Beszélgetési nyelvfelismerési modell betanítása
Miután befejezte a kimondott szövegek címkézését, megkezdheti a modell betanítását. A betanítás az a folyamat, amelyben a modell tanul a címkézett kimondott szövegekből.
Modell betanításához kezdjen el egy betanítási feladatot. Csak a sikeresen befejezett feladatok hoznak létre modellt. A betanítási feladatok hét nap után lejárnak, ezután már nem fogja tudni lekérni a feladat részleteit. Ha a betanítási feladat sikeresen befejeződött, és létrejött egy modell, a feladat lejáró feladata nem lesz hatással rá. Egyszerre csak egy betanítási feladat futhat, és nem indíthat el más feladatokat ugyanabban a projektben.
A betanítási idő akár néhány másodpercig is eltarthat, amikor egyszerű projekteket kezel, akár néhány óráig is, amikor eléri a kimondott szövegek maximális korlátját .
A modell kiértékelése automatikusan aktiválódik a betanítás sikeres befejezése után. A kiértékelési folyamat a betanított modell használatával kezdődik, amely előrejelzéseket futtat a tesztelési csoportban lévő kimondott szövegeken, és összehasonlítja az előrejelzett eredményeket a megadott címkékkel (amelyek az igazság alapkonfigurációját állapítják meg).
Előfeltételek
- Sikeresen létrehozott projekt egy konfigurált Azure Blob Storage-fiókkal
- Címkézett kimondott szövegek
Betanítási adatok kiegyensúlyozása
A betanítási adatokkal kapcsolatban érdemes megpróbálni egyensúlyban tartani a sémát. Ha nagy mennyiségű szándékot is beleszámítottunk, a másikból nagyon kevés olyan modellt eredményez, amely erősen elfogult az adott szándékokkal szemben.
Ennek megoldásához előfordulhat, hogy le kell állítania a betanítási készletet, vagy hozzá kell adnia. A lecsúszást a következőkkel végezheti el:
- A betanítási adatok bizonyos százalékától véletlenszerűen megszabadulni.
- Szisztematikusabb módon elemezheti az adathalmazt, és eltávolíthatja a túlreprezentált ismétlődő bejegyzéseket.
A betanítási készlethez a Language Studio Adatcímkézés lapján a Kimondott szövegek ajánlása lehetőséget választva is hozzáadhatja. A beszélgetési Language Understanding hívást küldenek az Azure OpenAI-nak hasonló beszédelemek létrehozásához.

A betanítási készletben nem kívánt "mintákat" is meg kell keresnie. Ha például egy adott szándék betanítási készlete kisbetűs, vagy egy adott kifejezéssel kezdődik. Ilyen esetekben előfordulhat, hogy a betanított modell ezeket a nem kívánt torzításokat a betanítási készletben tanulja meg ahelyett, hogy általánosíthatná őket.
Javasoljuk, hogy a betanítási készletben vezesse be a burkolatok és írásjelek sokféleségét. Ha a modell várhatóan kezeli a variációkat, győződjön meg arról, hogy rendelkezik egy olyan betanítási készlettel, amely szintén tükrözi ezt a sokféleséget. Adjon meg például néhány kimondott szöveget a megfelelő szövegbe, néhányat pedig kisbetűkbe.
Adatok felosztása
A betanítási folyamat megkezdése előtt a projektben a címkézett beszédelemek betanítási és tesztelési készletre vannak osztva. Mindegyik más-más funkciót szolgál. A betanítási készlet a modell betanításához használatos. Ez az a készlet, amelyből a modell megtanulja a címkézett kimondott szövegeket. A tesztelési készlet egy olyan vakkészlet, amely nem a betanítás során, hanem csak az értékelés során kerül bevezetésre a modellbe.
A modell sikeres betanítása után a modell használatával előrejelzéseket készíthet a tesztelési csoportban lévő kimondott szövegekből. Ezek az előrejelzések a kiértékelési metrikák kiszámítására szolgálnak. Ajánlott gondoskodni arról, hogy az összes szándék és entitás megfelelően szerepeljen a betanítási és tesztelési készletben.
A társalgási nyelvfelismerés két módszert támogat az adatfelosztáshoz:
- A tesztelési készlet automatikus felosztása a betanítási adatokból: A rendszer a kiválasztott százalékos arányoknak megfelelően felosztja a címkézett adatokat a betanítási és a tesztelési készletek között. Az ajánlott százalékos felosztás 80% a betanításhoz és 20% teszteléshez.
