen csomópontot észlelt, a megfelelő munkaterület-tulajdonosokkal együttműködve frissítheti a számítási fürt konfigurációját, hogy ezzel megelőzze ezt a többletköltséget. A kihasználtsági minták elemzésének előnyei segíthetnek a költségek előrejelzésében és a költségvetés javításában.
Ezeket a metrikákat közvetlenül a Azure Portal érheti el. Nyissa meg az Azure Machine Learning-munkaterületet, és válassza a metrikák lehetőséget a bal oldali panel monitorozási szakaszában. Ezután kiválaszthatja a megtekinteni kívánt adatok részleteit, például a metrikákat, az összesítést és az időtartamot. További információ: Az Azure Machine Learning monitorozása dokumentációs oldal.
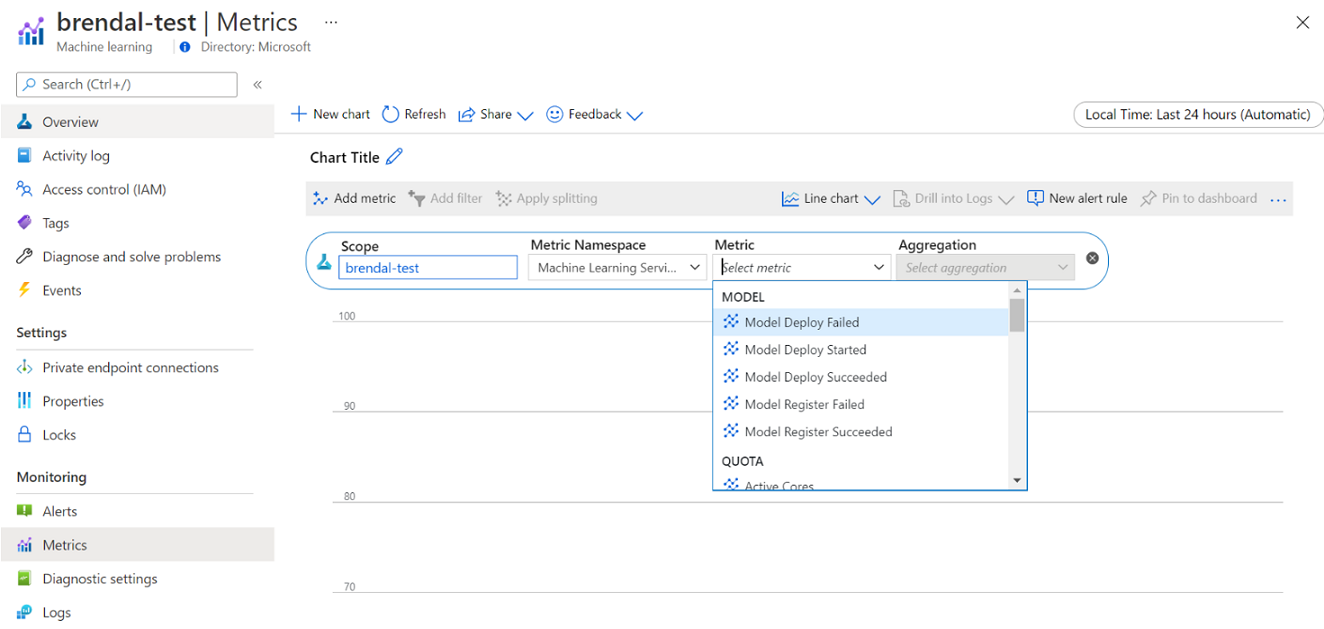
Váltás helyi, egycsomópontos és többcsomópontos felhőbeli számítás között fejlesztés közben
A gépi tanulási életciklus során különböző számítási és eszközhasználati követelmények vonatkoznak. Az Azure Machine Learning egy SDK- és CLI-felületen keresztül illeszthető össze gyakorlatilag bármilyen előnyben részesített munkaállomás-konfigurációból, hogy megfeleljen ezeknek a követelményeknek.
A költségek és a hatékony munkavégzés érdekében a következőket javasoljuk:
- Klónozza helyileg a kísérletezési kódbázist a Git használatával, és küldje el a feladatokat a felhőbeli számításba az Azure Machine Learning SDK vagy a PARANCSSOR használatával.
- Ha az adathalmaz nagy, fontolja meg az adatok mintájának kezelését a helyi munkaállomáson, miközben a teljes adatkészletet a felhőbeli tárolóban tartja.
