Egyéni fordító kezdőknek
A Custom Translator lehetővé teszi az üzleti, iparági és tartományspecifikus terminológiát és stílust tükröző fordítási rendszer kiépítését. Az egyéni rendszerek betanítása és üzembe helyezése egyszerű, és nem igényel programozási készségeket. A testreszabott fordítási rendszer zökkenőmentesen integrálható a meglévő alkalmazásokba, munkafolyamatokba és webhelyekbe, és ugyanazon felhőalapú Microsoft Text Translation API szolgáltatáson keresztül érhető el az Azure-ban, amely naponta több milliárd fordítást biztosít.
A platform lehetővé teszi, hogy a felhasználók egyéni fordítási rendszereket építsenek ki és tegyenek közzé angol nyelven. A Custom Translator több mint 60 nyelvet támogat, amelyek közvetlenül az NMT-hez elérhető nyelvekhez kapcsolódnak. A teljes listát a Translator nyelvi támogatásában találja.
Az egyéni fordítási modell a megfelelő választás számomra?
A jól betanított egyéni fordítási modell pontosabb tartományspecifikus fordításokat biztosít, mivel a korábban lefordított tartományon belüli dokumentumokra támaszkodik az előnyben részesített fordítások elsajátításához. A Translator ezeket a kifejezéseket és kifejezéseket a kontextusban használja, hogy folyékony fordításokat készítsen a célnyelven, miközben tiszteletben tartja a környezetfüggő nyelvtant.
A teljes egyéni fordítási modell betanítása jelentős mennyiségű adatot igényel. Ha nem rendelkezik legalább 10 000 mondatnyi korábban betanított dokumentumtal, nem fog tudni betanítani egy teljes nyelvű fordítási modellt. Azonban betanított egy csak szótáras modellt, vagy használhatja a Text Translation API-val elérhető kiváló minőségű, beépített fordításokat.
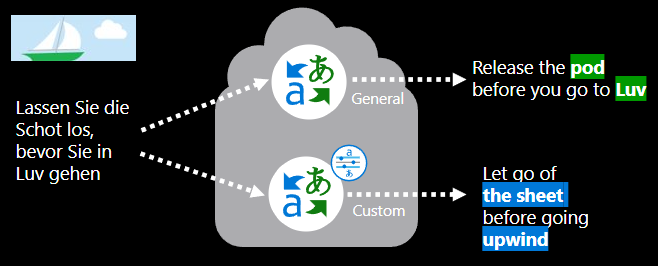
Mit jelent az egyéni fordítási modellek betanítása?
Egyéni fordítási modell létrehozásához a következőre van szükség:
A használati eset ismertetése.
A tartományon belüli lefordított adatok beszerzése (lehetőleg emberi fordítással).
A fordítási minőség vagy a célnyelvi fordítások értékelésének képessége.
Hogyan kiértékelni a használati esetemet?
A használat és a sikeresség első lépése a jártas betanítási adatok beszerzése. Íme néhány szempont:
Mi a kívánt eredmény, és hogyan fogja mérni?
Mi az üzleti tartománya?
Rendelkezik hasonló terminológiával és stílusú tartományon belüli mondatokkal?
A használati eset több tartományt is érint? Ha igen, létre kell hoznia egy fordítórendszert vagy több rendszert?
Vannak olyan követelmények, amelyek hatással vannak a inaktív és az átvitel alatt lévő regionális adatokra?
A célfelhasználók egy vagy több régióban vannak?
Hogyan kell forrásként használnom az adataimat?
A tartományon belüli minőségi adatok megkeresése gyakran kihívást jelentő feladat, amely a felhasználói besorolástól függően változik. Az alábbiakban néhány kérdést tehet fel magának, amikor kiértékeli, hogy milyen adatok érhetők el Ön számára:
A vállalatok gyakran rengeteg fordítási adattal rendelkeznek, amelyek sok év alatt halmozódtak fel az emberi fordítás használata során. Rendelkezik a vállalata korábbi fordítási adataival, amelyeket felhasználhat?
Rengeteg egynyelvű adata van? Az egynyelvű adatok csak egy nyelven lévő adatok. Ha igen, lekérheti az adatok fordítását?
Bejárhatja az online portálokat a forrásmondatok gyűjtéséhez és a célmondatok szintetizálásához?