Megjegyzés
Ha a Tesztelési csoport automatikus felosztása a betanítási adatokból beállítást választja, csak a betanítási készlethez rendelt adatok lesznek felosztva a megadott százalékos értékek szerint.
- Betanítási és tesztelési adatok manuális felosztása: Ez a módszer lehetővé teszi a felhasználók számára, hogy meghatározzák, mely kimondott szövegek melyik készlethez tartoznak. Ez a lépés csak akkor engedélyezett, ha kimondott szövegeket adott hozzá a tesztelési csoporthoz a címkézés során.
Betanítási módok
A CLU két módot támogat a modellek betanításához
A standard betanítás gyors gépi tanulási algoritmusokat használ a modellek viszonylag gyors betanításához. Ez jelenleg csak angol nyelven érhető el, és le van tiltva minden olyan projekt esetében, amely nem használja elsődleges nyelvként az angolt (USA) vagy az angolt (UK). Ez a betanítási lehetőség ingyenes. A standard betanítás lehetővé teszi kimondott szövegek hozzáadását és gyors tesztelését díjmentesen. A megjelenített értékelési pontszámok alapján megtudhatja, hogy hol végezhet módosításokat a projektben, és további kimondott szövegeket adhat hozzá. Miután néhányszor iterált, és növekményes fejlesztéseket hajtott végre, fontolja meg a speciális betanítás használatát a modell egy másik verziójának betanításához.
A speciális betanítás a gépi tanulási technológia legújabb verziójával szabja testre a modelleket az adataival. Ez várhatóan jobb teljesítményt mutat a modellekhez, és lehetővé teszi a CLU többnyelvű funkcióinak használatát is. A speciális képzés ára eltérő. A részletekért tekintse meg a díjszabással kapcsolatos információkat .
A kiértékelési pontszámokkal irányíthatja a döntéseket. Előfordulhat, hogy egy adott példát helytelenül jeleznek előre a speciális betanításban, szemben a normál betanítási móddal. Ha azonban az általános kiértékelési eredmények jobbak a fejlett használatban, akkor ajánlott a végső modellt használni. Ha nem ez a helyzet, és nem szeretne többnyelvű képességeket használni, továbbra is használhatja a standard módban betanított modellt.
Megjegyzés
A betanítási módok közötti szándékbizalmassági pontszámok viselkedésében eltérést kell látnia, mivel az egyes algoritmusok eltérően kalibrálják a pontszámukat.
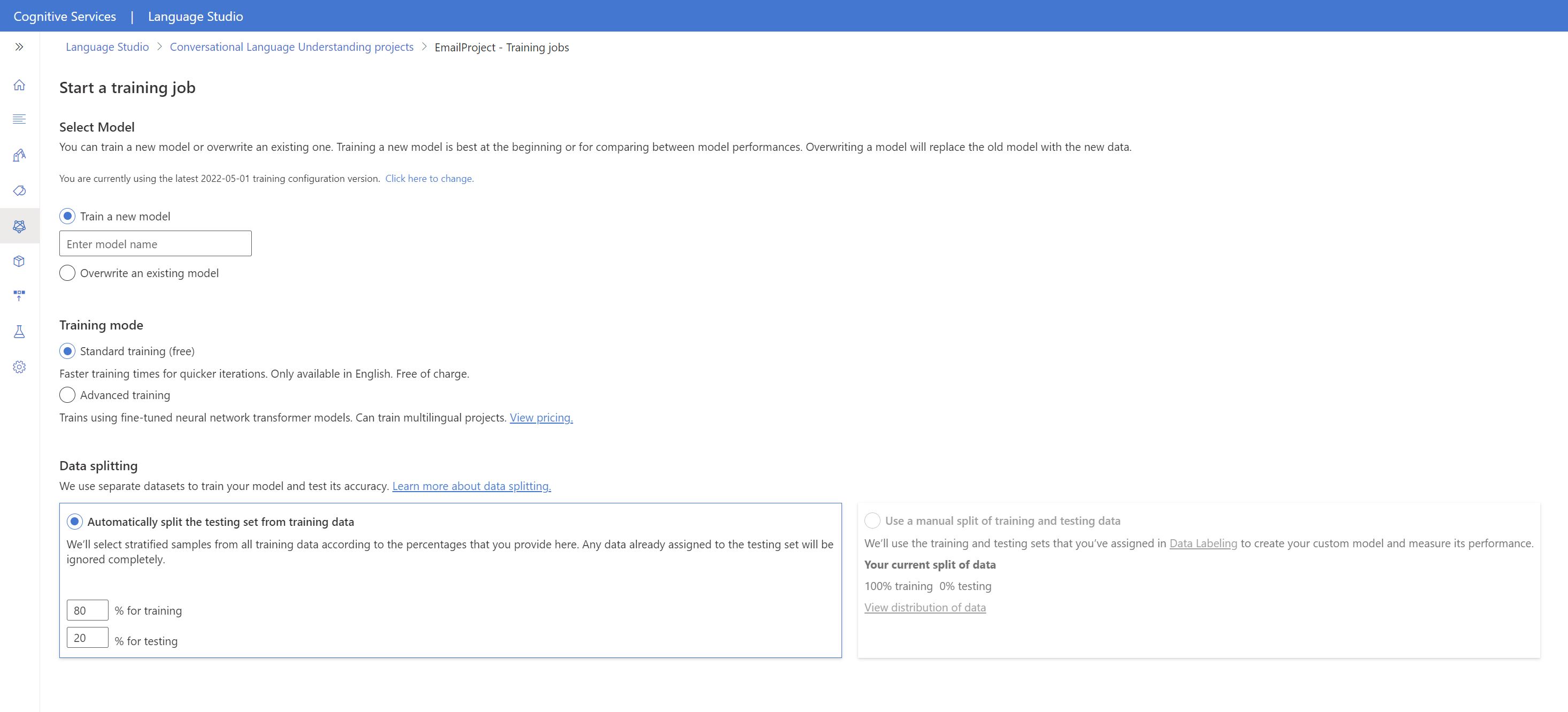
Modell betanítása
A modell betanítása a Language Studióban:
A bal oldali menüben válassza a Modell betanítása lehetőséget.
A felső menüben válassza a Betanítási feladat indítása lehetőséget.
Válassza az Új modell betanítása lehetőséget, és írjon be egy új modellnevet a szövegmezőbe. Ha egy meglévő modellt az új adatokon betanított modellre szeretne cserélni, válassza a Meglévő modell felülírása lehetőséget, majd válasszon ki egy meglévő modellt. A betanított modellek felülírása visszafordíthatatlan, de az új modell üzembe helyezéséig nem lesz hatással az üzembe helyezett modellekre.
Válassza ki a betanítási módot. A gyorsabb betanításhoz választhatja a Standard képzést , de csak angol nyelven érhető el. Választhat speciális képzést is, amely más nyelvekhez és többnyelvű projektekhez is támogatott, de hosszabb betanítási időt igényel. További tudnivalók a betanítási módokról.
Válasszon ki egy adatfelosztási módszert. A tesztelési készlet automatikus felosztása betanítási adatokból lehetőséget választhatja, ahol a rendszer a megadott százalékos arányok szerint felosztja a kimondott szövegeket a betanítási és a tesztelési készletek között. Vagy használhatja a betanítási és tesztelési adatok manuális felosztását is, ez a beállítás csak akkor engedélyezett, ha kimondott szövegeket adott hozzá a tesztkészlethez a kimondott szövegek címkézésekor.
Válassza a Betanítása gombot.
Válassza ki a betanítási feladat azonosítóját a listából. Megjelenik egy panel, ahol ellenőrizheti a betanítási folyamatot, a feladat állapotát és a feladat egyéb részleteit.
Megjegyzés
- Csak a sikeres betanítási feladatok hoznak létre modelleket.
- A betanítás eltarthat néhány perc és néhány óra között a kimondott szövegek számától függően.
- Egyszerre csak egy betanítási feladat futtatható. Nem indíthat el más betanítási feladatokat ugyanabban a projektben, amíg a futó feladat be nem fejeződik.
- A modellek betanítása során használt gépi tanulás rendszeresen frissül. Ha egy korábbi konfigurációs verzióra szeretne betanítást végezni, válassza a Kiválasztás itt lehetőséget a betanítási feladat indítása lapon, és válasszon ki egy korábbi verziót.

Betanítási feladat megszakítása
Betanítási feladat megszakítása a Language Studióban
- A Modell betanítása lapon válassza ki a megszakítani kívánt betanítási feladatot, majd a felső menüben válassza a Mégse lehetőséget.