- Paraméterezheti a kísérletezési kódbázist, hogy a feladatok különböző számú alapidőszakban vagy különböző méretű adathalmazokon fussanak.
- Ne írja be az adathalmaz mappaelérési útját. Ezután egyszerűen újra felhasználhatja ugyanazt a kódbázist különböző adathalmazokkal, valamint helyi és felhőbeli végrehajtási környezetben.
- Indítsa el a kísérletezési feladatokat a helyi számítási cél módban a fejlesztés vagy tesztelés során, vagy amikor megosztott számítási fürtkapacitásra vált, amikor teljes léptékű feladatokat küld be.
- Ha az adathalmaz nagy, használja a helyi vagy számítási példány munkaállomásán található adatok mintáját, miközben az Azure Machine Learningben felhőbeli számításra skálázva a teljes adatkészlettel dolgozhat.
- Ha a feladatok végrehajtása hosszú időt vesz igénybe, érdemes lehet optimalizálni a kódbázist az elosztott betanításhoz, hogy lehetővé tegye a horizontális felskálázást.
- Tervezheti meg az elosztott betanítási számítási feladatokat a csomópontok rugalmassága érdekében, hogy rugalmasan használhassa az egycsomópontos és több csomópontos számításokat, és megkönnyítse az előre felosztható számítási feladatok használatát.
Számítási típusok kombinálása Azure Machine Learning-folyamatokkal
A gépi tanulási munkafolyamatok vezénylésekor több lépésből is meghatározhat egy folyamatot. A folyamat minden lépése a saját számítási típusán futtatható. Ez lehetővé teszi a teljesítmény és a költségek optimalizálását a gépi tanulási életciklus különböző számítási követelményeinek megfelelően.
A csapat költségvetésének legjobb kihasználása
Bár a költségvetés-felosztási döntések nem feltétlenül befolyásolják az egyes csapatokat, a csapatok általában a legjobb igényeiknek megfelelően használhatják fel a kiosztott költségvetést. A feladatok prioritásának és a teljesítménynek és a költségeknek a figyelembe adásával a csapatok magasabb fürtkihasználtságot érhetnek el, alacsonyabb összköltséget érhetnek el, és ugyanabból a költségvetésből több számítási órát használhatnak. Ez fokozhatja a csapat hatékonyságát.
A megosztott számítási erőforrások költségeinek optimalizálása
A megosztott számítási erőforrások költségeinek optimalizálásának kulcsa annak biztosítása, hogy azok a teljes kapacitásukhoz legyenek felhasználva. Íme néhány tipp a megosztott erőforrás költségeinek optimalizálásához:
- Számítási példányok használatakor csak akkor kapcsolja be őket, ha rendelkezik végrehajtandó kóddal. Állítsa le őket, ha nem használják őket.
- Számítási fürtök használatakor állítsa a csomópontok minimális számát 0-ra, a csomópontok maximális számát pedig a költségvetési korlátozások alapján kiértékelt számra. Az Azure díjkalkulátorával kiszámíthatja a kiválasztott virtuálisgép-termékváltozat egy virtuálisgép-csomópontjának teljes kihasználtságát. Az automatikus skálázás leskálázza az összes számítási csomópontot, ha senki sem használja. Csak azoknak a csomópontoknak a száma lesz vertikálisan felskálázva, amelyekhez költségvetése van. Az automatikus skálázást az összes számítási csomópont vertikális leskálázásához konfigurálhatja.
- Monitorozza az erőforrás-kihasználtságot, például a CPU-kihasználtságot és a GPU-kihasználtságot a betanítási modellek során. Ha az erőforrások nincsenek teljesen kihasználva, módosítsa a kódot az erőforrások jobb kihasználása érdekében, vagy méretezze le kisebb vagy olcsóbb virtuálisgép-méretekre.
- Értékelje ki, hogy létrehozhat-e megosztott számítási erőforrásokat a csapat számára, hogy elkerülje a fürtskálázási műveletek által okozott számítási hatékonysági hiányosságokat.
- Optimalizálja a számítási fürt automatikus skálázási időtúllépési szabályzatait a használati metrikák alapján.
- A munkaterületkvóták használatával szabályozhatja, hogy az egyes munkaterületek mennyi számítási erőforráshoz férhetnek hozzá.