Mit kell használnom a tananyagokhoz?
| Source | Művelet | Követendő szabályok |
|---|---|---|
| Kétnyelvű képzési dokumentumok | A rendszer terminológiáját és stílusát tanítja. | Legyen liberális. A tartományon belüli emberi fordítások jobbak, mint a gépi fordítások. Útközben is hozzáadhat és eltávolíthat dokumentumokat, és megpróbálhatja javítani a BLEU-pontszámot. |
| Dokumentumok hangolása | Beképzi a neurális gép fordítási paramétereit. | Legyen szigorú. Írjon nekik, hogy optimálisan reprezentatív, amit fog fordítani a jövőben. |
| Dokumentumok tesztelése | Számítsa ki a BLEU-pontszámot. | Legyen szigorú. A tesztdokumentumokat úgy kell összeállítani, hogy optimálisan reprezentálják azt, amit a jövőben le szeretne fordítani. |
| Kifejezésszótár | Az adott fordítást az idő 100%-ában kényszeríti. | Legyen korlátozó. A kifejezésszótár megkülönbözteti a kis- és nagybetűk használatát, és a felsorolt szavak vagy kifejezések a megadott módon lesznek lefordítva. Sok esetben jobb, ha nem használ kifejezésszótárat, és hagyja, hogy a rendszer tanuljon. |
| Mondatszótár | Az adott fordítást az idő 100%-ában kényszeríti. | Legyen szigorú. A mondatszótárak kis- és nagybetűket nem érzékenek, és a tartomány rövid mondataiban gyakran használják. Ahhoz, hogy egy mondatszótár egyezzen, a teljes beküldött mondatnak meg kell egyeznie a forrásszótár bejegyzésével. Ha a mondatnak csak egy része egyezik, a bejegyzés nem egyezik. |
Mi az a BLEU-pontszám?
A BLEU (kétnyelvű kiértékelési alapművelet) egy algoritmus, amely az egyik nyelvről a másikra lefordított szöveg pontosságát vagy pontosságát értékeli. A Custom Translator a BLEU metrikát használja a fordítás pontosságának egyik módjaként.
A BLEU-pontszám nulla és 100 közötti szám. A nulla pontszám alacsony minőségű fordítást jelez, ahol a fordításban semmi sem felelt meg a hivatkozásnak. A 100-es pontszám tökéletes fordítást jelez, amely megegyezik a hivatkozással. Nem szükséges 100-ból álló pontszámot elérni – a 40 és 60 közötti BLEU-pontszám kiváló minőségű fordítást jelez.
Mi történik, ha nem küldöm el a hangolási vagy tesztelési adatokat?
A mondatok finomhangolása és tesztelése optimálisan reprezentálja a jövőben lefordítandó szöveget. Ha nem küld el hangolási vagy tesztelési adatokat, a Custom Translator automatikusan kizárja a betanítási dokumentumokból a mondatokat, hogy hangolási és tesztelési adatokként használják.
| Rendszer által generált | Manuális kijelölés |
|---|---|
| Kényelmes. | Lehetővé teszi a jövőbeli igények finomhangolását. |
| Jó, ha tudja, hogy a betanítási adatok reprezentatívak a lefordítani kívánt adatokra. | Nagyobb szabadságot biztosít a betanítási adatok írásához. |
| A tartomány növekedésekor vagy zsugorításakor könnyen újra elvégezhető. | Több adatot és jobb tartománylefedettségeket tesz lehetővé. |
| Az egyes betanítási futtatásokat módosítja. | Statikus marad az ismétlődő betanítási futtatásoknál |
Hogyan dolgozzák fel a betanítási anyagokat a Custom Translator?
A betanításra való felkészüléshez a dokumentumok feldolgozási és szűrési lépések sorozatán mennek keresztül. Ezeket a lépéseket az alábbiakban ismertetjük. A szűrési folyamat ismerete segíthet megérteni a megjelenített mondatok számát, valamint azokat a lépéseket, amelyekkel betanítási dokumentumokat készíthet a Custom Translatorrel való betanításhoz.
