Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A KÖVETKEZŐKRE VONATKOZIK: ![]() Gremlin
Gremlin
Ez a cikk a gráfadatmodellek használatára vonatkozó javaslatokat tartalmaz. Ezek az ajánlott eljárások létfontosságúak a gráfadatbázis-rendszerek skálázhatóságának és teljesítményének az adatok fejlődésével való biztosításához. A hatékony adatmodell különösen fontos a nagy léptékű gráfok esetében.
Követelmények
Az útmutatóban ismertetett folyamat a következő feltételezéseken alapul:
- A problématérben lévő entitások azonosíthatók. Ezeket az entitásokat minden kéréshez atomi módon kell felhasználni. Más szóval az adatbázis-rendszer nem egyetlen entitás adatainak lekérésére szolgál több lekérdezési kérelemben.
- Ismeri az adatbázisrendszer olvasási és írási követelményeit . Ezek a követelmények vezetik a gráfadatmodellhez szükséges optimalizálást.
- Az Apache Tinkerpop tulajdonsággráf szabvány alapelvei jól érthetők.
Mikor van szükségem gráfadatbázisra?
A gráfadatbázis-megoldás optimálisan használható, ha az adattartományban lévő entitások és kapcsolatok az alábbi jellemzők bármelyikével rendelkeznek:
- Az entitások leíró kapcsolatokon keresztül kapcsolódnak egymáshoz . Ebben a forgatókönyvben az az előnye, hogy a kapcsolatok a tárolóban maradnak.
- Vannak ciklikus kapcsolatok vagy önreferenciális entitások. Ez a minta gyakran kihívást jelent a relációs vagy dokumentumadatbázisok használatakor.
- Az entitások között dinamikusan fejlődő kapcsolatok vannak. Ez a minta különösen a hierarchikus vagy faszerkezetű, többszintű adatokra alkalmazható.
- Az entitások között több-a-többhöz kapcsolat áll fenn.
- Az entitásokra és kapcsolatokra egyaránt vonatkoznak írási és olvasási követelmények.
Ha a fenti feltételek teljesülnek, a gráfadatbázis-megközelítés valószínűleg előnyökkel jár a lekérdezések összetettsége, az adatmodell méretezhetősége és a lekérdezési teljesítmény szempontjából.
A következő lépés annak meghatározása, hogy a gráf elemzési vagy tranzakciós célokra lesz-e használva. Ha a gráfot nagy számítási és adatfeldolgozási számítási feladatokhoz szánják, érdemes megvizsgálni a Cosmos DB Spark-összekötőt és a GraphX-kódtárat.
Gráfobjektumok használata
Az Apache Tinkerpop tulajdonsággráf szabványa két objektumtípust határoz meg: csúcsokat és éleket.
A gráfobjektumok tulajdonságainak ajánlott eljárásai a következők:
Feljegyzés
Az élekhez nincs szükség partíciókulcs-értékre, mivel a rendszer automatikusan hozzárendeli az értéket a forrás csúcsa alapján. További információ: Particionált gráf használata az Azure Cosmos DB-ben.
Entitás- és kapcsolatmodellezési irányelvek
Az alábbi irányelvek segítséget nyújtanak az Apache Gremlin-gráfadatbázishoz készült Azure Cosmos DB adatmodellezésének megközelítésében. Ezek az irányelvek feltételezik, hogy létezik egy adattartomány meglévő definíciója, és lekérdezi azt.
Feljegyzés
A következő lépések javaslatokként jelennek meg. Mielőtt éles üzemkésznek tekintené, ki kell értékelnie és tesztelnie kell a végső modellt. A javaslatok emellett az Azure Cosmos DB Gremlin API-implementációjára is vonatkoznak.
Csúcspontok és tulajdonságok modellezése
A gráfadatmodell első lépése, hogy minden azonosított entitást egy csúcsobjektumhoz rendel. Az összes entitás csúcsokra való egy-az-egyhez leképezésének kezdeti lépésnek kell lennie, és változhat.
Az egyik gyakori buktató az egyetlen entitás tulajdonságainak leképezése különálló csúcspontokként. Vegyük az alábbi példát, ahol ugyanazt az entitást két különböző módon ábrázoljuk:
Csúcspontokon alapuló tulajdonságok: Ebben a megközelítésben az entitás három különböző csúcsot és két élt használ a tulajdonságainak leírásához. Bár ez a megközelítés csökkentheti a redundanciát, növeli a modell összetettségét. A modell összetettségének növekedése további késést, lekérdezések összetettségét és számítási költségeket eredményezhet. Ez a modell a particionálással kapcsolatos kihívásokat is jelenthet.