Ütemezési prioritás bevezetése több virtuálisgép-termékváltozat fürtjeinek létrehozásával
A kvóta- és költségvetési korlátozások mellett eljárva a csapatnak le kell cserélnie a feladatok időben történő végrehajtását a költségek helyett, hogy a fontos feladatok időben fussanak, és a költségvetést a lehető legjobb módon használják fel.
A legjobb számítási kihasználtság támogatása érdekében javasoljuk, hogy a csapatok különböző méretű, alacsony prioritású és dedikált virtuálisgép-prioritású fürtöket hozzanak létre. Az alacsony prioritású számítások többletkapacitást használnak az Azure-ban, ezért kedvezményes díjszabással járnak. Hátránya, hogy ezeket a gépeket bármikor elő lehet venni, amikor egy magasabb prioritású kérés érkezik.
A különböző méretű és prioritású fürtök használatával bevezethető az ütemezési prioritás fogalma. Ha például a kísérleti és éles feladatok ugyanazon NC GPU-kvótáért versenyeznek, előfordulhat, hogy egy éles feladatnak előnyben kell részesítenie a kísérleti feladat futtatását. Ebben az esetben futtassa az éles feladatot a dedikált számítási fürtön, és a kísérleti feladatot az alacsony prioritású számítási fürtön. Ha a kvóta rövid lesz, a kísérleti feladat az éles feladat előnyére válik.
A virtuálisgép-prioritás mellett érdemes lehet feladatokat futtatni különböző virtuálisgép-termékváltozatokon. Előfordulhat, hogy egy feladat végrehajtása hosszabb időt vesz igénybe egy P40 GPU-val rendelkező virtuálisgép-példányon, mint a V100 GPU-n. Mivel azonban előfordulhat, hogy a V100 virtuálisgép-példányok foglaltak vagy a kvóta teljes mértékben használatban van, a P40-ben a befejezési idő a feladat átviteli sebességének szempontjából továbbra is gyorsabb lehet. Költségkezelési szempontból érdemes lehet alacsonyabb prioritású feladatokat futtatni a kevésbé teljesítő és olcsóbb virtuálisgép-példányokon.
Futtatás korai leállítása, ha a betanítás nem konvergál
Ha folyamatosan kísérletezik egy modell alapkonfigurációjának továbbfejlesztésével, előfordulhat, hogy különböző kísérletfuttatásokat futtat, mindegyiket kissé eltérő konfigurációkkal. Egy futtatás esetén módosíthatja a bemeneti adatkészleteket. Egy másik futtatás esetén előfordulhat, hogy módosítja a hiperparamétert. Nem minden módosítás lehet olyan hatékony, mint a másik. Korán észleli, hogy egy módosítás nem volt a kívánt hatással a modell betanításának minőségére. Annak észleléséhez, hogy a betanítás nem konvergál-e, monitorozza a betanítási folyamatot a futtatás során. Például a teljesítménymetrikák naplózásával az egyes betanítási korszakok után. Fontolja meg a feladat korai leállítását, hogy erőforrásokat és költségvetést szabadítson fel egy másik próbaverzióhoz.
Költségvetések, költségek és kvóta megtervezése, kezelése és megosztása
Ahogy egy szervezet egyre több gépi tanulási használati esetet és csapatot használ, az informatikai és pénzügyi fejlettség növelését, valamint az egyes gépi tanulási csapatok közötti koordinációt igényli a hatékony üzemeltetés biztosítása érdekében. A vállalati szintű kapacitás- és kvótakezelés fontossá válik a számítási erőforrások szűkösségének kezelése és a felügyeleti többletterhelés leküzdése érdekében.
Ez a szakasz a költségvetések, költségek és kvóta nagyvállalati szintű tervezésére, kezelésére és megosztására vonatkozó ajánlott eljárásokat ismerteti. Ez a microsoftos gépi tanuláshoz szükséges számos GPU-betanítási erőforrás kezelésének elsajátításán alapul.
Az erőforrás-költségek ismertetése az Azure Machine Learning használatával
A számítási igények megtervezése rendszergazdaként az egyik legnagyobb kihívást az új, az alapterv becsléseként előzményadatok nélküli újítások jelentik. Gyakorlati szempontból a legtöbb projekt első lépésként kis költségvetésből indul ki.
Annak megértéséhez, hogy hol tart a költségvetés, fontos tudni, hogy az Azure Machine Learning költségei honnan származnak:
- Az Azure Machine Learning csak a felhasznált számítási infrastruktúráért számít fel díjat, és nem számol fel díjat a számítási költségekért.