Mondatok igazítása
Ha a dokumentum nem XLIFF, XLSX, TMX vagy ALIGN formátumban van, a Custom Translator egymáshoz igazítja a forrás- és céldokumentumok mondatonkénti mondatait. A Translator nem hajtja végre a dokumentumok igazítását – az ön elnevezési konvencióját követi, hogy a dokumentumok egyező dokumentumot találjanak a másik nyelven. A forrásszövegen belül a Custom Translator megpróbálja megtalálni a megfelelő mondatot a célnyelven. A dokumentumcímkéket, például a beágyazott HTML-címkéket használja az igazításhoz.
Ha nagy eltérést tapasztal a forrás- és céldokumentumok mondatainak száma között, előfordulhat, hogy a forrásdokumentum nem párhuzamos, vagy nem igazítható. A dokumentum mindkét oldalán nagy különbséggel (>10%) rendelkező mondatpárok garantálják a második pillantást annak érdekében, hogy valóban párhuzamosak legyenek.
Finomhangolási és tesztelési adatok kinyerése
Az adatok finomhangolása és tesztelése nem kötelező. Ha nem adja meg, a rendszer eltávolítja a megfelelő százalékot a betanítási dokumentumokból a hangoláshoz és teszteléshez. Az eltávolítás dinamikusan történik a betanítási folyamat részeként. Mivel ez a lépés a betanítás részeként történik, a feltöltött dokumentumokra nincs hatással. Az egyes adatkategóriák – betanítás, finomhangolás, tesztelés és szótár – utolsó használt mondatszámait a Modell részletei oldalon láthatja a betanítás sikeressége után.
Hosszszűrő
- Eltávolítja azokat a mondatokat, amelyen mindkét oldalon csak egy szó található.
- Eltávolítja a több mint 100 szót tartalmazó mondatokat mindkét oldalon. A kínai, a japán, a koreai kivételt képez.
- Eltávolítja a három karakternél kevesebb karakterből álló mondatokat. A kínai, a japán, a koreai kivételt képez.
- Eltávolítja a 2000 karakternél több karaktert tartalmazó mondatokat kínai, japán, koreai nyelven.
- Eltávolítja az 1%-nál kisebb alfanumerikus karaktereket tartalmazó mondatokat.
- Eltávolítja az 50-nél több szót tartalmazó szótárbejegyzéseket.
Üres terület
- Lecseréli a térközök tetszőleges sorozatát, beleértve a tabulátorokat és a CR/LF sorozatokat egyetlen szóköz karakterre.
- Eltávolítja a mondat kezdő vagy záró területét.
Mondat végi írásjelek
Több mondatvégi írásjelet cserél egyetlen példányra. Japán karakter normalizálása.
A teljes szélességű betűket és számjegyeket félszélességű karakterekké alakítja.
Nem kibontott XML-címkék
A nem kibontott címkéket feloldott címkékké alakítja át:
Címke Lesz < & Hadnagy; > & Gt; & & Amp; Érvénytelen karakterek
A Custom Translator eltávolítja az U+FFFD Unicode karaktert tartalmazó mondatokat. Az U+FFFD karakter sikertelen kódkonvertálást jelez.
Milyen lépéseket tegyek az adatok feltöltése előtt?
- Távolítsa el az érvénytelen kódolású mondatokat.
- Unicode-vezérlőkarakterek eltávolítása.
- Ha lehetséges, igazítsa a mondatokat (forrás–cél).
- Távolítsa el a forrás- és célnyelvekkel nem egyező forrás- és célmondatokat.
- Ha a forrás- és célmondatok vegyes nyelvekkel rendelkeznek, győződjön meg arról, hogy a nem lefordított szavak szándékosak, például szervezetek és termékek nevei.
- Javítsa ki a nyelvtani és tipográfiai hibákat, hogy ne tanítsa be ezeket a hibákat a modellbe.
- Bár a betanítási folyamat több mondatot tartalmazó forrás- és célvonalakat kezel, jobb, ha egy forrásmondat egy célmondatra van leképezve.
Hogyan kiértékelni az eredményeket?
A modell sikeres betanítása után megtekintheti a modell BLEU-pontszámát és az alapmodell BLEU-pontszámát a modell részleteinek oldalán. Ugyanazt a tesztadatkészletet használjuk a modell BLEU-pontszámának és az alapszintű BLEU-pontszámnak a létrehozásához. Ezek az adatok segítenek megalapozott döntést hozni arról, hogy melyik modell lenne jobb a használati esethez.