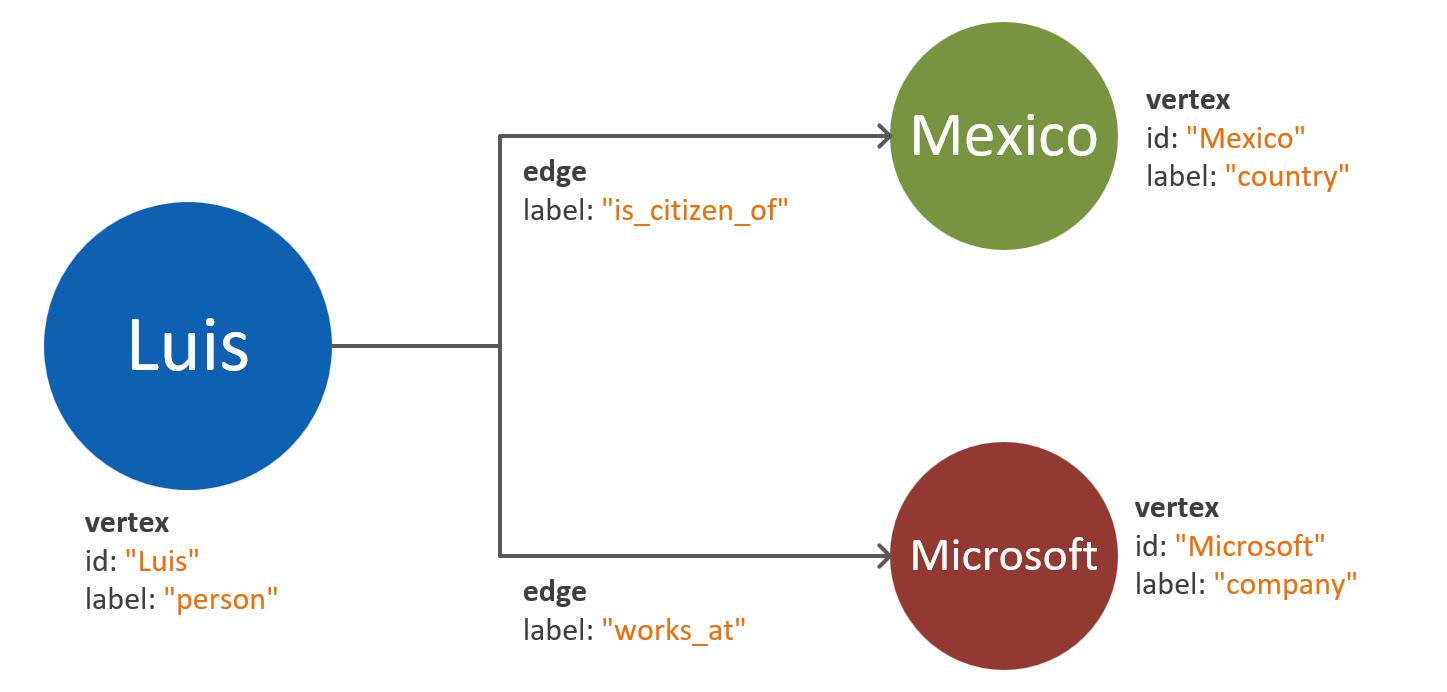
Tulajdonságba ágyazott csúcsok: Ez a megközelítés a kulcs-érték párok listájának előnyeit használja az entitás összes tulajdonságának megjelenítéséhez egy csúcsponton belül. Ez a megközelítés csökkenti a modell összetettségét, ami egyszerűbb lekérdezésekhez és költséghatékonyabb bejárásokhoz vezet.

Feljegyzés
Az előző diagramok egy egyszerűsített gráfmodellt mutatnak, amely csak az entitástulajdonságok megosztásának két módját hasonlítja össze.
A tulajdonságba ágyazott csúcsok mintázata általában hatékonyabb és skálázhatóbb megközelítést biztosít. Az új gráfadatmodell alapértelmezett megközelítésének ehhez a mintához kell gravitálnia.
Vannak azonban olyan helyzetek, amikor egy tulajdonságra való hivatkozás előnyt jelenthet. Ha például a hivatkozott tulajdonság gyakran frissül. Használjon egy külön csúcspontot egy olyan tulajdonság ábrázolásához, amely folyamatosan változik a frissítéshez szükséges írási műveletek mennyiségének minimalizálása érdekében.