- Az Azure Machine Learning-munkaterület létrehozásakor további erőforrások is létrejönnek az Azure Machine Learning engedélyezéséhez: Key Vault, Application Insights, Azure Storage és Azure Container Registry. Ezeket az erőforrásokat az Azure Machine Learningben használják, és fizetnie kell ezekért az erőforrásokért.
- A felügyelt számításokkal kapcsolatos költségek, például a betanítási fürtök, a számítási példányok és a felügyelt következtetési végpontok. Ezekkel a felügyelt számítási erőforrásokkal a következő infrastruktúraköltségeket kell figyelembe venni: virtuális gépek, virtuális hálózat, terheléselosztó, sávszélesség és tárolás.
Költségminták nyomon követése és jobb jelentéskészítés címkézéssel
A rendszergazdák gyakran szeretnék nyomon követni a különböző erőforrások költségeit az Azure Machine Learningben. A címkézés természetes megoldás erre a problémára, és összhangban van az Azure és számos más felhőszolgáltató által használt általános megközelítéssel. A címkék támogatásával mostantól a számítási szinten láthatja a költséglebontást, így részletesebb nézetet biztosíthat a jobb költségmonitorozáshoz, a jobb jelentéskészítéshez és a nagyobb átláthatósághoz.
A címkézés lehetővé teszi, hogy testre szabott címkéket helyezzen el a munkaterületeken és a számításokban (az Azure Resource Manager-sablonokból és Azure Machine Learning stúdió), hogy tovább szűrje ezeket az erőforrásokat az Azure Cost Managementben ezen címkék alapján a költési minták megfigyeléséhez. Ez a funkció a legjobban a belső költséghelyi elszámoláshoz használható. Emellett a címkék hasznosak lehetnek a számításhoz kapcsolódó metaadatok vagy részletek rögzítéséhez, például projekthez, csapathoz, bizonyos számlázási kódhoz stb. Ez nagyon hasznossá teszi a címkézést annak mérésére, hogy mennyi pénzt költ a különböző erőforrásokra, és így mélyebb betekintést nyerhet a költségekbe, és a csapatok vagy projektek közötti költési mintákba nyerhet mélyebb betekintést.
Vannak olyan rendszerbe ágyazott címkék is, amelyek lehetővé teszik, hogy a Költségelemzés oldalon a "Számítás típusa" címke alapján szűrjön, így megtekintheti a teljes költség számításalapú lebontását, és meghatározhatja, hogy a számítási erőforrások mely kategóriája lehet a költségek többségének tulajdonítható. Ez különösen akkor hasznos, ha jobban átlátja a betanítást és a következtetési költségmintákat.