Kapcsolatmodellek élirányokkal
A csúcspontok modellezése után az élek hozzáadhatók a köztük lévő kapcsolatok jelöléséhez. Az első szempont, amelyet értékelni kell, a kapcsolat iránya.
Az élobjektumok alapértelmezett irányt követnek, amelyet bejárás követ a függvények vagy outE() függvények out() használatakor. Ennek a természetes iránynak a használata hatékony műveletet eredményez, mivel minden csúcspont a kimenő élekkel együtt van tárolva.
Ha azonban egy él ellentétes irányában halad a függvény használatával in() , mindig keresztpartíciós lekérdezést eredményez. További információ a gráfparticionálásról. Ha folyamatosan kell haladni a in() függvény használatával, javasoljuk, hogy mindkét irányban adjon hozzá éleket.
Az él irányát a .to() Gremlin lépéssel vagy .from() predikátumokkal .addE() határozhatja meg. Vagy a Gremlin API tömeges végrehajtói kódtárával.
Feljegyzés
Az élobjektumok alapértelmezés szerint irányt adnak.
Kapcsolatfeliratok
A leíró kapcsolatcímkék használata javíthatja az élfeloldási műveletek hatékonyságát. Ezt a mintát a következő módokon alkalmazhatja:
- Kapcsolat címkézéséhez használjon nem általános kifejezéseket.
- Társítsa a forráspont címkéjét a cél csúcscímkéjével a kapcsolat nevével.
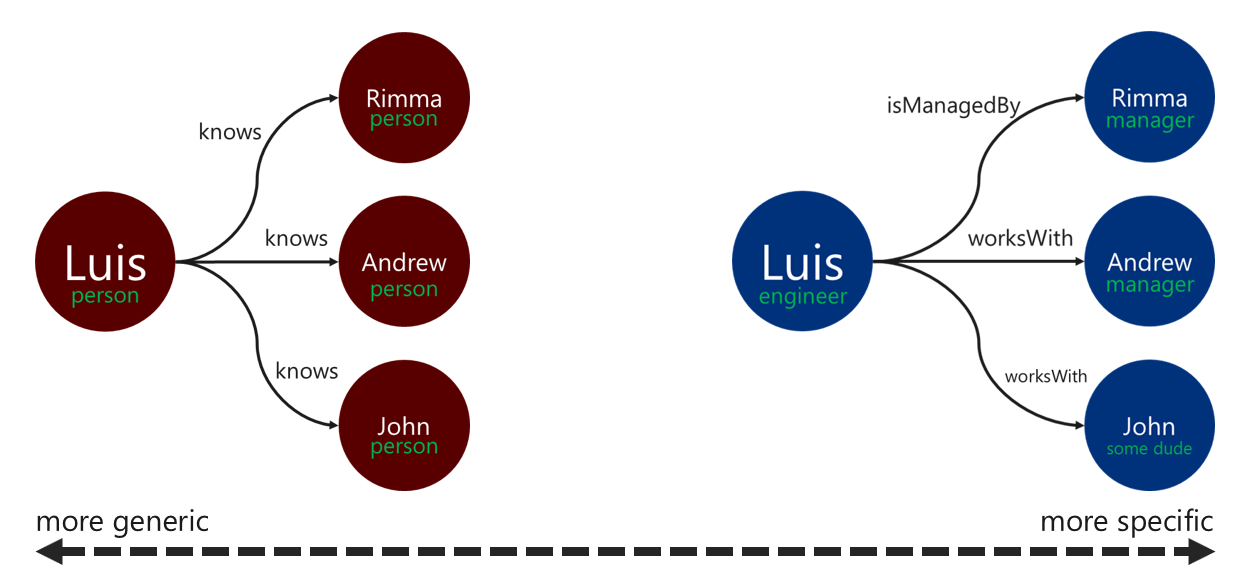
Minél pontosabb a címke, amelyet a bejáró a élek szűrésére használ, annál jobb. Ez a döntés jelentős hatással lehet a lekérdezési költségekre is. A lekérdezés költségét a végrehajtásiProfile lépéssel bármikor kiértékelheti.
Következő lépések
- Tekintse meg a támogatott Gremlin-lépések listáját.
- Ismerje meg a gráfadatbázis particionálását a nagyméretű gráfok kezeléséhez.
- A Gremlin-lekérdezések kiértékelése a végrehajtási profil lépésével.
- Külső gráftervezési adatmodell.