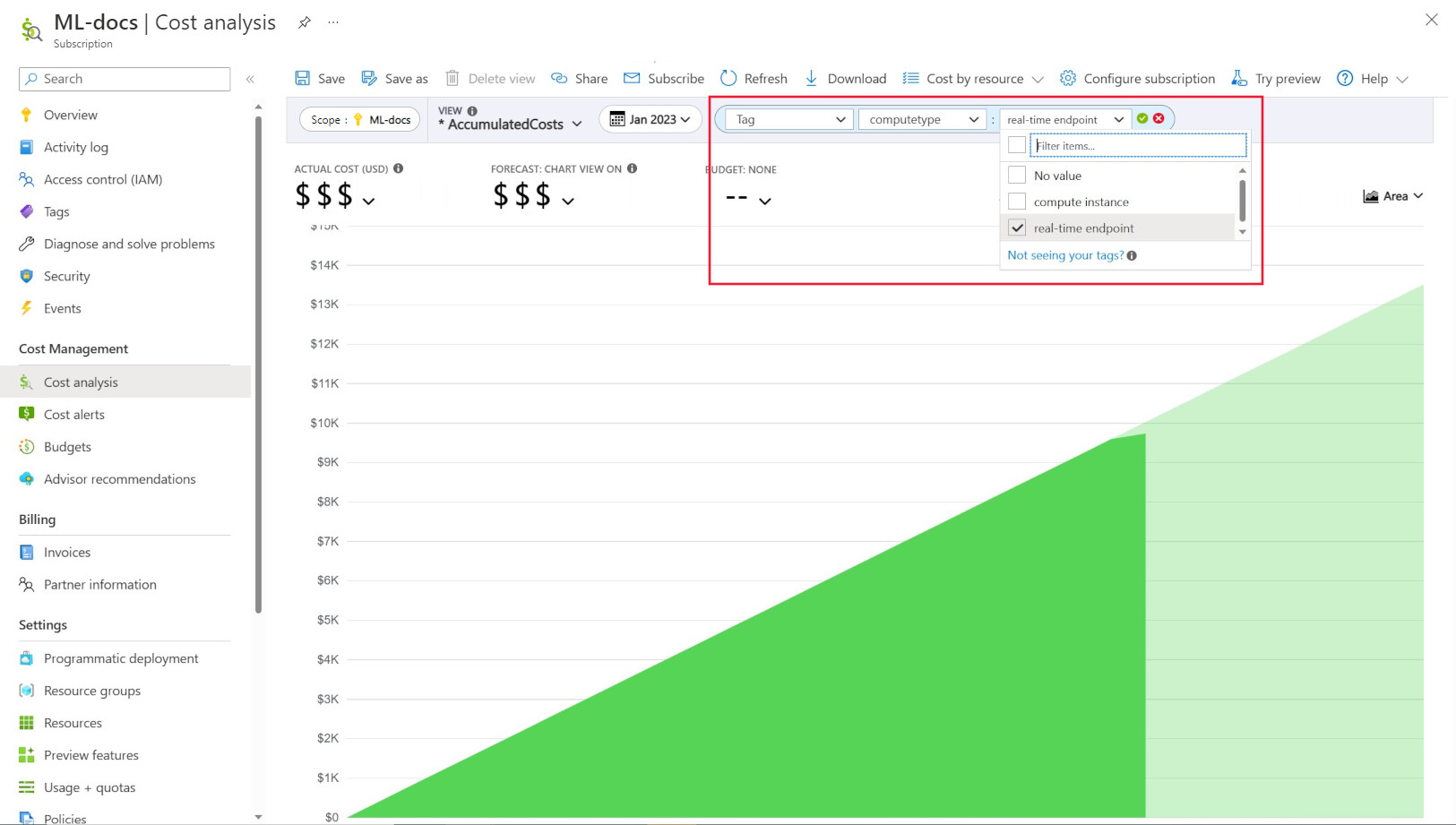
A számítási használat szabályozása és korlátozása szabályzat szerint
Ha sok számítási feladattal rendelkező Azure-környezetet kezel, kihívást jelenthet az erőforrás-költségek áttekintése. Azure Policy segíthet az erőforrás-kiadások szabályozásában és szabályozásában azáltal, hogy bizonyos használati mintákat korlátoz az Azure-környezetben.
Az Azure Machine Learning esetében azt javasoljuk, hogy olyan szabályzatokat állítson be, amelyek csak adott virtuálisgép-termékváltozatok használatát teszik lehetővé. A szabályzatok segíthetnek megelőzni és szabályozni a költséges virtuális gépek kiválasztását. A szabályzatok az alacsony prioritású virtuálisgép-termékváltozatok használatának kényszerítésére is használhatók.
Kvóta lefoglalása és kezelése üzleti prioritás alapján
Az Azure lehetővé teszi, hogy korlátokat állítson be a kvótaelosztáshoz az előfizetés és az Azure Machine Learning-munkaterület szintjén. Ha az Azure szerepköralapú hozzáférés-vezérléssel (RBAC) korlátozza, hogy ki kezelheti a kvótát, az segíthet biztosítani az erőforrás-kihasználtságot és a költségek kiszámíthatóságát.
A GPU-kvóta rendelkezésre állása az előfizetések között szűkös lehet. A számítási feladatok magas kvótakihasználtságának biztosítása érdekében javasoljuk, hogy ellenőrizze, hogy a kvóta a legjobban használható-e, és a számítási feladatok között van-e hozzárendelve.
A Microsoftnál rendszeres időközönként meg van határozva, hogy a gpu-kvótákat a legjobban a gépi tanulási csapatok használják-e fel és osztják-e ki az üzleti prioritásnak megfelelő kapacitásigények kiértékelésével.
Kapacitás véglegesítése előre
Ha jó becsléssel rendelkezik arról, hogy a következő évben vagy a következő néhány évben mennyi számítási erőforrás lesz felhasználva, kedvezményes áron vásárolhat Azure Reserved VM Instances-példányokat. Egyéves vagy hároméves vásárlási feltételek vannak. Mivel az Azure-beli fenntartott virtuálisgép-példányok kedvezményesek, a használatalapú fizetéshez képest jelentős költségmegtakarítás érhető el.
Az Azure Machine Learning támogatja a fenntartott számítási példányokat. A rendszer automatikusan alkalmazza a kedvezményeket az Azure Machine Learning által felügyelt számítási feladatokra.
Adatmegőrzés kezelése
Minden alkalommal, amikor egy gépi tanulási folyamat végrehajtása történik, minden egyes folyamatlépésnél köztes adathalmazok hozhatók létre az adat-gyorsítótárazás és -újrafelhasználás érdekében. Ezeknek a gépi tanulási folyamatoknak a kimeneteként történő adatnövekedés fájdalmas ponttá válhat egy olyan szervezet számára, amely számos gépi tanulási kísérletet futtat.
Az adatelemzők általában nem töltik az idejüket a létrehozott köztes adathalmazok törlésére. Idővel a létrehozott adatok mennyisége összeadódik. Az Azure Storage képes fokozni az adatéletciklusok kezelését. Az életciklus-felügyelet Azure Blob Storage használatával általános szabályzatokat állíthat be a nem használt adatok hidegebb tárolási szintekre való áthelyezéséhez és a költségek megtakarításához.
Infrastruktúraköltség-optimalizálási szempontok
Hálózatkezelés
Az Azure hálózatkezelési költségei az Azure-adatközpontból kimenő sávszélesség miatt merülnek fel. Az Azure-adatközpontba irányuló összes bejövő adat ingyenes. A hálózati költségek csökkentésének kulcsa, hogy minden erőforrást ugyanabban az adatközpont-régióban helyezzen üzembe, amikor csak lehetséges. Ha az Azure Machine Learning-munkaterületet és a számítást ugyanabban a régióban helyezheti üzembe, amelyben az adatai vannak, alacsonyabb költségek és nagyobb teljesítmény érhető el.
Érdemes lehet privát kapcsolatot létesíteni a helyszíni hálózat és az Azure-hálózat között, hogy hibrid felhőkörnyezettel rendelkezzen. Az ExpressRoute ezt lehetővé teszi, de figyelembe véve az ExpressRoute magas költségeit, költséghatékonyabb lehet a hibrid felhők beállításától való eltávolodás és az összes erőforrás áthelyezése az Azure-felhőbe.
Azure Container Registry
A Azure Container Registry a költségoptimalizálás meghatározó tényezői a következők:
- A Docker-rendszerképek tárolóregisztrációs adatbázisból az Azure Machine Learningbe való letöltéséhez szükséges átviteli sebesség
- A vállalati biztonsági funkciókra, például a Azure Private Link
Olyan éles helyzetekben, ahol magas átviteli sebességre vagy vállalati biztonságra van szükség, a Azure Container Registry prémium termékváltozata ajánlott.
Olyan fejlesztési/tesztelési forgatókönyvek esetén, ahol az átviteli sebesség és a biztonság kevésbé kritikus, standard termékváltozatot vagy prémium termékváltozatot javasoljuk.
A Azure Container Registry alapszintű termékváltozata nem ajánlott az Azure Machine Learninghez. Ez nem ajánlott az alacsony átviteli sebesség és az alacsony belefoglalt tárterület miatt, amelyet az Azure Machine Learning viszonylag nagy méretű (1+ GB) Docker-lemezképei gyorsan túlléphetnek.
Fontolja meg a számítási típus rendelkezésre állását az Azure-régiók kiválasztásakor
Amikor régiót választ a számításhoz, tartsa szem előtt a számítási kvóta rendelkezésre állását. A népszerű és nagyobb régiók, mint például az USA keleti régiója, az USA nyugati régiója és Nyugat-Európa általában magasabb alapértelmezett kvótaértékekkel és a legtöbb CPU és GPU nagyobb rendelkezésre állásával rendelkezik, mint néhány más régióban, ahol szigorúbb kapacitáskorlátozások vannak érvényben.
Tudjon meg többet
Következő lépések
Az Azure Machine Learning-környezetek rendszerezéséről és beállításáról további információt az Azure Machine Learning-környezetek rendszerezése és beállítása című témakörben talál.
A Machine Learning DevOps és az Azure Machine Learning ajánlott eljárásainak megismeréséhez tekintse meg a Machine Learning DevOps útmutatóját.